
- 1Web框架开发-Django-Form组件归类
- 2GLM 130B和chatGLM2-6B模型结构_chatglm 结构图
- 3SQL,group by分组后分别计算组内不同值的数量
- 4vue学习笔记——Vue3循环生成表单时,对每一行新生成的数据添加表单验证的方法
- 5【信息抽取】NLP中关系抽取的概念,发展及其展望
- 6【数据结构课程设计系列】农夫过河问题操作演示_基于谓词表示的农夫过河问题
- 7如何彻底解决小程序滚动穿透问题_scroll-view滚动穿透
- 8后台 配置页面功能设计_配置操作指南功能的后台页面
- 9【黄啊码】php实现关注公众号自动回复消息(网上教程有大坑,慎用)_微信公众号关注回复源码
- 10人工智能 AI 概念梳理_ai概念
大型语言模型综述,非常详细,格局打开!A Survey of Large Language Models
赞
踩
大型语言模型综述,非常详细,格局打开!A Survey of Large Language Models
1.导读
讲得通俗易懂,且格局拉满!基本覆盖了自ChatGPT以来的AI比较火的事件,还多次提到强人工智能AGI(人工通用智能)。对近几年的大型语言模型( Large Language Models)进行了详细介绍。非常建议感兴趣大模型和强人工智能的读者阅读!!!
2.摘要和引言
从图灵测试开始讲起,人类一直在探索用机器掌握语言智能的方法。
在过去20年,语言模型得到了广泛研究。从统计语言模型到了基于神经网络的语言模型(LSTM等)。
最近这些年,通过在大规模语料库(数据集)上对Transformer模型的预训练,提出了预训练语言模型(PLMs),在解决各种自然语言处理(NLP)任务方面显示出了很强的能力。
近一两年(从20年的GPT-3开始),发现当参数尺度超过一定水平时,这些扩展的语言模型不仅实现了显著的性能提高,而且还表现出一些小规模语言模型(如BERT)中不存在的特殊能力(如上下文学习)。为了区分不同参数尺度下的语言模型,研究界创造了术语大型语言模型(LLM),用于描述具有显著规模的PLM(例如,包含数百亿或数千亿个参数)的PLM。
近半年来,ChatGPT(基于LLM开发的强大的人工智能聊天机器人)的推出,引起了社会的广泛关注。
总的来说,语言模型LM经过了如下4个阶段:
- STM(统计语言模型):例如基于马尔科夫链预测下个词。
- NLM(神经语言模型/基于神经网络的语言模型):例如RNN、LSTM等。
- PLM(预训练语言模型):例如GPT-1,GPT-2,Bert等。与NLM的不同是,将语言模型做成了“一劳永逸”的形式,即一个模型可以做很多事,只要训练了一个模型后,不需要下游任务进行复杂的微调。其中GPT-2将模型做成了Zero-shot的形式大大加强了预训练语言模型的性能。
- LLM(大型语言模型):GPT-3,PALM、ChatGPT、LLaMA、GPT-4等。与PLM最直观的不同是模型大了,训练数据多了。
作者在这给出了LLM出现后的3个情况:
- LLM涌现出PLM中未出现的性能。LLM更大GPT-3是第一个将模型大小扩展到千亿参数的模型,其涌现出模型较小时未出现的智能。现在的ChatGPT也是。
- 已有都是人来选择使用的LM模型来解决具体的任务,现在是人告诉LLM要干嘛,然后LLM根据要求解决问题。
- 出现了工业界和学业界的划分。以前都基本是学业界引导AI发展,现在出现工业界引导的情况。因为LLM需要大量的资金基础,所以最早的突破来自OpenAI,而非高校。
作者提到了LLM与AGI的联系
OpenAI给出了关于实现AGI的计划。
最近一些研究《Sparks of Artificial General Intelligence: Early experiments with GPT-4》也认为GPT-4已经具备了一定的AGI能力。
作者给出了关于LLM相关文献的回顾,并在github上创建了一个项目
3.回顾
背景
已有的LLM仍然基于Transformer结构。
LLM涌现出的能力
- 上下文理解
- 跟随指令
- 一步一步推理
LLM的关键技术
- 规模:考虑固定模型规模和数据集规模,如何提升模型性能
- 训练:如何降低训练成本
- 能力引出:如何引导出模型已经具备的能力
- 调优:减少有害的输出
- 工具使用:例如使用计算器帮助LLM提升计算能力
LLM模型发展脉络

