
- 1pip安装出现Fatal error in launcher: Unable to create process using '"'的解决办法
- 2前端面经(面试准备+面试题)_店小秘erp 前端面试
- 3算法-买卖股票问题_股票买卖问题算法
- 4Linux 系统应用编程——网络编程(I/O模型)_<
> - 5【图解数据结构】栈全面总结
- 6MyBatis中的复杂映射_对象包含集合字段的对应数据库表
- 7iptables详解_iptables destination
- 8mysql的分区和索引详解_Mysql分区和索引记录
- 9DCMM评估体系
- 10网络工程师面试经验分享_深信服笔试面试问答总结-有一定深度!完整版「建议收藏」_深信服技术服务工程师面试题
flinkcdc 3.0 源码学习之客户端flink-cdc-cli模块
赞
踩
注意 : 本文章是基于flinkcdc 3.0 版本写的
我们在前面的文章已经提到过,flinkcdc3.0版本分为4层,API接口层,Connect链接层,Composer同步任务构建层,Runtime运行时层,这篇文章会对API接口层进行一个探索.探索一下flink-cdc-cli模块,看看是如何将一个yaml配置文件转换成一个任务实体类,并且启动任务的.
概述
flink-cdc-cli 模块目录结构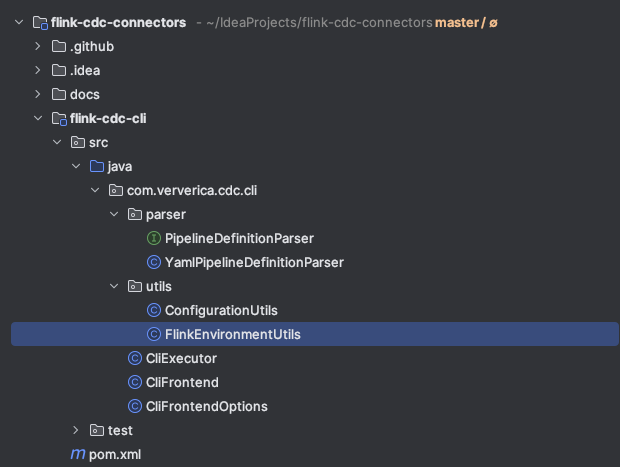
可以看到一共有6个类,1个接口,其中在上一篇文章探索flink-cdc.sh脚本的时候我们知道入口类是CliFrontend,所以接下来会从这个类来一步一步探索这一模块.
入口类 CliFrontend
main方法
public static void main(String[] args) throws Exception { Options cliOptions = CliFrontendOptions.initializeOptions(); CommandLineParser parser = new DefaultParser(); CommandLine commandLine = parser.parse(cliOptions, args); // Help message if (args.length == 0 || commandLine.hasOption(CliFrontendOptions.HELP)) { HelpFormatter formatter = new HelpFormatter(); formatter.setLeftPadding(4); formatter.setWidth(80); formatter.printHelp(" ", cliOptions); return; } // Create executor and execute the pipeline PipelineExecution.ExecutionInfo result = createExecutor(commandLine).run(); // Print execution result printExecutionInfo(result); }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
这里首先是初始化了一下选项,这里用到了Apache Commons CLI 这个工具类,可以很方便的处理命令行参数
大概的步骤有3步
1.定义阶段 : 定义要解析的命令选项,对应的每个选项就是一个Option类,Options类是Option类的一个集合
2.解析阶段 : 通过CommandLineParser的parser方法将main方法的args参数解析,获得一个CommandLine对象
3.查询阶段 : 就是具体使用解析后的结果,可以通过hasOption来判断是否有该选项,getOptionValue来获取选项对应的值
具体可以参考我的另外一系列文章,有详细介绍这个工具的用法
超强命令行解析工具 Apache Commons CLI
超强命令行解析工具 Apache Commons CLI 各个模块阅读
解析了入参后就判断入参args是否是空或者是否包含-h或者–help这个选项,如果是的话就打印一下帮助信息
接着通过CommandLine对象创建执行器并且执行任务
最后在打印一下结果信息
这个类中最核心的一行就是创建执行器并且执行任务
// Create executor and execute the pipeline PipelineExecution.ExecutionInfo result = createExecutor(commandLine).run(); static CliExecutor createExecutor(CommandLine commandLine) throws Exception { // The pipeline definition file would remain unparsed List<String> unparsedArgs = commandLine.getArgList(); if (unparsedArgs.isEmpty()) { throw new IllegalArgumentException( "Missing pipeline definition file path in arguments. "); } // Take the first unparsed argument as the pipeline definition file Path pipelineDefPath = Paths.get(unparsedArgs.get(0)); if (!Files.exists(pipelineDefPath)) { throw new FileNotFoundException( String.format("Cannot find pipeline definition file \"%s\"", pipelineDefPath)); } // Global pipeline configuration Configuration globalPipelineConfig = getGlobalConfig(commandLine); // Load Flink environment Path flinkHome = getFlinkHome(commandLine); Configuration flinkConfig = FlinkEnvironmentUtils.loadFlinkConfiguration(flinkHome); // Additional JARs List<Path> additionalJars = Arrays.stream( Optional.ofNullable( commandLine.getOptionValues(CliFrontendOptions.JAR)) .orElse(new String[0])) .map(Paths::get) .collect(Collectors.toList()); // Build executor return new CliExecutor( pipelineDefPath, flinkConfig, globalPipelineConfig, commandLine.hasOption(CliFrontendOptions.USE_MINI_CLUSTER), additionalJars); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
可以看到最后是构建了一个CliExecutor类,并执行了它的run方法.
