
- 1ArcGIS Engine10.0轻松入门级教程(4)——基本功能开发_arcengine movelinefeedbackclass
- 2java分布式事务——最终一致性,最大努力通知总结!_分布式事务中的最大努力通知思想
- 3python tokenizer是什么_Python tokenizer包_程序模块 - PyPI - Python中文网
- 4wordpress开源代码的一次白盒审计_开源代码安全审计
- 5大厂偏爱的Agent技术究竟是个啥_azure agent 是通过什么技术和后端通讯
- 6【gpt】免费部署个人gpt平台(无需tz)_gpt免费
- 7白天研究生系列:炼丹专题第三集《本地部署大语言模型保姆级教程——以ChatGLM-6B为例》_chatglm4-6b
- 8在Atlas 200 DK(Soc=Ascend 310)快速上手自定义模型训练、部署与推理_aclliteresource
- 9Python 零基础学习指南_momodel
- 10Python和人工智能的关系_人工智能程序是关联独立
.net 父子级关联排序_LTR排序算法LambdaRank原理详解
赞
踩

1.前言
在互联网应用场景中,排序是非常核心的模块。一个最直接的应用,就是日常生活常用到的搜索引擎。用户通过搜索框提交query,搜索引擎会返回一些与query相关的文档,并根据相关度大小排序后展示给用户。这一应用场景中,最相关的一些文档能否通过排序后优先展示,将直接影响用户。除些之外,排序算法也应用于在线广告、协同过滤、多媒体检索等领域。
传统排序方法,基于人工方式做策略组合,在数据量较小时能够起到作用。随着互联网数据量的增加,这种方法变得越来越困难。因而,更自然的解决方案,是开发基于机器学习的搜索引擎排序算法。这种算法通常称之为Learning to Rank(LTR)。
LTR算法中,LambdaMART[1]是最常被使用的一种Listwise算法,在各大搜索引擎中均有应用。从其名称上,可以知道其由Lambda和MART两部分组合成,其中MART(Multiple Additive Regression Tree)表示的是底层训练模型,而Lambda表示的是MART求解过程使用的梯度。
为什么LambdaMART可以很好的应用于排序场景?这主要受益于Lambda梯度的使用。但Lambda最初是在LambdaRank模型中被提出,而LambdaRank模型又是在RankNet模型的基础上改进而来。
下面我们将从MART、Lambda来深入了解LambdaMART算法。
2.MART算法
说起MART(Multiple Additive Regression Tree),大家可能比较陌生。但是提起GBDG(Gradient Boosting Decision Tree),很多人都熟悉。没错,MART本质上就是梯度提升决策树GBDT。所以,我们很容易知道MART的一些特征:
- 基于多个决策树来预测结果;
- 决策树之间通过加法模型叠加结果;
- 每棵决策树都是针对之前决策树的不足进行改进。
本质上,MART是一种Boosting思想下的算法框架。它通过不断迭代弱模型,改进新模型的能力,最终得到的是所有模型的叠加,这一结果起到足以预测真实值的强模型。关于MART算法细节可参考[8],这里不再详细说明。
那么在LambdaMART中,MART的损失函数是如何定义的?这里就必须了解下Lambda的演化史了。
3.Lambda
Lambda最早诞生于LambdaRank算法,而LambdaRank算法改进自RankNet算法。为了对排序算法有更深刻的理解,我们先来了解下RankNet算法。
2.1RankNet
我们知道,在排序中,常用的评价指标NDCG,MAP,ERR都是不可导的,即无法求梯度,这就导致了无法运用梯度下降算法求解排序问题。RankNet[2]以一种巧妙方法,将无法用梯度下降求解的排序问题,优化为对概率的交叉熵损失函数,继而可用梯度下降算法求解。
下面来看看RankNet是如何优化排序问题的。RankNet的训练目标是得到一个模型,输入是文档,输出是该文档的得分:
其中表示模型的参数集。
有了模型后,对于文档和,我们可以分别得到其得分和:
RankNet巧妙的地方在于,它通过偏序关系将文档之间的得分与文档顺序关联起来,进而得出概率。具体地,记表示文档排在前面的概率,则:
可以看到,RankNet使用了sigmoid函数来转化排序概率,本质上就是逻辑回归!这里影响的是sigmoid函数的形状,对最终结果影响不大,为简化说明,后文将使用=1。
在实际应用中,文档排在之前的真实概率我们是知道的,这里记为。我们约定,如果排在之前则为1,否则为0。
接着,根据模型概率和真实概率,使用交叉熵可衡量出模型在排序文档和产生的损失函数:
上面公式中,我们使用了符号,它表示的是文档与的真实序关系:
最后,RankNet的损失函数定义如下,目标是使得所有文档对的排序概率估计的损失最小:
这里,表示的是一次查询中所有文档对集合。
RankNet的训练目标是求解模型的参数,此时可通过梯度下降法求解:
2.2LambdaRank
RankNet避开了直接对排序中的评价指标进行优化,以概率模型抽象解决了排序中的相关顺序问题。但是由于没有涉及到评价指标的优化,实际应用中存在一些问题。
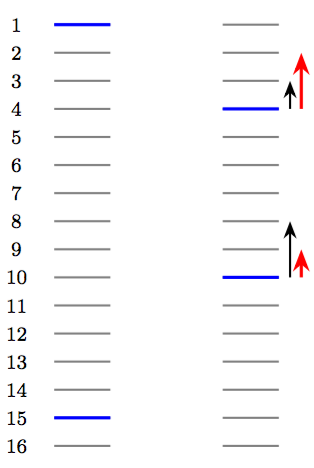
如图所示[4],每个线条表示一个文档,蓝色表示相关文档,而灰色表示不相关文档,排在前面的文档将优先展示给用户。由于RankNet只关心两两文档之间的顺序,忽视了文档的具体顺序信息,那么当面对左图的情形时,假设此时损失值为13,RankNet通过把排在首位的相关文档下调3个位置,排在倒数第二的相关文档上调5个位置,从而将损失值降为11。但是,对于用户来说,通常更关注top k个结果的顺序,在优化过程中下调top结果中的相关文档并不能令用户满意。
图1右图左边黑色的箭头表示RankNet下一轮的调序方向和强度,但用户真正需要的是右边红色箭头代表的方向和强度,即更关注靠前位置的相关文档的排序位置的提升。
所以,排序中的评价指标NDCG更能反应用户对相关性的潜在需求。这里问题就来了:能不能通过NDCG指标来定义梯度呢?
LambdaRank[3]正是基于这个思想演化而来,其中Lambda指的就是红色箭头,代表下一次迭代优化的方向和强度,也就是梯度。
我们来看看LambdaRank是如何通过NDCG指标定义梯度的。首先,对于RankNet的梯度,我们有如下推导:
进一步的,可以观察到对模型的求导有下面的对称性:
因此,LambdaRank有如下关于文档和的Lambda定义:
我们首先考虑有序对,因而有,于是上述公式可以进一步简化:
至此可以得到每个文档的Lambda值为:
公式中是文档对(,)的集合,其中文档排在前面,即更相关。
为了加强排序中顺序前后的重要性,LambdaRank进一步在Lambda中引入评价指标Z(如NDCG),把交换两个文档的位置引起的评价指标的变化作为其中一个因子:
可以这么理解Lambda,Lambda量化了一个待排序的文档在下一次迭代时应该调整的方向和强度。
可以看出,LambdaRank不是通过显示定义损失函数再求梯度的方式对排序问题进行求解,而是分析排序问题需要的梯度的物理意义,直接定义梯度,可以反向推导出LambdaRank的损失函数为:
2.3LambdaMART
理解了Lambda和MART的定义后,对LambdaMART理解起来就不难了。LambdaMART模型结果由许多棵决策树通过Boosting思想组成,每棵树的拟合目标是损失函数的梯度,这里的梯度采用Lambda方法计算。
下面是Lambda算法的具体步骤[5]:

