
- 1软件测试 | 简历中应该如何描述才能体现出软技能的实力?_简历怎么体现软件应用能力 知乎
- 29.基于粤嵌gec6818开发板小游戏2048的算法实现_粤嵌6818开发板2048算法
- 3【树莓派4B串口通信之wiringPi库】小白踩坑成功出逃_树莓派wiringpi
- 4mysql oracle nosql_Oracle
- 5Camtasia Studio2024永久免费注册码激活码分享_camtasia studio2024 序列号
- 6ContentProvider 的 query 流程分析_contentprovider query
- 7凭借这份《2022测试八股文》候选者逆袭面试官,offer拿到手软_八股文机场面试
- 8微软: 用于文本到语音合成(TTS)的语言模型方法VALL-E_微软tts模型
- 9六位数字密码锁设计(数字电路,proteus仿真)_密码锁 数字电路
- 10基于Whisper语音识别的实时视频字幕生成 (一): 流式播放视频帧和音频帧_whisper 流式语音识别
ProbTS:时间序列预测的统一评测框架
赞
踩
编者按:如今,时间序列预测在健康、能源、商业、气候等多个行业发挥着至关重要的作用。它不仅影响着相关资源的分配和调度,还影响着行业的管理和运营决策。但是现有的时间序列预测方法通常缺乏对基础预测需求的全面考虑,无论是经典的时序预测模型还是近期涌现的时序基础模型,都存在方法设计上的“偏见”。
为此,微软亚洲研究院的研究员们联合香港科技大学(广州)和清华大学的科研人员合作开发了 ProbTS 框架,希望对现有时序预测模型进行统一的基准评测。在 ProbTS 框架下,研究员们通过在点估计/分布估计、长程/短程、自回归/非自回归等多维度上的预测效果比较,揭示了各模型在关键方法论上的“抉择”难题和差异,并对各模型进行了全面的优劣势辨析。ProbTS 的分析结果可以帮助业界反思当前时间序列预测模型在底层方法论上遭遇的挑战,更重要的是为未来预测模型的发展梳理出了更加清晰的研究方向。
