
- 1【毕业设计】基于微信小程序的高校宿舍管理系统_微信小程序宿舍管理
- 2【Android Audio 入门 一】--- Audio ALSA Driver_soc_single_multi_ext
- 3python的数据降维库umap_python umap
- 4Android Studio版本最新更新Gradle配置与Kotlin包冲突问题_implementation(platform("org.jetbrains.kotlin:kotl
- 5Stable Diffusion Lora模型训练详细教程_stable diffusion lora训练
- 6Requestium
- 7计算机毕业设计PHP基于微信小程序的网络办公系统(源码+程序+VUE+lw+部署)_php开源 办公 小程序
- 8Github,SourceForge,Gitee三个平台的简介_github、gitee及huggingface平台
- 9深度学习大模型框架的简单介绍(ChatGPT背后原理的基本介绍)
- 10XShell调整字体大小以及样式_xshell文本样式解析
【得物技术】推荐系统是如何做召回的?_推荐系统召回中的信息检索
赞
踩
引言
推荐系统的目的是自动为用户挑选匹配度最高的内容,节约用户信息检索的时间,从而创造价值。淘宝上,数以亿计的商品和店铺内容,最终展现在手机屏幕上的商品只有几十个;抖音中,千万级的短视频内容,每次划屏也只会播放出一个;难道强大的推荐系统真的能在短短几十毫秒之间,把用户对全平台所有商品的兴趣都计算一遍然后选出最好的?即使是得物APP这样内容规模相对较小的平台上,使用算法规则在毫秒级的时间内把用户与所有商品或者内容的偏好关系全部计算一遍也是非常不现实的,但是排序的环节又是必不可少的。那我们应该对哪些内容进行排序才是相对公平而又合理的呢?今天让我们来聊聊,推荐系统中的召回环节。
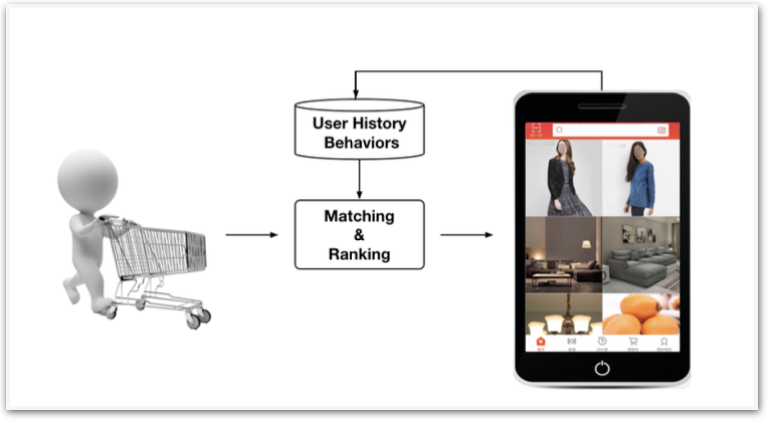
图1. 推荐系统示意图(引用自阿里巴巴DIN论文)
什么是召回?
