
- 1pytorch nn.Embedding的用法和理解_pytorch里nn.embedding的vocab是多少
- 2“宇宙最强”GPU —— NVIDIA Tesla V100 面向开发者开放试用!_v100pcie3.0
- 3使用GPTQ进行4位LLM量化_gptq 代码
- 4python表达式作为参数_Python中的参数解包:`*`表达式和`**`表达式
- 5最新大模型面经+感受,4家大厂offer!
- 6大创项目推荐 深度学习 python opencv 火焰检测识别
- 7基于uniapp开发 微信小程序登陆页面一_uniapp开发小程序启动进入登录页面
- 8DL之Attention:基于中英文平行语料库和TF NMT工具利用的 ED-Attention模型(神经网络翻译模型(LSTM/Attention))实现将英文翻译为中文设计和训练过程之详细攻略_embeddings 实现翻译
- 9AI的未来:挑战与机遇
- 10初步使用mmdetection3d进行点云目标检测_mmdetection3d可以做3d点云吗
大数据技术之Kafka——Kafka入门_kafka数据
赞
踩
目录
一、概述
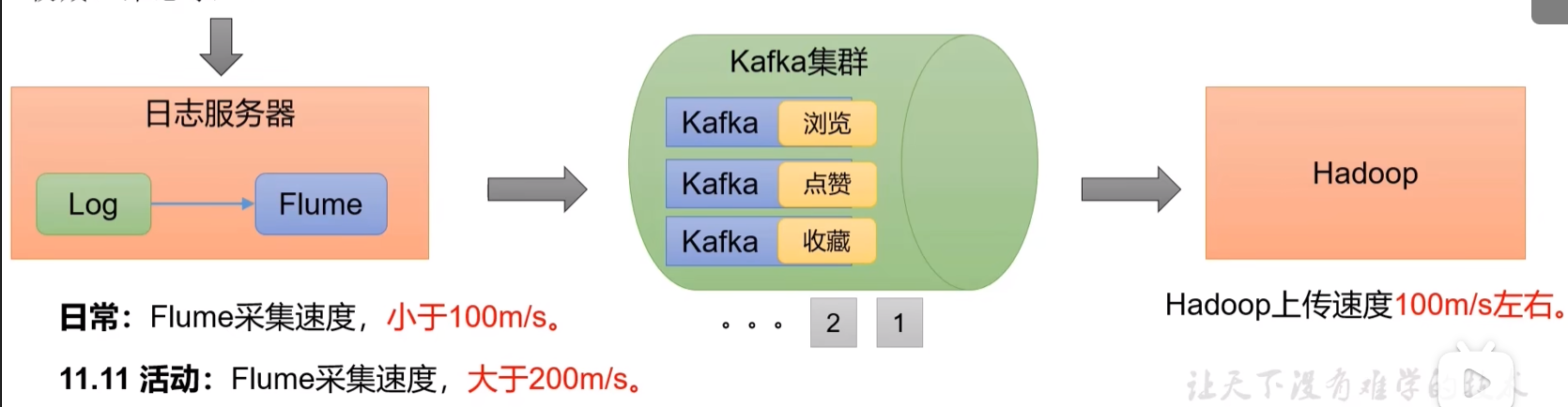
1.1 为什么要有Kafka
如果不使用Kafka,我们每产生一条数据,日志服务器可以通过flume读取,传到Hadoop集群。但是Hadoop的上传速度约100M/s,flume的日常数据采集速度小于100M/s,而当遇到峰值数据时,flume采集速度大于200M/s,这种情况下就无法处理了。于是引入了Kafka。
通过Kafka可以进行缓冲,我们可以将海量的数据先放到Kafka中,Kafka集群按照Hadoop的上传速度进行文件的传输。
1.2 定义
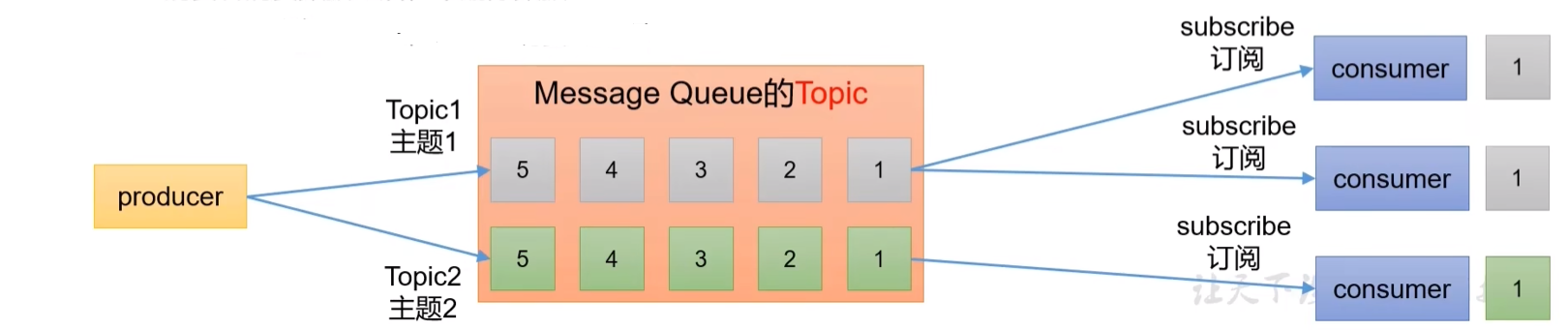
传统定义:Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue)主要应用于大数据实时处理领域。
分布式:多台服务器干一件事。
发布/订阅:消息的发布者不会将消息直接发送给特点的订阅者,而是将发布的消息(数据)分为不同的类型,订阅者只接收感兴趣的消息,根据需求选择性订阅。
最新定义:Kafka是一个开源的分布式事件流平台(Event Streaming Platform)被公司用于高性能数据管道、流分析、数据集成和关键任务应用。
1.3 消息队列
目前常见的消息队列产品主要有Kafka、ActiveMQ、RabbitMQ、RocketMQ等。在大数据场景下主要使用Kafka作为消息队列。
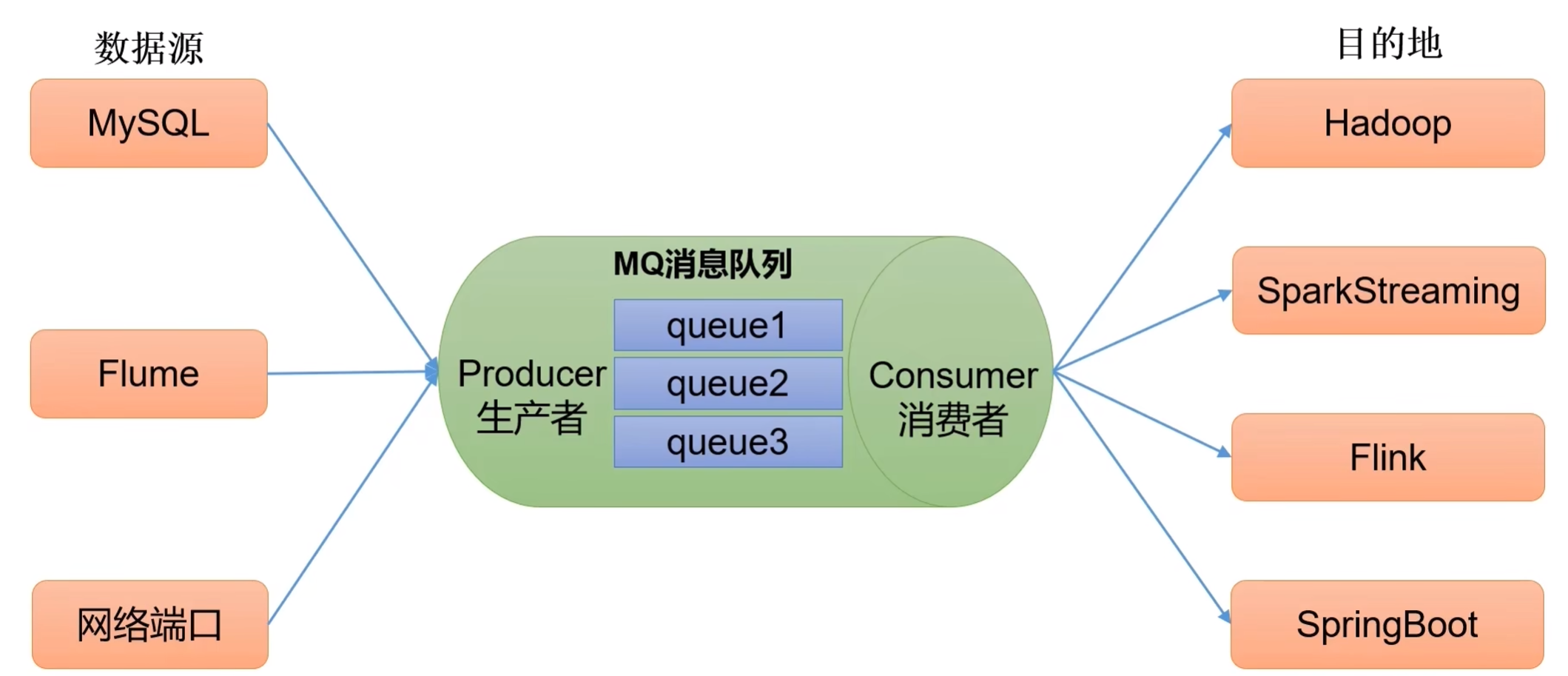
1)消息队列的应用场景
主要应用场景包括:缓存/消峰、解耦、异步通信。
a. 解耦合
耦合:当实现某个功能的时候,直接接入当前接口
解耦合:利用消息队列,将相应的消息发送到消息队列。允许独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。如果接口出现问题,将不会影响到当前的功能
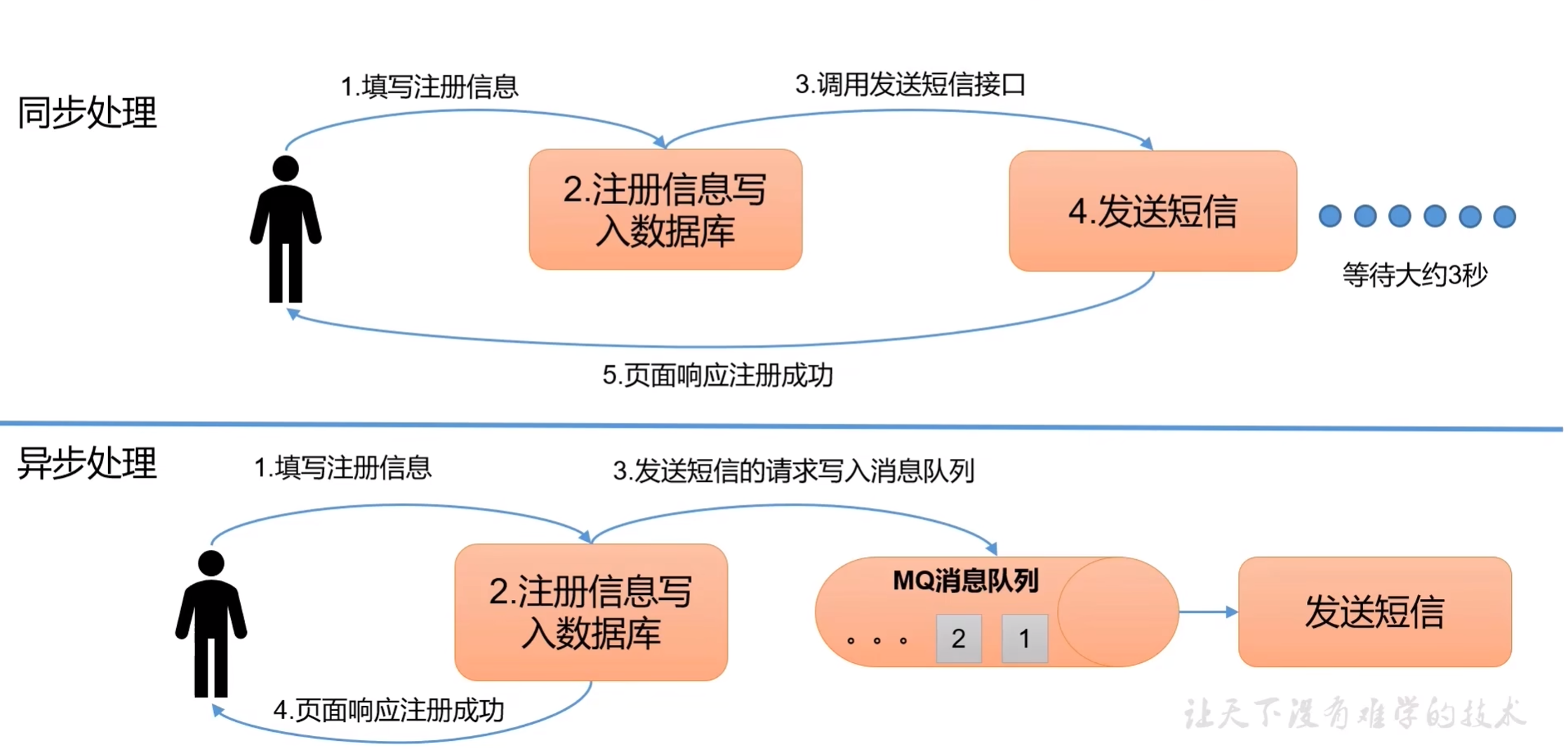
b. 异步处理
允许用户把一个消息放入队列,但不立即处理,在需要的时候再去处理它们。
c. 流量削峰
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。如:高流量的时候,使用消息队列作为中间件可以将流量的高峰保存在消息队列中,从而防止了系统的高请求,减轻服务器的请求处理压力。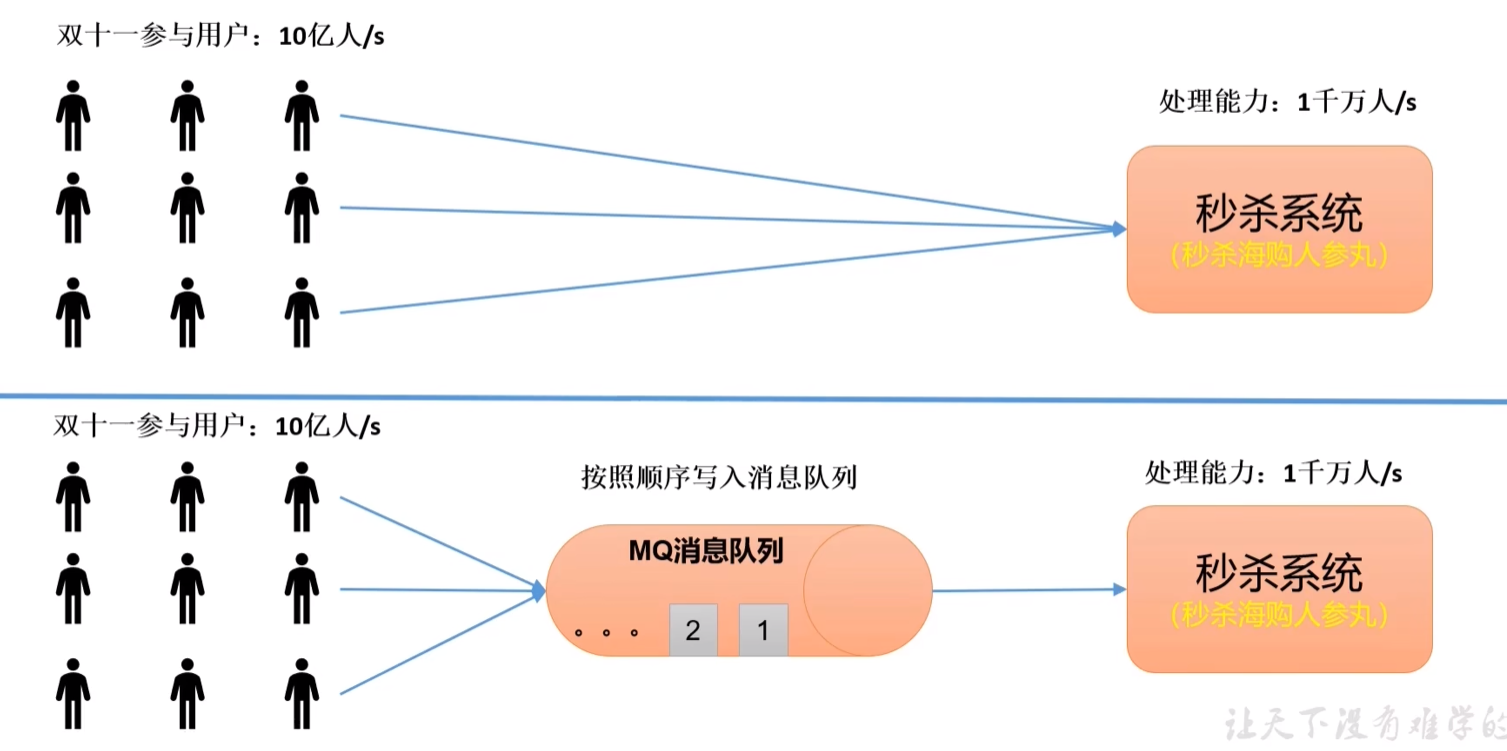
2)消息队列的两种模式
Kafka的消费模式主要有两种:一种是一对一的消费,也即点对点的通信,即一个发送一个接收。第二种为一对多的消费,即一个消息发送到消息队列,消费者根据消息队列的订阅拉取消息消费。
a. 点对点模式
- 一个生产者,一个消费者,一个topic,会删除数据(使用不多)

b. 发布/订阅模式
- 多个生产者,多个消费者,而且相互独立
- 多个topic
- 不会删除数据
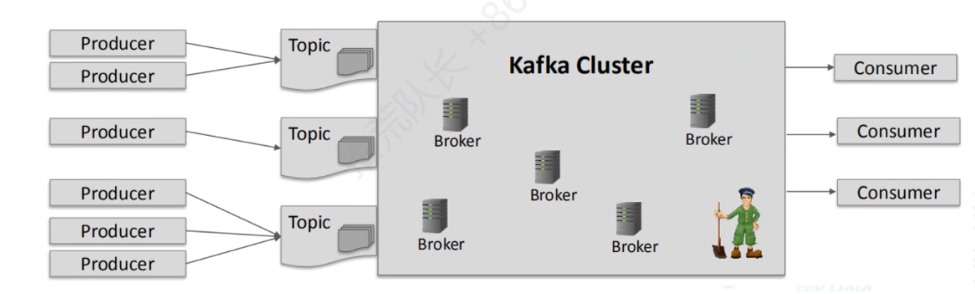
1.4 基础架构
1)生产者:100T数据
2)broker
(1)broker即服务器,如hadoop101/hadoop102/hadoop103
(2)topic主题,对数据分类
