
热门标签
热门文章
- 1【OpenCV】颜色空间(RGB,HSV与Gray)及图像处理中的颜色识别_opencv数字图像处理颜色块
- 2用Python制作一个自动抢票脚本_python抢票脚本
- 3STM32F103C8T6最小系统板是一种基于STM32F103C8T6微控制器的开发板,具有丰富的外设和强大的处理能力,适用于各种嵌入式应用开发_stm32f103c8t6最小系统板介绍
- 4Hbase索引_hbase用的什么索引
- 5如何获取OpenCV并于DELPHI10.3中搭建开发环境_open cv library for delphi
- 6android应用去掉状态栏_android去掉状态栏
- 72020年云原生技术关键趋势总结
- 8【Tello无人机】实物轨迹跟踪控制
- 9mysql 安卓lib库_android提供的数据库
- 10Spring AI使用向量数据库实现检索AI对话_spring ai 国内
当前位置: article > 正文
深度学习UNet网络
作者:我家自动化 | 2024-05-20 04:16:34
赞
踩
深度学习UNet网络

DDPM主干模型;

UNet是一种分类网络架构,输入一张图片,网络进行分类是目标物体还是背景像素?
像素级的判断。
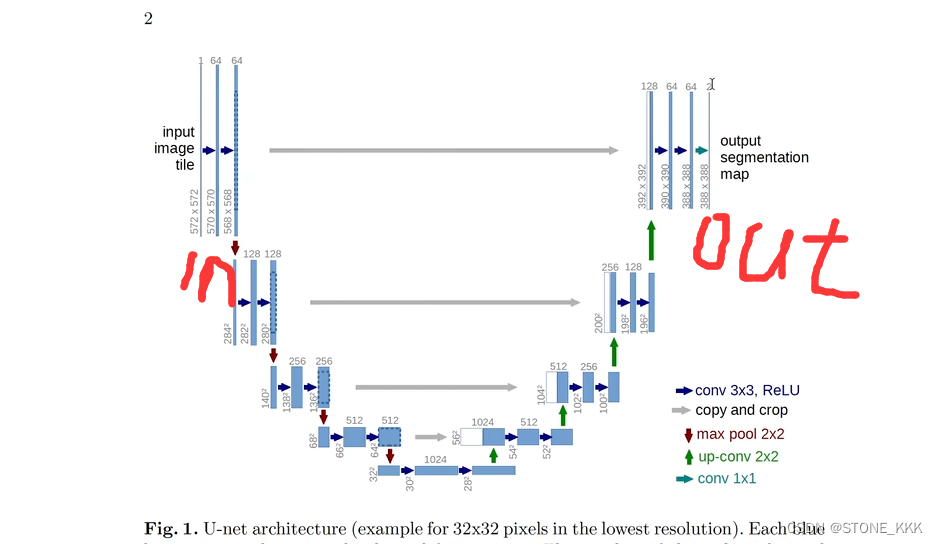