LLM模型汇总

其他方面LLM模型作者写的还没有这篇公众号清楚。
不过作者在github上给出了很多相关论文地址。
数据集

模型使用的数据集分布

数据处理流程

模型结构

优化设置

4.模型调优
构建指令数流程

指令数据集

RLHF算法(InstructGPT使用的方法)
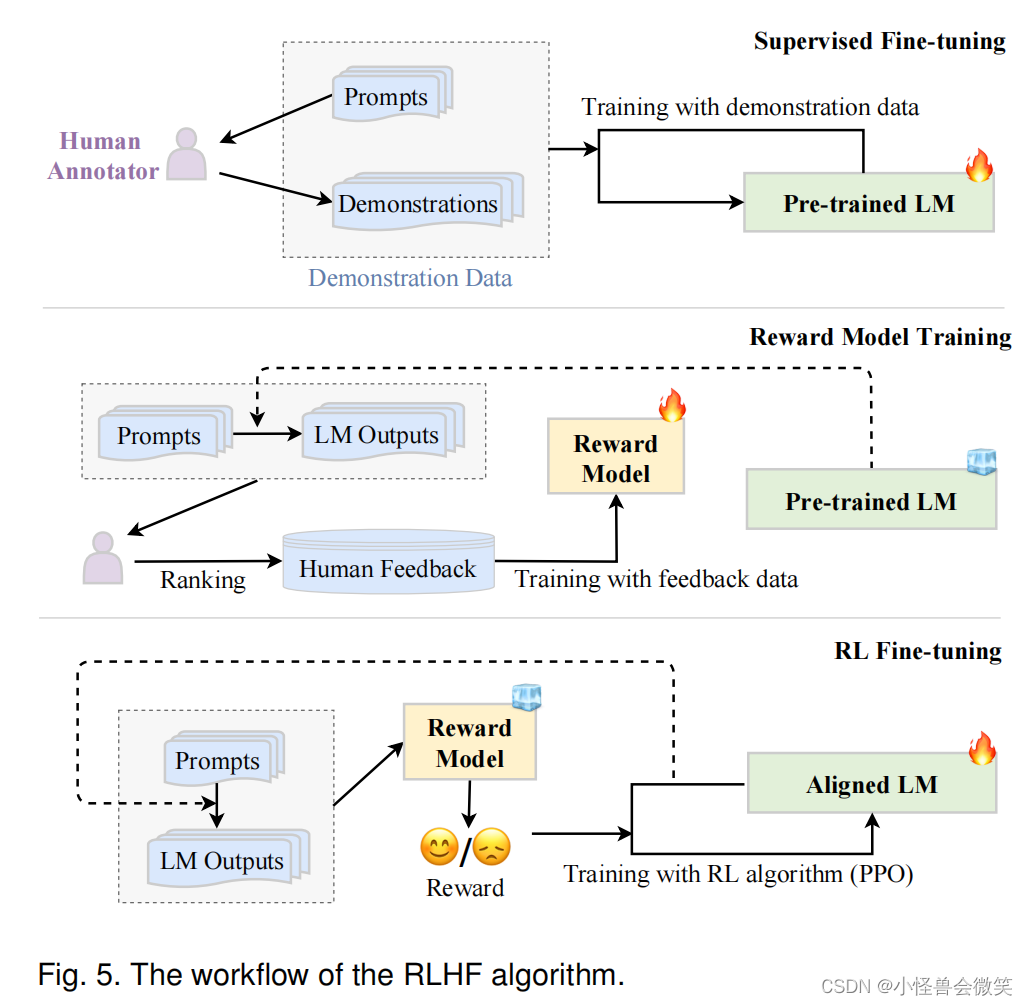
5.评估

未完待续

