- 1AMEYA360:蔡司辐射损伤智能分析方案
- 2面试题总结(简答)_容量测试 通用测试用例
- 3移动文件如何保留原有的权限设置
- 4IDEA安装及使用详细教程_csdn idea
- 5Exception in thread “main“ java.lang.NoClassDefFoundError: org/junit/platform/launcher/TestIdentifie_exception in thread "main" java.lang.noclassdeffou
- 6假设检验_零假设是我们的模型被正确指定,我们有强有力的证据来拒绝这个假设。因此,我们有充
- 7ORACLE-安装PL/SQL developer连接oracle数据库_pl/sql develop 安装并连接oracle
- 8pytorch入门3--一些概念补充、线性回归以及许多python,pytorch函数的用法_pytorch中def extractor代表什么意思
- 9chatGPT爆火,什么时候中国能有自己的“ChatGPT“_csdnchat 中国gpt
- 10python把视频取帧_用Python提取视频帧
情感语音转换学习_基于文本的情感语音生成
赞
踩
情感语音转换(Emotional Voice conversion)
言语不仅仅是词汇,它承载着说话者的情感。之前的研究(Mehrabian和Wiener, 1967)表明,在交流情感和态度时,口头语言只传达了7%的信息,非语言的声音属性(38%)和面部表情(55%)对社会态度的表达有重大影响。非言语的声音属性反映了说话者的情绪状态,在日常交流中起着重要的作用(Arnold, 1960)。
情感语音转换(EVC)侧重于将语音从源情感转换为目标情感;因此,它可以成为人机交互应用和其他应用的关键促成技术。然而,EVC仍然是一个悬而未决的研究问题,面临着一些挑战。特别是,由于语速和节奏是情绪转换的两个关键因素,模型必须生成不同长度的输出序列。序列到序列建模最近正成为一种能够克服这些挑战的模型的竞争范式。
引言
什么是情感语音转换?
情感语音转(EVC)是一种将话语的情感状态从一种转换为另一种,同时保留语言信息和说话人身份的技术。
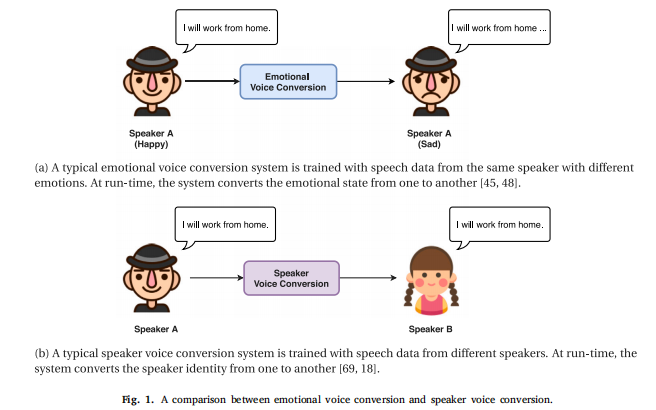
语音转换和情感语音转换的异同?
语音转换(VC)的目的是转换人类语音中的说话人身份,同时保留其语言内容,也称为说话人语音转换(speaker voice conversion)。
语音转换的最新进展成为情感语音转换研究的灵感来源。
说话人语音转换和情感语音转换的目的都是保存语音内容和转换副语言信息。在说话人语音转换中,说话人的身份被认为是由说话人的物理属性来表征的,这是由个人的声音质量决定的,所以转换只关注谱的映射,对基频只是进行简单的线性变换。而在情感语音转换中,情感本质上是超音段复杂的,涉及频谱和韵律因此,通过谱映射来转换情绪不足以表达,音段层级的韵律变化动态也需要考虑。
下面一张图说明了两者异同。
概述
如何描述和表示情感语音?