相对于排序而言,召回不是一个太常见的词,有一些统计学知识背景的同学可能还会把它和混淆矩阵中的召回率(recall)搞混,其实他们并没有什么关系。推荐系统的召回环节,在文献中常见的翻译有两个,一个是match,即匹配,有点相亲的感觉,为用户先挑选一些合适的对象,然后再一个个细聊(排序);另一个是candidate generate,即生成候选集,有点招聘的感觉,为用户先搜罗一堆简历,然后再一个个面试(排序);从英文的翻译里,我们大概就能觉察出这个词的含义了,就是为了能在进行一个精细化的比较以前,在更广的范围里进行初筛的一个过程,我们称之为召回环节,通常在电商的场景下,我们需要从上千万的商品中,召回几千或者几万个目标,是真正的万里挑一。
在推荐系统的技术演进中,扮演着主力核心角色的是排序环节,也是算法工程师们发力最多的地方,关于推荐系统是如何做排序的,感兴趣的同学可以看笔者的另一篇文章,我们今天的主角是扮演着辅助地位的召回环节,这里面也同样涉及到大量的算法知识。接下来,我们再从最原始的视角出发,来看一看这个领域近二十年以来的技术发展历程。
直觉的重要性
直觉是解决问题的第一步。召回作为一个初步筛选过程,我们的目标是尽可能快的定位到一些用户可能感兴趣的商品。还是以招聘来举例子,面对成千上万封的简历,HR也很难一一细看,这个时候,为了节省时间,往往就会出现一些硬性的门槛,比如985/211的学历,或者硕士研究生以上,或者大厂经历之类的,以筛出一部分的“优秀”简历,再一一细审,虽然可能部分“潜力股”的好苗子就这样漏掉了,但这对于公司来说,这样节省时间而且通常也保证了候选人质量。说回我们的推荐系统,在做商品召回时,我们自然而然地便想到了,何不也给商品设置一些门槛,然后符合条件的再排序呢?这便有了最初的召回思路:属性倒排。离线的过程中,根据商品属性,比如销量、新鲜度、点击率、收藏率等一系列指标,每一路指标总能排出个先后高低来,然后每个指标下取前K个商品作为属性的召回列表存储在数据库中,线上用户访问时,直接对某些属性进行召回,从而达到了快速且高质量的目的,剩下的工作便交给了排序环节。
这样简单高效的召回方式是非常符合直觉的,但是作为一个推荐系统工程师,不能仅仅满足于普通的直觉,我们要看到这种做法的不足之处:
1. 召回覆盖率太低。召回仅仅照顾到了各个属性的头部商品,而召回作为排序的上游,返回的结果已经限制了后续可能展示的上限,作为一个电商平台,整个推荐流中只能展示极少数的头部商品,这个问题是致命的。
2. 召回没有个性化。对于每个用户,待排序商品都是完全一样的,排序模型做的再好,发挥的空间也是极其有限的,用户看到的很有可能都是同一批商品。
为了解决这些问题,我们需要对召回方案进行第一次革命。
矩阵革命
寻找合适的数学模型是解决问题的第二步,一个领域的革命,通常和引入数学模型来描述问题是分不开的,这次我们把目光投向了一个熟悉的概念——矩阵。为什么是矩阵?让我们先来看一个小故事:
这个故事发生于20世纪90年代的美国超市中,超市管理人员分析销售数据时发现了一个令人难于理解的现象:在某些特定的情况下,“啤酒”与“尿布”两件看上去毫无关系的商品会经常出现在同一个购物篮中,经过后续调查发现,这种现象出现在年轻的父亲身上,父亲在外出给孩子买尿布时会顺便给自己买一些啤酒。
故事讲完了,这和召回以及矩阵又有什么联系呢?故事中反应出来一个问题:两件看似不相关的商品会被人的行为联系起来,商品与商品之间可以产生“行为相关”(两个商品被同一人买过),而人与人之间也可以产生“商品相关”(两个人买过相似的商品组合),利用这种相关关系,我们产生了一个很棒的想法:在做召回时,可以给某一用户召回与他相似的用户曾经买过(但他还没有买)的商品,或者给他召回他刚买过的某商品(比如尿布)行为相关的其他商品(比如啤酒)。那如何实现这个想法呢?当我们画出一个记录表,纵向罗列出n个用户,横向罗列出m个商品,在纵横交错的地方记录下用户与商品的互动记录(0,1,2,3…),得到一个nxm的表格,这便是矩阵,我们把它称为邻接矩阵,基于这个矩阵所构建出来的推荐策略,便发展成了早期推荐场景最著名的模型:协同过滤(Collaborative Filtering,简称CF)。接下来让我们进入数学的世界,来看一看矩阵是如何解决推荐问题的。
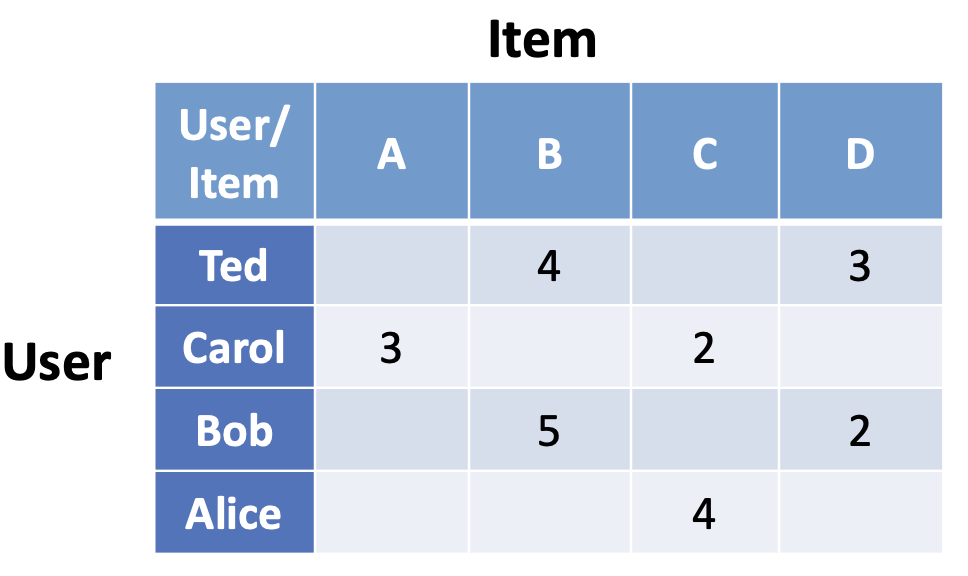
图2. 邻接矩阵示意图