(3)分区
(4)可靠性:副本
(5)leader、follower
(6)生产者和消费者只针对leader操作
3)消费者
(1)消费者和消费者相互独立
(2)消费者组(某个分区只能由一个消费者消费)
4)zookeeper
(1)broker.ids 0 1 2
(2)leader
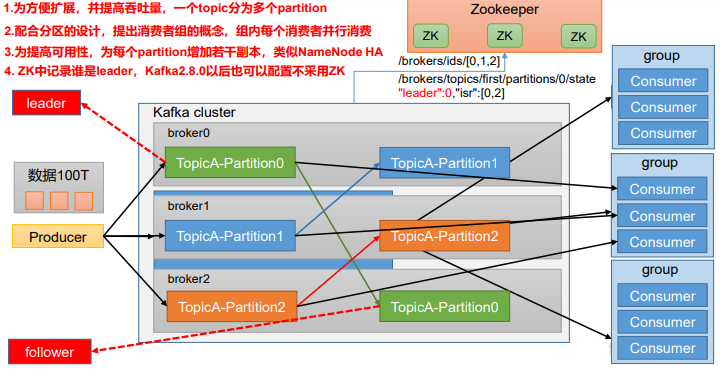
- 为方便扩展,并提高吞吐量,一个topic分为多个partition
- 配合分区的设计,提高消费者组的概念,组内每个消费者并行消费。一个分区内的数据只能由一个消费者来消费。
- 为提高可用性,为每个partition增加若干副本,类似NameNode HA
- ZK中记录leader信息。Kafka2.8.0以后也可以配置不采用ZK
主要功能分为三块:生产者Producer、消费者Consumer、Topic。
生产者Producer:对接外部设备(外部数据)
消费者Consumer:处理数据
Topic:存储数据。
- 当数据量过大时,topicA上的数据无法存储在一台服务器上,所以对其引入分区Partition进行存储,将数据进行切分,存储在不同的服务器上,一个Kafka服务器就是一个broker,一个集群由多个broker组成,一个broker九二一容纳多个topic。
- 数据切分后,从消费者Consumer的角度,也可以按照分区一块一块进行处理,能够提高处理的并发度。需要注意的是,某一个分区当中的数据只能由一个消费者进行消费,否则容易混乱。
- 为了保证分区的可靠性,引入了副本,分为leader和follower。无论生产还是消费,处理对象都只针对leader副本,follower只是一个备份。等leader挂掉之后,follower才有条件称为新的leader。zk来充当存储kafka集群上下线信息,在线节点信息,每一个分区下的leader副本信息。
二、Producer生产者
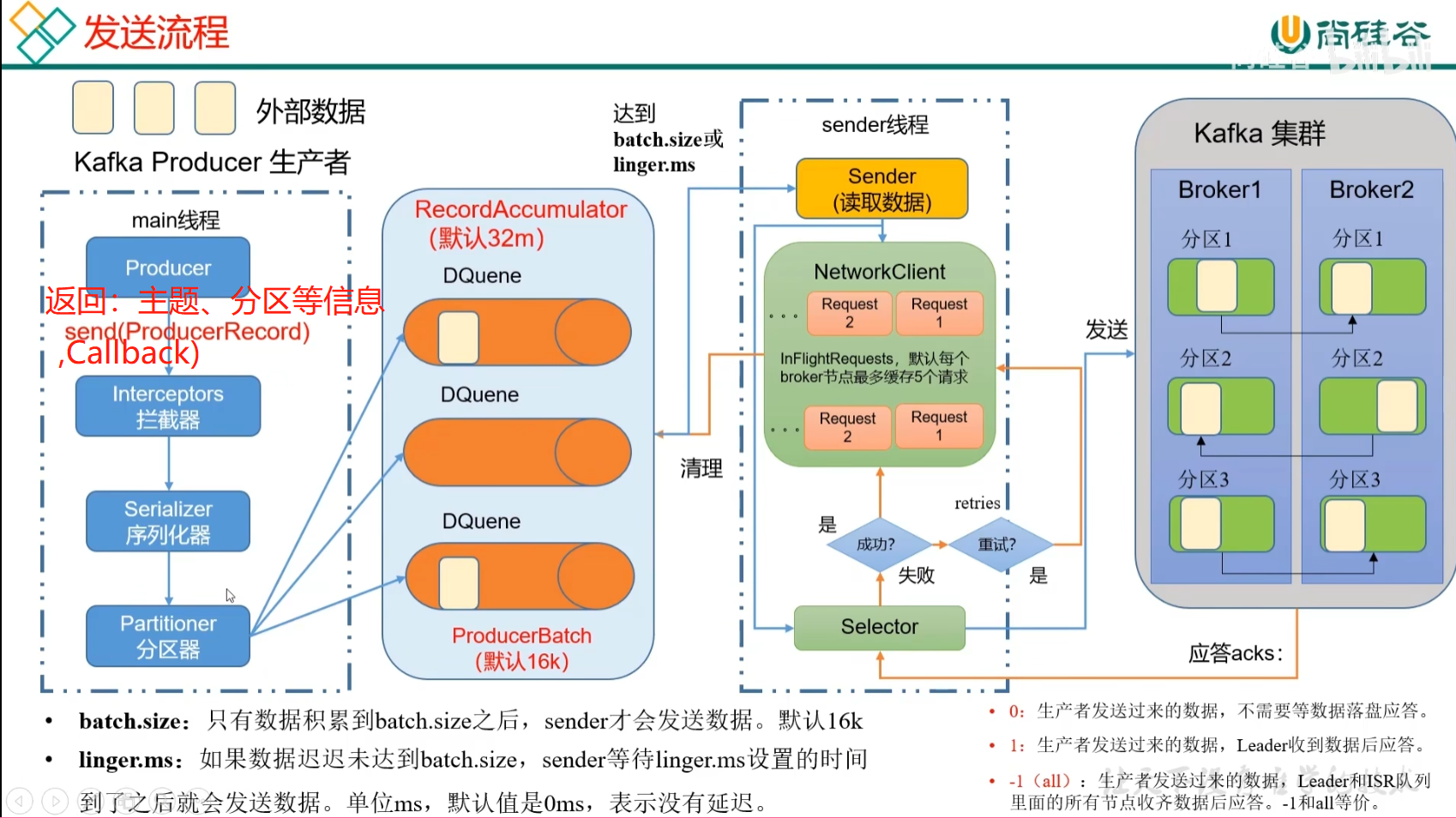
2.1 生产者消息发送流程
2.1.1 发送原理
在消息发送的过程中,涉及到了两个线程——main线程和sender线程。在main线程中创建了一个双端队列RecordAccumulator。main线程将消息发送给RecordAccumulator,Sender线程不断从RecordAccumulator中拉取消息发送到Kafka Broker。
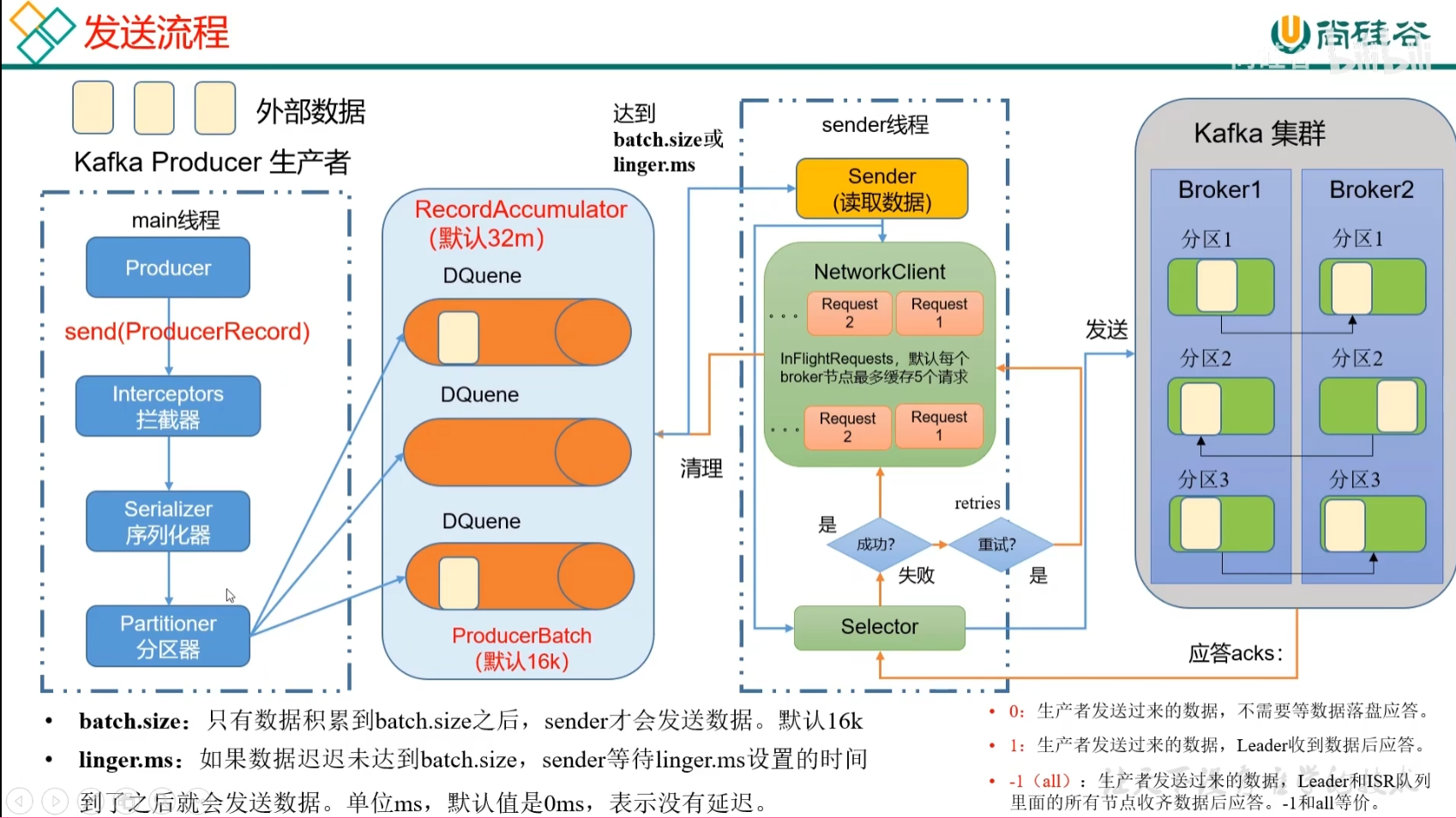
作用:将外部接受的数据传输到Kafka集群
方式:
- main线程
——创建main线程,创建客户端对象Producer
——调用send(ProducerRedord)方法进行发送
——经过拦截器Interceptors(可选项),可以对数据进行加工和操作。一般使用flume的拦截器
——数据继续传输,经过序列化器Serializer
——分区器Partitioner,将海量数据进行切块,决定数据应该发往哪个分区器。一个分区器会创建一个队列,方便数据的管理。
- RecordAccumulator缓冲队列
——RecordAccumulator在内存中创建,缓存队列DQueue大小默认32M
——每一批次的大小16k(batch.size)
- Sender线程
——将缓冲队列中的值读出来之后发往Kafka集群。
——发送数据的条件:
1. 只有数据累积到batch.size之后,sender才会发送数据,默认16k
2. 如果数据迟迟未达到batch.size,sender等待linger.ms设置的时间到了之后就会发送数据。单位ms,默认为0ms,表示没有延迟。
——以每一个broker节点为key,后面跟上请求request,放到一个队列里面进行发送。如果broker1没有及时应答,允许发送第二个请求。最多可以缓存五个请求。
——selector连接底层链路,相当于是高速公路。请求request相当于是汽车。
- 应答ack
应答级别:
0:生产者发送过来的数据,不需要等数据落盘应答。
1:生产者发送过来的数据,Leader收到后应答。
-1(all):生产者大送过来的数据,Leader和ISR队列(可以理解为所有follower)里面的所有节点收齐数据后应答。-1与all等价。
——应答成功,清除掉所有的请求request,同时清理分区的数据。
——应答失败,进行重试。默认重试的次数是输入的最大值。
——为什么Kafka不用Java的序列化器?
