
热门标签
热门文章
- 1Java 对接智谱 AI(官方 sdk 是真垃圾)_智普ai java 调用
- 2基于ROS搭建简易软件框架实现ROV水下目标跟踪(十)--程序解析之手动控制_rov运动控制 csdn
- 304SpringCloud 消息中间件_spring cloud 消息中间件
- 4python 自然语言处理 词性标注_词性标注器用 pos_tagger(sentence) 来实现
- 5华为“全球最大研发中心”今年建成!预计招聘3.5万人!_华为全球最大研发中心年中启用,招募3.5万名研发人员
- 6基于springboot的在线导游预约系统java+vue
- 7Word2Vec词向量模型代码_根据已有词表,实现词转换为词向量代码
- 8谁说 Python 搞不定 AI 模型微服务?!Towhee 来了!_towhee 需要gpu吗
- 9Python+django+vue开发的家教信息管理系统
- 10.net 父子级关联排序_LTR排序算法LambdaRank原理详解
当前位置: article > 正文
【NLP】词的表示方式及word embeddings代码
作者:小丑西瓜9 | 2024-04-05 14:42:47
赞
踩
【NLP】词的表示方式及word embeddings代码
1.one-hot编码
- 给每个词分配一个数字ID,如“爸爸”=1=[010],“妈妈”=2=[001]
- 缺点(1)高维度,稀疏(2)词之间相互独立,无法表示词之间的语义
2.分布式表示
(1)基于矩阵的分布表示
- 词的相似度转换为向量的空间距离
- Global Vector模型
(2)基于聚类的分布表示
(3)基于神经网络的分布表示----词向量/词嵌入
- word embedding词嵌入空间
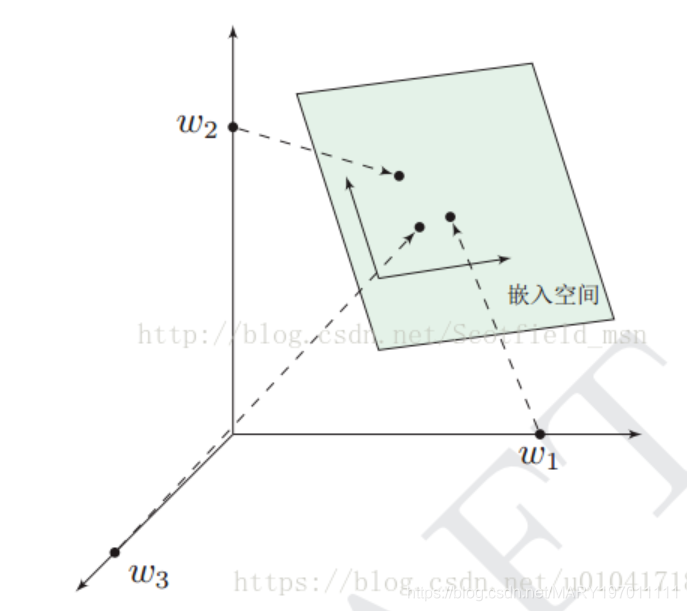
- 把one-hot的向量空间映射到低维、浮点数表示的向量空间中。


- 3.一般使用别人训练好的词向量,使用的语料库领域相同的。
3.word embedding代码
(1)安装gensim
gensim是处理word embeddings的python包
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/366260
推荐阅读
相关标签

