
- 1Android实战技巧之十六:getprop与dumpsys命令
- 2如何使用 Flink Connectors —— ElasticSearch?_flink-connector-elasticsearch
- 3Kali Linux2023年最新版全网最细安装教程_kali linux iso
- 4如何在 Mac上运行 Windows程序?_mac 运行windows软件
- 5这里有你想看的最全的HashMap扩容过程!---基于HashMap源码,非常详细的总结HashMap构造过程、插入过程、位运算细节、扩容机制,红黑树转化。
- 6中科院&地平线开源state-of-the-art行人重识别算法EANet:增强跨域行人重识别中的部件对齐...
- 7Paimon新版本核心特性和生产实践解读
- 8管理进阶——利益分配机制
- 9git提交pull request到主项目_git request
- 10Github Actions 构建Vue3 + Vite项目
AI Scaling的神话
赞
踩

截至目前,语言模型越来越大,能力也越来越强,但过去的表现能预测未来吗?
一种流行的观点是,我们应该期待当前的趋势继续保持下去,并且出现更多数量级,这最终可能会引领我们实现AGI。
本文作者认为,这种观点来自于一系列神话和误解。从表面上看,规模扩展(Scaling)具有可预测性,但这是对研究成果的误解。此外,有迹象表明,LLM开发者已经接近高质量训练数据的极限。而且,模型行业正面临着模型尺寸的强烈下行压力。虽然现在无法准确地预测AI通过扩展能取得多大进展,但作者认为仅靠扩展几乎不可能实现AGI。
(本文作者Arvind Narayanan是普林斯顿大学计算机科学教授,Sayash Kapoor是普林斯顿大学计算机科学博士生。本文由OneFlow编译发布,转载请联系授权。来源:https://www.aisnakeoil.com/p/ai-scaling-myths)
作者|ARVIND NARAYANAN、SAYASH KAPOOR
OneFlow编译
翻译|张雪聃、凌小雨
题图由SiliconCloud生成
1
扩展“定律”常被误解
有关扩展定律的研究表明,如果增加模型大小、训练计算量和数据集大小,语言模型会变得“更好”。这一改进在可预测性上十分显著,并且跨越了很多数量级。这使得许多人相信,扩展将在未来可预见的时间内将持续进行,并且领先的AI公司将定期发布更大、更强大的模型。
但这是对扩展定律的完全误解。什么是“更好”的模型?扩展定律只是将困惑度的下降进行了量化,也就是模型预测序列中下一个词的能力提高。当然,困惑度对最终用户来说其实并不重要——真正重要的是“涌现能力”,即模型随着大小增加而获得新能力的趋势。
涌现能力并不受任何类似定律的行为的支配。事实上,迄今为止,规模的增加带来了新的能力。但没有任何经验规律能让我们确信这会无限期地继续下去。[1]
为什么涌现能力无法无限期持续?这涉及到一个关于LLM能力的核心争论——模型是否能够外推,还是只能学习训练数据中展示的任务?在这个问题上,证据并不完整,有多种合理的解释方式。但我们倾向于持怀疑态度。在用于测试获取解决未见任务的技能效率的基准测试中,LLM表现不佳。
如果LLM无法做到超出训练以外的事情,那么在未来某时,拥有更多的数据不再有帮助,因为这些数据将要展示的所有任务都已经展示完了。每个传统的机器学习模型最终都会遇到瓶颈;LLM可能也不例外。
2
趋势外推是无依据的猜测
继续扩展的另一个障碍是获取训练数据。研发公司已经用上了所有现成的可用数据源。他们还能获取更多数据吗?