Java的序列化传输的数据比较重。大数据场景下传输的数据量由于比较庞大,我们希望校验变得简单。所以使用Kafka自己的序列化器
2.2 异步发送API
2.2.1 普通异步发送
1)同步发送
将外部数据发送到队列DQueue中,第一波数据发送完毕,再发送第二波数据。
2)异步发送
将外部数据发送到队列DQueue中,不管数据是否发送到Kafka集群中。
异步发送API:
- 0)配置
- (1)连接 boorstrap-server
- (2)key value序列化
-
- 1)创建生产者
- kafkaProducer<String, String>()
-
- 2)发送数据
- send() send(,new Callback)
-
- 3)关闭资源
- import org.apache.kafka.clients.producer.ProducerRecord;
- import java.util.Properties;
-
- public class CustomProducer {
- public static void main(String[] args) throws InterruptedException {
- // 1. 创建 kafka 生产者的配置对象
- Properties properties = new Properties();
- // 2. 给 kafka 配置对象添加配置信息:bootstrap.servers
- properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");
-
-
- // key,value 序列化(必须):key.serializer,value.serializer
- properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
-
- properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
-
- // 3. 创建 kafka 生产者对象
- KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
-
- // 4. 调用 send 方法,发送消息
- for (int i = 0; i < 5; i++) {
- kafkaProducer.send(new ProducerRecord<>("first","atguigu " + i));
- }
- // 5. 关闭资源
- kafkaProducer.close();
- }
- }

2.2.2 带回调函数的异步发送
数据发往RecordAccumulator缓冲队列,队列返回发送的主题、所在分区。
- // 添加回调
- kafkaProducer.send(new ProducerRecord<>("first", "atguigu " + i), new Callback() {
2.3 同步发送API
第一批数据正常发送成功之后,发送下一批数据。
异步发送API:
- 0)配置
- (1)连接 boorstrap-server
- (2)key value序列化
-
- 1)创建生产者
- kafkaProducer<String, String>()
-
- 2)发送数据
- send() send(,new Callback).get()
-
- 3)关闭资源
2.4 生产者分区
2.4.1 分区好处
1)存储:便于合理使用存储资源,每个Partition子一个Broker上存储,可以把海量的数据按照分区切割成一块一块数据存储在多态Broker上。合理控制分区的任务,可以实现负载均衡的效果。
2)计算:提高并行度,生产者可以以分区为单位发送数据;消费者可以以分区为单位进行消费数据。
2.4.2 默认分区规则
1)指定分区,按分区进行划分
2)不指定分区,指定key,按key的hashcode值%分区数
3)不指定分区,不指定key,粘性
第一次随机,一旦粘上一个,直到该分区挂掉(批次大小到了,或者响应时间到了)再切换分区。切换的时候还是随机,但是与上一个不相同。
2.4.3 自定义分区
自定义类,实现partitioner接口。
2.5 生产者如何提高吞吐量
- batch.size:批次大小,默认16k
- linger.ms:等待时间默认为0,修改为5-100ms
- compression.type:压缩snappy
- RecordAccumulator:缓冲区大小默认为32M,修改为64m
2.6 生产者提高数据可靠性
2.6.1 ack应答原理
0:生产者发送过来的数据,不需要等数据落盘应答。可能会丢失数据
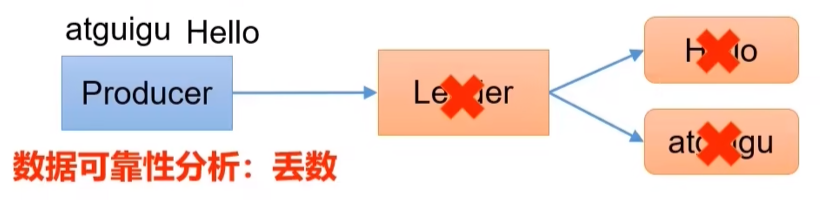
1:生产者发送过来的数据,Leader收到数据后应答。也可能丢失数据
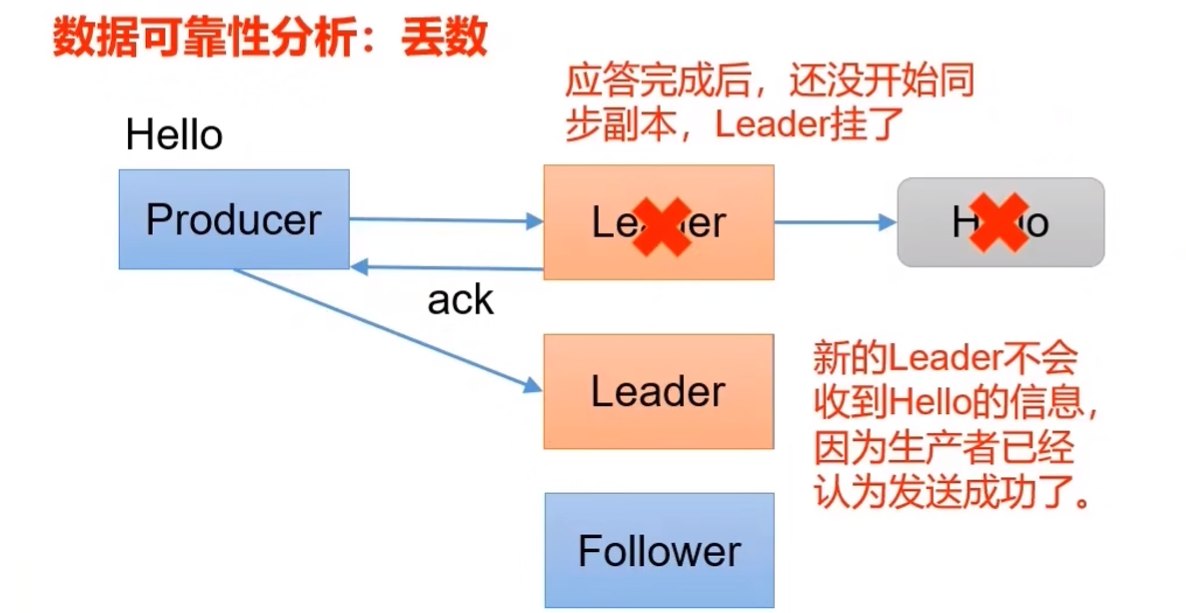
-1(all): 生产者发送过来的数据Leader和ISR队列里面的所有节点收齐数据后应答。完全可靠。
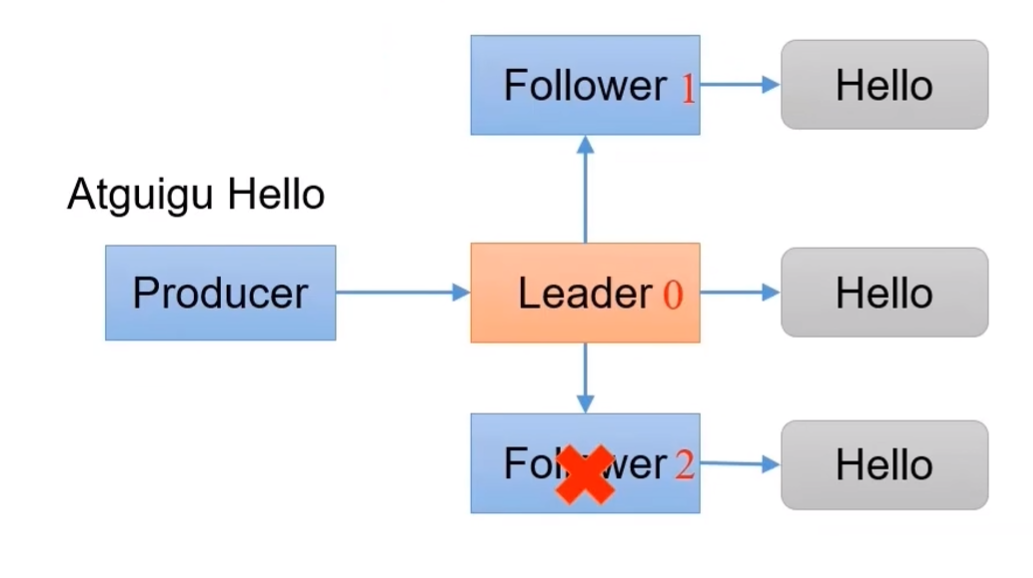
2.6.2 可靠性分析
Leader收到数据,所有Follower都开始同步数据,但如果有一个Follower因为某种故障,迟迟不能与Leader进行同步,此时应该怎么办?
Leader维护了一个动态的in-sync replica set (ISR),即和Leader同步的Follower+Leader集合(Leader:0,isr:0,1,2)。
如果Follower长时间未向Leader发送通信请求或同步数据,则该Follower将被踢出ISR。该时间阈值由replica.lag.time.max.ms参数设定,默认30s。
这样就不用等长期联系不上或者已经故障的节点。
数据可靠性分析:
如果分区副本设置为1个,或者ISR里应答的最小副本数量(默认为1)设置为1,和ack=1的效果是一样的,仍有丢数的风险。
数据完全可靠条件:ACK级别设置为-1 + 分区副本≥2 + ISR里应答的最小副本数量≥2
总结:
acks = 0:生产者发送过来数据就不管了,可靠性差,效率高;
acks = 1:生产者发送过来数据Leader应答,可靠性中等,效率中等;
acks = -1:生产者发送过来数据Leader和ISR队列里面所有Follwer应答,可靠性高,效率低。
生产环境中,acks=0很少使用;acks=1一般用于传输普通日志,允许丢个别数据;acks=-1,一般用于传输和钱相关的数据,对可靠性要求比较高的场景。
2.6.3 数据重复分析
ask=-1:生产者发送过来的数据,Leader和ISR队列里面的所有节点收齐数据后应答。
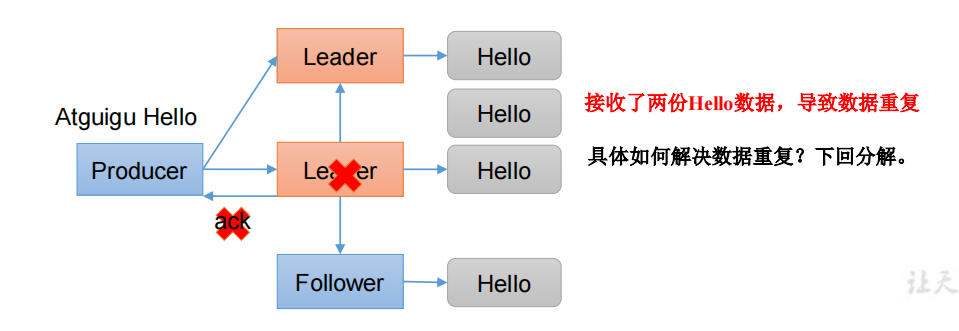
2.7 数据去重
2.7.1 数据传递语义
- 至少一次(At Least Once)= ACK级别设置为-1 + 分区副本≥2 + ISR应答的最小副本数≥2
- 最多一次(At Most Once)= ACK级别设置为0
- 总结:
- At Least Once 可以保证数据不丢失,但是不能保证数据不重复;
- At Most Once 可以保证数据不重复,但是不能保证数据不丢失;
- 精确一次(Exactly Once):对于一些非常重要的信息(如和线相关的数据)要求数据既不能重复也不能丢失。我们引入了特性:幂等性和事务。
2.7.2 幂等性
1)定义:
幂等性就是Producer不管向Broker发送多少次重复数据,Broker都只会持久化一条,保证了不重复。
精确一次(Exactly Once):