时间序列预测(Time-series Forecasting)对众多行业都至关重要,包括健康、能源、商业、气候等。在不同预测长度上的准确性,对这些领域中服务短期和长期的规划和决策需求来说极其重要。例如,在疫情爆发这种公共卫生的紧急情况下,预测一到四周内的感染病例和死亡人数对于有效分配医疗和社会资源非常重要。在能源领域,准确预测每小时、每天、每周甚至每月的电力需求也对电网管理和可再生能源调度十分关键。同样,在物流行业,准确预测短期和长期的货物量能有效帮助企业合理安排运输路线以及高效管理供应链。
除了涵盖各种预测长度,面向规划和决策的精准预测不仅要考虑到点估计(Point Estimation),更要支持分布估计(Distribution Estimation),以衡量估计的不确定性。因为期望下的预测值及其相关的不确定性可以为随后的规划和优化提供一个全面的视角来引导更好的决策。
鉴于不同预测长度对点预测和分布预测的迫切需求,来自微软亚洲研究院的研究员们对现有不同研究领域开发的最先进的模型进行了回顾,这些模型包括:
- 经典时间序列模型:这些模型通常需要在每个数据集上从头开始训练,包括专门用于长程点预测(例如,PatchTST、iTransformer)以及专注于短程分布预测的方法(例如,CSDI、TimeGrad)。
- 近期的时间序列基础模型:这些模型涉及在广泛的时间序列数据集上进行通用预训练,包括由工业实验室(例如,TimesFM、MOIRAI、Chronos)和学术机构(例如,Timer、UniTS)开发的方法。
研究员们发现,尽管目前的预测模型有着可观的进展,但现有的方法通常缺乏对基础预测需求的全面考虑。这种局限性将导致现有模型方法在设计上存在“偏见”,而且这些模型能力尚未在更广泛的预测场景中得到验证。
基于此,研究员们开发了 ProbTS 框架。ProbTS 是一个统一的基准评测框架,旨在评估当前方法在满足基本预测需求方面的表现。研究员们通过 ProbTS 工具,不仅对预测研究的关键方法论差异进行了探讨,还对各类时间序列预测的经典模型和基础模型进行了评测,揭示了现有时间序列预测研究中存在的问题,以及各模型的优劣势所在,进而对该领域未来的研究方向进行了梳理。