这看起来有可能实现,但实际上可能性却小得多。人们有时会假设新的数据来源(如转录整个 YouTube)将使可用数据量增加一到两个数量级。的确,YouTube 拥有1500亿分钟的视频。但考虑到其中大部分视频近乎或完全没有可用音频(相反是音乐、静止图像、游戏画面等),我们最终得到的估算远远低于Llama 3已经使用的 1.5 万亿个词元——这还是在对转录的YouTube音频进行去重和质量过滤之前,过滤之后的估算可能会再减少至少一个数量级。[2]
人们经常会讨论研发公司何时会“用完”训练数据。但这是一个没有意义的问题。总会有更多训练数据,但获取它的成本会越来越高。而现在,数据版权持有者已经意识到了这个问题,并且希望得到补偿,那么成本可能会急剧增加。除了金钱成本,可能还有声誉和监管成本,因为社会可能会反对数据收集行为。
我们可以确定没有任何指数趋势可以无限期持续。但很难预测一种技术趋势何时达到瓶颈,尤其是当增长突然停止而不是逐渐停止的时候。趋势线本身并未提供即将达到瓶颈的线索。
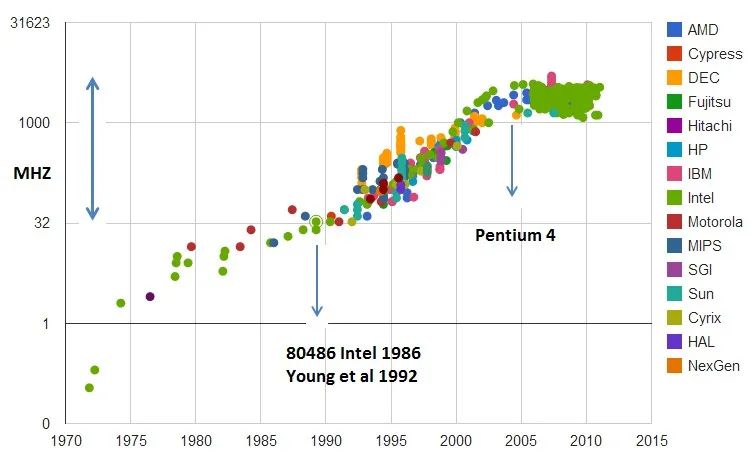
(CPU时钟速度随时间变化图,y轴为对数)
可以举两个著名的例子,一个是2000年代的CPU时钟速度,一个是1970年代的飞机速度。CPU制造商认为进一步提高时钟速度的成本过高且几乎无意义(因为CPU不再是整体性能的瓶颈),于是停止了在这一维度上的竞争,这突然消除了时钟速度的提升压力。飞机的故事更复杂一些,但可以归结为市场优先考虑燃油效率而非速度。[3]
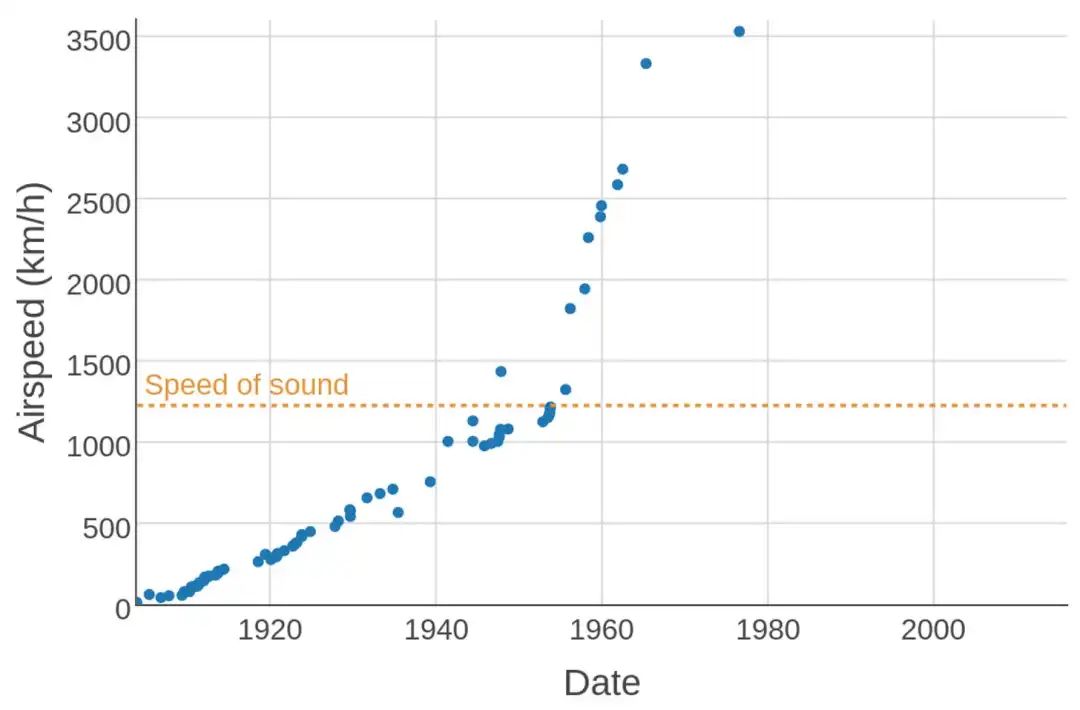
(飞行速度随时间变化图。1976年的SR-71 Blackbird记录至今仍然存在)
于LLM而言,我们可能还有几个数量级的扩展空间,也有可能扩展已经结束了。就像CPU和飞机一样,最终是一个商业决策,并且本质上难以提前预测。
在研究方面,关注重点已经从编译越来越大的数据集转向提高训练数据的质量。细致的数据清理和过滤可以使我们用更小的数据集构建同样强大的模型。[4]
3
合成数据不是魔法
人们常常认为合成数据是继续扩展的途径。换句话说,也许可以使用当前模型生成下一代模型的训练数据。
但我们认为,这个观点依旧来自于误解——我们并不认为开发者在用(或可以用)合成数据来增加训练数据的量。这篇论文(https://arxiv.org/html/2404.07503v1)列出了合成数据用于训练的许多用途,全部都在于修复特定的漏洞并进行领域特定的改进,如数学、代码或低资源语言。同样,Nvidia最近的340B模型Nemotron也专注于合成数据生成,并将对齐作为主要用途。合成数据也有一些次要用途,但替代当前的预训练数据来源并不是其中之一。简而言之,盲目生成合成训练数据可能无法与拥有更多高质量人类数据产生同样的效果。