幂等性 + 至少一次(ack=-1 + 分区副本数≥2 + ISR最小副本数 ≥2)
重复数据的判断标准:具有<PID,Partition,SeqNumber>相同主键的消息提交时,Broker只会持久化一条。
- PID:Kafka每次重启都会分配一个新的
- Partition:分区号
- Sequence Number:单调自增的
局限性:幂等性只能保证 【单分区、单会话】 内不重复。
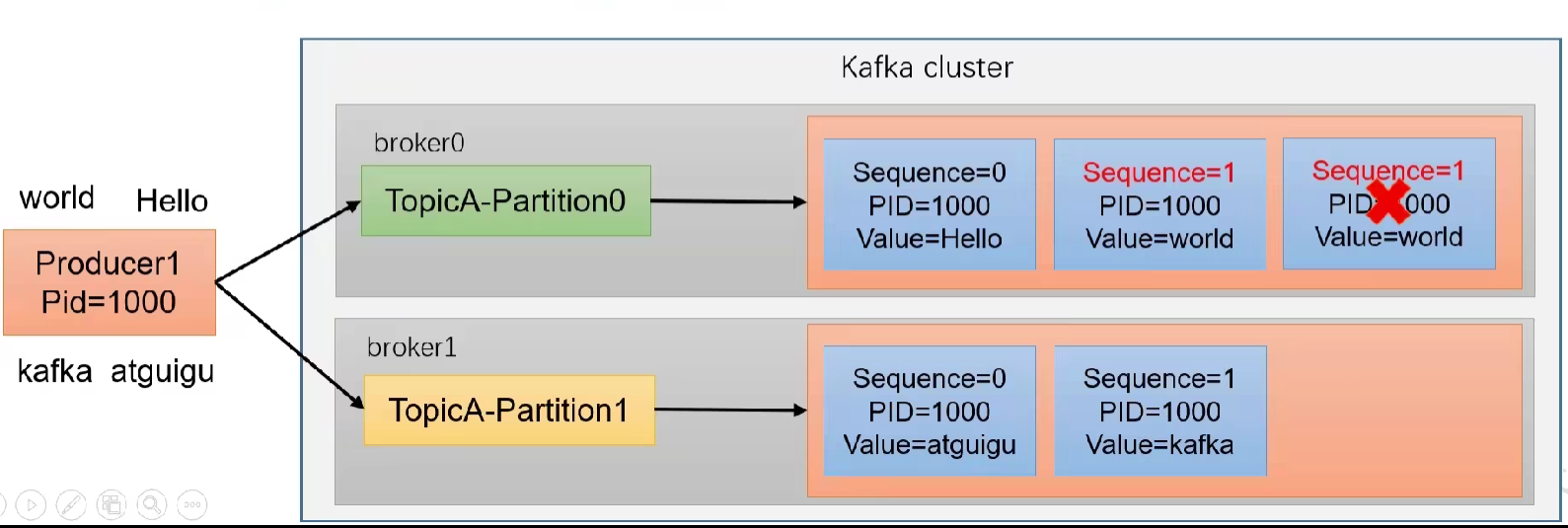
2)使用
开启参数enable.idempotence默认为true,false关闭。默认打开
2.7.3 生产者事务
说明:开启事务,必须开启幂等性。
定义:保证原子性的写入到多个分区。写入到多个分区的消息要么全部成功,要么全部回滚。
Kafka事务「原理剖析」 - 昔久 - 博客园 (cnblogs.com)
2.8 数据有序
我们希望生产者发送的数据是有序的,消费者消费到的数据仍然是有序的。
单分区内有序(有条件),多分区,分区与分区间无序。
2.9 数据乱序
1)1.x版本之前:in.flight = 1
2)1.x版本之后:
(1)未开启幂等性:in.flight = 1
(2)开启幂等性:in.flight ≤ 5
max.in.flight.requests.per.connection
该参数指定了生产者在收到服务器响应之前可以发送多少个消息。它的值越高,就会占用越多的内存,不过也会提升吞吐量。把它设为 1 可以保证消息是按照发送的顺序写入服务器的,即使发生了重试。

2.10 生产者核心参数配置
| 参数名称 | 描述 |
|---|---|
| bootstrap.servers | 生产者连接集群所需的broker地址清单。 如:hadoop101:9092,hadoop102:9092 |
| key.serializer和value.serializer | 指定发送消息的key和value序列化类型 |
| buffer.memory |
RecordAccumulator 缓冲区总大小,
默认 32m。
|
| batch.size |
缓冲区一批数据最大值,
默认 16k。适当增加该值,可以提高吞吐量,但是如果该值设置太大,会导致数据传输延迟增加。
|
| linger.ms |
如果数据迟迟未达到 batch.size,sender 等待 linger.time之后就会发送数据。单位 ms,
默认值是 0ms,表示没有延迟。生产环境建议该值大小为 5-100ms 之间。
|
| acks |
0:生产者发送过来的数据,不需要等数据落盘应答。
1:生产者发送过来的数据,Leader 收到数据后应答。
-1(all):生产者发送过来的数据,Leader+和 isr 队列里面所有节点收齐数据后应答。
默认值是-1,-1 和 all
是等价的。
|
| max.in.flight.requests.per.connection |
允许最多没有返回 ack 的次数,
默认为 5,开启幂等性要保证该值是 1-5 的数字。
|
| retries |
当消息发送出现错误的时候,系统会重发消息。
retries 表示重试次数。
默认是 int 最大值,2147483647。
如果设置了重试,还想保证消息的有序性,需要设置 MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION=1
否则在重试此失败消息的时候,其他的消息可能发送成功了
|
| retry.backoff.ms |
两次重试之间的时间间隔,默认是 100ms。
|
| enable.idempotence |
是否开启幂等性,
默认 true,开启幂等性。
|
| compression.type |
生产者发送的所有数据的压缩方式。默认是
none,也就是不压缩。
支持压缩类型:none、gzip、snappy、lz4 和 zstd。
|
三、Broker
3.1 zk中存储的Kafka信息
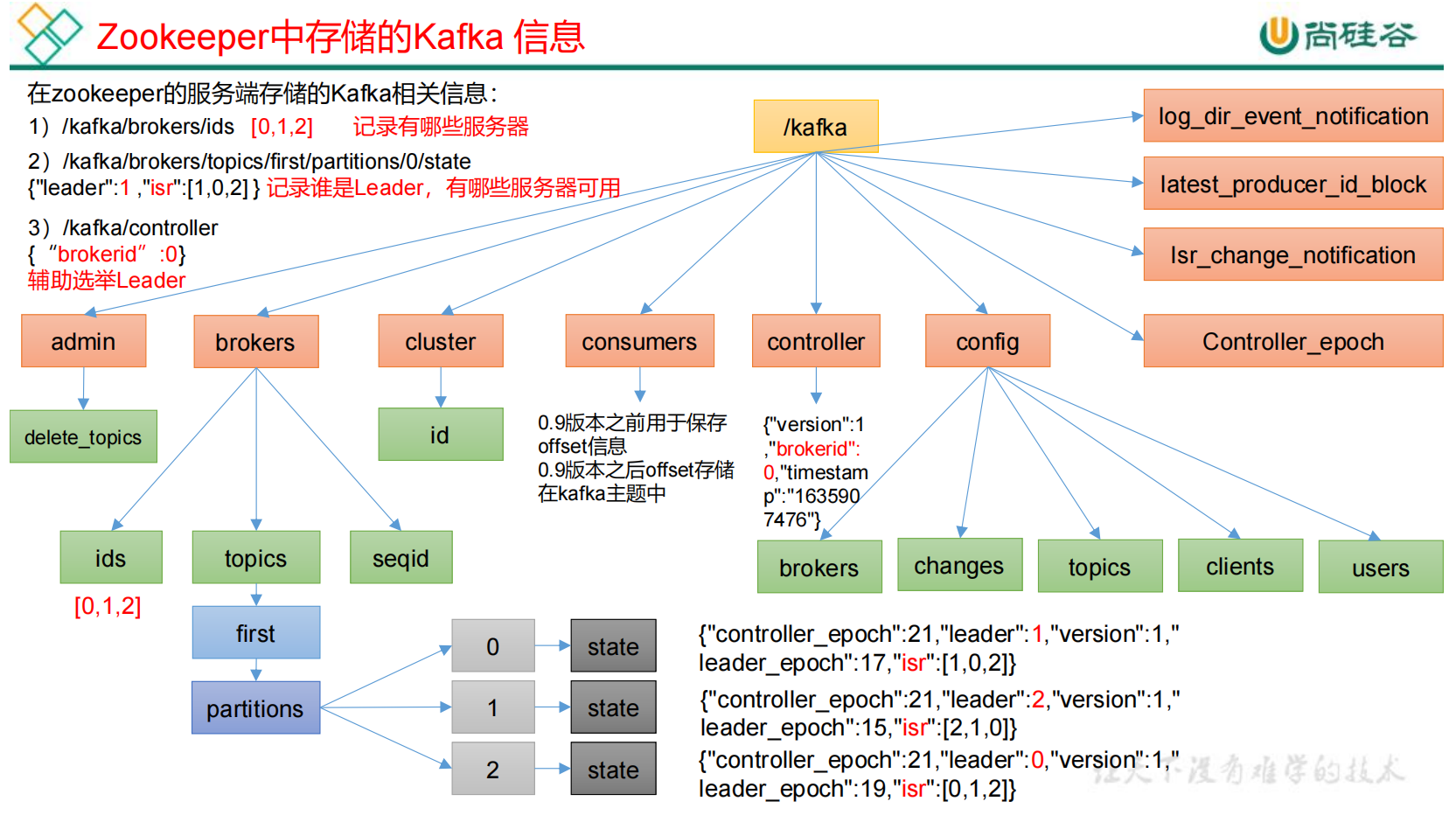
1)ids:有哪些服务器(brokers)正常上线工作。
2)state:每一个主题topic下面的分区partition对应的leader和isr是谁。
3)controller:辅助leader选举。
3.2 Broker工作流程
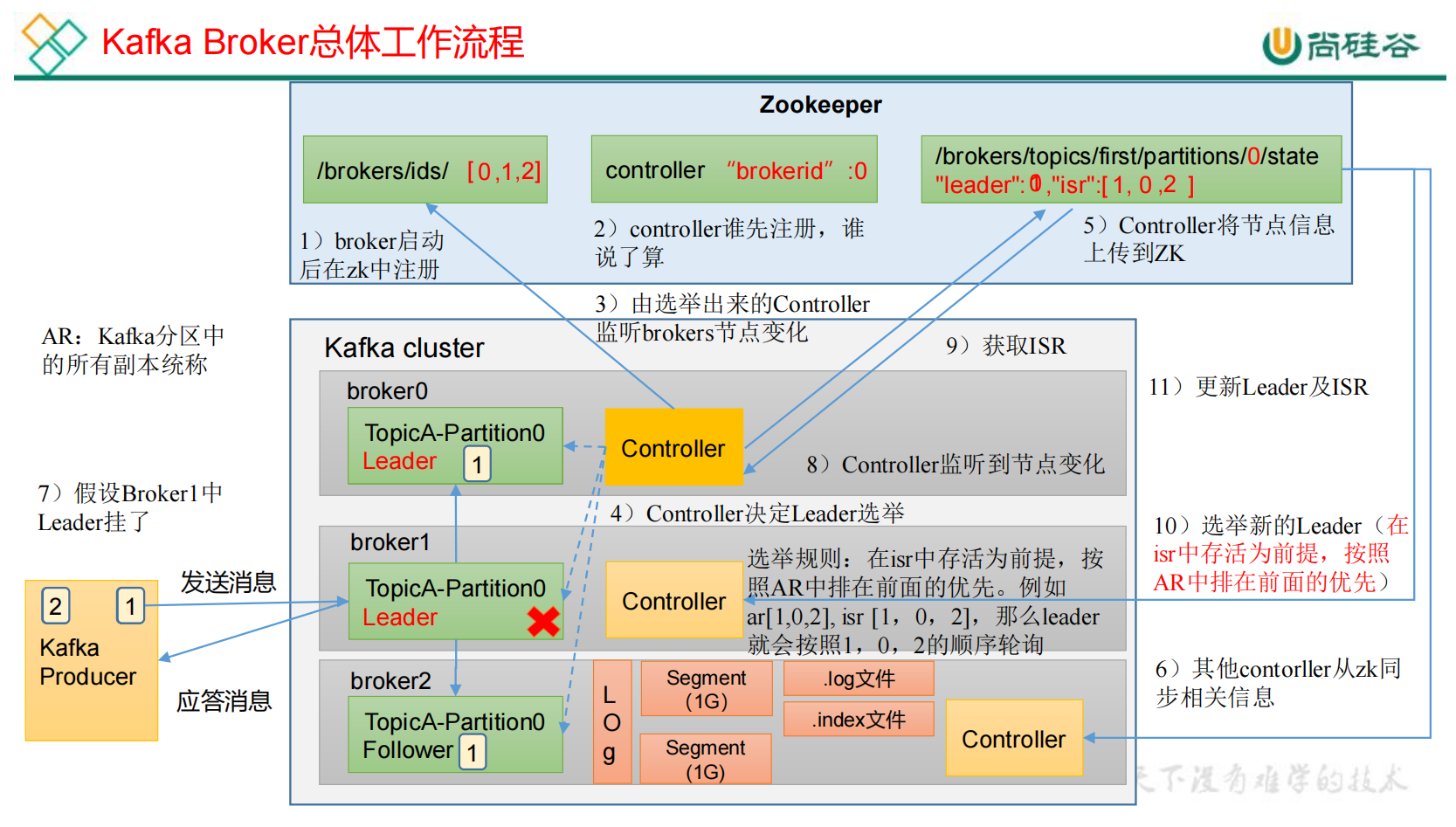
1)每台broker节点启动之后,都会向zk注册, 增加对应节点。
2)注册完成之后选择controller节点,每个broker上都有一个对应的controller。controller争先抢占注册节点,谁先抢到,谁负责leader选举。
3)选举出来的controller监听brokers节点变化。
4)controller决定leader选举:在isr中存活为前提,按照AR中(AR启动的时候会有固定的顺序)排在前面的优先。
5)controller不存储数据,会将leader信息和isr信息上传到ZK。
6)其他controller从zk同步相关数据。
3.3 Kafka副本Follower
3.3.1 Kafka副本基本信息
ISR(In-Sync replicas),表示和 Leader 保持同步的 Follower 集合。如果 Follower 长时间(30s)未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值由 replica.lag.time.max.ms参数设定,默认 30s。Leader 发生故障之后,就会从 ISR 中选举新的 Leader。
OSR(Out-Sync replicas),表示 Follower 与 Leader 副本同步时,延迟过多的副本。
3.3.2 Leader选举流程
1)查看leader分布情况:
2)停止掉 hadoop105 的 kafka 进程,并查看 Leader 分区情况:
3)停止掉 hadoop104 的 kafka 进程,并查看 Leader 分区情况:
4)启动 hadoop105 的 kafka 进程,并查看 Leader 分区情况:
5)启动 hadoop104 的 kafka 进程,并查看 Leader 分区情况:
6)停止掉 hadoop103 的 kafka 进程,并查看 Leader 分区情况:
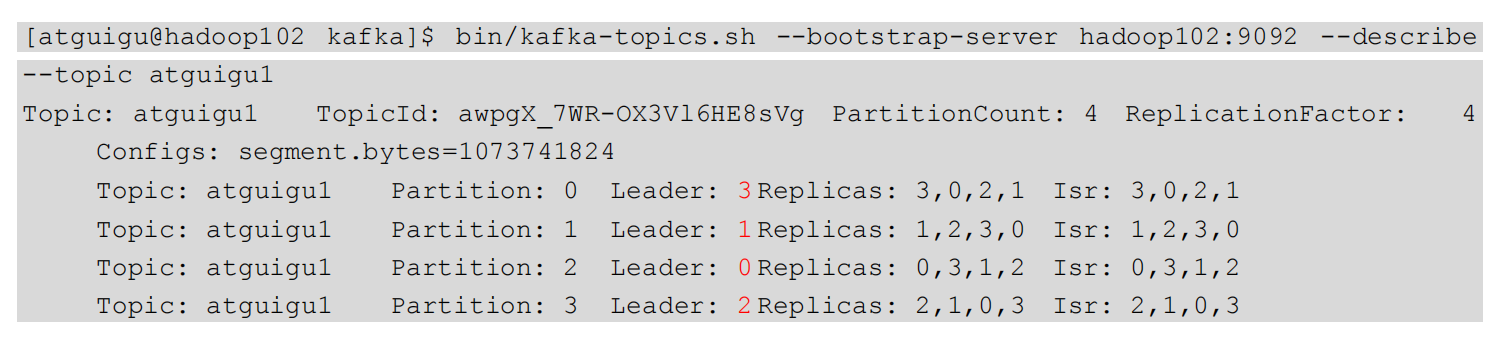
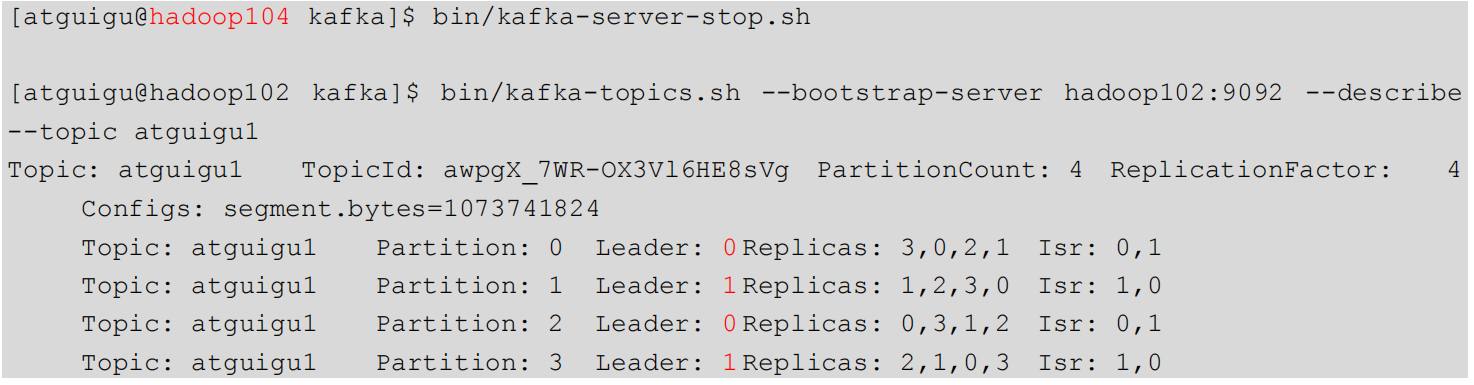
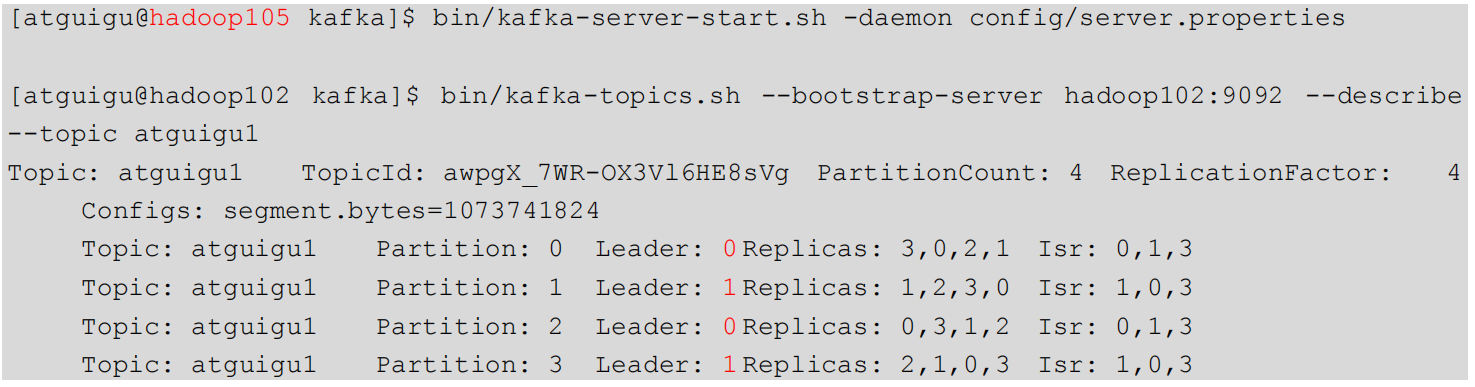
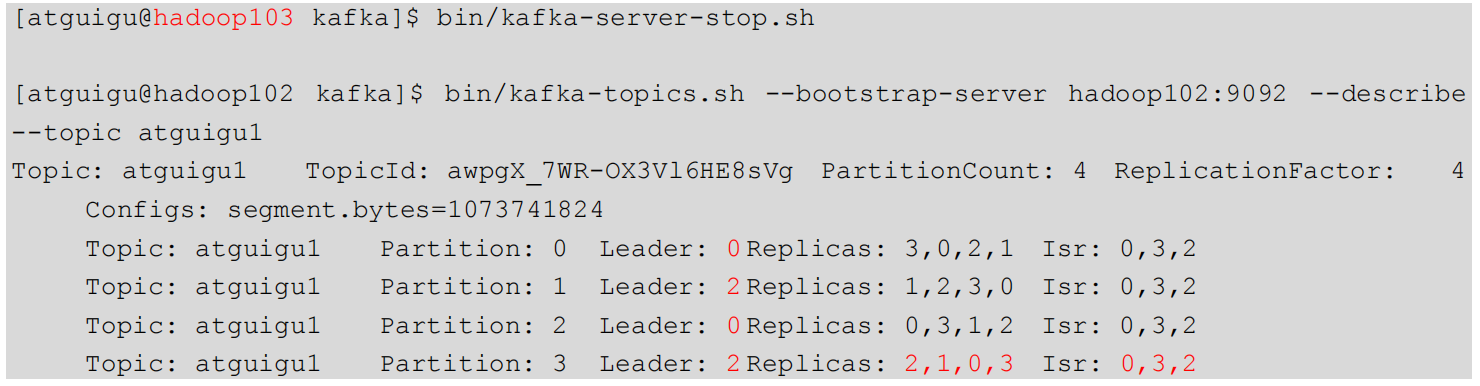
3.3.3 Leader和Follower故障处理细节
LEO(Log End Offset):标识当前日志文件中下一条待写入的消息的offset,即 offset+1
HW(High Watermark):所有副本中最小的LEO。
注意:消费者能看到的最大的offset是4,Kafka是只有主副本全部将该数据落磁盘之后才对消费者进行可见。
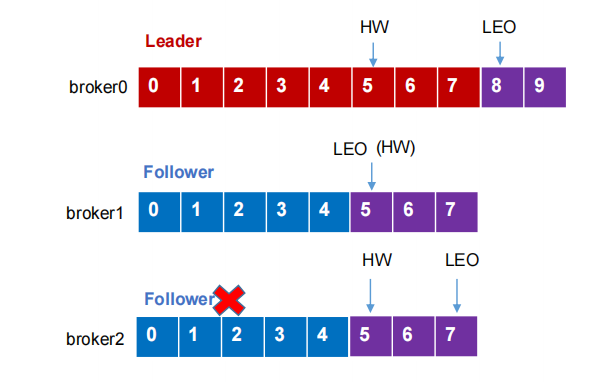
1)Follower故障:
(1)Follower发生故障后会被临时提出ISR
(2)这个期间Leader和Follower会继续接收数据
(3)该Follower恢复后,Follower会读取本地磁盘记录的上次HW,将log文件高于HW的部分截取掉,从HW开始向Leader进行同步。
(4)等待Follower的LEO大于等于该Partition的HW(Follower追上Leader后)就可以重新加入ISR。
