
- 1能不能介绍一下USB传输协议的原理
- 2SpringDataJpa使用详解_spring data jpa使用
- 3jQuery ui effects详细用法_$effect详解
- 4NameError: name xx is not defined_input nameerror: name 'qwe' is not defined
- 5盘点人工智能十大经典应用领域、图解技术原理
- 6JavaScript、Kotlin、Flutter可以开发鸿蒙APP吗?
- 7APP测试Adb操作命令与Monkey使用、查错流程(入门+精通级)_monkey命令忽略崩溃
- 8AWS S3跨账号复制迁移数据_两个不同账户的aws 跨库复制
- 9Ineffective mark-compacts near heap limit Allocation failed-JavaScript heap out of memory vue项目内存溢出_v8 ineffective mark-compacts near heap limit alloc
- 10发掘非结构化数据价值:AI 在文档理解领域的现状与未来_非结构化数据 ai
轻量化之王MobileNetV4 开源!精度直逼87%,速度起飞~
赞
踩
编辑 | 极市平台
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文

作者介绍了最新一代的MobileNets,名为MobileNetV4(MNv4),其特点是针对移动设备设计的通用高效架构。在其核心部分,引入了通用倒瓶颈(UIB)搜索块,这是一个统一且灵活的结构,它融合了倒瓶颈(IB)、ConvNext、前馈网络(FFN)以及一种新颖的额外深度可分(ExtraDW)变体。与UIB并行,我们提出了Mobile MQA,这是一个专为移动加速器设计的注意力块,能带来显著的39%速度提升。
同时,作者还介绍了一种优化的神经架构搜索(NAS)方法,它提高了MNv4搜索的有效性。UIB、Mobile MQA以及精细化的NAS方法的整合,使得MNv4模型系列在移动CPU、DSP、GPU以及像苹果神经引擎和谷歌Pixel EdgeTPU这样的专用加速器上几乎达到了帕累托最优——这是其他测试模型所不具备的特性。最后,为了进一步提升准确度,引入了一种新颖的蒸馏技术。借助这项技术,MNv4-Hybrid-Large模型在ImageNet-1K上的准确度达到了87%,在Pixel 8 EdgeTPU上的运行时间仅为3.8ms。
1 Introduction
作者的两阶段神经网络架构搜索(NAS)方法,将粗略搜索与细粒度搜索分开,显著提升了搜索效率,并促进了比先前最先进模型显著更大的模型的创建。此外,结合离线蒸馏数据集,减少了NAS奖励测量中的噪声,从而提升了模型质量。
通过整合UIB、MQA和改进的NAS配方,作者推出了MNv4模型系列,在包括CPU、DSP、GPU和专业加速器在内的多种硬件平台上,实现了大多为帕累托最优性能。作者的模型系列覆盖了从极其紧凑的MNv4-Conv-S设计(拥有3.8M参数和0.2GMACs),在Pixel6CPU上以2.4毫秒内达到73.8%的ImageNet-1Ktop-1准确率,到MNv4-Hybrid-L高端变体,在Pixel8EdgeTPU上以3.8毫秒的运算时间为移动模型准确率树立了新的基准。作者新颖的蒸馏配方混合了带有不同增强的数据集,并添加了平衡的同类数据,增强了泛化能力,进一步提高了准确率。借助这项技术,尽管MNv4-Hybrid-L的MACs减少了39倍,但其ImageNet-1Ktop-1准确率仍达到了令人印象深刻的87%:仅比其教师模型低0.5%。
2 RelatedWork
优化模型的准确性和效率是一个研究得很深入的问题。
移动卷积网络: 关键工作包括MobileNetV1 利用深度可分离卷积以提高效率,MobileNetV2 引入了线性瓶颈和倒置残差,MnasNet 在瓶颈中整合了轻量级注意力机制,以及MobileOne 在推理时在倒置瓶颈中添加并重新参数化线性分支。