ProbTS: Benchmarking Point and Distributional Forecasting across Diverse Prediction Horizons
论文链接:https://arxiv.org/abs/2310.07446v4
GitHub链接:https://github.com/microsoft/ProbTS
范式差异:时间序列预测的方法论辨析
研究员们通过 ProbTS 进行的基准研究发现,目前的时间序列预测关键方法论存在两方面的差异——点估计和分布估计的预测范式,以及多步预测的解码方案。
点估计和分布估计的预测范式:
- 点预测:只支持点预测的方法,提供预期估计值而不进行不确定性量化。
- 预定义的分布函数预测头:使用预定义的分布函数预测头生成分布预测的方法,提供了一定的不确定估计,但缺乏对复杂数据分布的建模能力。
- 神经分布估计模块:采用基于神经网络的模块来估计数据分布,允许更灵活且可能更准确的不确定性量化。
多步预测输出的解码方案:
- 自回归(Autoregressive,简称 AR)方法:这些方法逐步生成预测,使用先前的预测作为未来时间步的输入,适用于序列依赖性至关重要的场景。
- 非自回归(Non-autoregressive,简称 NAR)方法:这些方法同时为所有时间步生成预测,提供更快的预测速度,并且可能在长程预测中表现更好。
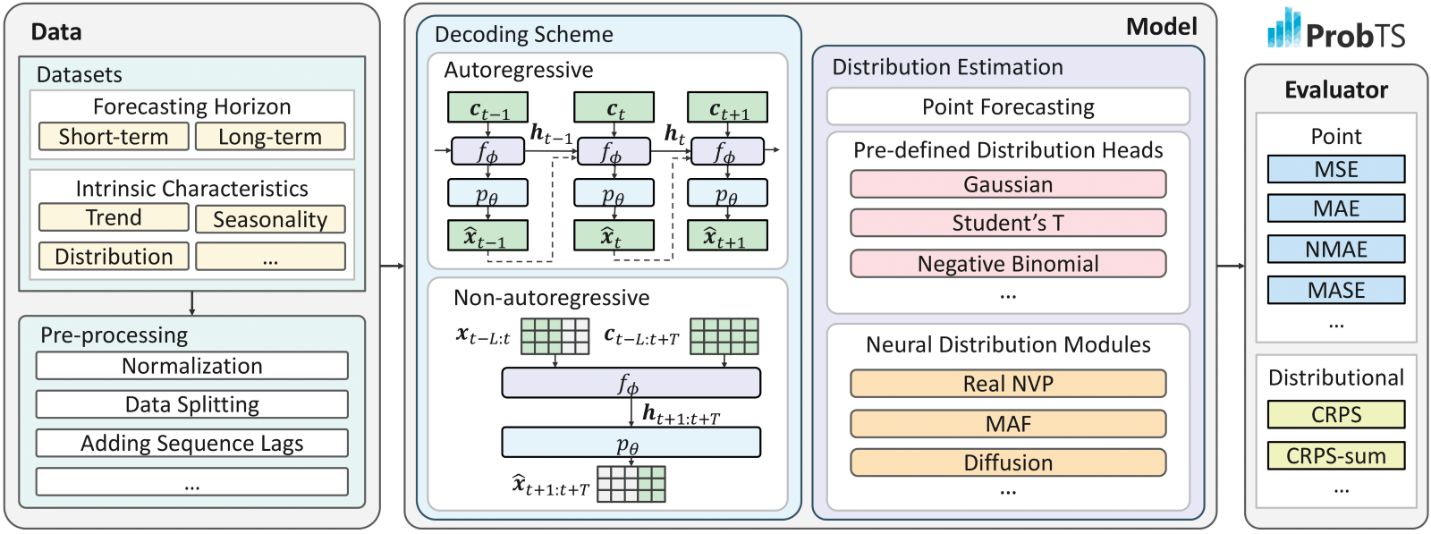
图1:ProbTS 概览,展示了其在不同预测场景中的覆盖范围,包括不同研究分支中开发的典型模型和全面的评估指标。
在 ProbTS 框架下的研究结果显示:首先,在长程及短程预测中,长程点预测的方法因定制化的神经架构在长程场景中表现出色,但在短程案例和复杂数据分布中表现不佳,并且因为缺乏对预测不确定性的量化评估,导致其与概率模型相比在应对复杂数据分布情况下存在显著的性能差距。而短程概率预测方法仅在短程分布预测方面表现专业,但在长程预测场景中就会出现性能下降以及计算效率的问题。
其次,针对解码器设计,长程点预测模型主要采用非自回归解码,而在短程概率预测模型设计中则没有出现这种偏向性。并且,尽管自回归解码在长程预测中容易受到误差累积的影响,但在具有强周期性模式的场景下可能表现更好。
