
- 1在 LaTeX 中插入表格_latex插入表格
- 2神器Ai工具箱全集,不用找了你想要的Ai都在这里。_work.rightbrain.art
- 3基于Bert的微博舆论分析Web系统_bert舆情分析项目介绍
- 4Nginx项目发布成功之后,再次启动服务器无法访问(解决办法)_nginx发布应用一直转圈圈 再次访问就出错
- 5leaflet—marker总结_leaflet marker
- 6Android.mk中 LOCAL_COPY_HEADERS_TO 和 LOCAL_COPY_HEADERS的作用
- 7《Spring》IOC实现原理_spring ioc实现原理
- 8【干货】数据结构与算法该如何正确学习?(书籍\视频\网站都推荐了)_数据结构与算法怎么学
- 9鸿蒙Socket通信示例(TCP通信)
- 10vscode创建flutter项目无法运行的解决方法_command 'flutter.createsampleproject' not found
时序数据库基本概念学习_时序数据库原理
赞
踩
1、时序数据
1.1 定义
时序数据就是一串按时间维度索引的数据,这类数据描述了某个被测量的主体在一个时间范围内的每个时间点上的测量值。
对时序数据践行建模的话,会包含三个重要部分:主体,时间点和测量值。
我们经常接触到的监控数据就是一类时序数据,比如每间隔1秒机器内存的小时占用。
1.2 数学模型
时序数据的基本模型可以分成下面几个部分:
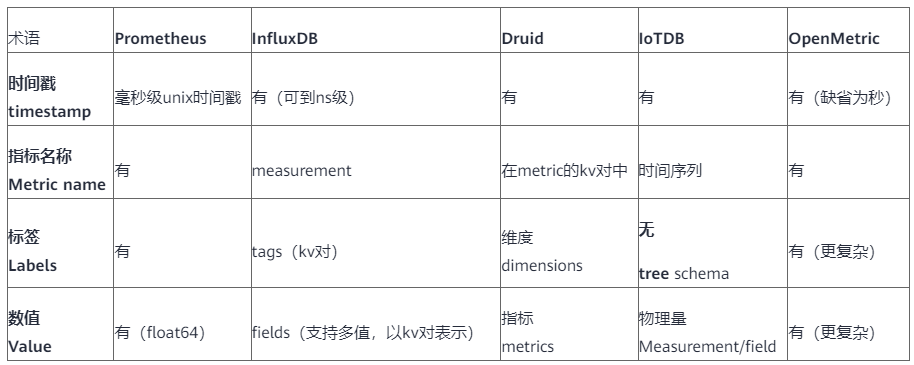
- Metric:度量的数据集,类似于关系型数据库中的 table,是固定属性,一般不随时间而变化
- Timestamp:时间戳,表征采集到数据的时间点
- Tags:维度列,用于描述Metric,代表数据的归属、属性,表明是哪个设备/模块产生的,一般不随着时间变化
- Field/Value:指标列,代表数据的测量值,可以是单值也可以是多值
常见TSDB中基本概念的对应关系
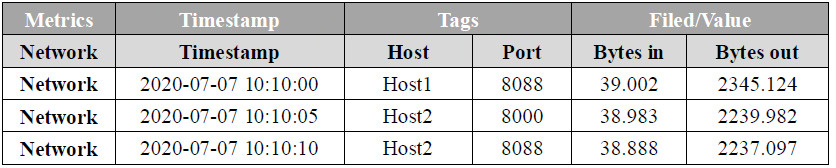
下图为某机器网络流量的时序数据
1.3 数据特点
- 数据模式: 时序数据随时间增长,相同维度重复取值
- 数据写入:持续高并发写入,更新操作极少
- 数据查询:按不同维度对指标进行统计分析
2、存储优化
时序数据库产品的发明都是为了解决传统关系型数据库在时序数据存储和分析上的不足和缺陷,对应上述的数据特点,时序数据库大致做了一下优化:
-
存储成本:
利用时间递增、维度重复、指标平滑变化的特性,合理选择编码压缩算法,提高数据压缩比;
通过预降精度,对历史数据做聚合,节省存储空间 -
高并发写入:
批量写入数据,降低网络开销;
数据先写入内存,再周期性的dump为不可变的文件存储 -