高效混合网络: 这一研究方向整合了卷积和注意力机制。MobileViT 通过全局注意力块将CNN的优势与ViT相结合。MobileFormer并行处理MobileNet和一个Transformer,并在两者之间建立双向桥梁进行特征融合。FastViT 在最后一个阶段加入注意力,并使用大的卷积核作为早期阶段自注意力机制的替代。
高效注意力: 研究工作一直集中在提高MHSA的效率。EfficientViT和MobileViTv2提出了自注意力近似方法,以达到线性复杂度,而对准确度的影响很小。EfficientFormer-V2为了提高效率而对Q、K、V进行下采样,而CMT和NextViT仅对K和V进行下采样。
硬件感知神经架构搜索(NAS): 另一种常见的技术是使用硬件感知神经架构搜索(NAS)来自动化模型设计过程。NetAdapt 使用经验延迟表来在目标延迟约束下优化模型的准确性。MnasNet 同样使用延迟表,但它应用强化学习来进行硬件感知的NAS。FBNet 通过可微分的NAS加速了多任务硬件感知搜索。MobileNetV3 通过结合硬件感知NAS、NetAdapt算法和架构改进,针对手机CPU进行调优。MobileNetMultiHardware 为多个硬件目标优化单一模型。Once-for-all 为提高效率,将训练和搜索分离。
3 Hardware-IndependentParetoEfficiency
屋顶线模型: 为了使一个模型在普遍情况下都高效,它必须能够在其理论的计算复杂度与实际硬件性能之间找到平衡。
在硬件目标上表现出色,这些硬件目标的瓶颈极大地限制了模型性能,这些瓶颈主要由硬件的最高计算吞吐量和最高内存带宽决定。
为此,作者使用了屋顶线模型,该模型估计给定工作负载的性能,并预测它是受内存瓶颈还是计算瓶颈的限制。简而言之,它忽略了特定的硬件细节,只考虑工作负载的操作强度(LayerMACs WeightBytes ActivationBytes )与硬件处理器和内存系统的理论极限之间的关系。内存和计算操作大致是并行发生的,因此两个中较慢的那个大约决定了延迟瓶颈。为了将屋顶线模型应用于以为索引的神经网络层,作者可以以下述方式计算模型推理延迟,ModelTime:
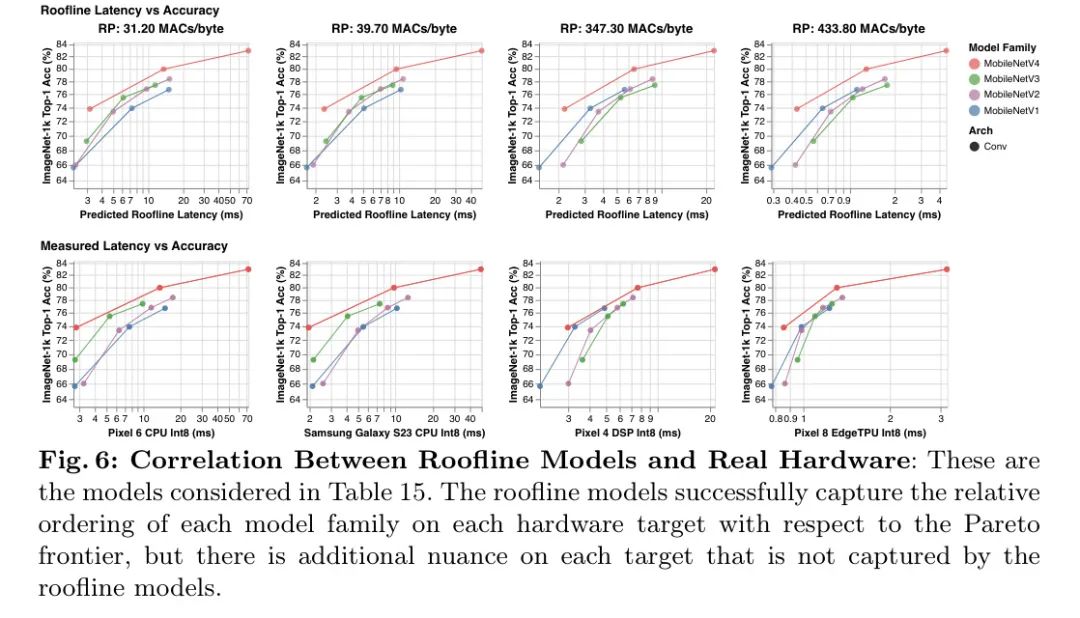
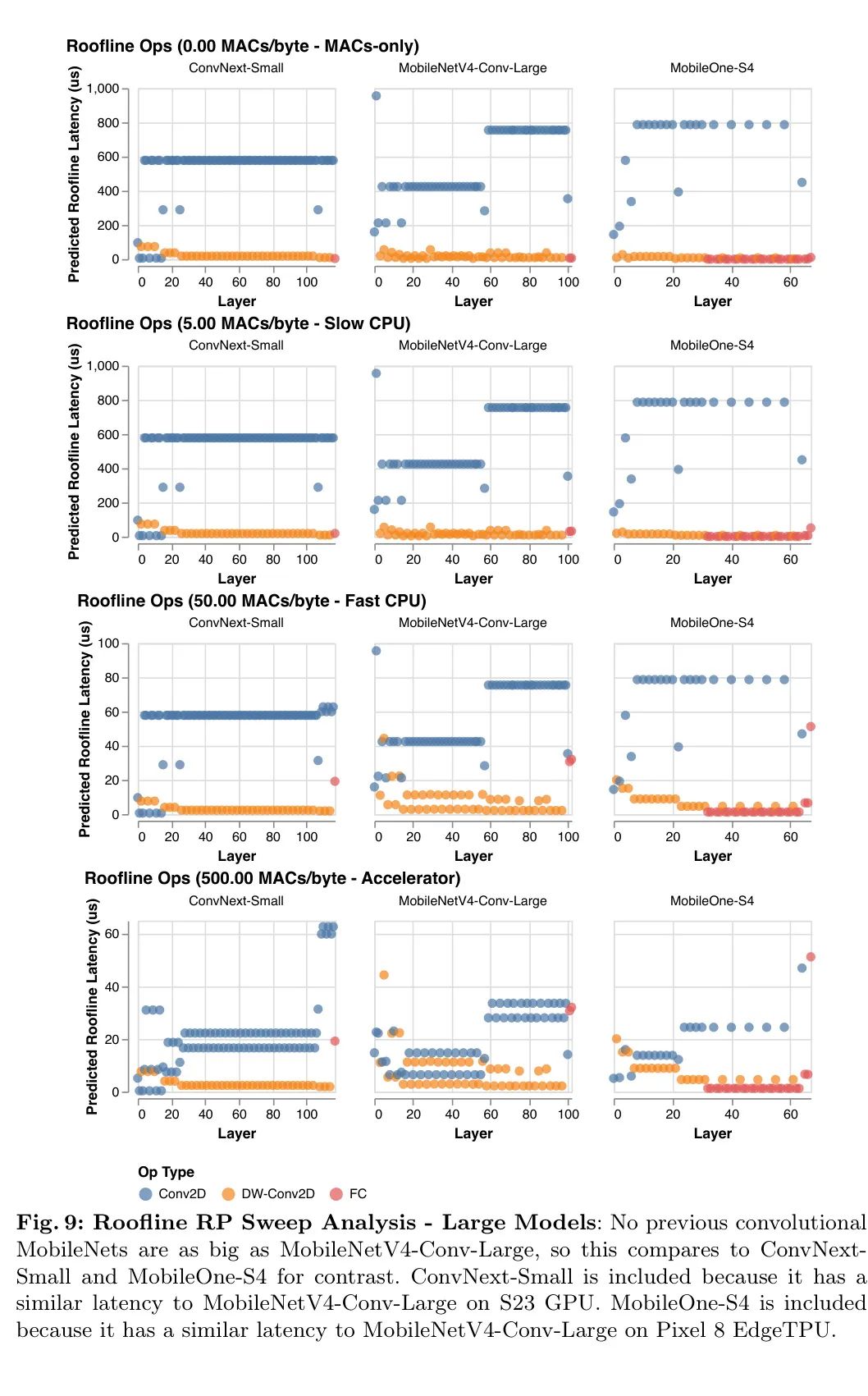
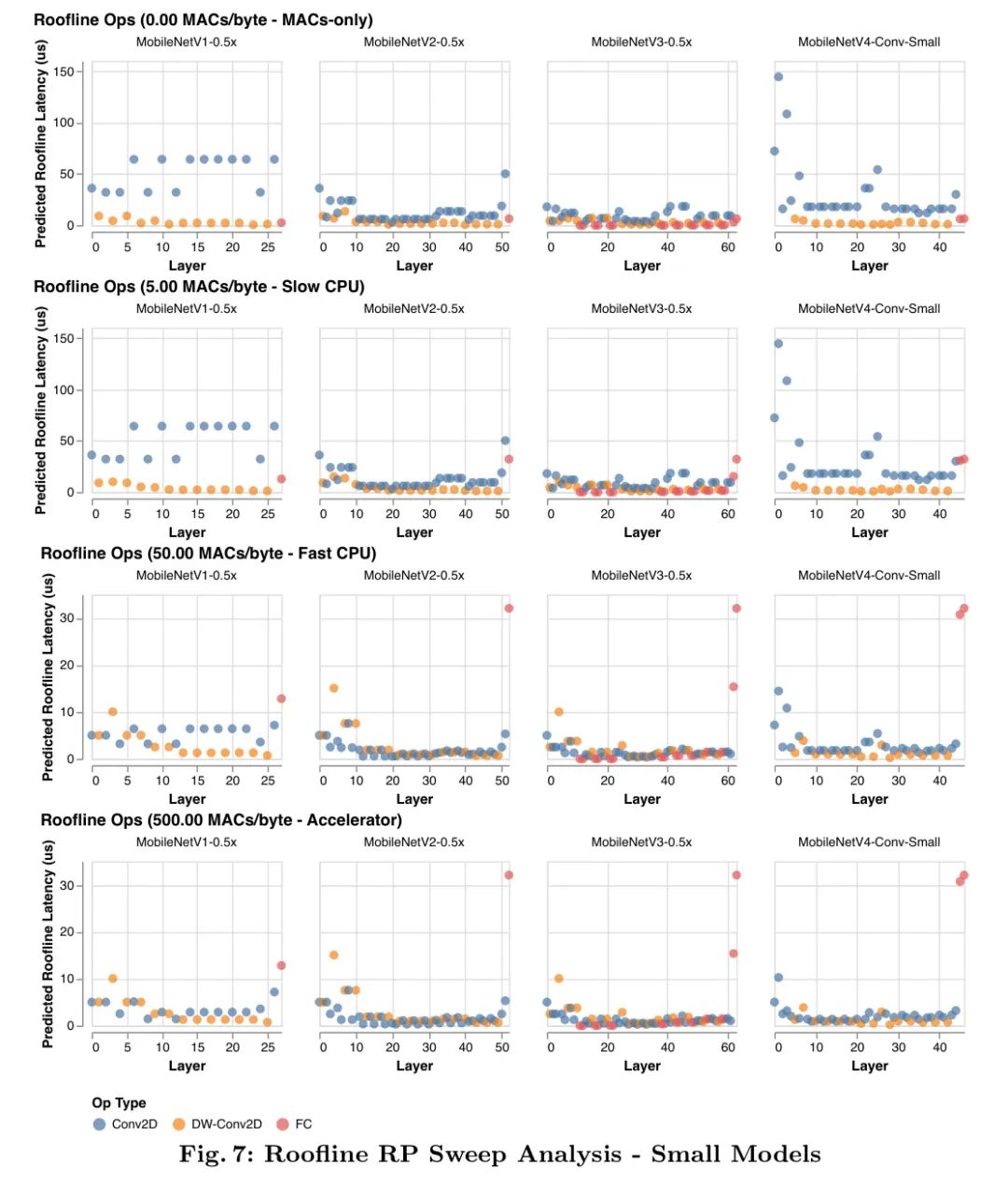
在屋顶线模型中,硬件行为由_脊点_(RP)来总结,即硬件的峰值MACs与峰值MemBW之比。也就是说,这是实现最大性能所需的最小操作强度。2为了优化具有各种瓶颈的硬件,如图2和图3所示,作者从RP预期的最低值(0MAC/字节)扫描到最高值(500MACs/字节)来分析作者算法的延迟——更多详情见附录F。屋顶线模型仅依赖于数据传输与计算的比率,因此具有相同RP的所有硬件通过延迟对工作负载的排名是相同的。3这意味着,如果新目标的RP包含在扫描范围内,那么扫描-RP的屋顶线分析(见下一段)同样适用于未来的硬件和软件。
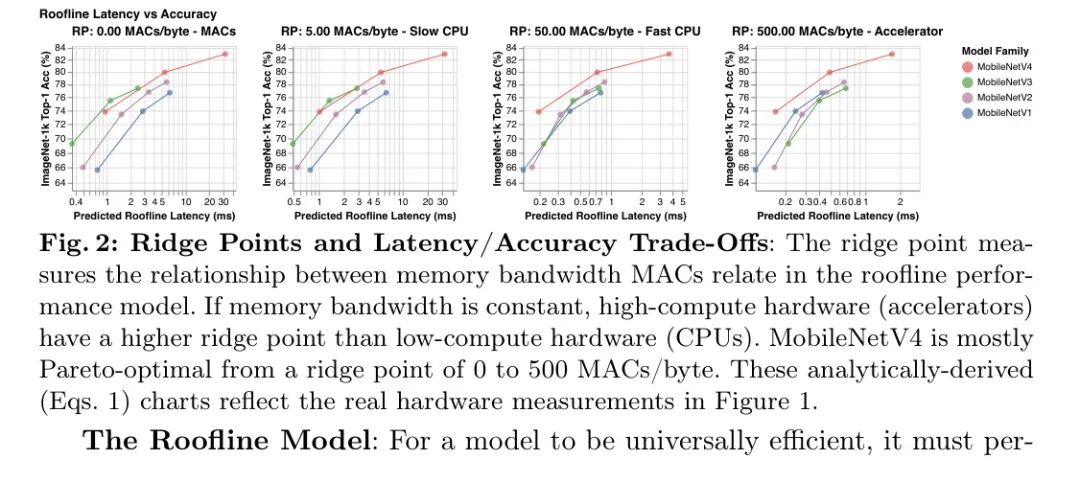
脊点扫描分析: 如图2和图3所示,屋顶线模型揭示了MobileNetV4模型如何与其他卷积MobileNets相比,实现硬件独立的几乎帕累托最优性能。在低脊点硬件(例如CPU)上,模型更可能受计算限制而非内存限制。因此,为了提高延迟,即使以增加内存复杂度为代价(如MobileNetV3Large-1.5x),也要最小化总的MAC数量。在高脊点硬件上,数据移动是瓶颈,所以MAC不会显著减慢模型速度,但可以增加模型容量(如MobileNetV1-1.5x)。因此,为低脊点优化的模型在高脊点上运行缓慢,因为内存密集和低MAC的全连接(FC)层受到内存带宽的限制,不能利用高可用的峰值MAC。