最后,在当前涌现的时间序列基础模型中,部分采用自回归解码的基础模型在长程预测中同样面临误差累积的挑战,且尚未有较好的应对措施。同时,当前基础模型对分布预测的支持有限,突显了提升复杂数据分布建模能力的需求。
经典时间序列模型的评测结果与分析
研究员们使用 ProbTS 框架对广泛的预测场景中的各种经典时间序列模型进行了基准评测,涵盖短程和长程预测。具体评测指标包括点预测指标 NMAE (Normalized Mean Absolute Error) 和分布预测指标 CRPS (Continuous Ranked Probability Score)。此外,研究员们还通过计算一种非高斯性的评分,量化了每个预测场景中数据分布的复杂性。
根据 ProbTS 的评测结果,研究员们发现:
- 长程点预测模型的局限性:针对长程点预测所设计的时间序列神经架构,在长程场景中表现出色,然而,它们在短程预测任务中的架构优势显著降低(见图2(a)和2(c))。而且,这些模型无法衡量预测的不确定性,导致其与概率模型相比在分布预测上存在更大的性能差距。这一差距在数据分布复杂时会更加显著(见图2(c)和2(d))。
- 短程概率预测模型的弱点:当前的概率预测模型虽然在短程分布预测方面表现出色,但在长程场景中面临挑战,表现为显著的性能下降(见图2(a)和2(b))。此外,随着预测长度的增加,一些模型会遭受严重的计算效率问题(详情请参见论文)。
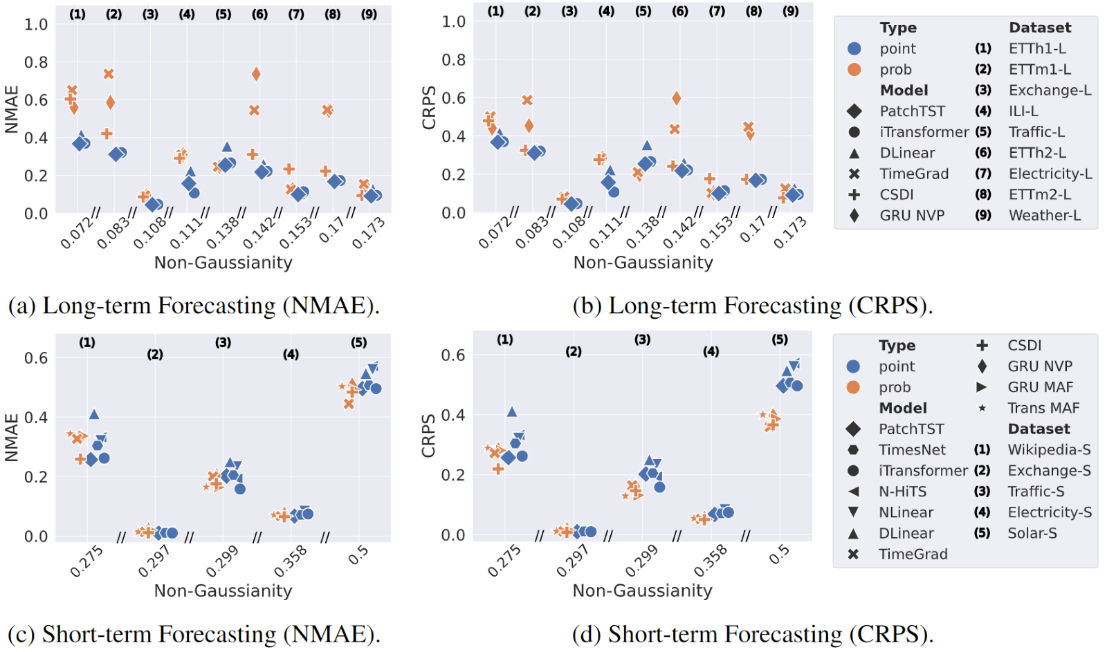
图2:使用 ProbTS 对经典时间序列模型进行基准评测
这些观察结果表明,当前已有的预测模型中仍然缺乏适合短程预测的有效架构设计;另外刻画复杂数据分布的能力对于这些预测模型的能力而言及其重要。同时,目前的长程分布预测在性能和效率方面都面临着重大挑战。
随后,研究员们在各种预测场景中比较了自回归(AR)和非自回归(NAR)解码方案,以突出它们在预测长度,以及面对不同趋势性和周期性时序数据方面的优势与劣势。
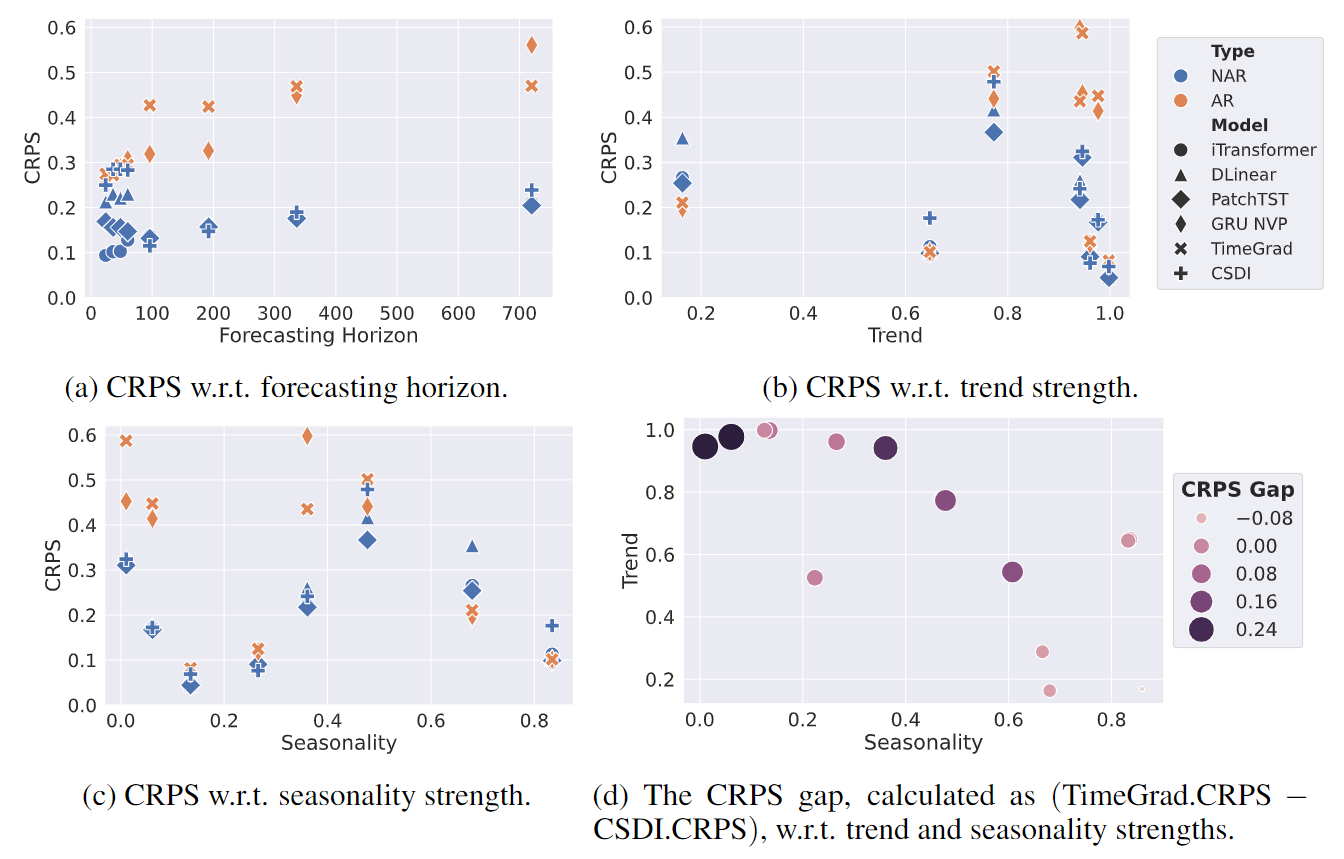
图3:使用 ProbTS 比较自回归和非自回归解码方案