2)Leader故障:
(1)Leader发生故障之后,会从ISR中选出一个新的Leader
(2)为保证多个副本之间的数据一致性,其余的Follower会先将各自的log文件高于HW的部分截取掉,然后从新的Leader中同步数据。
注意:这种方式只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
3.3.4 分区副本分配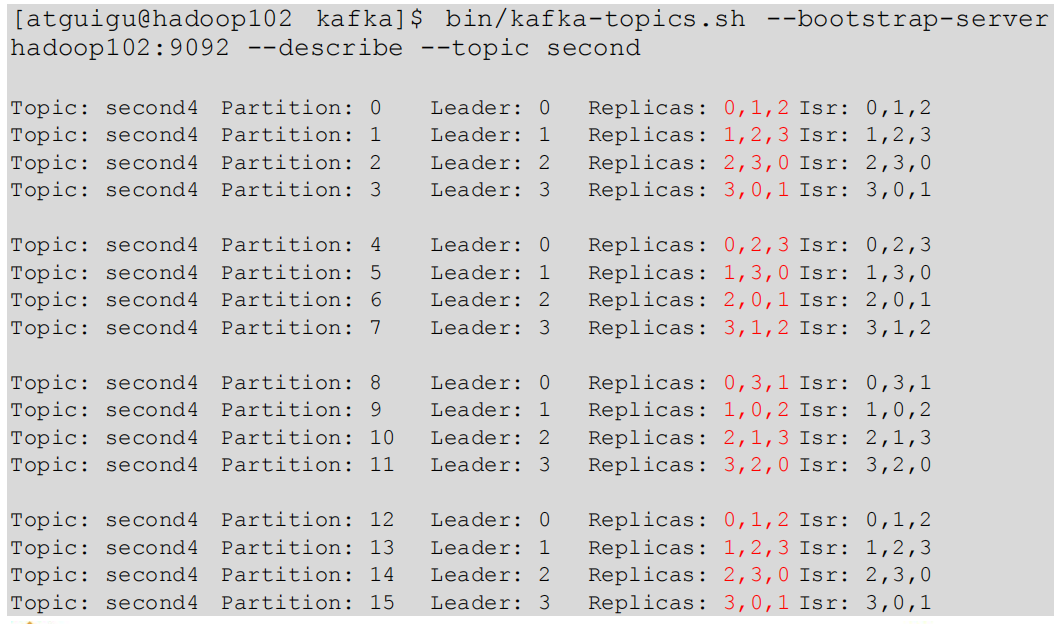
3.3.5 手动调整分区副本存储

3.3.6 Leader Partition负载均衡
3.3.7 增加副本因子


3.4 文件存储
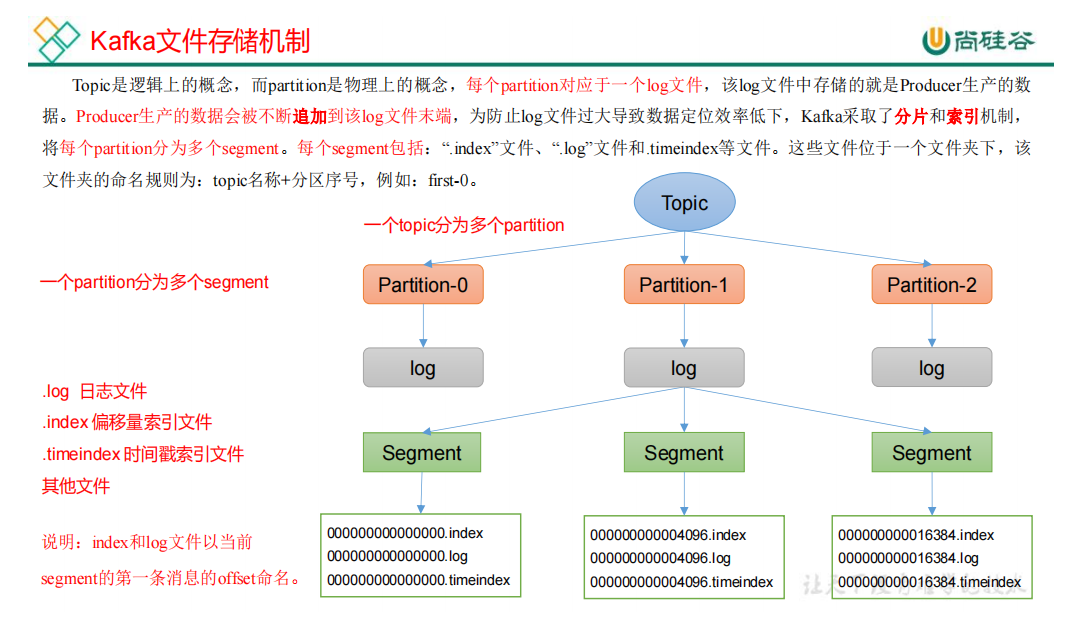
3.4.1 文件存储机制
topic是逻辑上的概念。
partition是物理上的概念,每个partition对应于一个log文件。一个partition可以分为多个segment。每个segment包含:
.log 日志文件
.index 偏移量索引文件
.timeindex 时间戳索引文件
每个segment大小为1G
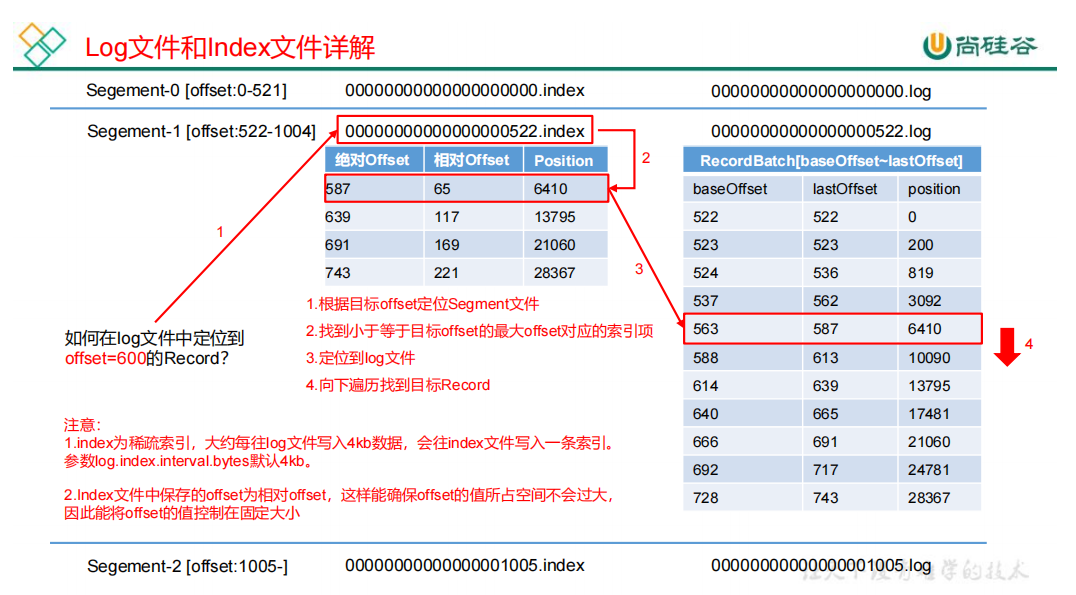
log文件和 index文件:
1)index为稀疏索引。大约每往log文件写入4kb数据,会往index文件中写入一条索引。
2)index文件中保存的offset为相对offset,可以确保offset的值所占空间不会过大。
3.4.2 文件清理策略
Kafka中提供的日志清理策略由 delete 和 compact 两种。
1)delete日志删除:将过期数据删除
log.cleanup.policy = delete 所有数据启用删除策略
(1)基于时间:默认打开。以segment中所有记录中的最大时间戳作为该文件的时间戳。
(2)基于大小:默认关闭。超过设置的所有日志总大小,删除最早的segment。
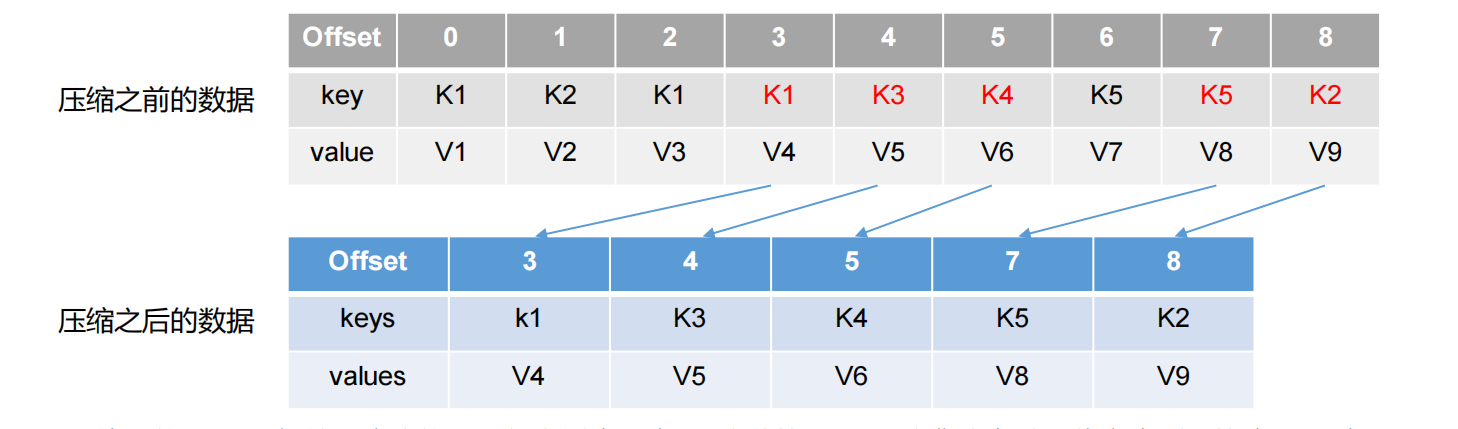
这种策略只适合特殊场景。如消息的key是用户ID,value是用户的资料。通过这种压缩策略,整个消息集里就保存了所有用户最新的资料。
3.5 高效读写数据
零拷贝:Kafka的数据加工处理操作交由Kafka生产者和Kafka消费者处理。 Kafka Broker 应用层不关心存储的数据,所以就不用 走应用层,传输效率高。PageCache页缓存:Kafka重度依赖底层操作系统提供的PageCache功 能。当上层有写操作时,操作系统只是将数据写入PageCache。当读操作发生时,先从PageCache中查找,如果找不到,再去磁盘中读取。实际上PageCache是把尽可能多的空闲内存都当做了磁盘缓存来使用。
3.6 Broker核心参数配置
| 参数名称 | 描述 |
|---|---|
| replica.lag.time.max.ms | ISR中,如果Follower长时间未向Leader发送通信请求或同步数据,则该Follower将被踢出ISR。 时间阈值默认为30s。 |
| auto.leader.rebalance.enable | 默认true。自动Leader Partition平衡。建议关闭。 |
| leader.imbalance.per.broker.percentage | 默认为10%。每个broker允许的不平衡的leader的比率。 如果每个broker超过了这个值,控制器会触发leader的平衡。 |
| leader.imbalance.check.interval.seconds |
默认值 300 秒。检查 leader 负载是否平衡的间隔时间。
|
| log.segment.bytes | kafka中log日志是分成一块块存储的。 log日志划分成块的大小,默认值1G。 |
| log.index.interval.bytes |
默认 4kb,kafka 里面每当写入了 4kb 大小的日志(.log),然后就往 index 文件里面记录一个索引。
|
| log.retention.hours | kafka中数据保存的时间,默认7天。 |
| log.retention.mintues | kafka中数据保存的时间,分钟级别,默认关闭。 |
| log.retention.ms | kafka中数据保存的时间,毫秒级别,默认关闭。 |
| log.retention.check.interval.ms | 检查数据是否保存超时的间隔,默认是5min。 |
| log.retention.bytes | 默认等于-1,表示无穷大。 超过设置的所有日志总大小,删除最早的segment。 |
| log.cleanup.policy | 默认是delete,表示所有数据启用删除策略。 如果设置值为compact,表示所有数据启用压缩策略。 |
| num.io.threads | 默认是8。负责写磁盘的线程数。 整个参数值要占总核数的50% |
| num.replica.fetchers | 默认是1。副本拉去线程数。 该参数占总核数的50%的1/3 |
| num.network.threads | 默认是3。数据传输线程数。 该参数占总核数的50%的1/3 |
| log.flush.interval.messages |
强制页缓存刷写到磁盘的条数,默认是long的最大值,9223372036854775807。
一般不建议修改,交给系统自己管理。
|
| log.flush.interval.ms | 每隔多久刷数据到磁盘,默认是null。 一般不建议修改。 |
四、消费者customer
push(推)模式:Kafka没有采用这种方式。如果broker决定消息发送速率,很难使用所有消费者的消费速率。
pull(拉)模式:customer从broker中主动拉取数据。但是,如果Kafka中没有数据,消费者会陷入循环,一直返回空数据。
4.1 customer工作流程
4.1.1 消费者总体工作流程
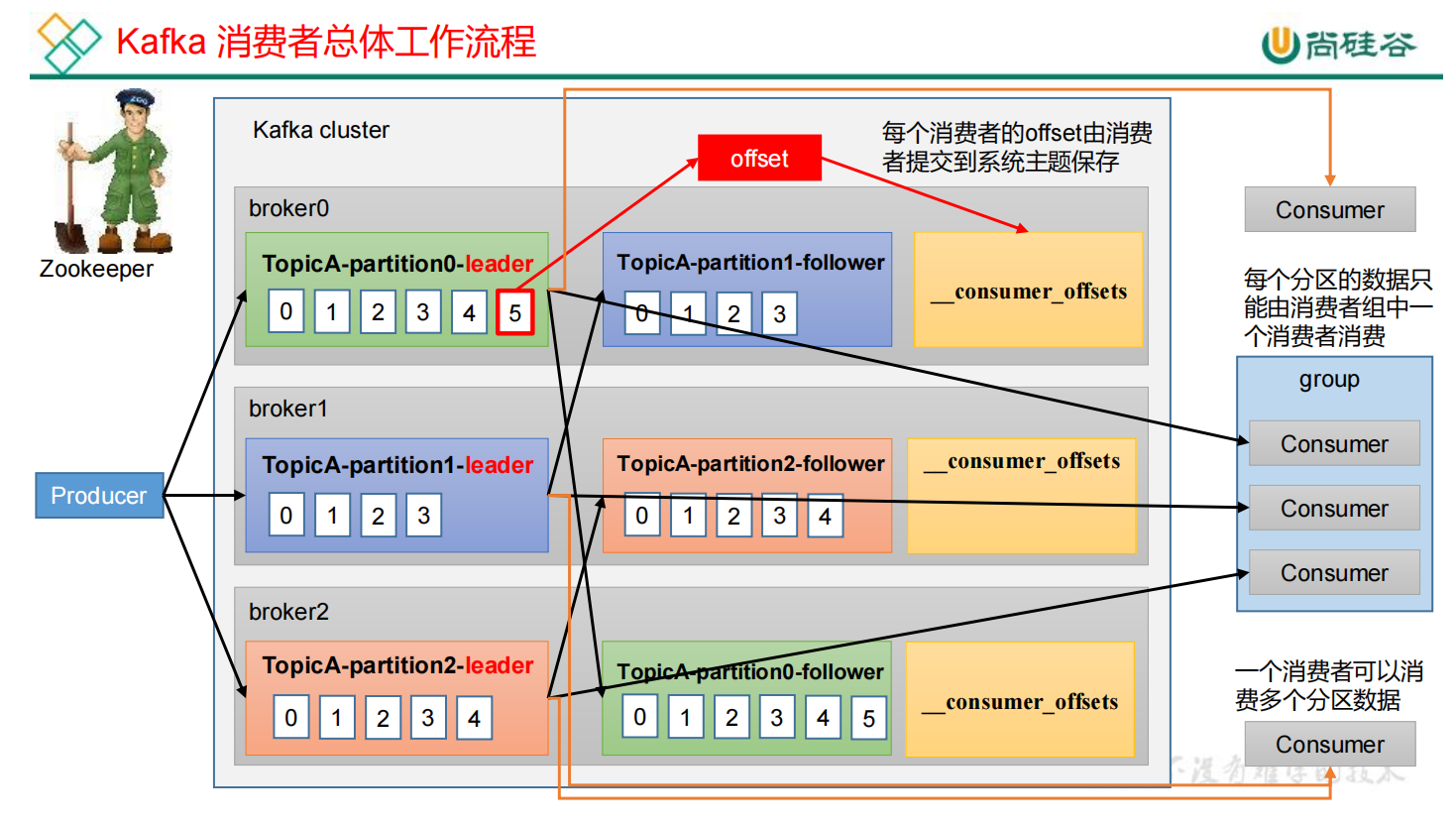
1)生产者producer向每一个分区的leader发送数据
2)follower主动和leader同步数据,保证数据的可靠性
3)consumer可以消费某一个分区的数据,也可以消费多个分区的数据。两个消费者之间相互不干预,相互独立。
4)消费者组:每个分区的数据只能由消费者组中的一个消费者进行消费。
5)每个消费者具体消费到哪一条数据由offset来记录。offset会持久化到系统主题(__consumer_offsets)中,底层会存储到磁盘上。由于是基于硬盘继续存储,所以可靠性能够得到保障。
0.9版本之前,offset会存储在zk中。但如果所有的offset都存储在zk中,那么消费者customer会和zk进行大量的交互,导致网络上数据传输非常频繁,传输压力过大。
4.1.2 消费者组原理
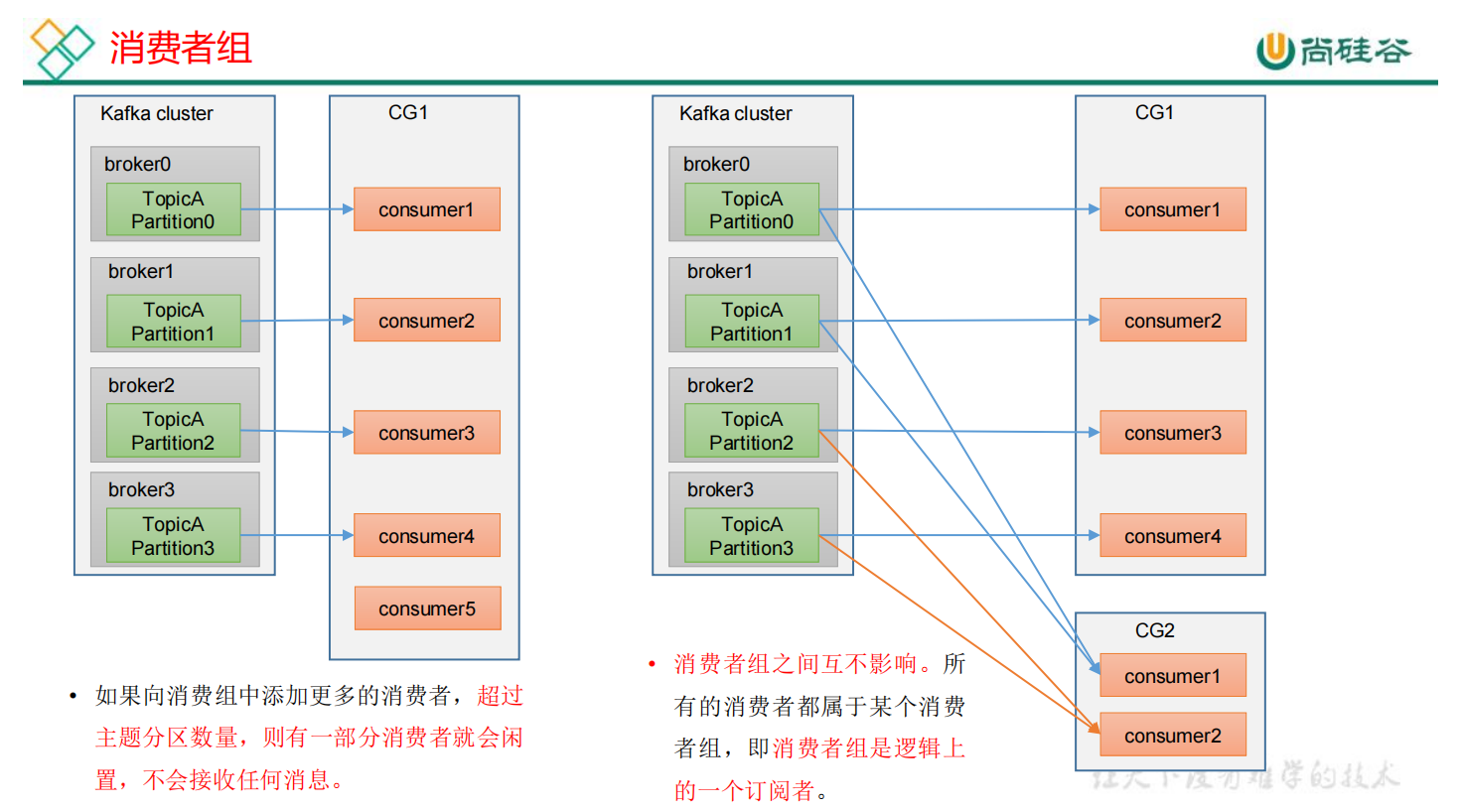
Cunsumer Group(CG):消费者组,由多个consumer组成。形成一个消费者组的条件,是所有的消费者的groupid相同。
- 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。
- 消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
注意1:一个消费者组中,消费者的数量不能超过partition的数量,不然多出来的会空转,即不会接收到任何消息。
注意2:消费者组之间互不影响,消费者组只是逻辑上的一个订阅者。
4.1.3 消费者组的初始化流程