MobileNetV4设计: MobileNetV4在平衡MACs和内存带宽方面进行了投资,旨在以最低的成本获得最大的回报,特别关注网络的起始和结束部分。在网络的开头,MobileNetV4使用大而昂贵的前几层来显著提高模型的容量和下游准确性。这些初始层主要由大量的MACs组成,因此它们仅在低RP硬件上成本较高。在网络的末端,所有MobileNetV4变体使用相同大小的最终全连接(FC)层以最大化准确性,尽管这导致较小尺寸的MNV4变体在高RP硬件上遭受更高的FC延迟。由于大的初始卷积层在低RP硬件上成本高,但在高RP硬件上并不昂贵,而最终的全连接层在高RP硬件上成本高,在低RP硬件上却不贵,MobileNetV4模型不会同时遭受这两种减速。换句话说,MNV4模型能够使用提高准确性的昂贵层,但不会同时承受这些层的组合成本,从而在所有脊点上都实现了几乎是最优的Pareto性能。
4 UniversalInvertedBottlenecks
作者提出了通用逆瓶颈(UniversalInvertedBottleneck, UIB)模块,这是一个适用于高效网络设计的可适应构建块,它具有灵活地适应各种优化目标的能力,而不会使搜索复杂度爆炸性增长。
倒瓶颈(IB)模块,由MobileNetV2提出,已成为高效网络的标准化构建模块。
基于最成功的MobileNet要素——可分离的深度卷积(DW)和点式(PW)扩展及倒瓶颈结构,本文引入了一种新的构建块——通用倒瓶颈(UIB)块,如图4所示。其结构相当简单。作者在倒瓶颈块中引入了两个可选的DW,一个在扩展层之前,另一个在扩展层和投影层之间。这些DW的存在与否是神经网络架构搜索(NAS)优化过程的一部分,从而产生新的架构。尽管这种修改很简单,但作者的新构建块很好地统一了几个重要现有块,包括原始的IB块、ConvNext块以及ViT中的FFN块。此外,UIB还引入了一种新的变体:额外的深度卷积IB(ExtraDW)块。
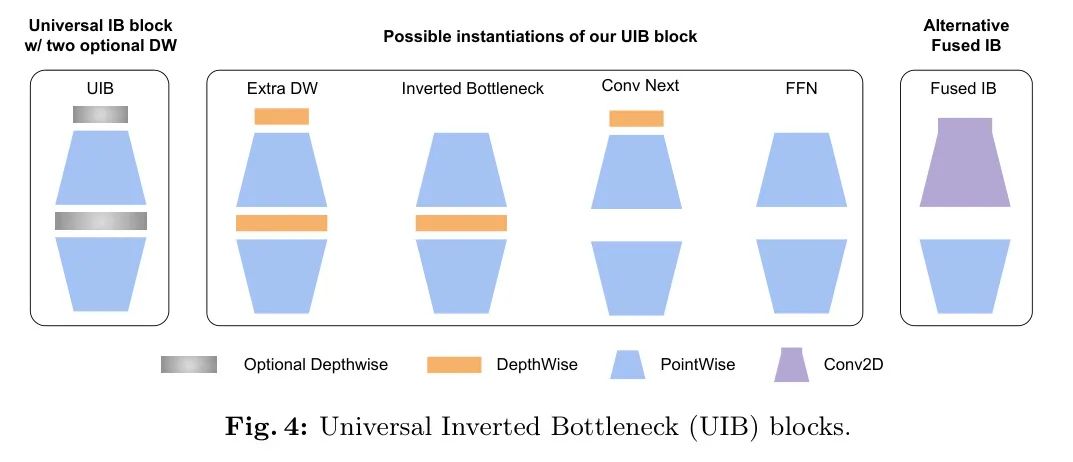
除了在神经网络架构搜索(NAS)过程中允许灵活的中间层(IB)结构外,作者还避免了任何人为设计的缩放规则,比如在EfficientNet中使用的那种,而是为每个模型大小单独优化结构。为了防止NAS超级网络的大小爆炸性增长,作者共享了通用组件(逐点扩展和投影)并简单地将深度可分离卷积(DWs)作为额外的搜索选项添加进去。结合基于超级网络的网络架构搜索算法,这种方法使得大多数参数(大于95%)可以在不同的实例之间共享,使得NAS变得极其高效。
UIB实例化 UIB块中的两个可选深度卷积有四种可能的实例化方式(图4),这导致了不同的权衡。
倒瓶颈(IB)- 在扩展的特征激活上进行空间混合,以增加成本为代价提供更大的模型容量。
ConvNext 通过在扩展之前执行空间混合,实现了使用更大核尺寸进行更廉价的空间混合。
ExtraDW是本文提出的一种新变体,它允许廉价地增加网络的深度和感受野。它提供了以下几点优势:
结合ConvNext与IB.4的优势。
FFN 是由两个1x1的点状卷积(PW)堆叠而成,并在它们之间加入激活和标准化层。PW是最受加速器友好的操作之一,但最好与其他模块一起使用。
在网络的每个阶段,UIB提供了灵活性以:
达成一个即时的空间和通道混合的权衡。
按需扩大感受野。
最大化计算利用率。
5 MobileMQA
在本节中,作者介绍了MobileMQA,这是一个专门为加速器优化的新型注意力块,它能提供超过39%的推理速度提升。
操作强度的重要性:近期在视觉模型的研究中,人们大多致力于减少算术运算(MACs)以提高效率。然而,在移动加速器上性能的真正瓶颈往往不是计算而是内存访问。这是因为加速器提供的计算能力远大于内存带宽。因此,仅仅最小化MACs可能并不会导致更好的性能。相反,作者必须考虑操作强度,即算术运算与内存访问的比率。
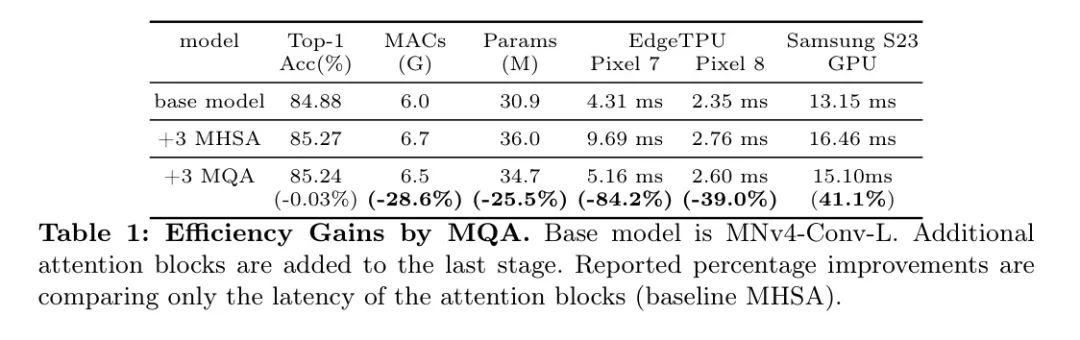