数学中,我们需要把抽象的概念具像化,定性的分析定量化。我们刚才提到的“相似”、“相关”的概念,映射到数学中需要具体的公式来描述,这个时候我们注意到了我们所构建的矩阵。矩阵是向量的二维拓展,同一个邻接矩阵W可以有两种方式描述:
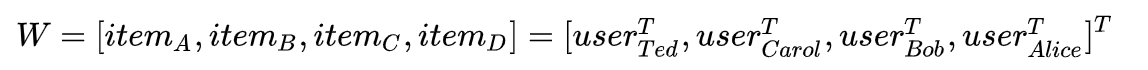
从这个关系里我们发现,无论是物品还是用户,都可以用一个固定维度的向量来表示,而要度量他们之间的“相似”或者“相关”关系,很自然的就会想到用向量之间的距离来定量描述,计算向量间距离常见的方式有Jaccard距离,欧几里得距离,余弦相似度或者曼哈顿距离等,具体就不一一介绍。还有一件有趣的事情是,这里向量的维度似乎是依赖于用户数量和商品数量的,并且商品向量和用户向量维度并不一定相同,无法放在同一空间中进行度量,有没有一种方案能够人工定义向量的维度呢?数学里给出的最简单的方式叫做矩阵分解:
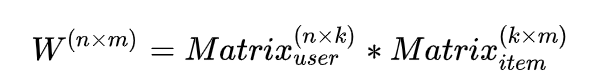
参数k可以人工定义出来,如下图:
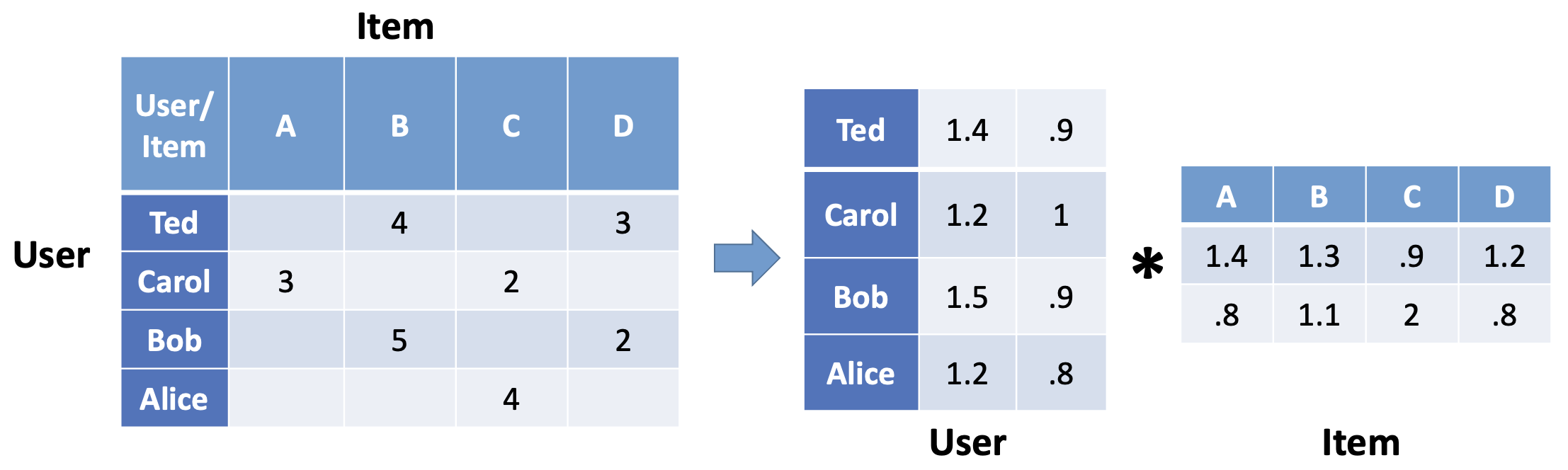
图3. 邻接矩阵分解示意图
这样,我们就实现了,商品和用户的向量化表示,并且我们成功地度量了商品与商品、用户与用户的相关关系,再转化到同一维度k后,我们甚至能够直接计算出商品和用户之间的距离关系。以此延伸出来的方法有item_cf,user_cf, model_based_cf 分别对应我们上面提到的为顾客推荐已购商品的相似商品,相似用户的已购商品,以及直接计算和用户距离近的商品。整个思路清晰自然,也成功用数学描述了推荐问题,在工程上提前离线计算好相关关系,线上推断时根据用户个性化的行为直接从对应索引中取相似推荐结果召回,这便是至今仍被广泛使用的协同过滤的召回策略,它比较有效地解决了之前提到的腰部尾部商品的召回问题和用户个性化召回的问题,在这个思路上近些年也有许多改进和沿伸的算法,比如基于图结构相似度的swing算法等,这里就不详细介绍了,总的而言,这一类型方法的核心思路就是对用户和商品间的行为互动关系进行充分的挖掘,然后定量计算出他们的相关度。
深度学习