在某些情况下,合成训练数据取得了巨大成功,例如2016年击败围棋世界冠军的AlphaGo及其后续产品AlphaGo Zero和AlphaZero。这些系统通过自我对弈进行学习;后两者没有使用任何人类棋局作为训练数据。它们使用了大量且相对高质量的计算生成棋局,用来训练神经网络,随后结合计算生成更高质量的棋局,形成迭代改进循环。
自我对弈是“系统2-->系统1蒸馏”的典型例子,其中缓慢且昂贵的“系统2”能够生成训练数据,以训练快速且便宜的“系统1”模型,这在围棋这样的完全自成一体的环境中效果很好。将自我对弈应用到游戏以外的领域是一个十分有价值的研究方向,这在代码生成等重要领域可能十分有益。但对于更开放的任务(例如语言翻译),我们无法期待其能通过自我改进而得到无限期提升。可以预见,那些可以通过自我对弈实现显著改进的领域是例外情况,并不是常规。
4
模型越来越小,但训练时间却越来越长
历史上,扩展的三个维度——数据集大小、模型大小和训练计算——是同步发展的,这是公认的最佳方式。但如果其中一个维度(高质量数据)成为瓶颈,会发生什么?其他两个维度(模型大小和训练计算)会继续扩展吗?根据当前的市场趋势,即使构建更大的模型可能会解锁新的涌现能力,但这似乎并不是一个明智的商业决策,因为能力本身不再是技术采用的主要障碍。换句话说,许多应用可以利用现有的LLM的能力来开发,但由于成本等其他原因,这些应用尚未被开发或广泛使用,尤其是“智能体”工作流,这类工作流可能需要调用数十次甚至数百次LLM才能完成任务,例如代码生成。
在过去的一年中,大部分开发工作都投入到在给定的能力级别上生成较小的模型。[5] 前沿模型开发人员不再透露模型大小,因此我们无法确定这一点,但我们可以将API定价作为模型尺寸的粗略替代,来做出相应的的猜测。GPT-4o的成本仅为GPT-4的25%,但他们功能相似,前者或许更好。我们在Anthropic和Google上也看到了同样的模式。Claude 3 Opus是Claude系列中最昂贵(也可能是最大)的型号,但最近的Claude 3.5 Sonnet价格便宜 5 倍,功能也更强大。同样,Gemini 1.5 Pro比Gemini 1.0 Ultra更便宜,功能也更强大。因此,于这三家开发商而言,最大的模型并不是最有能力的!