研究员们发现,目前几乎所有的长程点预测模型都在使用非自回归解码方案进行多步预测输出,而概率预测模型则更平衡地使用自回归和非自回归方案。从数据特性视角出发,两种方案的差异可能源于:
- 预测长度影响:图3(a)显示,随着预测长度的增加,AR 解码与 NAR 方法相比表现出更大的性能差距,表明 AR 可能受到错误累积的影响。
- 趋势性强度影响:图3(b)将性能差距与趋势性的强度联系起来,表明强烈的趋势效应可能导致 NAR 和 AR 模型之间的显著性能差异。当然也存在例外情况,即使趋势性强,基于 AR 的模型也未必出现大幅度性能下降。
- 周期性强度影响:图3(c)通过引入周期性强度作为另一个因素来解释这些例外。令人惊讶的是,基于 AR 的模型在具有强周期性模式的场景中表现更好,这很可能是由于它们在这种情况下具有更高的参数效率。
- 趋势性和周期性的综合影响:图3(d)展示了趋势性和周期性对性能差异的综合影响。
基于此,研究员们指出,不同研究分支选择 AR 和 NAR 解码方案主要是由它们所关注的预测场景中特定的数据特性所驱动的,这也解释了大多数长期预测模型对 NAR 解码范式的偏好。然而,这种对 NAR 的偏好可能忽略了 AR 的优势,特别是 AR 在处理强周期性方面的有效性。由于 NAR 和 AR 各自拥有独特的优势,未来的研究可以探索两者的平衡之道,并改善它们的弱点。
时间序列基础模型的评测结果与分析
研究员们还使用 ProbTS 框架将分析扩展到最新涌现的时间序列基础模型上(参见图4),不仅评估了这些模型在各种预测长度内的表现,还检验了它们的分布预测能力。
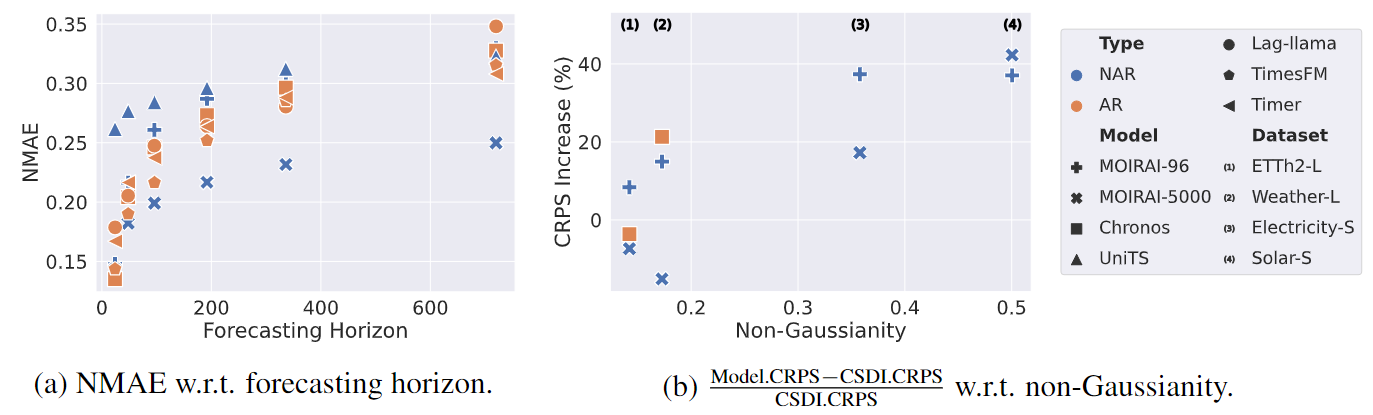
图4:使用 ProbTS 进行时间序列基础模型评测
评测结果表明:
- AR 解码在扩展预测长度时存在局限性(图4(a)),这可能是由于时间序列具有数值连续的特性,与语言建模中 AR 方法操作在离散空间中的情况不同,AR 解码方法在时序预测上会遇到更加严重的误差累积问题。
- AR 和 NAR 模型在短程场景中可以提供相当的性能,有时基于AR的模型甚至会优于它们的 NAR 对手。