算法的参数有:决策树的数量M、叶子节点数L和学习率。
- 初始时,没有决策树模型,因而每个文档的模型得分都为0。
- 针对每棵树的训练,算法会遍历训练数据集中label不同的文档对,求出将label不同的文档对位置互换时导致的指标变化以及,进而得到每个文档的Lambda值。
- 计算每个的导数,用于后面的Newton step求解叶子节点的数值。
- 以所有文档的作为label训练一棵决策树,注意这里是决策树的拟合目标。建立决策树的关键是如何决定分裂节点。LambdaMART采用最朴素的最小二乘法,也就是最小化平方误差和来分裂节点:即对于某个选定的feature,选定一个值val,所有<=val的样本分到左子节点,>val的分到右子节点。然后分别对左右两个节点计算Lambda的平方误差和,并加在一起作为这次分裂的代价,进而选出代价最小的(feature,val)作为当前分裂点,最后生成一颗叶子节点数为L的决策树。
- 对上述生成的决策树,采用Newton step计算每个叶子节点的数值,即对落入该叶子节点的文档集,计算该叶子节点的输出值。
- 更新模型,将当前学习到的决策树加入到已有的模型中,用学习率v做regularization。
3.总结
LambdaMART是一种Listwise类型的LTR算法,它基于Lambda思想和MART算法,将搜索引擎结果排序问题转化为回归决策树问题。LambdaMART有很多优点,取一些列举如下[7]:
- 直接求解排序问题,而不是用分类或者回归的方法;
- 可以将NDCG之类的不可求导的评价指标转换为可导的损失函数,具有明确的物理意义;
- 可以在已有模型的基础上进行Continue Training;
- 每次迭代选取gain最大的特征进行梯度下降,因此可以学到不同特征的组合情况,并体现出特征的重要程度(特征选择);
- 对正例和负例的数量比例不敏感。
参考文献
- [1] http://research.microsoft.com/en-us/um/people/cburges/tech_reports/msr-tr-2010-82.pdf
- [2] http://research.microsoft.com/pubs/69183/icml_ranking.pdf
- [3] http://research.microsoft.com/pubs/68133/lambdarank.pdf
- [4] https://blog.csdn.net/huagong_adu/article/details/40710305
- [5] http://dasonmo.cn/2019/02/08/from-ranknet-to-lambda-mart/
- [6] https://www.cnblogs.com/wowarsenal/p/3900359.html
- [7] https://liam.page/2016/07/10/a-not-so-simple-introduction-to-lambdamart/
- [8] http://projecteuclid.org/download/pdf_1/euclid.aos/1013203451
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。

推荐阅读
这个NLP工具,玩得根本停不下来
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
从数据到模型,你可能需要1篇详实的pytorch踩坑指南
如何让Bert在finetune小数据集时更“稳”一点
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
Node2Vec 论文+代码笔记
模型压缩实践收尾篇——模型蒸馏以及其他一些技巧实践小结
中文命名实体识别工具(NER)哪家强?
学自然语言处理,其实更应该学好英语
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧?