低查询延时,高查询并发:
优化常见的查询模式,通过索引等技术降低查询延时;
通过缓存、routing等技术提高查询并发
3、存储原理
传统数据库存储采用的都是 B tree,这是由于其在查询和顺序插入时有利于减少寻道次数的组织形式。我们知道磁盘寻道时间是非常慢的,一般在 10ms 左右。磁盘的随机读写慢就慢在寻道上面。对于随机写入 B tree 会消耗大量的时间在磁盘寻道上,导致速度很慢。
对于 90% 以上场景都是写入的时序数据库,B tree 很明显是不合适的。业界主流都是采用 LSM tree 替换 B tree,LSM tree 包括内存里的数据结构和磁盘上的文件两部分。
LSM tree 操作流程如下:
数据写入和更新时首先写入位于内存里的数据结构。为了避免数据丢失也会先写到 WAL 文件中。内存里的数据结构会定时或者达到固定大小会刷到磁盘。这些磁盘上的文件不会被修改。随着磁盘上积累的文件越来越多,会定时的进行合并操作,消除冗余数据,减少文件数量。
可以看到 LSM tree 核心思想就是通过内存写和后续磁盘的顺序写入获得更高的写入性能,避免了随机写入。但同时也牺牲了读取性能,因为同一个 key 的值可能存在于多个 HFile 中。为了获取更好的读取性能,可以通过其他方式进行优化。
4、时序数据模型
4.1 基于标签(tag-value)
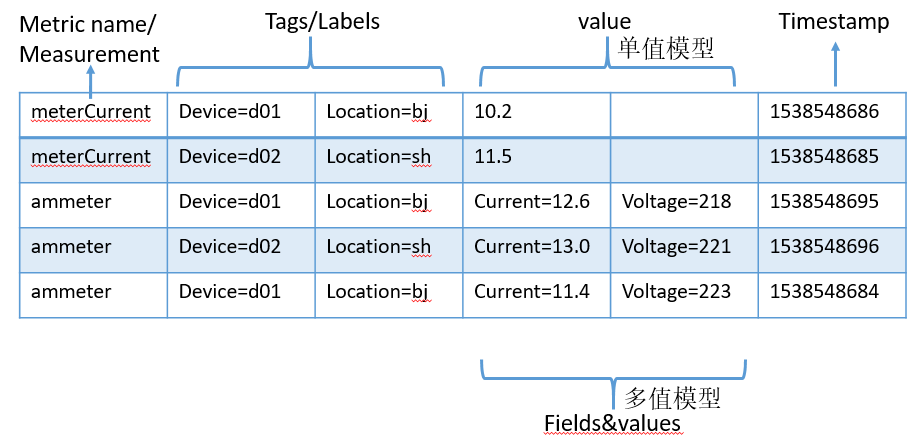
时序数据一般分为两部分,一个是标识符(指标名称、标签或维度),方便搜索与过滤;一个是数据点,包括时间戳和度量数值。数值主要是用作计算,一般不建索引。从数据点包含数值的多少,可以分为单值模型(比如Prometheus)和多值模型(比如InfluxDB);从数据点存储方式来看,有行存储和列存储之分。一般情况下,列存能有更好的压缩率和查询性能。
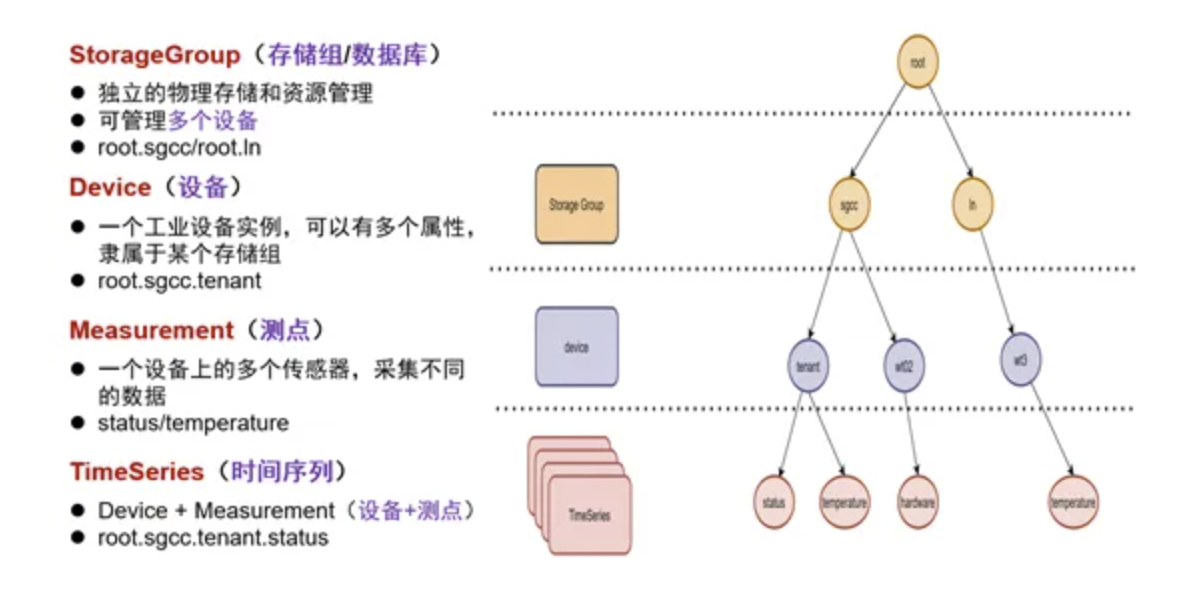
4.2 基于树形(tree schema)
IoTDB与其他TSDB的数据模型最大的不同,没有采用标签(tag-value、Labels)模式,而是采用树形结构定义数据模式:以root为根节点、把存储组、设备、传感器串联在一起的树形结构,从root根节点经过存储组、设备到传感器叶子节点,构成了一条路径(Path)。一条路径就可以命名一个时间序列,层次间以“.”连接。
参考链接:
https://blog.miuyun.work/archives/12485081
https://zhuanlan.zhihu.com/p/410255386
https://www.cnblogs.com/eyesfree/p/15394159.html
https://bbs.huaweicloud.com/blogs/300156
如有不对,烦请指出,感谢~

