
热门标签
热门文章
- 1首起针对国内金融企业的开源组件投毒攻击事件_组件投毒 数据库
- 2项目体检(Health Check)升级上线
- 3Mac系统安装及配置python_macbook如何安装python2
- 4python读程序写结果-31.Python:文件读写
- 5Git+TortoiseGit详细安装教程(HTTP方式)_tortoisegit http
- 6Python的日志输出_python日志输出到文件
- 7Springboot+Vue项目-基于Java+MySQL的图书馆管理系统(附源码+演示视频+LW)
- 8阅读小车循迹论文笔记:灰度传感器、仿生处理器、路径跟踪机制()_灰度传感器原理图
- 9SIDE:开启研发新的颠覆式的开发体验
- 10Flask-SQLAlchemy的使用(详解)_flask sqlalchemy options
当前位置: article > 正文
大语言模型会引发第四次产业革命——智能革命吗?_人工智能起步已经很久,但为什么大语言模型的诞生掀起了各行各业的大讨论?
作者:很楠不爱3 | 2024-04-29 14:49:24
赞
踩
人工智能起步已经很久,但为什么大语言模型的诞生掀起了各行各业的大讨论?
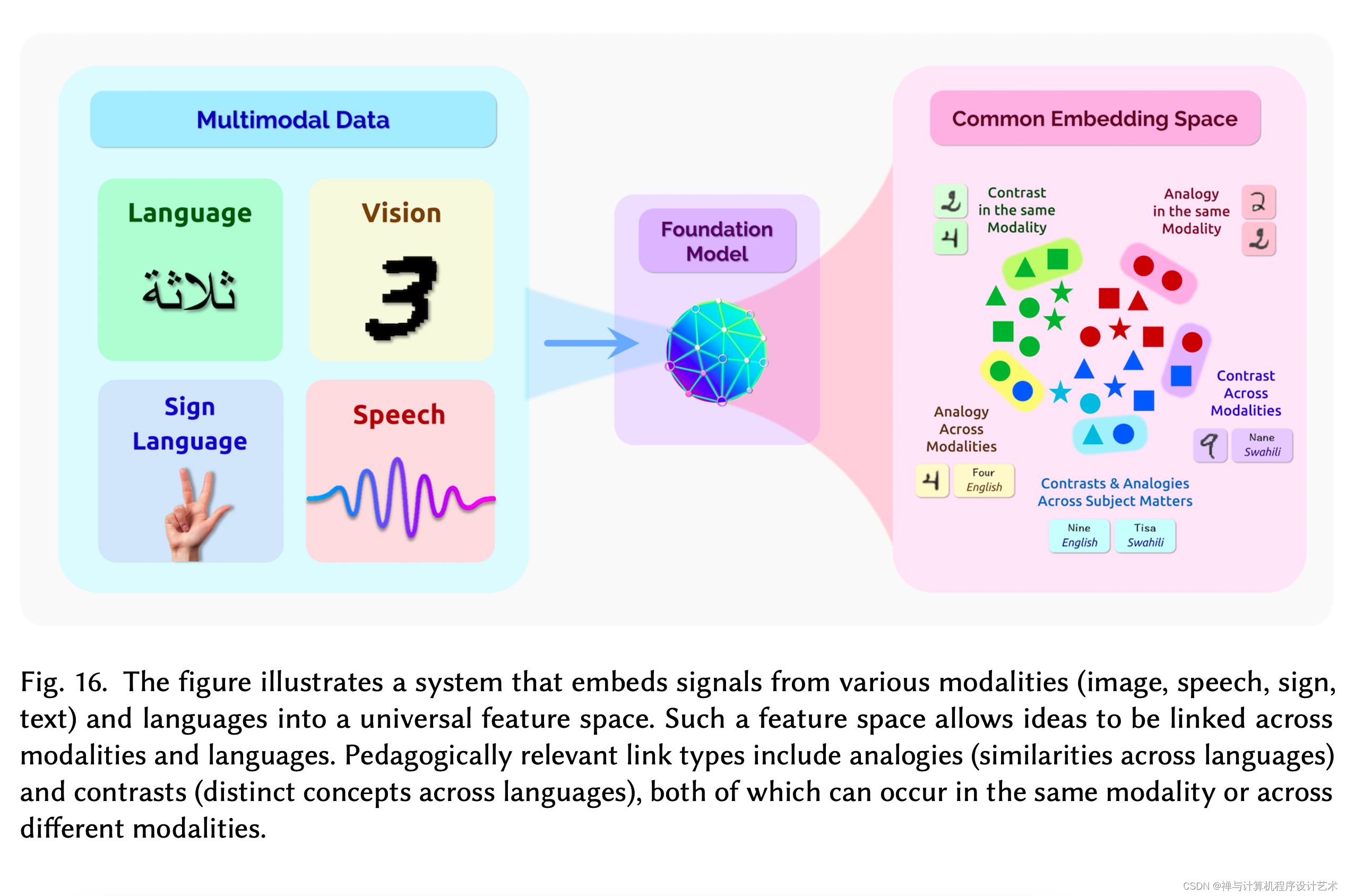
大概盘算了一下,一年多来,业界发布了非常多的大模型,从去年OpenAI GPT-3 1750亿参数开始,到年初华为盘古大模型 1000亿,鹏程盘古-α 2000亿参数,Google switch transformer 1.6万亿;及近期的智源悟道2.0 1.75万亿参数 MoE,快手1.9万亿参数推荐精排模型,阿里达摩院M6 1万亿参数等。
很多小伙伴看的是眼花缭乱,那究竟这些模型有没有差异?如果有差异,差异在哪里?
到底什么是大模型?到底大模型有什么用呢?
第一章 引言
过去10年的人工智能产品的成功,都归功于以为深度卷积、训练神经网络等为核心算法+NVIDIA显卡驱动算力+规模化监督标注下的深度学习1.0范式。也就是深度学习1.0对于AI产业是基础性的生产力变革,而在这个基础上应用这些技术构建的产品和服务,那都是在这个生产力框架下的上层应用。这是过往看到的技术推动生产力革命,带动产品服务产业化的路径。
最近几年,深度学习2.0范式正在进行,也就是以transformer结构为基础构建的大模型+自监督学习的方式构建超大规模数据集+知识+新的算力和算法框架。这又是一次技术涌现带来的生产力革命,可能带来新的产品化和商业机会。
深度学习2.0的核心技术,我们就称之为【大模型】,或者叫【基础模型】、【基模型】。
那【大模型/基础模型/基模型】
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/很楠不爱3/article/detail/508279
推荐阅读
相关标签