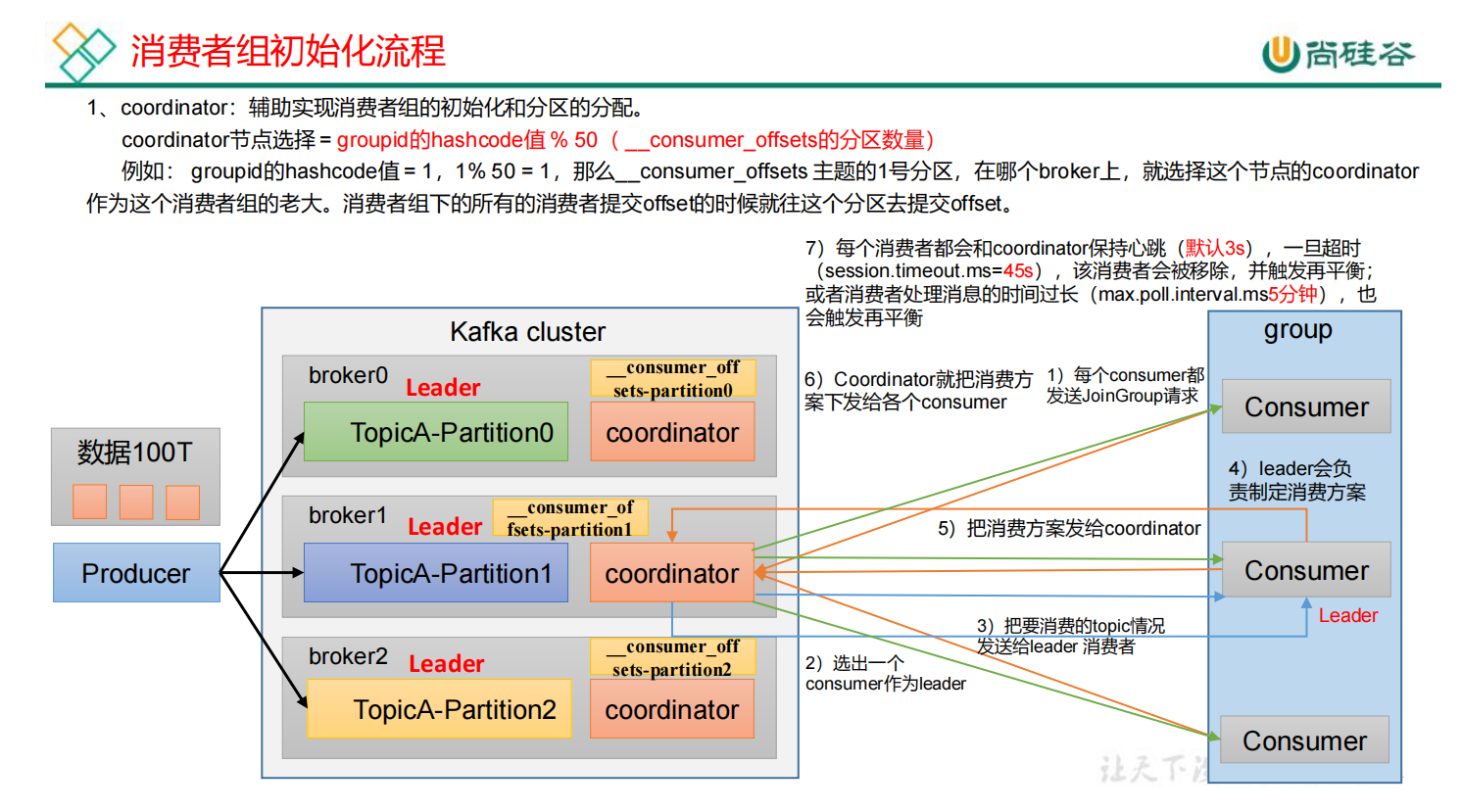
生产者把数据发送到Kafka集群,由消费者组中的消费者进行数据消费。那么消费者组是如何形成的呢?由coordinator组件辅助实现消费者组的初始化和分区的分配。
每一个broker节点有一个coordinator组件,消费者组要选择哪个coordinator来辅助它进行后续的工作呢?
coordinator节点选择 = groupid的hashcode值 % 50(默认为50,由__consumer_offsets的分区数量决定)
例如:groupid的hashcode值=1,那么__consumer_offsets主题的1号分区在哪个broker上,就选择这个节点的coordinator作为这个消费者组的老大。消费者组下所有的消费者提交offset的时候就往这个分区提交offset。
1)所有的消费者都会主动向coordinator发送请求,加入到组当中。
2)coordinator从消费者组中选出一个消费者id作为leader。
3)coordinator把要消费的topic情况发送给leader消费者。
4)leader制定消费方案。
5)leader把消费方法发送给coordinator。
6)coordinator把消费方案下发给各个consumer。
7)每个消费者和coordinator保持心跳(默认3s)一旦超时(session.timeout.ms = 45s),该消费者会被移除,并触发再平衡。消费者处理时间过长(max.poll.interval.ms5min)也会触发再平衡。
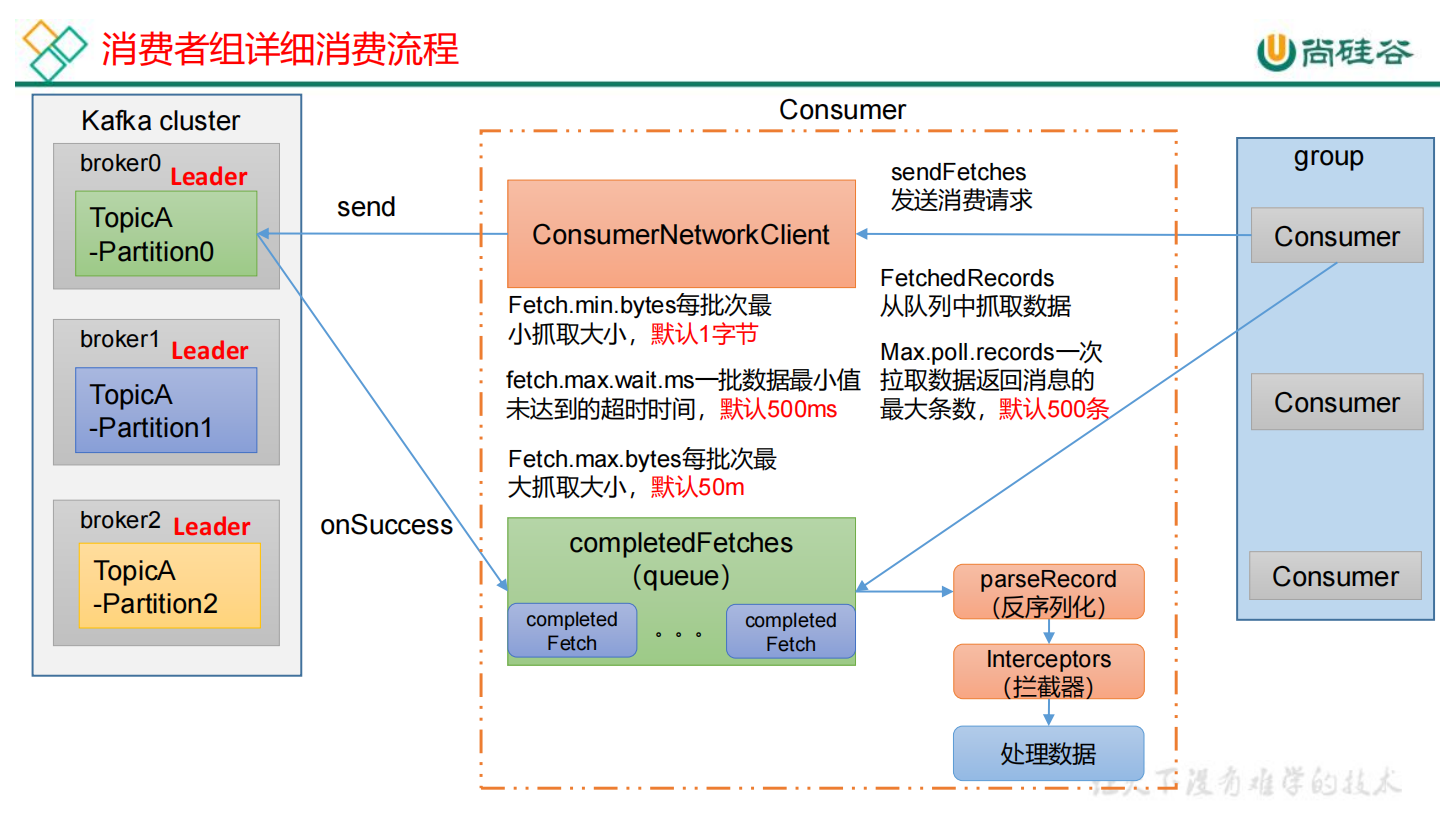
消费者详细消费流程:
(1)消费者组想要进行工作,首先需要创建一个消费者网络连接客户端 (ConsumerNetworkClient),主要用来和Kafka集群进行交互。
(2)CNC前期进行一些准备工作,首先调用 sendFetchs方法,用来抓取数据的初始化。期间会准备一些参数:
Fetch.min.bytes 每批次最小抓取的字节数,默认1字节
fetch.max.wait.ms 一批数据最小值未达到的超时时间,默认500ms
Fetch.max.bytes 每批次最大抓取大小,默认50m
(3)准备完毕之后调用send方法,发送请求。发送完请求之后,会通过回调方法onSuccess将对应的结果拉取过来。
(4)拉去过来的数据会放在消息队列queue中
(5)数据拉过来之后,消费者FetchedRecords从队列中抓取数据。
Max.poll.records 一次拉去数据返回消息的最大条数,默认500条
(6)数据拉去过来之后,经过parseRecord(反序列化)、Interceptors(拦截器)后,才会处理数据。
4.2 消费者API
4.2.1 独立消费者案例(订阅主题)
注意:在消费者API中必须配置消费者组id,命令行启动消费者不填写消费者id,会被自动填写随机的消费者组id。
- public class CustomConsumer {
- public static void main(String[] args){
-
- // 1. 创建消费者的配置对象
- Properties properties = new Properties();
-
- // 2. 给消费者配置对象添加参数
- // 连接
- properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.153.139:9092");
- // 反序列化
- properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
- properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
-
- // 配置消费者组(组名任意)
- properties.put(ConsumerConfig.GROUP_ID_CONFIG, "GROUP1");
-
- // 3. 创建消费者对象
- KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
-
- // 4. 订阅主题。指定消息队列名字
- ArrayList<String> topics = new ArrayList<>();
- topics.add("first");
- consumer.subscribe(topics);
-
- // 5. 消费数据
- while(true){
- ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
-
- for (ConsumerRecord<String, String> record : records) {
- // 如果数据过程过程中失败,可以将相关位置记录下来
- System.out.println(
- record.topic() + "\t" +
- record.offset() + "\t" +
- record.partition() + "\t" +
- "key:" + record.key() + "\t" +
- "value:" + record.value() + "\t" +
- record.timestamp()
-
- );
- consumer.commitAsync();
- }
- }
-
- }
- }
4.2.2 独立消费者案例(订阅分区)
- public class MyConsumer {
- public static void main(String[] args) {
- // 1. 配置
- Properties pro = new Properties();
- // 连接
- pro.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.153.139:9092");
- // 反序列化
- pro.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
- pro.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
- // 组id
- pro.put(ConsumerConfig.GROUP_ID_CONFIG, "GROUP1");
-
- // 2. 创建一个消费者
- KafkaConsumer<String, String> consumer = new KafkaConsumer<>(pro);
-
- // 3. 订阅主题对应的分区
- ArrayList<TopicPartition> topicPartitions = new ArrayList<>();
- topicPartitions.add(new TopicPartition("bigdata",0));
- consumer.assign(topicPartitions);
-
- // 4. 消费数据
- while(true){
- ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
- for(ConsumerRecords<String, String> record : records){
- System.out.println(record);
- }
- }
-
- }
- }
4.3 生产经验——分区的分配以及再平衡
一个consumer group中有多个consumer组成,一个topic有多个partition组成。那么由哪个consumer来消费哪个partition的数据呢?