- 当前的基础模型在分布预测方面支持有限,通常使用预定义的分布预测函数(例如:MOIRAI)或在值量化空间中用离散分布来近似建模(例如:Chronos)。这一点可以通过其与经典概率模型 CSDI 在比较捕捉复杂数据效果时发现(图4(b))
总而言之,虽然当前基于 AR 的基础模型在短程场景中表现优异,但它们的性能在面临更长的预测长度时显著降低,这表明时间序列数据预测,尤其在长程预测场景中,需要独特的处理来优化 AR 解码。同时,上述研究再次证明了准确刻画复杂数据分布的能力仍然是时间序列基础模型中亟需提升的关键领域。
未来方向:视角、模型和工具的三重更新
基于对现有方法的评测与分析,研究员们提出了在时间序列预测模型领域未来最重要的若干研究方向,在这些方向上的深入探索将会对各个行业的关键预测场景产生重大影响。
方向1:采用全面视角。研究员们指出,在开发新模型时有必要采用全面的视角审视前述的核心预测需求。这将帮助我们重新思考不同模型的方法选择,迭代它们的优势和劣势,并促进更多样化的研究探索。
方向2:创建通用模型。ProbTS 的研究引发了一个基本问题,即能否开发出一个满足所有核心预测需求的通用模型?或者是否应该分别处理不同的预测需求,为每种需求引入特定技术?
研究员们认为,虽然很难给出一个明确的答案,但当前的发展趋势可能倾向于创建一个通用模型。在设计该模型时,需要考虑输入表示、编码架构、解码方案和分布估计模块等问题。此外,未来还需要研究该通用模型如何应对高维数据和嘈杂场景中的分布预测(特别是对于长程预测),并探索如何利用 AR 和 NAR 解码方案的不同优势,同时规避它们各自的弱点。
方向3:开发研究工具。未来应进一步加强对相关研究工具的开发。目前研究中使用的 ProbTS 框架已经开源,研究员们希望通过这一框架吸引并凝聚研究社区的集体力量,从而促进时间序列预测领域的进步。
通过解决这些问题,微软亚洲研究院的研究员们将不断探索时间序列预测研究的边界,致力于研发出更加稳健、多功能且能够应对各种实际工业预测场景和挑战的时间序列模型。未来,完善的预测模型将极大激发多个行业的潜力,推动资源的高效利用、优化决策流程以及提升运营效率,从而加速产业智能化发展,并提升人们的生活品质。