MQA在混合模型中是高效的:MHSA 将Query、键和值投影到多个空间以捕捉信息的不同方面。多Query注意力(MQA)[37] 通过在所有头之间使用共享的键和值简化了这一点。尽管多个Query头是必要的,但大型语言模型可以有效共享单个键和值的头,而不会牺牲准确度[25]。对于键和值使用一个共享的头,当批处理的Token数量相对于特征维度较小时,可以大大减少内存访问需求,从而显著提高操作强度。这对于面向移动应用的混合视觉模型通常是这种情况,在这种情况下,仅在具有高特征维度的低分辨率后期阶段使用注意力,并且批大小通常为1。作者的实验证实了MQA在混合模型中的优势。如表1所示,与MHSA相比,MQA在EdgeTPUs和三星S23GPU上实现了超过39%的加速,而质量损失可以忽略不计(-0.03%)。MQA还将MACs和模型参数减少了25%以上。据作者所知,作者是第一个在移动视觉中使用MQA的。
采用非对称空间下采样: 受到MQA的启发,它在Query、键和值之间使用非对称计算,作者将空间缩减注意力(SRA)[45]融合到作者优化的MQA模块中,以降低键和值的分辨率,同时保持高分辨率Query。这一策略是由混合模型中空间相邻标记之间的观察到的相关性所启发的,这归因于早期层中的空间混合卷积滤波器。通过非对称空间下采样,作者在输入和输出之间保持了相同的标记数量,保持了注意力的高分辨率并显著提高了效率。与不同,作者的方法用步长为2的3x3深度卷积替换了AvgPooling,为提高模型容量提供了一种成本效益高的方式。
移动MQA 这里作者提出了作者的移动MQA模块:
在这段文本中, 表示空间缩减,在作者设计中是指步长为2的深度可分离卷积(DW),或者在未使用空间缩减的情况下的恒等函数。如表格2所示,结合非对称空间下采样可以在极小的精度损失(-0.06%)情况下,带来超过20%的效率提升。
6 DesignofMNv4Models
作者的设计理念:简约遇见高效。 在开发最新的MobileNets时,作者的核心目标是实现在各种移动平台上的帕累托最优。为了达到这个目标,作者首先对现有模型和硬件进行了广泛的相关性分析。通过实证检验,作者找到了一组既能确保在各种设备上成本模型(延迟成本的预测)之间的高度相关性,又能在性能上接近帕累托前沿的组件和参数。
作者的调查揭示了一些关键的见解:
多路径效率问题:组卷积和类似的多路径设计,尽管具有更低的浮点运算次数(FLOPcounts),但由于内存访问复杂度,可能效率较低。
硬件支持很重要:像SqueezeandExcite(SE)[21]这样的高级模块,
GELU、LayerNorm 在DSPs上的支持并不好,LayerNorm的速度也比BatchNorm慢,而SE在加速器上的表现也比较慢。
简洁的力量: 传统组件——深度卷积和逐点卷积、ReLU、批量归一化以及简单的注意力机制(例如,MHSA)——展示了卓越的效率和硬件兼容性。
基于这些发现,作者建立了一套设计原则:
标准组件: 作者优先考虑广泛支持的元素,以实现无缝部署和硬件效率。
灵活的UIB模块: 作者新颖的可搜索UIB构建块支持可适应的空间和通道混合,接收场调整,以及最大化的计算利用率,通过网络架构搜索(NAS),促进了效率和准确性之间的平衡妥协。
采用直接注意力机制: 作者的MobileMQA机制为了最佳性能而优先考虑简单性。
这些原则使得MobileNetV4在所有评估的硬件上大多数情况下都是帕累托最优的。以下,作者详细介绍了针对UIB模型搜索改进的NAS配方,概述了各种MNv4-Conv模型大小的特定搜索配置,并解释了混合模型的构建过程。
RefiningNASforEnhancedArchitectures
为了有效地实例化UIB块,作者采用了针对性能改进定制的TuNAS。
增强搜索策略: 作者的方法通过实施两阶段搜索,减轻了TuNAS因参数共享而偏向于较小滤波器和扩展因子的偏见。这种策略解决了UIB的深度层与其他搜索选项之间参数数量方差的问题。
粗粒度搜索:起初,作者专注于确定最优的滤波器大小,同时保持参数固定:一个默认扩展因子为4的反向瓶颈块和一个3x3的深度可分核。
细粒度搜索:在初步搜索结果的基础上,作者搜索UIB的两个深度可分层的配置(包括它们的存在以及3x3或5x5的核大小),同时保持扩展因子恒定为4。
表3展示了与传统的单阶段搜索相比,通过作者的两阶段搜索所提高的效率和模型质量,在单次TuNAS传递中探索了一个统一的搜索空间。