情感可以用分类来描述或维度表示。对于表示情绪的标签,情绪类别方法是表示情绪最直接的方法。最著名的分类方法之一是Ekman的六种基本情绪理论,将情绪分为六个离散的类别,即愤怒、厌恶、恐惧、快乐、悲伤和惊讶,在许多情绪语音合成研究中被采用。然而,这种离散的表示并不寻求模拟人类情感中的微妙差异来控制渲染语音。另一种方法是模拟情绪表达的物理特性。一个例子是罗素的环状模型,由觉醒、效价和支配性定义。例如,在价态唤醒(V - A)表征中,快乐言语的特征是积极的价态和唤醒值,而悲伤言语的特征是所有的负值。另一方面,愤怒又可分为热愤怒和冷愤怒,分别对应心理学上的全面愤怒和温和愤怒。
总之,情绪的分类和维度表示都已广泛应用于情绪识别和情绪语音转换。 表征学习研究代表了一种新的情绪表征方式,但需要大规模的情绪标注语音数据 。
如何模拟人类情感表达和感知的过程?
Brunswik的模型中认为情绪的感知是多层次的,该模型已广泛应用于语音情感识别,其中情感类别、语义基元和声学特征分别构成了从上到下的层次,并假设情绪产生是情绪感知的逆过程。
在与情绪相关的研究中,常用的声学特征如语音质量、语音速率和基频(F0)的韵律特征,如频谱特征、持续时间、F0轮廓和能量包络。在情感语音转换中,我们感兴趣的是转换这种声学特征来渲染情绪。在情感识别中,我们也依赖于类似的声学特征,例如专家制作的特征如使用openSMILE提取的特征,并从频谱中学习声学特征。在情感语音合成中,两者都基于规则和数据驱动技术包括统计建模或深度学习方法,依赖语音数据库进行情绪分析和产生。
随着深度学习的出现,人们用神经网络学习的深度特征来描述连续空间中的不同情感风格。与人工制作的特征不同,深层情感特征对人类知识的依赖较少,因此更适合情感风格的转移。最近,深度情感特征已用于情感语音转换。
转换模型
模型可以分为多类,如按训练数据,可分为并行数据和非并行数据。
EVC是情感语音合成ESS领域的一个分支。
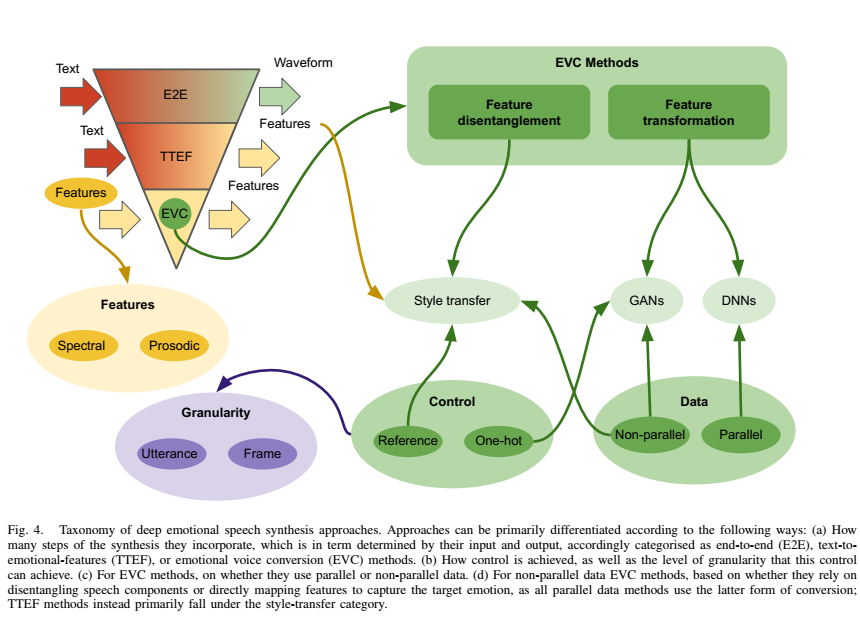
总结可以看出:
并行数据以DNN,LSTM模型为主,主要是做特征变换;
非并行数据以GAN为主,做风格迁移,主要是特征解耦。
基于并行数据
早期关于情绪语音转换的研究大多依赖于并行训练数据,即同一说话人的一对内容相同但情绪不同的话语。在训练过程中,转换模型通过配对的特征向量学习从源情绪A到目标情绪B的映射。一般来说,如图2所示,情感语音转换过程通常包括三个步骤,即特征提取、帧对齐和特征映射。并行数据需要帧对齐,方法有动态时间规整(DTW)和基于模型的语音识别器对齐或注意机制。
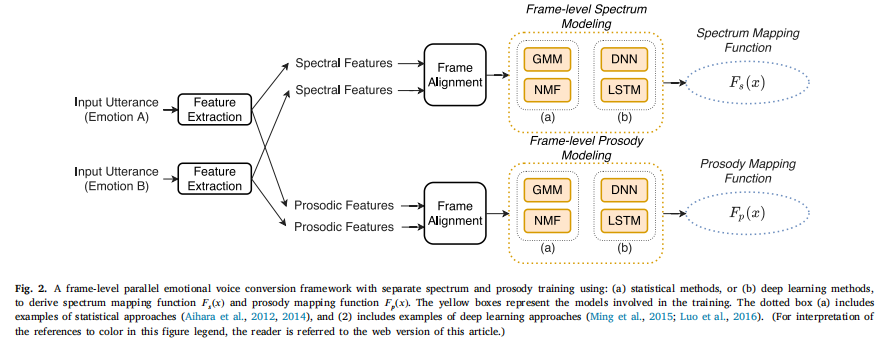
特征提取:
通常使用来自高维谱的低维谱表示进行建模。常用的谱特征包括mel -倒谱系数(MCC)、线性预测倒谱系数(LPCC)和线谱频率(LSF)。