最终输出是单通道388*388
但是输入是572,输入572是填充过来的
而且UNet使用的是镜像填充
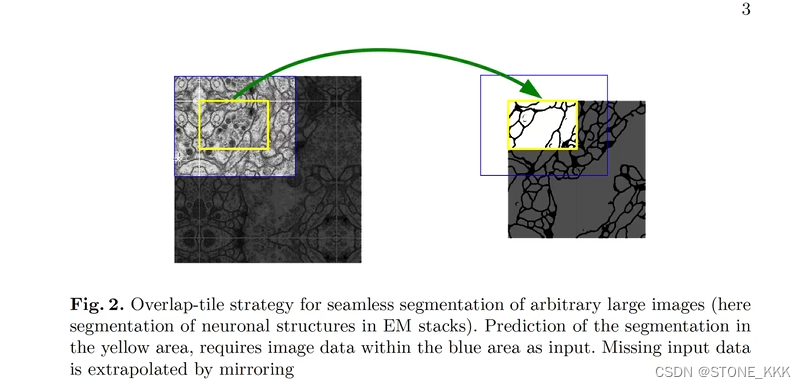
镜像填充目的是为了让像素点具有上下文信 息。
示意图解释:第一阶段分别对图片进行两次的3*3卷积操作,通道数从1扩充到64
第二阶段开始进行最大池化2*2,对图片进行压缩,但是通道数不变。图片尺寸变小一半 284*284,但是之后进行卷积操作3*3但是通道数从640->128其他不变。
后续操作同理。
- 1
- 2
- 3
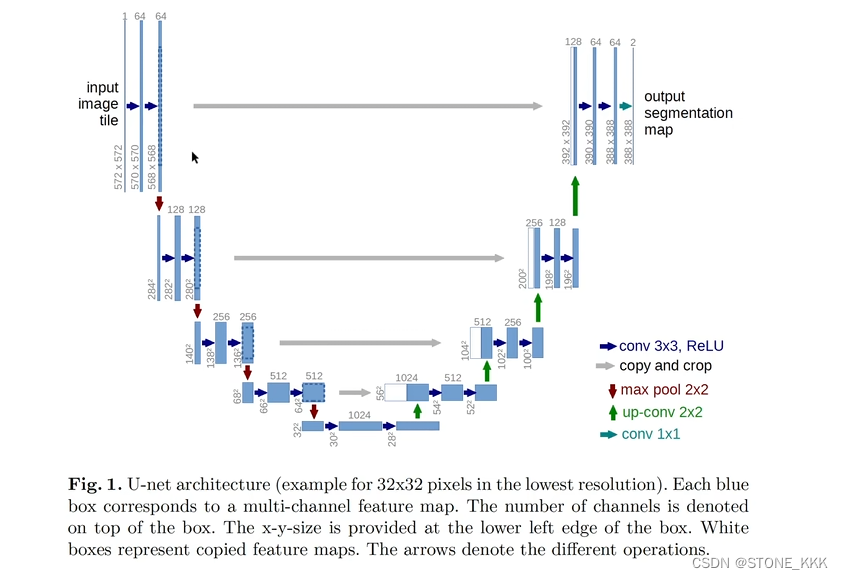
右侧可以理解为一个反卷积或者理解为一个解码器也可以
接下来是上采样的过程,其本质也是一种反卷积
其次就是在进行复原的时候,我们要将高像素的特征进行赋值过来

此过程也可以成为skip connection,但是中间会出现像素不匹配的过程
这样可以进行挖中间部分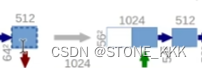
64 挖成56
然后与上采样的特征进行拼接操作
之后进行两个卷积操作,3*3的卷积核,只不过通道数发生改变其他不变。
此图上采样都是运用两次卷积操作,然后通道降维
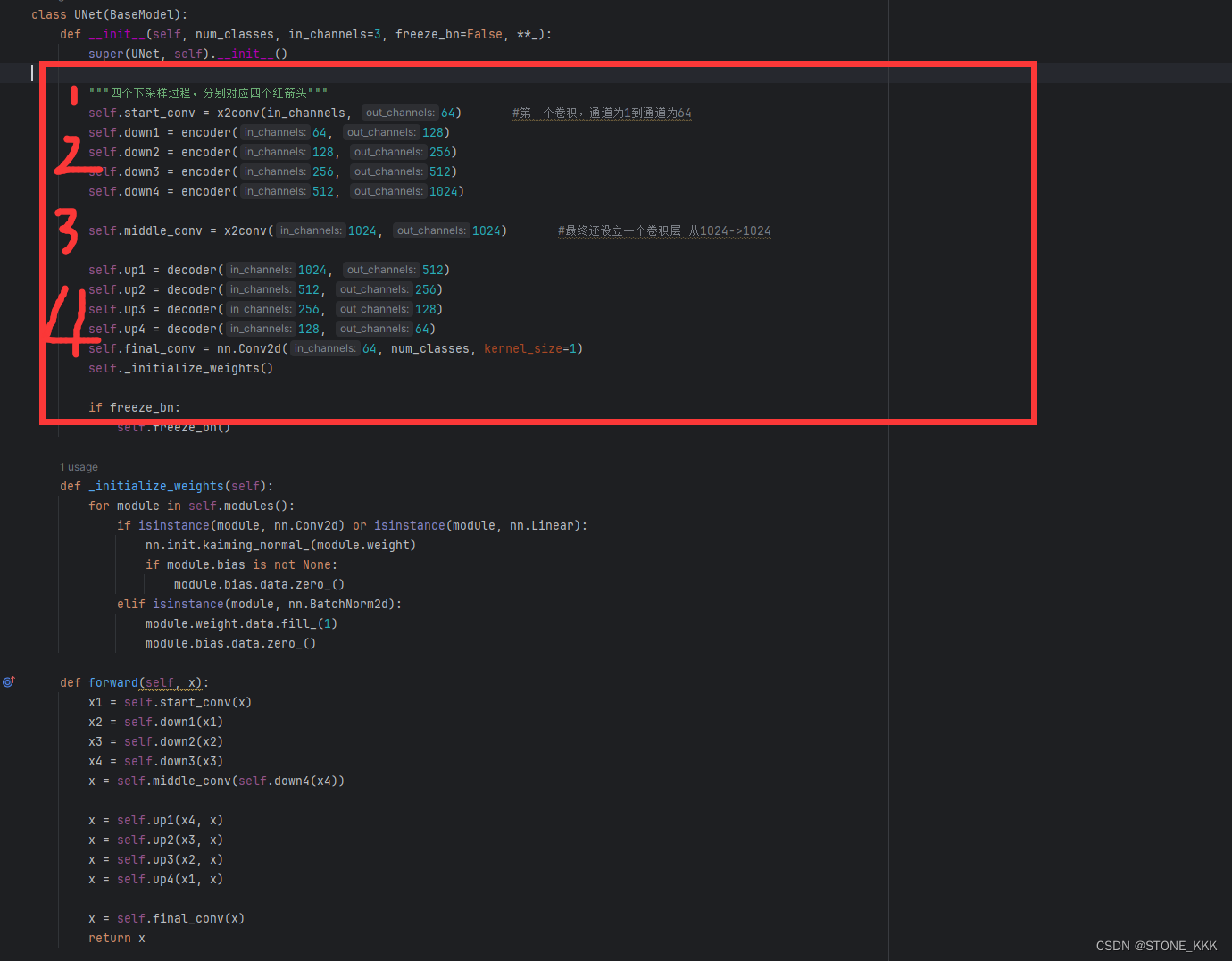
UNet代码实现