增强TuNAS的鲁棒训练 TuNAS的成功取决于对架构质量的准确评估,这对于奖励计算和政策学习至关重要。最初,TuNAS利用ImageNet-1k来训练超级网络,以便进行架构评估。然而,这种做法忽略了实际应用中网络可能遇到的噪声和扰动。为了解决这个问题,作者建议在训练过程中加入鲁棒性训练。具体来说,作者在训练集中引入了多种数据增强和对抗样本,以此来增强模型的鲁棒性。通过这种方式,TuNAS可以更好地评估架构在嘈杂环境下的性能,从而提高最终学到的网络架构的质量。
网络,然而模型在ImageNet上的性能显著受到数据增强、正则化以及超参数选择的影响。鉴于TuNAS的架构样本在不断发展变化,找到一个稳定的超参数集合是具有挑战性的。
作者通过一个离线的蒸馏数据集来解决这一问题,这样就不需要额外的增强方法,并减少了对正则化和优化设置的敏感性。如第8节所述的JFT蒸馏数据集作为作者训练TuNAS的集合,在表4中展示了显著的改进。考虑到在扩展训练会话中,深度缩放模型超越了宽度缩放模型,作者将TuNAS的训练扩展到750个周期,产生了更深、质量更高的模型。

作者构建了基于NAS优化的UIB块的MNv4-Conv模型,并根据特定的资源限制对其进行定制。更多详细信息见附录0.A。与其他混合模型一致,作者发现将注意力机制添加到卷积模型的最后阶段最为有效。在MNv4-Hybrid模型中,作者交错使用MobileMQA块和UIB块以提升性能。有关全面的模型规格,请参考附录0.D。
7 Results
在本节中,作者将展示MobileNetV4(MNv4)模型在ImageNet-1K分类和COCO目标检测上的几乎是最优的帕累托性能。
ImageNetclassification
实验设置: 为了评估模型结构的性能,作者遵循标准的协议,仅使用ImageNet-1k 训练分割进行训练,并在验证分割上测量Top-1准确度。作者的延迟分析涵盖了多种移动硬件的广泛和代表性选择,包括ARMCortexCPU(Pixel6, SamsungS23)、高通HexagonDSP(Pixel4)、ARMMaliGPU(Pixel7)、高通Snapdragon(S23GPU)、苹果神经引擎和谷歌EdgeTPU。作者完整的训练设置在附录0.C中详细说明。
在基准测试中,作者将自己的模型与领先的效率模型进行了比较,包括混合型(MiT-EfficientViT,FastViT,NextViT)和卷积型(MobileOne,ConvNext,以及先前的MobileNet)。
作者根据报告的Top-1准确率以及作者的延迟评估,选择了这些版本([19][36][18])。值得注意的是,作者采用现代训练方法改进了MobileNet系列(V1、V2、V3),从而显著提高了准确性:MobileNetV1提高了3.4%,达到74.0%;V2提高了1.4%,达到73.4%;V3提高了0.3%,达到75.5%。这些改进后的MobileNets基准线在本论文中被用于隔离架构的进步。
结果:
作者的结果,如图1所示,并在表5中详细说明,表明MNv4模型在一系列准确度目标和移动硬件上大多数情况下都达到了帕累托最优,包括CPU、DSP、GPU以及像苹果神经引擎和谷歌EdgeTPU这样的专用加速器。
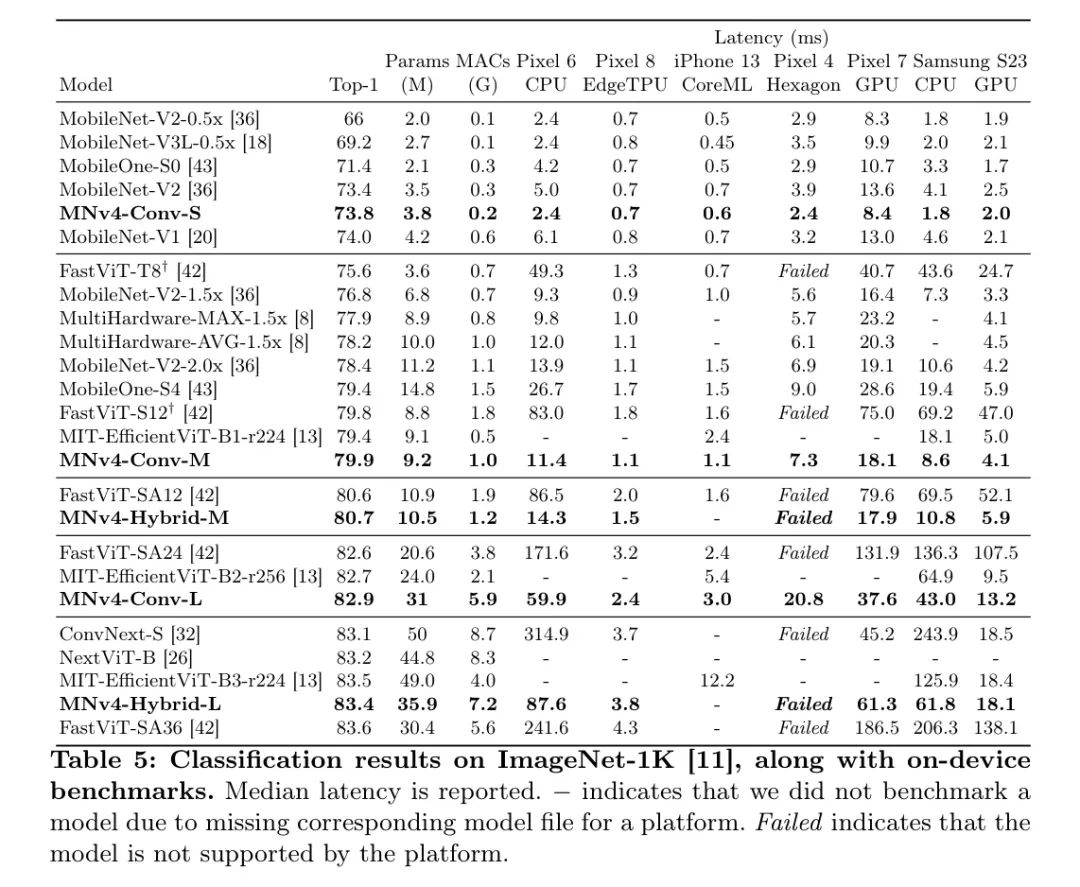
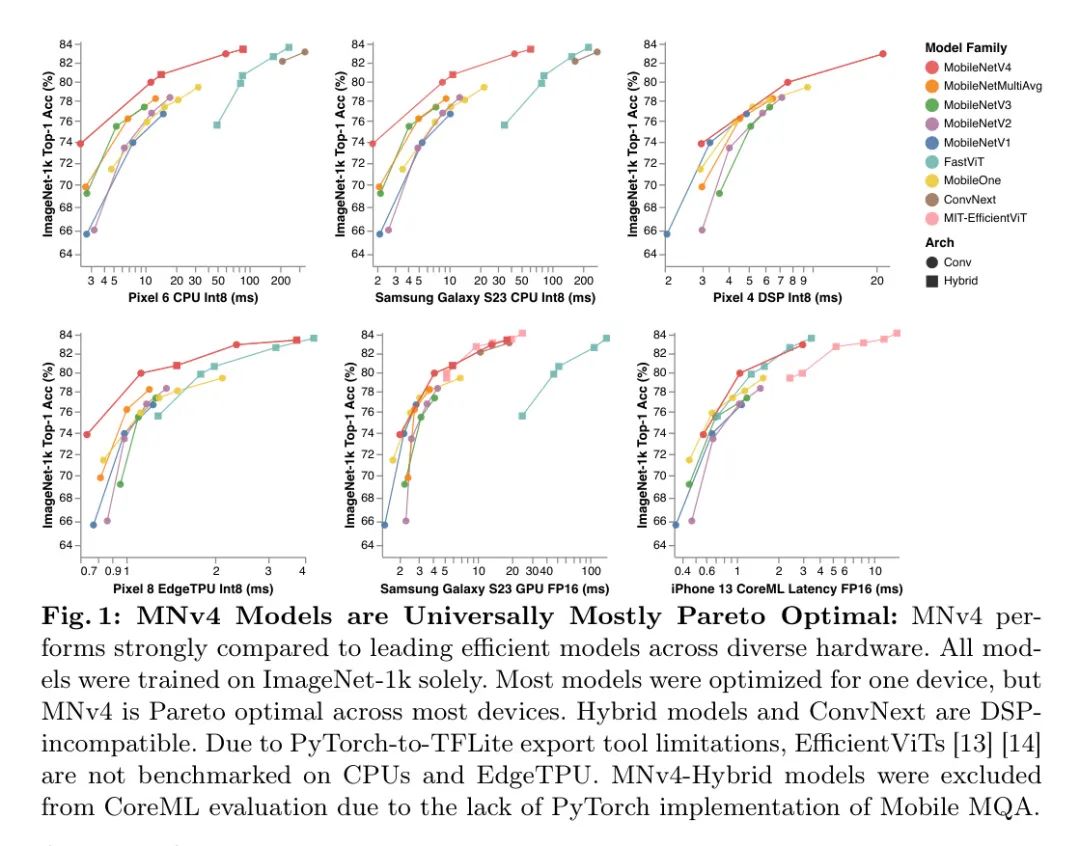
在CPU上,MNv4模型显著优于其他模型,其速度大约是MobileNetV3的两倍,与同等准确度目标的其他模型相比,速度要快几倍。在EdgeTPU上,MNv4模型在相同准确度水平下的速度是MobileNetV3的两倍。特别是,MNv4-Conv-M模型比MobileOne-S4和FastViT-S12快了50%以上,同时在可比延迟下,比MobileNetV2的Top-1准确度提高了1.5%。在S23GPU和iPhone13CoreML(ANE)上,MNv4模型大多数都处于Pareto前沿。在S23GPU上,最接近的竞争对手MIT-EfficientViT,其速度超过了。