Kafka有四种主流的分区分配策略:Range、RoundRobin、Sticky、CooperativeSticky。通过partition.assignment.strategy修改分区的分配策略。默认策略是Range+CooperativeSticky 。Kafka可以同时使用多个分区分配策略。
4.3.1 Range + 再平衡
1)Range分区策略原理
Range是对每个topic而言的。首先对同一个topic里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。
假如现在有7个分区,3个消费者,排序后的分区将会是0,1,...,6,消费者排序完之后将会是C0,C1,C2。
通过 partitions数 / consumer数 来决定每个消费者应该消费几个分区。如果除不尽,那么前面及格消费者将会多消费一个分区。
如 7/3=2...1,那么消费者C0会多消费一个分区;8/3=2...2,那么C0和C1多消费一个。
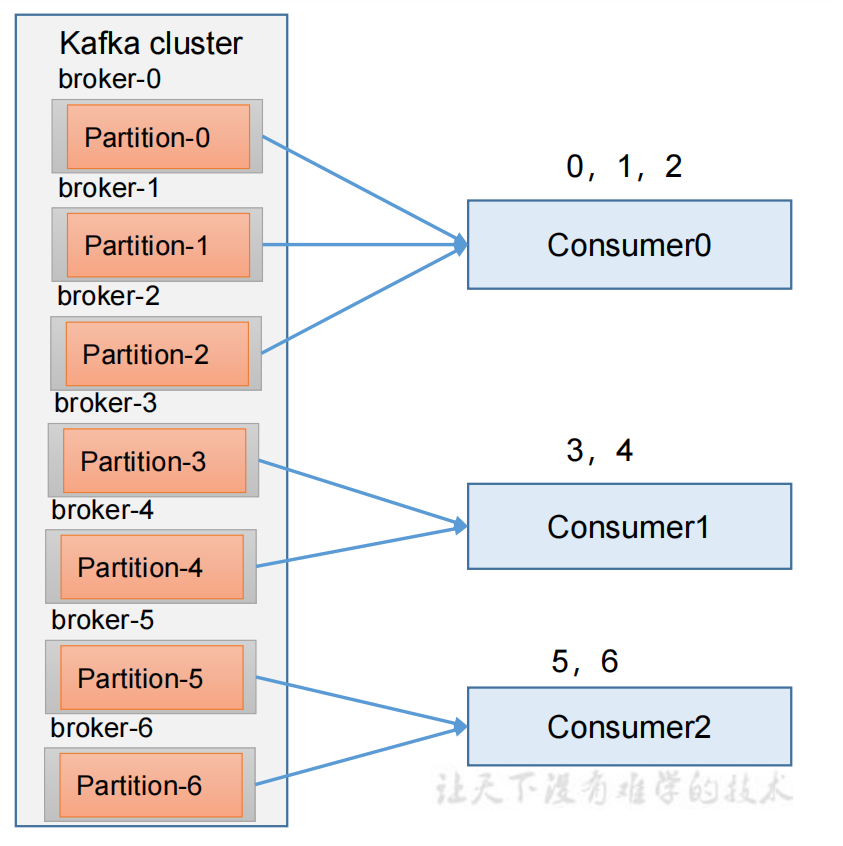
注意:如果只是针对1个topic而言,C0消费者多消费1个分区的影响不是很大。但如果有N个topic那么针对每个topic,消费者C0都将多消费1个分区。topic越多,C0消费的分区会比其他消费者明显多消费N个分区。容易产生数据倾斜。
说明:Kafka默认的分区分配策略就是 Range + CooperativeSticky,所以不需要修改策略。
4.3.2 RoundRobin + 再平衡
1)RoundRobin分区策略原理
RoundRobin 针对集群中所有Topic而言。
RoundRobin轮询分区策略,是把所有的 partition 和所有的 consumer 都列出来,然后按照hashcode进行排序。最后通过轮询算法来分配partition给到各个消费者。
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"org.apache.kafka.clients.consumer.RoundRobinAssignor")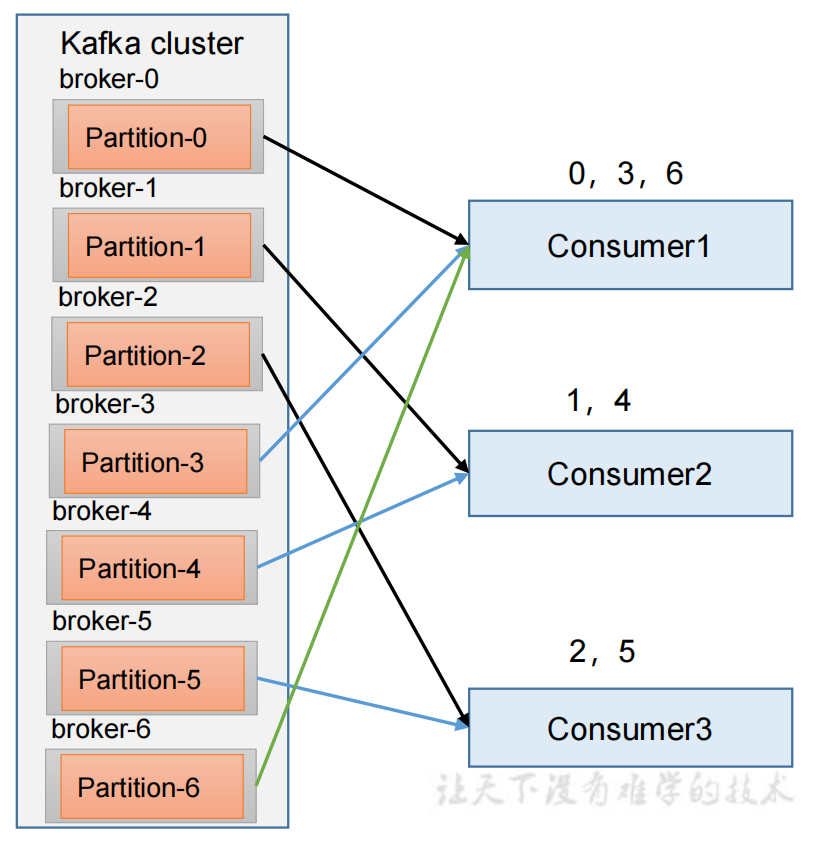
4.3.3 Sticky + 再平衡
粘性分区定义:可以理解为分配的结果带有“粘性的”。即在执行一次新的分配之前,考虑上一次分配的结果,尽量少的减少分配的变动,可以节省大量的开销。
粘性分区是Kafka从0.11.x版本开始引入这种分配策略。首先会尽量均衡的放置分区到消费者上面,在出现同一消费者组内消费者出现问题的时候,会尽量保持原有分配的分区不变化。
也就是说,当一个节点挂掉之后,其余两个分区策略不发生变化,而是增加了另外的几个。
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"org.apache.kafka.clients.consumer.StickyAssignor")4.4 offset位移
4.4.1 offset的默认维护位置
Kafka 0.9版本之前,消费者offset维护在zk中,0.9版本之后,维护在系统主题__consumer_offsets
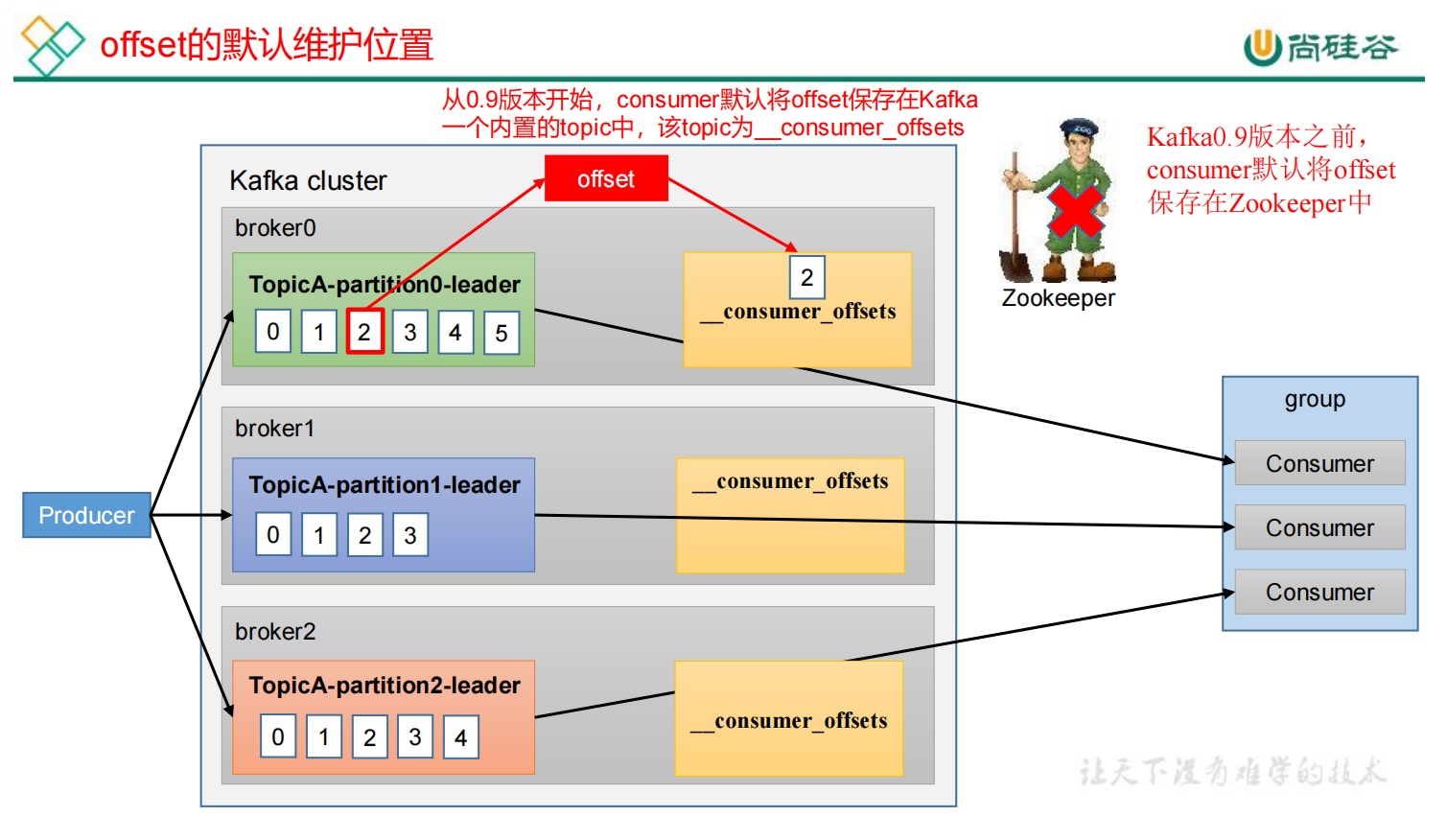
默认不能消费系统主题。为了查看该系统主题,将配置文件 config / consumer.properties 中添加配置 exclude. internal.topics=false 。
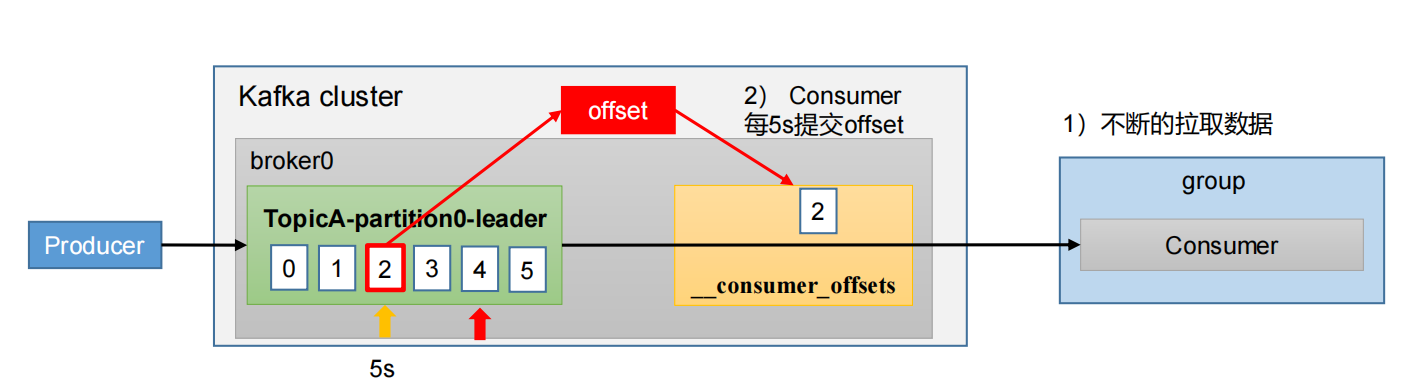
4.4.2 自动提交offset
自动提交offset的相关参数:
enable.auto.commit:是否开启自动提交offset功能,默认是true
auto.commit.interval.ms:自动提交offset的时间间隔,默认是5s
- // 是否自动提交offset
- propertoes.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
-
- // 提交offset的时间周期为1000ms,默认为5000ms
- properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 1000);
4.4.3 手动提交offset
虽然自动提交offset十分便利,但由于其是基于时间提交的,开发人员难以把握offset提交的时机。因此Kafka提供了手动提交offset的API。
手动提交offset的方法有两种:分别是commitSync(同步提交)和commitAsync(异步提交)。两者的相同点是,都会将本次提交的一批数据最高的偏移量提交;不同点是,同步提交阻塞当前线程,一直到提交成功,并且会失败重试;而异步提交则没有失败重试机制,可能提交失败。
- // 手动提交
- properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
-
- // 手动提交offset
- // 同步提交
- kafkaConsumer.commitSync();
- // 异步提交
- kafkaConsumer.commitAsync();

4.4.4 指定offset消费
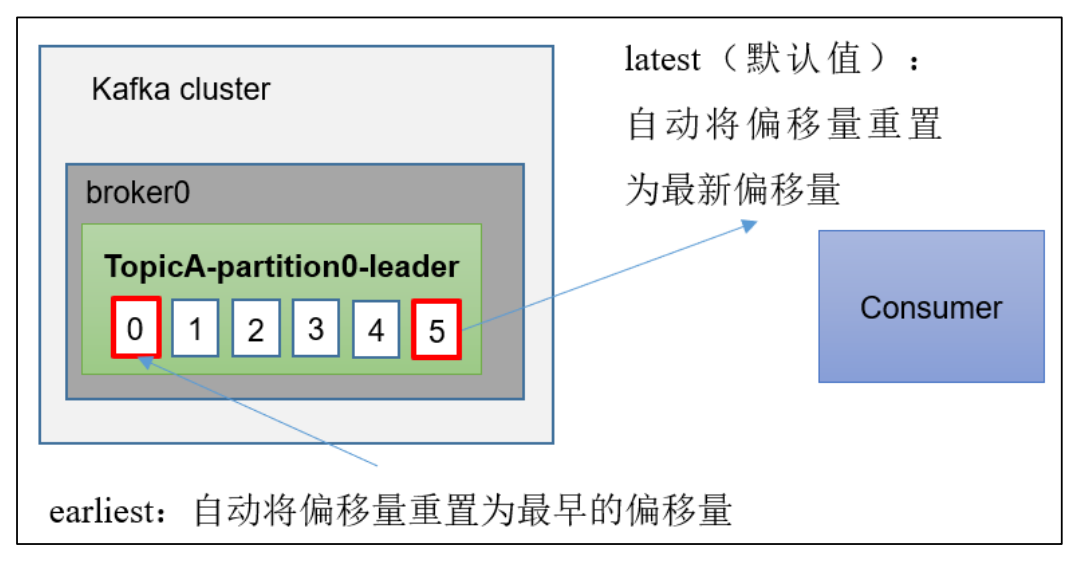
auto.offset.reset = earliest | latest | none 默认为latest
当Kafka中没有初始偏移量(消费者组第一次消费)或服务器上不再存在当前偏移量时(如该数据已被删除)
(1)earliest:自动将偏移量重置为最早的偏移量,--from-beginning
(2)latest(默认值):自动将偏移量重置为最新偏移量
(3)none:如果未找到消费者组的先前偏移量,则向消费者抛出异常。
- public static void main(String[] args) {
- // 1. 配置信息
- Properties properties = new Properties();
-
- // 连接
- properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFFIG, "hadoop02:9092,hadoop03:9092");
- // 反序列化
- properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserizlizer.class);
- properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserizlizer.class);
- // 组id
- properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test2");
-
-
- // 2. 创建消费者
- KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
-
- // 指定位置进行消费
- Set<TopicPartition> assignment = kafkaConsumer.assignment;
- // 保证分区分配方案已经制定完毕
- while(assignment.size() == 0){
- kafkaConsumer.poll(Duration.ofSeconds(1));
- assignment = kafkaConsumer.assignment();
- }
- // 指定消费的offset
- for(TopicPartition topicPartition : assignment){
- kafkaConsumer.seek(topicPartition, 100);
- }
-
- // 3.订阅主题
- ArrayList<String> topics = new ArrayList<>();
- topics.add("first");
- kafkaConsumer.subscribe(topics);
-
- // 4. 消费数据
- while(true){
- ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));