结合具体业务场景的深入思考,是解决问题的第三步。协同过滤给了我们巨大的启发:用户和商品这种抽象的概念,是可以用具体的向量来表示的!再仔细回想上面的步骤,这个向量是怎样产生的?可以观察到它仅仅用到了用户与商品的历史互动行为数据,如果是一位全新的用户,或者是全新的商品,并没有参与过交易上的互动(在推荐中被称为冷启动问题),那么这个向量还存在吗?或者说是不是应该有一套其他的方案来定义这个向量呢?答案是肯定的,首先除了互动数据以外,显然还有很多信息是有价值的,比如用户的性别、年龄段和手机设备型号等;商品的类目、品牌、颜色和奢侈度等级等;这些信息被称为side information或者content features,是对主体(用户或者商品)的某一属性的描述,而对这些信息进行向量化编码,可以大大提高向量使用的适用范围,解决冷启动问题。其次对于大量信息的编码问题,在深度学习出现以后,特别是谷歌在自然语言处理中提出了词嵌入(Embedding)的概念之后,已经是深度学习领域非常热点的问题了,我们可以统称为Embedding问题。所谓的Embedding技术,用一句话介绍,就是将世间的万事万物,从人到物,从具体到抽象的所有概念,都可以放在一个固定的向量空间,用数学进行描述的方法。再往深入的说就到哲学了,我们就此打住,知道深度学习的方案可以实现信息的向量化就可以了。顺便一提,我们上面提到的矩阵分解技术,当初在学界被称为“隐向量”表示,也是Embedding方案中的一种,Embedding并不仅仅存在于深度学习之中。
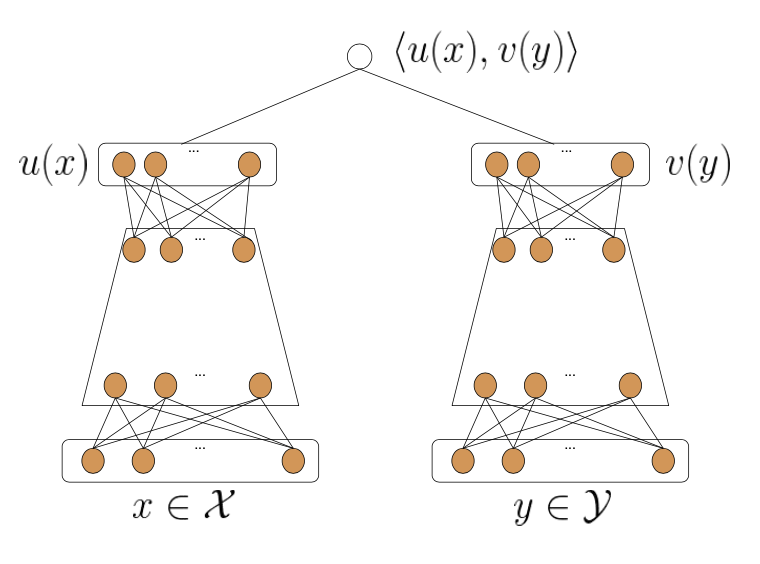
图4. 双塔结构示意图(引自论文Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations)
结合深度学习的embedding技术加上我们推荐场景中具体的人与物的关系,再加上自然语言处理中有类似的先例(处理query与document关系的DSSM模型),推荐中自然地引入了一种被称为“双塔”的模型结构,它大致如图所示。从图中我们可以理解到“双塔”这个名字的由来,两边都是一个塔状的结构,左边是用户塔右边是商品塔,塔底是我们输入的信息,通常是Id+side information。长度不受限制;塔顶是两个固定维度的向量,分别代表embedding后的结果,为了在同一空间中进行计算,两个塔顶的向量维度是相同的,并在最顶端做交互计算相似度。为了学习这个网络结构,通常会以业务场景中的正负样本事件(点击、收藏、购买)来做为有监督分类模型学习的目标,用计算出的相似度去逼近拟合这个目标。