在相同的准确度下,MNv4在CoreML上的延迟是两倍。针对AppleNeuralEngine进行优化的FastViT在CoreML上排名第二,但在S23GPU上的延迟是MNv4的五倍以上。与许多混合模型一样,MNv4混合模型与DSP不兼容。尽管如此,MNv4-Conv模型在DSP上仍然表现最佳,突显了它们在多样化硬件平台上的领先兼容性和效率。MNv4-Conv模型提供了卓越的硬件兼容性和效率。这一成功凸显了作者的UIB块、增强的NAS配方以及精心设计的搜索空间的强大。MNv4-Hybrid在CPU和加速器上实现了优异的性能,展示了作者MobileMQA设计的跨平台效率。
普遍性对于移动模型至关重要,它要求这些模型能够在多样化的硬件平台上实现最佳性能。作者的评估突显出现有模型在实现这一目标时所面临的挑战。MobileNetV3在CPU上的表现不错,但在EdgeTPUs、DSPs和GPU上则有所不足。FastViT在苹果神经引擎上表现良好,但在CPU和GPU上则表现挣扎。EfficientViT在GPU上的性能较好,但在苹果神经引擎上的表现就不尽如人意。相比之下,MNv4-Conv模型展现出了异常好的兼容性,并在包括CPU、GPU、苹果神经引擎和谷歌EdgeTPUs在内的广泛硬件上实现了几乎普遍的帕累托最优性能。这种多用途性确保了MNv4-Conv模型可以在移动生态系统间无缝部署,无需进行任何平台特定的调整,为移动模型的普遍性树立了新的基准。
COCO Object Detection
实验设置: 作者在COCO17数据集上评估了MNv4Backbone网络在目标检测任务中的有效性。作者将M尺寸的MNv4Backbone网络与具有相似MACs数量的SOTA高效Backbone网络进行了比较。对于每个Backbone网络,作者使用RetinaNet框架构建了一个目标检测器。作者在P3- P7端点附加了一个256维FPN解码器和一个带有4个卷积层的256维预测头。像移动检测器一样,作者采用深度可分离卷积来降低FPN解码器和边界框预测头的计算复杂性。作者在COCO17训练集上对所有模型进行了600轮训练。
所有图像都被调整到,并使用随机水平翻转、随机缩放以及Randaug进行增强。作者从Randaug中排除了剪切和旋转增强,因为这些形变会降低小目标检测的AP。训练使用2048的批量大小,Adam优化器和0.00003的L2权重衰减。作者使用带有24个周期Warmup的余弦学习率计划,并分别为每个模型调整学习率。对于所有Baseline,作者将滤波器乘数设置为大致可比较的MACs。遵循分类实验,MobileNetV4Backbone网络使用0.2的随机丢弃率进行训练。所有MobileNetBaseline都使用了官方TensorflowModelGarden的实现进行了训练。作者使用Tensorflow重新实现了EfficientFormer。
结果: 表6报告了实验结果。在输入分辨率下,使用整个检测器计算参数、MACs和基准。仅中等尺寸卷积的MNv4-Conv-M检测器达到32.6%的AP,与MobileNetMulti-AVG和MobileNetv2相似。然而,这个模型在Pixel6CPU上的延迟比MobileNetMulti-AVG低12%,比MobileNetv2低23%。在Pixel6CPU延迟增加18%的情况下,加入MobileMQA块使MNv4-Hybrid-M检测器的AP比MNv4-Conv-M提高了+1.6%,这表明MNv4以其混合形式在目标检测等任务中的有效性和高效性。

8 Enhanced distillation recipe
在补充架构创新的同时,蒸馏是一种提高机器学习效率的强大工具。其对移动模型的益处尤为显著,在严格的部署约束下,可能提供数倍的效率提升。基于稳固的“PatientTeacher”蒸馏基准,作者引入了两项新技术来进一步推动性能的提升。
动态数据集混合: 数据增强对于提取性能至关重要。尽管先前的方法依赖于固定的增强序列,但作者发现动态地混合多个具有不同增强策略的数据集会导致更优的提取结果。作者对三个关键提取数据集进行了实验:
: 对500个ImageNet-1k复制品应用InceptionCrop 后续使用RandAugment I2m9。
: 采用InceptionCrop后接着应用极端Mixup 方法于 1000 个ImageNet-1k复制品(模仿耐心教师方法)。
在训练过程中, 和 的动态混合。
作者的表7结果显示, 在学生准确度上优于 对 。然而, 动态混合数据集 将准确度提升到了 。这一发现表明, 数据集混合扩展了增强图像的空间, 增加了难度和多样性, 最终导致了学生表现的提升。
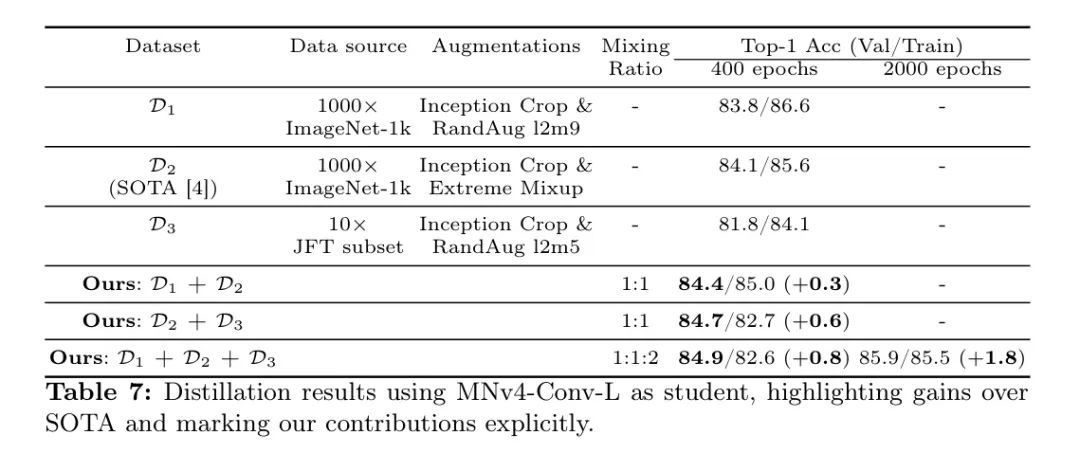
JFT数据增强: 为了增加训练数据量,作者通过重新采样JFT-300M 数据集,以使每个类别包含13万张图片(总计1.3亿张),加入领域内、类别平衡的数据。遵循NoisyStudent 协议,并使用在ImageNet-1K上训练的EfficientNet-B0。
阈值高于0.3。对于数据丰富的类别,作者选择了前130K张图片;对于稀有类别,作者复制图片以保持平衡。这个数据集被复制了10倍。由于JFT的复杂性,作者应用了较弱的增强方法(Inception裁剪+RandAugmentl2m5)。这形成了蒸馏数据集。表7显示,仅使用JFT()会导致准确率下降2%。然而,将JFT与ImageNet数据结合使用则带来了0.6%的改进,这证明了额外数据对于泛化的价值。
作者的精炼方法: 作者的综合精炼方法动态混合数据集, 和 以实现多样的增强,并利用类别平衡的JFT数据。正如表7和表8所示,与先前的SOTA相比,作者的方法一致性提高了超过0.8%的top-1准确率。对MNv4-Conv-L学生模型进行2000个周期的训练,得到85.9%的top-1准确率。这证明了作者方法的有效性:学生模型在参数上比其教师模型EfficientNet-L2小15倍,在MACs上小48倍,但准确率下降仅为1.6%。当结合在JFT上的预训练进行精炼时,MNv4-Conv-Hybrid达到了87.0%的top-1准确率。

9 Conclusion
在本文中,作者提出了MobileNetV4,这是一系列通用的、高效的模型,旨在在整个移动生态系统内高效运行。作者利用了多项进展,使MobileNetV4几乎在所有的移动CPU、GPU、DSP以及专用加速器上达到帕累托最优,这是其他任何模型所不具备的特性。
作者测试了多种模型。作者引入了新的通用反转瓶颈和移动MQA层,并结合了改进的神经架构搜索(NAS)方法。将这些与一种新颖的、最先进的蒸馏方法相结合,作者在Pixel8EdgeTPU上以3.8毫秒的延迟达到了87%的ImageNet-1K准确度,推进了移动计算机视觉的最新技术水平。此外,作者还提出了一种理论框架和分析方法,以理解是什么让模型在异构设备上具有通用性,这为未来的设计指明了方向。作者希望这些新颖的贡献和分析框架能进一步推动移动计算机视觉的发展。
搜索空间构建:
固定初始层:作者首先在第一阶段使用了一个Conv2D层(3x3核,步长2)以便快速降低分辨率,随后在第二阶段采用了NAS优化的融合IB块(步长2),以平衡效率和准确性。
NAS驱动的优化:NAS过程精确地确定了在剩余四个阶段中UIB块的数量和参数实例化,确保了性能的最优结构。
固定Head层:作者使用了与MobileNetV3相同的Head层配置。
观察到在UIB块内的点式卷积在高分辨率下往往表现出较低的运算强度,作者优先在初始层中使用计算密度更高的操作,以平衡效率和准确度。
作者的优化目标:
MNv4-Conv-S:双重目标——285MMACs和0.2ms延迟(Pixel6EdgeTPU,224px输入)。
MNv4-Conv-M:0.6毫秒延迟(Pixel6EdgeTPU,256像素输入)。
MNv4-Conv-L:针对384px输入,双重延迟目标为2.3ms(Pixel6EdgeTPU)和2.0ms(Pixel7EdgeTPU)。
需要注意的是,通过将作者的搜索空间限制在跨设备具有良好相关成本模型的组件上,作者发现EdgeTPU延迟优化可以直接产生普遍高效的模型,这一点在后文中有详细演示。
