
- 1困惑度PPL (perplexity)_ppl困惑度
- 2Python实现jieba分词
- 3【NLP】自然语言处理学习笔记(三)语音合成_grapheme-to-phoneme
- 4超凡写手:科技的力量,让写作更高效
- 5dockerfile编写
- 6VMware_vmware workstation player 12.5.9官网下载
- 7Ubuntu配置samba_ubuntu samba配置
- 8springboot3.2 整合 mybatis-plus_java.lang.illegalargumentexception: invalid value
- 9(谷歌)浏览器查看后台接口数据返回值
- 10基于BERT模型进行文本处理(Python)_bert模型可以用spyder运行吗
使用纹理对比度检测检测AI生成的图像_ai 对比度
赞
踩
在本篇文章中我们将介绍如何开发一个深度学习模型来检测人工智能生成的图像
大多数用于检测人工智能生成图像的深度学习方法取决于生成图像的方法,或者取决于图像的性质/语义,其中模型只能检测人工智能生成的人、脸、汽车等特定对象。
但是这篇论文“Rich and Poor Texture Contrast: A Simple yet Effective Approach for AI-generated Image Detection”所提出的方法克服了上述问题,适用范围更广。我们将解释这篇论文,以及它是如何解决许多其他检测人工智能生成图像的方法所面临的问题的。
泛化性问题
当我们训练一个模型(如ResNet-50)来检测人工智能生成的图像时,模型会从图像的语义中学习。如果训练一个通过使用真实图像和人工智能生成的不同汽车图像来检测人工智能生成的汽车图像的模型,那么目前的模型只能从该数据中获得有关汽车的信息,而对于其他的物体就无法进行判别
虽然可以在各种对象的数据上进行训练,但当我们尝试这样做时,这种方法慢得多,并且只能够在未见过的数据上给出大约72%的准确率。虽然可以通过更多的训练和更多的数据来提高准确率,但我们不可能找到无穷无尽的数据进行训练。
也就是说目前检测模型的泛化性有很大的问题,为了解决这个问题,论文提出了以下的方法
Smash&Reconstruction
这篇论文提出了一种独特的方法来防止模型从图像的形状(在训练期间)学习人工智能生成的特征。它通过一个名为Smash&Reconstruction的方法来实现这一点。
在该方法将图像分成预定大小的小块,并对它们进行打乱洗牌生成形成新图像。这只是一个简单的解释,因为在形生成模型最终的输入图像之前还有一个额外的步骤。
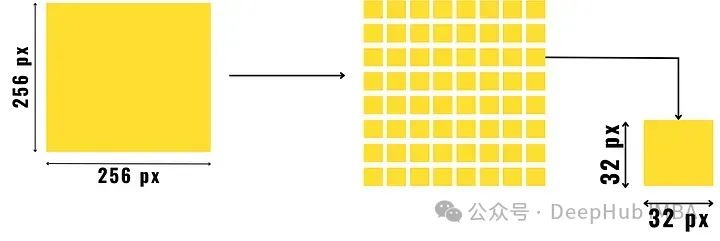
将图像分割成小块后,我们将小块分成两组,一组是纹理丰富的小块,另一组是纹理较差的小块。
图像中细节丰富的区域,如物体或两个对比色区域之间的边界,就成为一个丰富的纹理块。与主要是背景的纹理区域(如天空或静止的水)相比,丰富的纹理区域在像素上有很大的变化。
计算纹理丰富的指标
首先将图像分成预先确定大小的小块,如上图所示。然后找到这些图像块的像素梯度(即找出水平方向、对角线方向和反对角线方向上的像素值之差并将它们相加),并将它们分离成丰富纹理块和纹理较差块。
与纹理较差的块相比,纹理丰富的块具有更高的像素梯度值,计算图像梯度值得公式如下:

在像素对比度的基础上对图像进行分离,得到两幅合成图像。这一过程是本文称之为“Smash&Reconstruction”的完整过程。

这样就让模型学习到得是纹理的细节,而不是物体的内容表征
fingerprint
大多数基于指纹的方法受到图像生成技术的限制,这些模型/算法只能检测由特定方法/类似方法(如扩散、GAN或其他基于CNN的图像生成方法)生成的图像。
为了精确地解决这个问题,论文已经将这些图像块划分为丰富或贫乏的纹理。然后作者又提出了一种识别人工智能生成图像指纹的新方法,这也就是论文的标题。他们提出在应用30个高通滤波器后,找到图像中丰富和贫乏纹理斑块之间的对比度。
丰富和贫乏的纹理块之间的对比度有什么帮助呢?
为了更好理解,我们将图像并排比较,真实图像和人工智能生成的图像。

这两张图像使用肉眼观看也是很难查看他们的去别的对吧
论文首先使用Smash&Reconstruction 过程:


在每个图像上应用30个高通滤波器后,它们之间的对比度:


从这些结果中我们可以看到,人工智能生成的图像与真实图像的对比度相比,纹理斑块丰富和贫乏的对比度要高得多。
这样我们用肉眼就可以看到区别了,所以可以将对比度的结果放入可训练模型,并将结果数据输入分类器,这样就是我们这篇论文的模型架构:

分类器的结构如下:
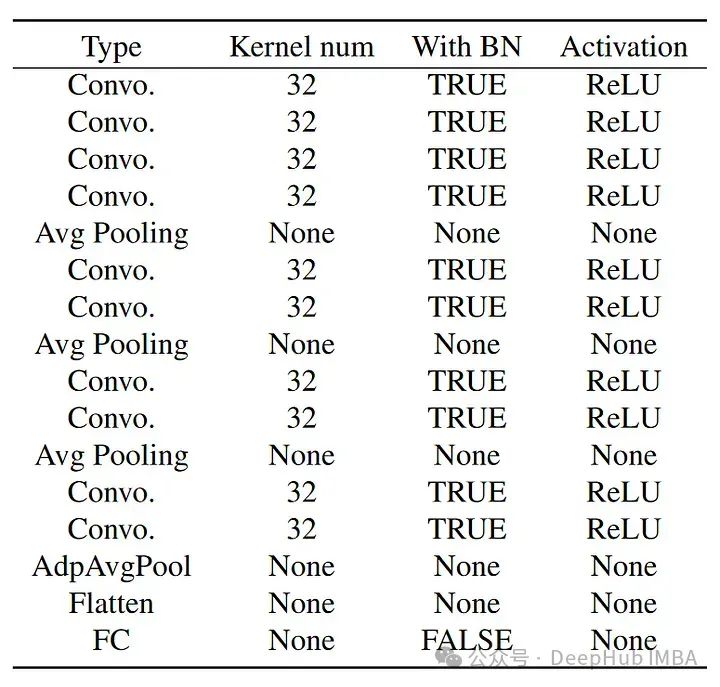
论文中提到了30个高通滤波器,这些滤波器最初是为隐写分析而引入的。
注:
图片隐写的方式有很多种。广义上,只要通过某种方式将信息隐藏到图片中而难以通过普通方式发现,就可以称为图片隐写,对于隐写分析有很多相关的研究,有兴趣的可以查阅相关资料。
这里的过滤器是使用卷积方法应用于图像的矩阵值,所使用的滤波器是高通滤波器,它只允许图像的高频特征通过它。高频特征通常包括边缘、精细细节和强度或颜色的快速变化。

除(f)和(g)外,所有滤波器在重新应用于图像之前都以一定角度旋转,因此总共形成30个滤波器。这些矩阵的旋转是用仿射变换完成的,而仿射变换是用SciPy完成的。
总结
论文的结果已经达到了92%的验证精度,并且据说如果训练的更多还会有更好的结果,这是一个非常有意思的研究,我还找到了训练的代码,有兴趣的可以深入研究:
论文:
https://avoid.overfit.cn/post/3aa6760ae9a9409896683fb17af7f876
作者:Hriday Keswani