通常会考虑几个韵律特征,如音高、能量和持续时间。注意F0是一个重要的韵律成分,它描述了从音节到话语的不同持续时间内的语调。建模F0变量的方法包括风格化方法和多层次建模。连续小波变换(continuous wavelet transform, CWT)作为一种多层次的建模方法,已被广泛用于分层韵律特征的建模,如F0 (Suni et al., 2013;Ming等,2015;Luo等人,2017)和能量等值线(Şişman等人,2017;Sisman and Li, 2018b;Sisman等人,2019b)。CWT分析可以将信号分解为不同的频率分量,并用不同的时间尺度表示。CWT已被证明是语音韵律建模的有效方法(Ming等人,2016b;Suni等人,2013),并已成功应用于各种情感语音转换。
特征映射:
1.传统统计建模:
在Tao et al.(2006)和Wu et al.(2009)中提出使用分类和回归树将源语音的基音轮廓分解为层次结构,然后采用GMM和基于回归的聚类方法。 Aihara等人(2012)提出了一种基于GMM的情感语音转换框架来学习频谱和韵律映射。 Aihara等人(2014)引入了一种基于样本的情感方法,其中使用并行样本对源语音信号进行编码并合成目标语音信号,该思想进一步扩展为统一的基于范例的情感语音转换框架(Ming等人,2015),该框架同时学习频谱特征和基于cwt的F0特征的映射。
2. 基于神经网络:
DNN (Lorenzo-Trueba等人,2018a)、深度信念网络(DBN) (Luo等人,2016)、神经网络(Shankar等人,2019a)和DBLSTM (Ming等人,2016a)是使用并行训练话语执行频谱和韵律映射的例子。 值得注意的是,帧级特征映射并没有明确地处理持续时间的映射,而持续时间是韵律的一个重要元素。
3.基于序列-序列:
编码器-解码器架构代表了持续时间映射的解决方案(Sutskever等人,2014; Vaswani等人,2017)。 通过注意力机制,神经网络在训练过程中学习特征映射和对齐,并在运行时推理时自动预测输出持续时间。 编码器-解码器模型(Robinson等人,2019)就是一个例子,其中对音高和持续时间进行了联合建模。
一般来说,更精确的对齐将有助于构建更好的特性映射函数,这也解释了为什么这些框架都是用并行数据构建的。
基于非并行数据
在实际应用中,并行语音数据采集成本高且难度大,因此非并行数据的情感语音转换技术更适合于现实生活应用。我们将非平行数据用于多情感话语,即在不同情感之间并不共享相同的词汇内容。神经网络为非并行数据的情感语音转换框架成为可能。两种最典型的非并行方法,即(1)auto-encoder (Kingma and Welling, 2013)和(2)CycleGAN (Zhu et al., 2017)方法。我们将从非并行训练数据中学习的方法归纳为三种场景:
- 情感域间翻译
- 情感韵律与语言内容的解耦
- 利用TTS或ASR系统辅助
下面分别介绍:
1.情感域间翻译(Emotional domain translation)
源域和目标域之间的翻译模型,常见的例如GAN、CycleGAN、Augmented CycleGAN和StarGAN,这些模型早期在在计算机视觉问题中应用。
下图是典型的CycleGAN模型,基本原理搜我其他博客。
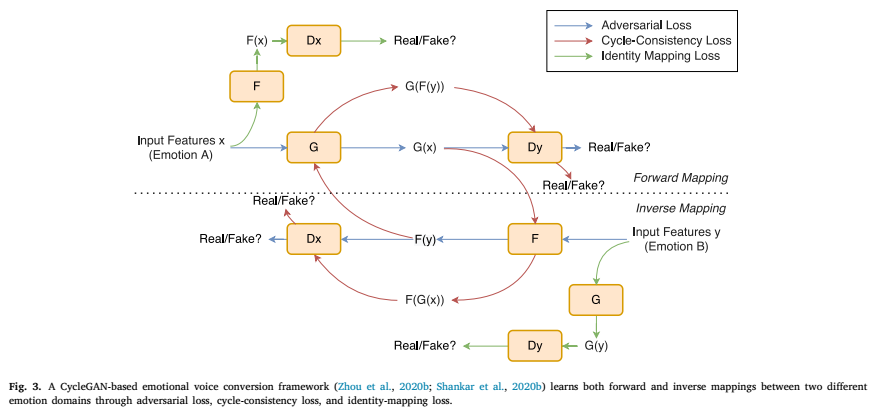
在情感域翻译中,cyclegan被用于对源和目标之间的频谱和韵律映射进行建模。例如,Shankar等人提出了一种混合隐式正则化的CycleGAN自适应模型来预测F0轮廓,其中生成器由可训练组件和静态组件组成。
2.情感韵律与语言内容的解耦(Disentanglement between emotional prosody and linguistic content)
如果我们能够将情感风格从语言内容中分离出来,我们就可以在不改变语言内容的情况下独立地修改情感风格。常见的模型如自编码器及其变体。
下图是典型的自编码器模型,基本原理搜我其他博客。

典型的基于自编码器的情感语音转换主要由三个部分组成,即(1)编码器;
(2)生成器,(3)鉴别器。
在实践中,我们可以训练情感分类器从语音中获得深度特征表示,即深度情感特征。然后在训练过程中,以这种深层情感特征或one-hot情感表示为条件来训练生成器。这样,我们就以一种无监督的方式从语音中学习到框架级的内容相关表示,这种模型有VAE-GAN,VAW-GAN。另一种思路是让自编码器在隐空间中学习一种情绪不变的潜码和一种情感相关的风格码。为此,使用一对内容编码器和风格编码器来将情感风格从说话内容中分离出来。
目前较新的研究以说话人嵌入表示speaker embedding 为代表,如i-vector, d-vector, x-vector, v-vector等。能实现说话人音色和内容信息分离的模型如:DGANVC、AdaIN-VC和AUTOVC。
语音转换模型:
最近的VC模型遵循通用的编码器-解码器架构:
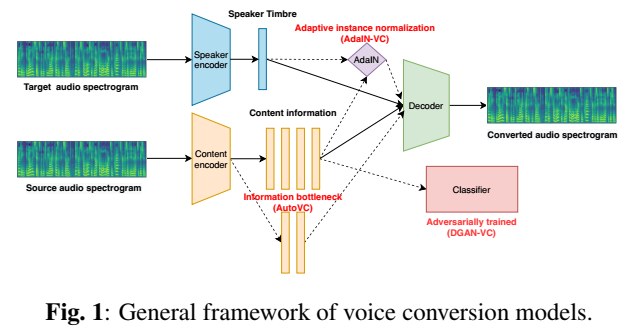
编码器:
- 音质:由speaker encoder Es提取
- 内容:由content encoder En提取
解码器:D
DGAN-VC:
采用两阶段训练框架进行多对多语音转换。Es提供one-hot向量作为说话人嵌入来表示不同的说话人。在第一阶段,使用一个额外的分类器,将内容表示作为输入并对抗训练,以获得与说话人无关的语言信息。在第二阶段,采用生成对抗网络(GAN)使输出谱更真实。