Appendix0.B Benchmarking methodology
作者在各种移动平台上应用了一致的基准测试策略,对苹果神经引擎(AppleNeuralEngine)做了例外处理。为了提高效率,模型被转换为TensorFlowLite格式,并针对移动CPU、Hexagon和EdgeTPUs量化为INT8,而移动GPU则使用FP16。作者每个模型运行1000次,并取那些运行的平均延迟。然后,作者对每个模型重复该过程5次,并报告均值的中间值。为了优化性能,作者将CPU亲和性设置为最快的核心,并在CPU评估中使用XNNPACK后端。相比之下,对于苹果神经引擎的基准测试(在配备iOS16.6.1、CoreMLTools7.1和Xcode15.0.1的iPhone13上进行性能分析),PyTorch模型被转换为CoreML的MLProgram格式,以Float16精度,使用float16的MultiArray输入以最小化输入复制。
Appendix0.C Training set up for ImageNet-1k classification
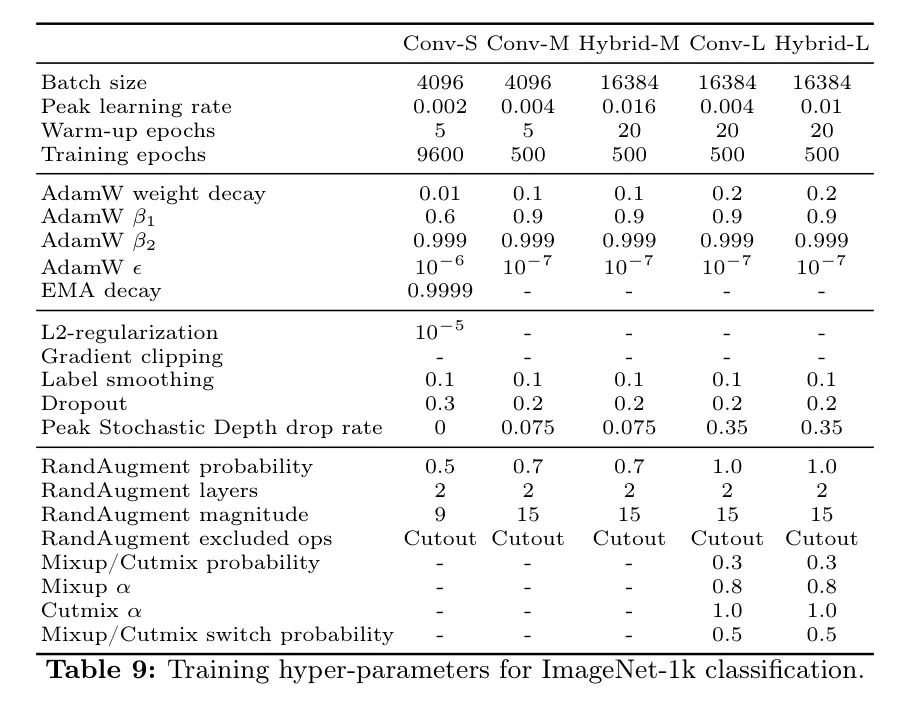
为了提升模型性能,作者的训练方法融合了广泛采用的数据增强技术和正则化方法。在数据增强方面,作者使用了Inception裁剪,水平翻转,RandAugment,Mixup,以及CutMix。在正则化方面,作者应用了L2规范化和随机深度丢弃。增强和正则化的强度根据模型大小进行调整,具体细节见表9。
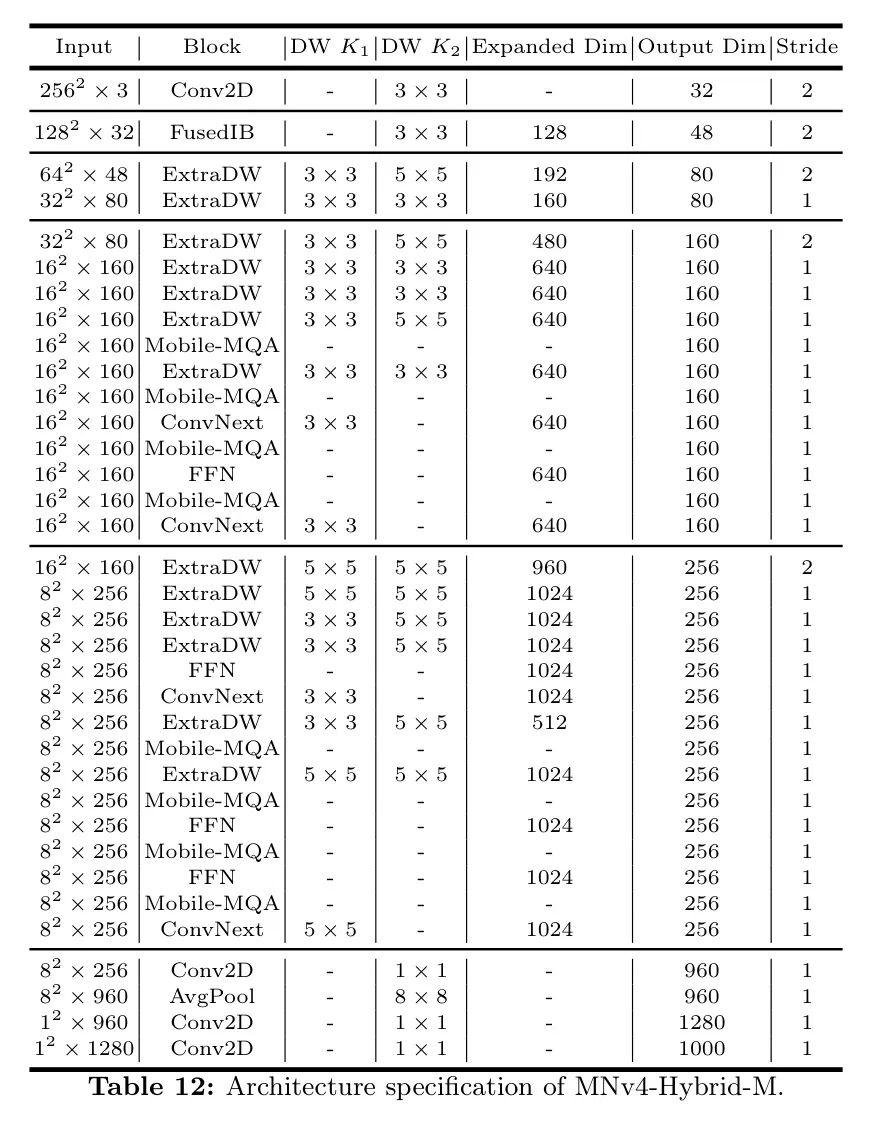
Appendix0.DModeldetails
作者的MNv4模型的架构细节从表10到表14进行描述。
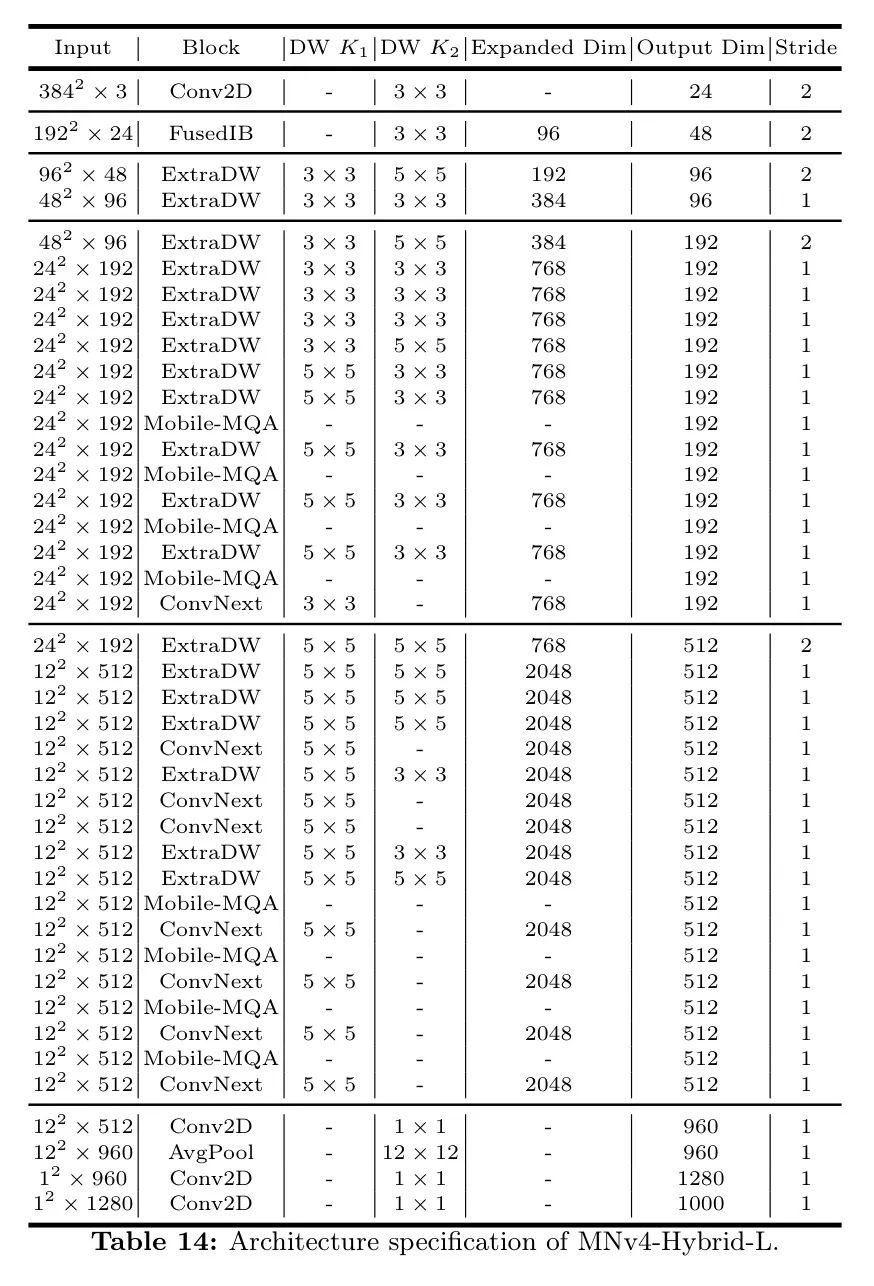

现在,让作者详细审视一下TuNAS优化后的MNv4-Conv模型。TuNAS优化的宏观架构策略性地结合了四种UIB实例:ExtraDW、ConvNext、IB和FFN。这种组合展示了UIB的灵活性以及在不同网络阶段使用不同实例化块的重要性。具体来说,在每一个可搜索阶段的开始,空间分辨率显著降低的地方,ExtraDW成为首选。ExtraDW中双深度分离层的设计有助于扩大感受野,增强空间混合,有效减轻分辨率损失。同样,由于类似的原因,ExtraDW也经常在MNv4-Conv模型的早期阶段被选择。对于最后的层,由于前面的层已经进行了大量的空间混合,选择了FFN和ConvNext,因为通道混合提供了更大的增益。
表12:* MNv4-Hybrid-M的架构规格。

参考
MobileNetV4- UniversalModelsfortheMobileEcosystem
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!
自动驾驶感知:目标检测、语义分割、BEV感知、毫米波雷达视觉融合、激光视觉融合、车道线检测、目标跟踪、Occupancy、深度估计、transformer、大模型、在线地图、点云处理、模型部署、CUDA加速等技术交流群;
多传感器标定:相机在线/离线标定、Lidar-Camera标定、Camera-Radar标定、Camera-IMU标定、多传感器时空同步等技术交流群;
多传感器融合:多传感器后融合技术交流群;
规划控制与预测:规划控制、轨迹预测、避障等技术交流群;
定位建图:视觉SLAM、激光SLAM、多传感器融合SLAM等技术交流群;
三维视觉:三维重建、NeRF、3D Gaussian Splatting技术交流群;
自动驾驶仿真:Carla仿真、Autoware仿真等技术交流群;
自动驾驶开发:自动驾驶开发、ROS等技术交流群;
其它方向:自动标注与数据闭环、产品经理、硬件选型、求职面试、自动驾驶测试等技术交流群;
扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】硬件专场