实现encoder部分,decoder部分
首先进行一层卷积操作也叫start_conv将单通道映射到64通道
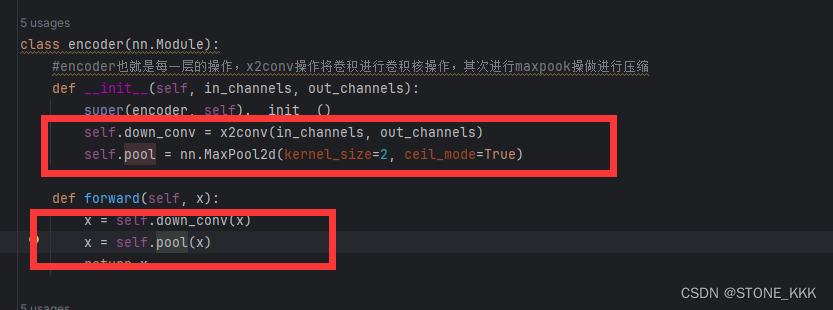
其次要进行四层下采样,每一层下采样包含三个部分
1.最大池化
卷积 归一化 非线性函数
卷积 归一化 非线性函数
之后进行1024 到1024的中间层 实现起来也是进行两次卷积padding==1
最终进行上采样操作,
每一次上采样,都是一个普通的转置卷积层和两个卷积层构成
最终设置的1*1卷积。最终的任务是做分类任务。
引用量四万
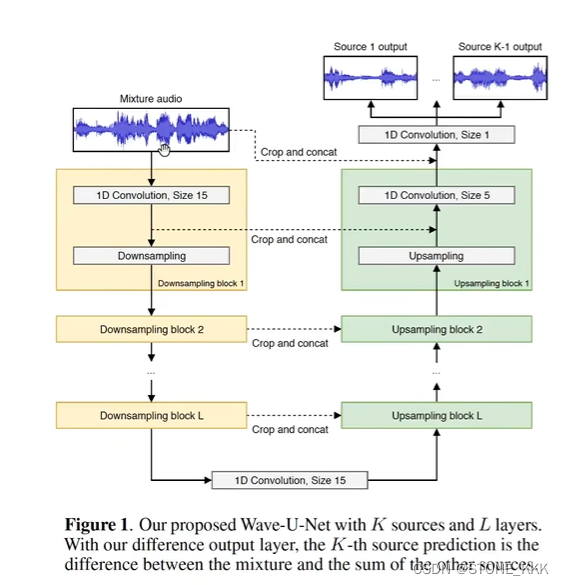
第二个应用,将音频和原声进行分离。
第二篇论文,分离人声伴奏,分离其他也可。甚至可以做抠图操作。

xconv
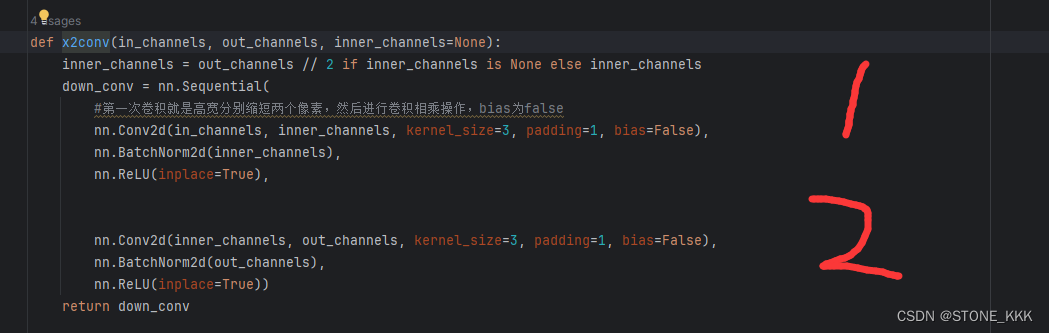
两个卷积操作 + 层归一化+RELU
xconv其实代表每一层的操作了
下采样的过程就是进行xconv操作后进行maxpool操作
上采样的过程相反
上采样的过程上采样的过程需要进行转置卷积操作+xconv+copy操作
forward的时候需要传入copy
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/596085
推荐阅读
相关标签