在模型训练完成之后,我们就可以把两个塔的计算图单独拆开来使用:离线定时任务中,提前将商品库中所有商品输入右塔来生成对应的item embedding向量;在线上推断时,把左塔部署在线上服务器中,即时地根据用户信息去生产对应的user embedding向量,再用邻近距离检索的方式,从商品向量中检索出距离最近的N条商品,作为召回结果参与排序,这便如今业界主流的深度双塔召回方案的大致模型。这之中可能会有读者好奇,如果商品量巨大(比如上百万),线上推断时能在很短是时间内完成距离的邻近检索吗?这个答案是可以的,10ms内可以从百万级商品中召回300个最邻近的向量,至于是如何做到的,笔者会在未来的博客中做更详尽的介绍。
一些新的动向
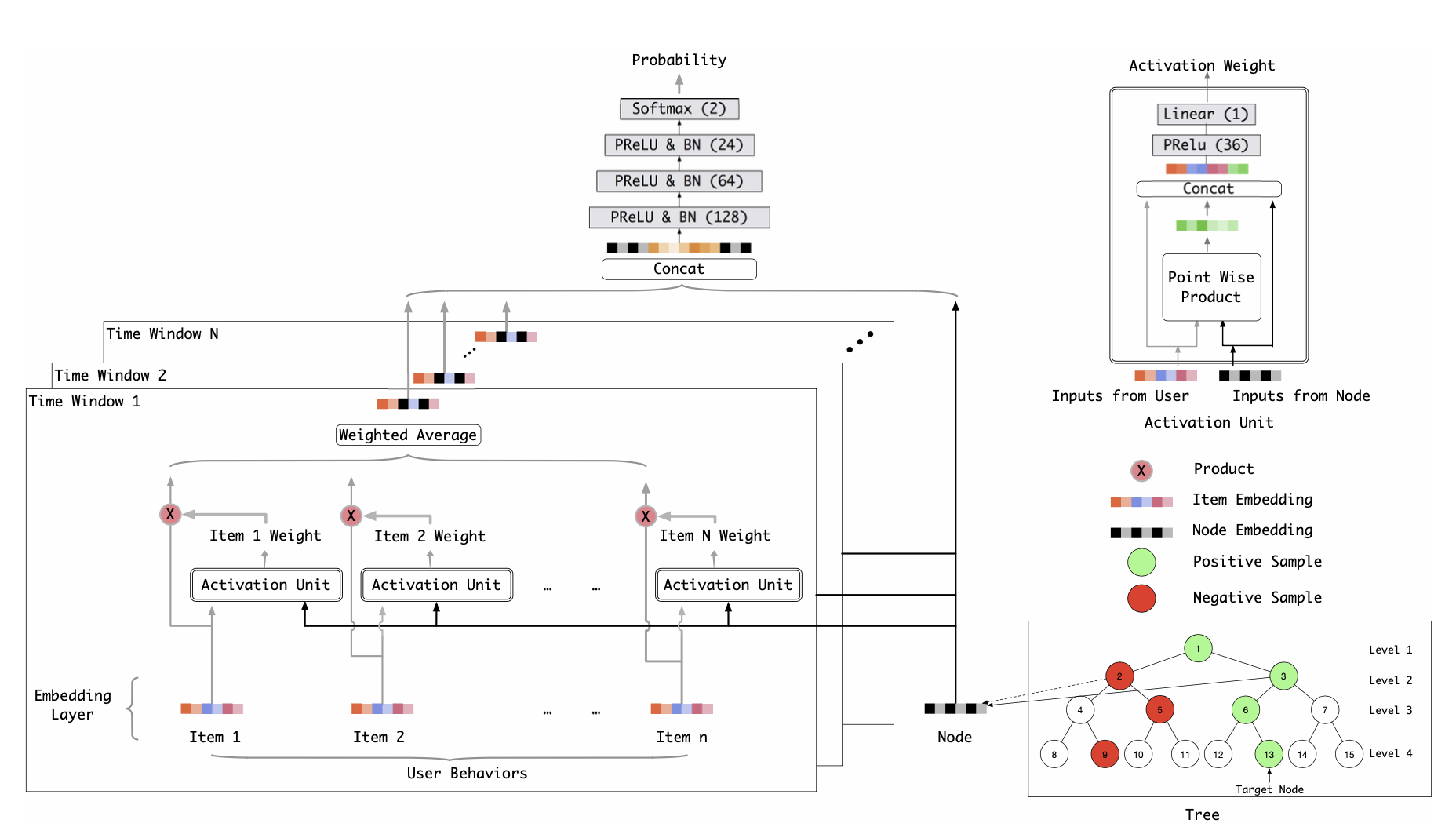
图5. 阿里巴巴TDM模型示意图
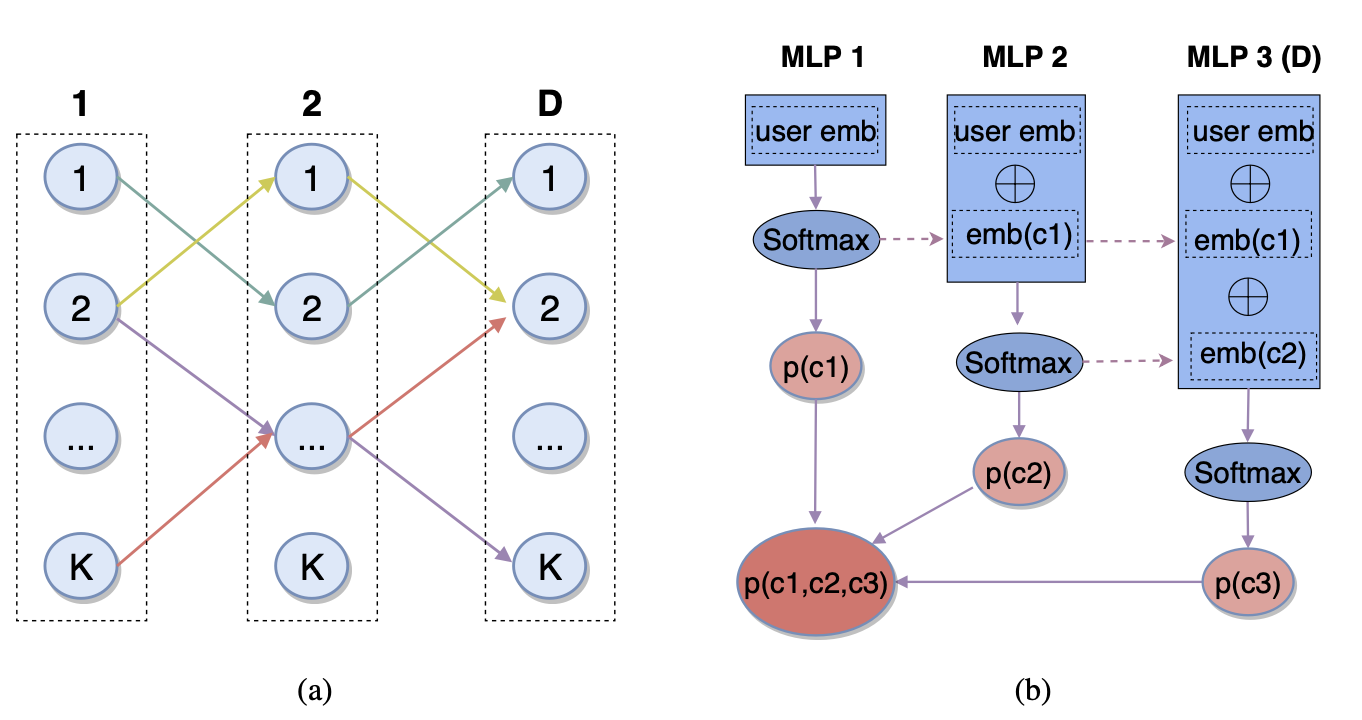
图6. 字节跳动Deep Retrieval模型示意图
讲到这里,我们对召回方案的发展也了解的差不多了,在双塔结构之后,学界也一直在探索着一些其他的可能性。双塔本身存在一些局限性,一是用户向量只有一个,结果是通过邻近搜索得到的,最终的召回结果会是以用户为中心点的一个球状簇中,这就会损失掉一些多样性;二是用户与商品间的交互关系过于简单,距离度量的方式并不能表达很多高阶的复杂关系。关于第一个问题,工业界暂时使用多路召回的方式进行修正,第二个问题有一些大厂已经在模型侧提出了一些新颖的解决思路,比如阿里巴巴在18年提出的TDM模型,用复杂模型+最大兴趣堆的数据结构,探索了树模型在召回中应用的可能性,并在阿里巴巴中实际落地;字节跳动也在20年的会议论文中提出了一种叫做Deep Retrieval 的方案来讨论召回的新思路。相信召回这个领域在近几年内还会有很多新的突破和变化。
结语