AdaIN-VC:
采用变分自编码器(VAE)作为内容编码器,其中隐层表示受KL散度损失的限制,并采用自适应实例归一化(AdaIN)实现zero-shot VC。Ec中使用的实例归一化在保留内容信息的同时去除了音色信息,然后由Es通过AdaIN层将音色信息提供给解码器。
AUTOVC:
是一个精心设计的自编码器,只有自重构损失训练的信息瓶颈t特征。信息瓶颈是Ec和D之间的潜在向量的维度。有了瓶颈,语言内容和音色信息在没有明确约束的情况下被解耦,后者在解码时由预训练的D向量提供。
说话人嵌入表示Speaker Embedding
说话人嵌入或说话人表示(Speaker embeddings, or speaker representations)广泛应用于说话人验证和语音转换。
i-vector:
说话人和话语相关GMM超向量M建模为:M = m + T w
其中m表示与说话人无关的GMM超向量,T是捕获说话人和话语可变性的低秩总可变性矩阵。i-vector就是w的最大后验点估计。
D-vector:
采用DNN作为说话人特征提取器,利用说话人识别任务或GE2E损失。最后一个隐藏层的输出作为说话人的压缩表示,称为d-vector。
X-vector:
使用延时神经网络(TDNN)来学习时间上下文信息。它在说话人识别任务上进行训练,最后一层隐藏层的输出作为说话人的表示,称为x-vector。
V-vector:
是本文引入的一个新概念,它被定义为与VC模型联合训练的说话人编码表示。
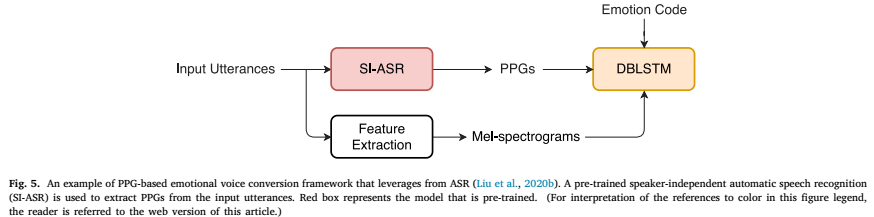
3.利用TTS或ASR系统辅助(Leveraging TTS or ASR systems)
TTS:
受说话人语音转换成功的启发,研究了情感语音转换和文本到语音之间的多任务学习(Kim et al., 2020)。在该框架中,单个序列到序列模型被训练来优化VC和TTS,其中VC系统受益于由TTS期间的培训。推理时,给定一个参考语音,系统可以将输入话语的情感风格从一个转移到另一个。实验结果也表明具有多任务学习功能的VC和TTS系统表现较好。
ASR:
情绪言语的韵律呈现包括说话人依赖和说话人独立,这使得仅从多说话人数据库中学习情绪相关信息具有挑战性(Sisman和Li, 2018b;Zhou et al., 2020c)。如图5所示,利用语音后图(ppg)作为情感语音转换的辅助输入特征(Liu et al., 2020b)。ppg是由ASR系统衍生而来的,它被认为是独立于说话者和情感的。利用ppg的语音信息,所提出的情感语音转换系统对多说话人、多情感语音数据具有较好的泛化能力。总的来说,这些框架显示了多任务学习或迁移学习的有效性,这代表了未来研究的潜在方向。
下图是一个典型的利用ASR产生PPG特征辅助EVC的框架