另一方面,训练计算在一段时间内可能会继续增长。矛盾的是,较小的模型需要更多的训练才能达到相同的性能水平。因此,模型大小的下行压力正在给训练计算带来上行压力。实际上,开发人员正在权衡训练成本和推理成本。早期模型如GPT-3.5和GPT-4在某种意义上训练不足,因为人们认为模型在其整个生命周期内的推理成本超过了训练成本。
理想情况下,训练成本和推理成本应该大致相等,因为两者之间总是可以权衡的。一个著名的例子是,Llama 3在训练时使用的浮点运算次数(FLOPs)是原始Llama模型(大约7亿参数)的20倍,尽管它的参数量(80亿)与原始模型的规模大致相同。
5
通用性阶梯
一个迹象表明我们可能无法通过扩展看到更多的能力提升:很多CEO一直在大幅降低对AGI的期望。不幸的是,他们并没有承认“三年内实现AGI”的天真预测是错误的,而是通过淡化对AGI的定义来保全面子,以至于这个定义现在已经变得毫无意义。AGI从未被明确定义,这反而帮了CEO们的忙。我们可以将“通用性”视为一个连续谱系,而不是二元对立的概念。
历史上,让计算机执行编程新任务所需的工作量已经减少,这可以看作是通用性不断增强的一个趋势。这一趋势可以追溯到从专门用途的计算机到图灵机的转变。从这个意义上说,LLM的通用性并不新鲜。
这是我们在《AI Snake Oil》一书中所持的观点,书中有一章专门讨论了AGI。我们将人工智能的历史概念化为一个间断均衡过程,将其称为通用性阶梯(这并不意味着线性进步)。经过指令调整的LLM是这个阶梯的最新一步。想要使人工智能像人类一样有效地执行任何具有经济价值的工作(这是AGI的一个定义),我们还有很多未知的路要走。
回顾历史,站在通用性阶梯的每一级上,AI研究社区在许多方面都表现不佳,包括预测当前范式的潜力、下一阶段会如何、何时会到来、能实现哪些新应用以及对安全性的影响等等。我们认为这种趋势还会继续下去。
拓展阅读
Leopold Aschenbrenner在最近发表的一篇文章(https://situational-awareness.ai/)中称“2027年实现AGI是十分有可能的”,该文章引起了业界轰动。我们并不是想逐条反驳——本文的大部分内容在Aschenbrenner的文章发表之前就已经起草了。他对时间预测的论证既有趣又发人深省,但从根本上说,这只是一次趋势线外推的实践。此外,和许多AI的狂热支持者一样,他将基准测试的性能与现实世界的实用性混为一谈。
许多AI研究人员都提出了质疑,包括 Melanie Mitchell、Yann LeCun、Gary Marcus、Francois Chollet 和 Subbarao Kambhampati 等人。
Dwarkesh Patel对辩论双方的观点进行了很好的总结。
致谢:十分感谢 Matt Salganik、Ollie Stephenson和Benedikt Ströbl对初稿的反馈。
[1] 如果我们能找到一个平稳变化而非间断变化的指标,涌现能力将是可预测的,但找到这样一个指标并不容易,特别是对于需要多种技能组合的任务而言。实际上,下一个数量级上会出现哪些新能力,以及这些新能力是什么,仍然是个未知数。
[2] AI公司确实使用转录的YouTube数据进行训练,但其价值不在于数量,而是在于它可以帮助LLM了解口语对话的样子。
[3] 不出所料,自由主义评论家将飞机速度停滞完全归因于监管,但这种说法是错误的,或者说至少是高度简化的。美国联邦航空局 (FAA)确实在1973年基本禁止民用飞机在美国陆地上空进行超音速飞行。但速度最快的都是军用飞机,因此该禁令并不会影响到民用飞机。出于燃油效率等考虑,民用飞机的巡航速度远低于1马赫。
[4] LLM训练是否可以使样本效率提高几个数量级?这个问题存在争议。毕竟,儿童接触的词汇比LLM少得多,但之后也习得了语言。另一方面,儿童是“婴儿床上的科学家”,很早就发展出了世界模型和推理能力,这可能是高效语言习得的关键。这场辩论与我们的观点无关。如果瓶颈在于任务表示或外推难度,则无论样本效率如何,它都将代表LLM能力的上限。
[5] 即使模型开发者发布了(参数数量)更大的模型,也会更加注重推理效率,例如在 Mixtral 8x22B 这样的混合专家模型中,推理过程中活跃的参数数量远低于总参数数量。
其他人都在看

开发生成式AI应用,减少响应时间
就用SiliconCloud
扫码加入用户交流群