总而言之,召回作为推荐系统一直依赖的重要环节,自诞生以来不断发生着巨大的变化。它的核心是效率,要在尽可能短的时间内,去兼顾商品的多样性,用户的个性化,结果的实时性等问题。一个终极形态的召回方案,应该是可以取代排序阶段的,直接在召回时就拿出了所有商品的相关度作为排序结果,同时兼顾效率和准确率,但目前来看,这样的方案还比较模糊而遥远,值得学界的学者和工业界的算法工程师们共同去努力探索,一起把这条路走下去。
参考资料
[1] Zhou, Guorui, et al. "Deep interest network for click-through rate prediction." Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018.
[2] Yi, Xinyang, et al. "Sampling-bias-corrected neural modeling for large corpus item recommendations." Proceedings of the 13th ACM Conference on Recommender Systems. 2019.
[3] Zhu, Han, et al. "Learning tree-based deep model for recommender systems." Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018.
[4] Gao, Weihao, et al. "Deep Retrieval: An End-to-End Learnable Structure Model for Large-Scale Recommendations." arXiv preprint arXiv:2007.07203 (2020).
[5] Schafer, J. Ben, et al. "Collaborative filtering recommender systems." The adaptive web. Springer, Berlin, Heidelberg, 2007. 291-324.
文|John
关注得物技术,携手走向技术的云端