- for(ConsumerRecord<String, String> consumerRecord : consumerRecords){
- System.out.println(consumerRecord);
- }
- }
-
- }
4.4.5 指定时间消费
需求:在生产环境中,会遇到最近消费的几个小时数据异常,想重新按照时间消费。例如要求按照时间消费前一天的数据。
- public static void main(String[] args) {
- // 1. 配置信息
- Properties properties = new Properties();
-
- // 连接
- properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFFIG, "hadoop02:9092,hadoop03:9092");
- // 反序列化
- properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserizlizer.class);
- properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserizlizer.class);
- // 组id
- properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test2");
-
-
- // 2. 创建消费者
- KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
-
- // 指定位置进行消费
- Set<TopicPartition> assignment = kafkaConsumer.assignment;
- // 保证分区分配方案已经制定完毕
- while(assignment.size() == 0){
- kafkaConsumer.poll(Duration.ofSeconds(1));
- assignment = kafkaConsumer.assignment();
- }
-
- // 希望把时间转换未对应的offset
- HashMap<TopicPartition, Long> topicPatririonLongHashMap = new HashMap<>();
- // 封装对应集合
- for(TopicPartition topicPatririon : assignment ){
- topicPatririonLongHashMap.put(TopicPartition, System.currentTimeMillis() - 1 * 24 * 3600 * 1000);
- }
- Map<TopicPartition, OffsetAndTimestamp> topicPartitionOffsetAndTimestampMap = kafkaConsumer.offsetsForTimes(topicPatririonLongHashMap);
- // 指定消费的offset
- for(TopicPartition topicPartition : assignment){
- OffsetAndTimestamp offsetAndTimestamp = topicPatririonOffsetAndTimestampMap.get(topicPartition);
- kafkaConsumer.seek(topicPartition, offsetAndTimestamp.offset());
- }
-
- // 3.订阅主题
- ArrayList<String> topics = new ArrayList<>();
- topics.add("first");
- kafkaConsumer.subscribe(topics);
-
- // 4. 消费数据
- while(true){
- ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));
- for(ConsumerRecord<String, String> consumerRecord : consumerRecords){
- System.out.println(consumerRecord);
- }
- }
-
- }
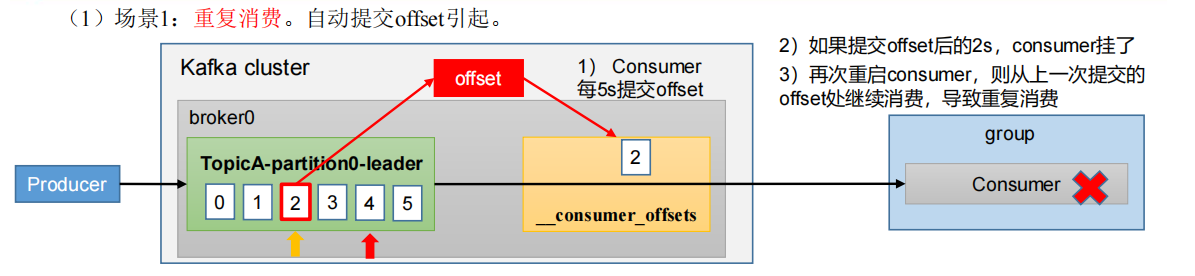
4.4.6 漏消费和重复消费
重复消费:已经消费了数据,但是offset没提交。
自动提交offset引起。consumer每5s提交一次offset,如果提交offset后的2s内consumer挂了,再次启动consumer时,从上一次提交的offset处继续消费,导致重复消费。
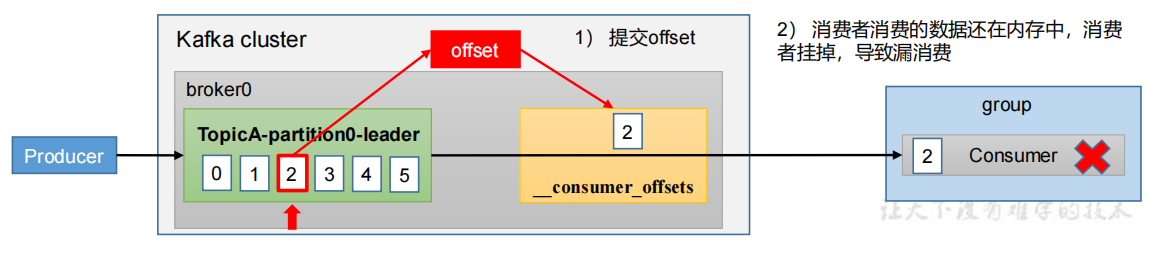
漏消费:先提交offset后消费,有可能会造成数据的漏消费。
设置offset为手动提交,当offset被提交时,数据还在内存中未落盘,此时刚好消费者线程被kill掉,那么offset已经提交,但是数据未处理,导致这部分内存中的数据丢失。
4.5 生产经验——消费者事务
如果想完成Consumer端的精准一次性消费,那么需要Kafka消费端将消费过程和提交offset过程做原子绑定。此时我们需要将Kafka的offset保存到事务的自定义介质(比如MySQL)
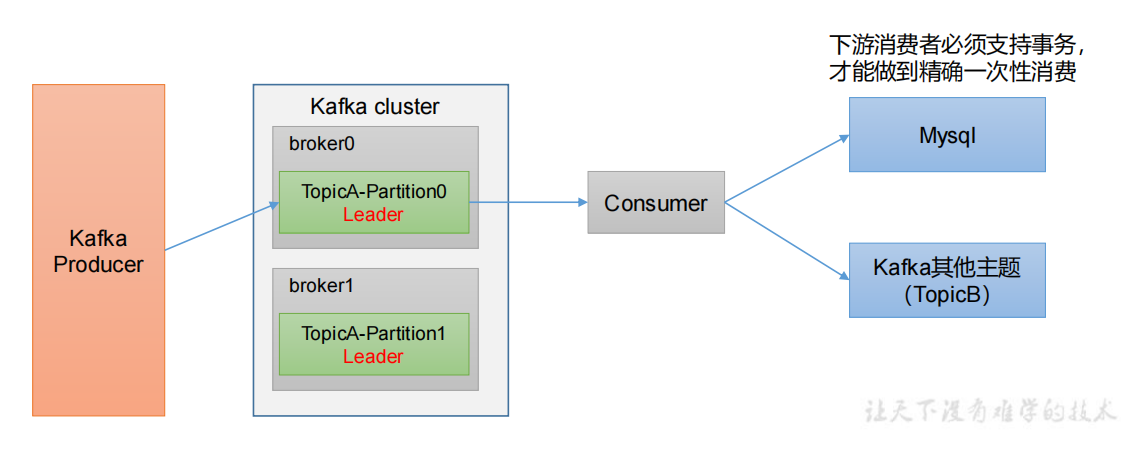
4.6 生产经验——数据积压(消费者如何提高吞吐量)
1)如果是Kafka消费能力不粗,则可以考虑增加topic的分区数,并且同时提升消费组的消费者熟练,消费者数 = 分区数。
2)如果是下游数据处理不及时:提高每批次拉取的数量。批次拉取数量过少(拉取数据/处理时间 < 生产速度)使处理的数据小于生产的数据,也会造成数据积压。
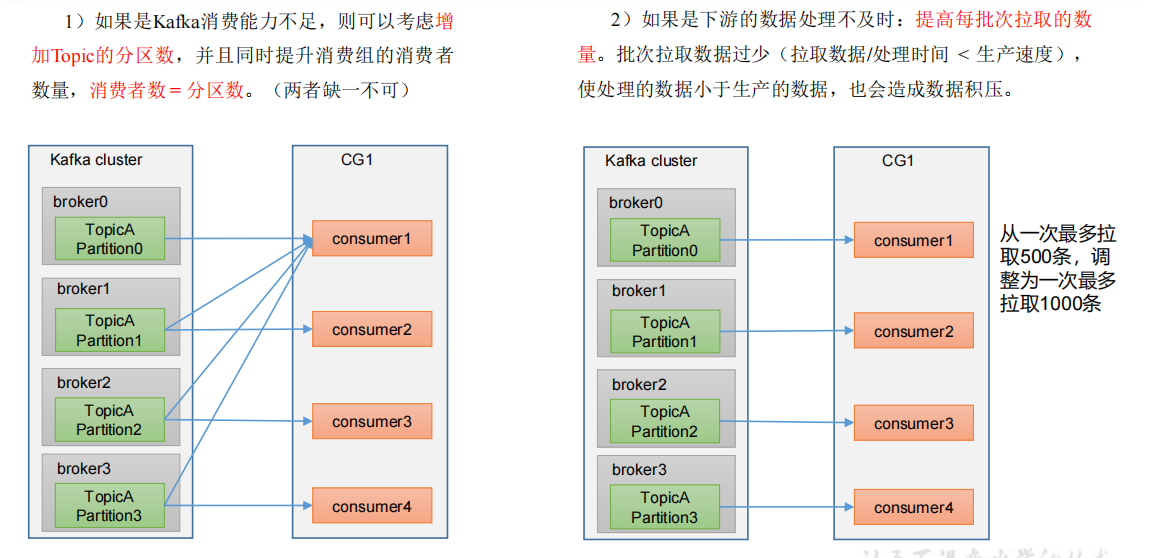
4.7 消费者核心参数配置
| 参数名称 | 描述 |
|---|---|
| bootstrap.server | 向Kafka集群建立初始连接用到的host/port列表 |
| key.deserializer value.deserializer | 指定接收消息的key和value反序列化类型。 |
| group.id | 标记消费者所属的消费者组。 |
| enable.auto.commit | 默认值为true。自动提交 |
| auto.commit.interval.ms | 如果enable.auto.commit为true,则该值定义了消费者偏移量向Kafka提交的频率。默认5s。 |
| auto.offset.reset |
earliest:自动重置偏移量到最早的偏移量。
latest:默认,自动重置偏移量为最新的偏移量。
none:如果消费组原来的(previous)偏移量不存在,则向消费者抛异常。anything:向消费者抛异常。
|
| offset.topic.num.partitions | __consumer_offsets的分区数。 默认50个分区,不建议修改。 |
| heartbeat.interval.ms | Kafka消费者和coordinator之间的心跳时间,默认3s。 该值比如小于session.timeout.ms,也不应高于session.timeout.ms的1/3。 不建议修改。 |
| session.timeout.ms | Kafka消费者和coordinate之间连接超时时间,默认45s。 超过该值,该消费者被移除,消费者组执行再平衡。 |
| max.poll.interval.ms | Kafka消费者和coordinate之间连接超时时间,默认5min。 超过该值,该消费者被移除,消费者组执行再平衡。 |
| fetch.min.bytes | 默认1字节。消费者获取服务器端一批消息最小的字节数。 |
| fetch.max.wait.ms | 默认500ms。如果没有从服务器端获取到一批数据的最小字节数,该时间到,仍然会返回数据。 |
| fetch.max.bytes | 默认default:50M。消费者获取服务器端一批消息的最大字节数。 如果服务器端一批次的数据大于该值(50M)仍然可以拉取回来这批数据。因此这不是一个绝对最大值。 |
| max.poll.records | 一次poll拉去数据参会消息的最大条数,默认500条。 |