选项类 CliFrontendOptions
这个类主要是用来定义命令行选项的,使用的是Apache Commons CLI这个类库,代码比较简单
这里主要细看一下各个选项都有什么作用
package org.apache.flink.cdc.cli; import org.apache.commons.cli.Option; import org.apache.commons.cli.Options; /** Command line argument options for {@link CliFrontend}. */ public class CliFrontendOptions { public static final Option FLINK_HOME = Option.builder() .longOpt("flink-home") .hasArg() .desc("Path of Flink home directory") .build(); public static final Option HELP = Option.builder("h").longOpt("help").desc("Display help message").build(); public static final Option GLOBAL_CONFIG = Option.builder() .longOpt("global-config") .hasArg() .desc("Path of the global configuration file for Flink CDC pipelines") .build(); public static final Option JAR = Option.builder() .longOpt("jar") .hasArgs() .desc("JARs to be submitted together with the pipeline") .build(); public static final Option USE_MINI_CLUSTER = Option.builder() .longOpt("use-mini-cluster") .hasArg(false) .desc("Use Flink MiniCluster to run the pipeline") .build(); public static Options initializeOptions() { return new Options() .addOption(HELP) .addOption(JAR) .addOption(FLINK_HOME) .addOption(GLOBAL_CONFIG) .addOption(USE_MINI_CLUSTER); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
–flink-home
指定flink-home的地址,有了这个参数我们就可以不使用系统环境自带的FLINK_HOME,可以使用指定的flink版本
–global-config
flink cdc pipelines 的全局配置文件 也就是 flink conf目录下的那个 flink-cdc.yaml文件,这里面的参数很少,我看只有配置一个并发度,其他的配置没看到,这块有感兴趣的老铁可以再仔细看看
–jar
和任务一起提交的依赖jar包
–use-mini-cluster
使用mini-cluster模式启动,mini-cluster相当于就是本地local模式启动,会用多个现成模拟JobManager,TaskManager,ResourceManager,Dispatcher等组件,一般用于测试
-h 或者 --help
打印帮助信息
执行类 CliExecutor
package com.ververica.cdc.cli; import com.ververica.cdc.cli.parser.PipelineDefinitionParser; import com.ververica.cdc.cli.parser.YamlPipelineDefinitionParser; import com.ververica.cdc.cli.utils.FlinkEnvironmentUtils; import com.ververica.cdc.common.annotation.VisibleForTesting; import com.ververica.cdc.common.configuration.Configuration; import com.ververica.cdc.composer.PipelineComposer; import com.ververica.cdc.composer.PipelineExecution; import com.ververica.cdc.composer.definition.PipelineDef; import java.nio.file.Path; import java.util.List; /** Executor for doing the composing and submitting logic for {@link CliFrontend}. */ public class CliExecutor { private final Path pipelineDefPath; private final Configuration flinkConfig; private final Configuration globalPipelineConfig; private final boolean useMiniCluster; private final List<Path> additionalJars; private PipelineComposer composer = null; public CliExecutor( Path pipelineDefPath, Configuration flinkConfig, Configuration globalPipelineConfig, boolean useMiniCluster, List<Path> additionalJars) { this.pipelineDefPath = pipelineDefPath; this.flinkConfig = flinkConfig; this.globalPipelineConfig = globalPipelineConfig; this.useMiniCluster = useMiniCluster; this.additionalJars = additionalJars; } public PipelineExecution.ExecutionInfo run() throws Exception { // Parse pipeline definition file PipelineDefinitionParser pipelineDefinitionParser = new YamlPipelineDefinitionParser(); PipelineDef pipelineDef = pipelineDefinitionParser.parse(pipelineDefPath, globalPipelineConfig); // Create composer PipelineComposer composer = getComposer(flinkConfig); // Compose pipeline PipelineExecution execution = composer.compose(pipelineDef); // Execute the pipeline return execution.execute(); } private PipelineComposer getComposer(Configuration flinkConfig) { if (composer == null) { return FlinkEnvironmentUtils.createComposer( useMiniCluster, flinkConfig, additionalJars); } return composer; } @VisibleForTesting void setComposer(PipelineComposer composer) { this.composer = composer; } @VisibleForTesting public Configuration getFlinkConfig() { return flinkConfig; } @VisibleForTesting public Configuration getGlobalPipelineConfig() { return globalPipelineConfig; } @VisibleForTesting public List<Path> getAdditionalJars() { return additionalJars; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
这个类的核心就是run 方法
首先是构建了一个yaml解析器用于解析yaml配置文件
然后调用parser 方法 获得一个PipelineDef类,这相当与将yaml配置文件转换成了一个配置实体Bean,方便之后操作
接下来获取到PipelineComposer对象,然后调用compose 方法传入刚刚的配置实体BeanPiplineDef对象,就获得了一个PiplineExecution对象
最后调用execute方法启动任务(这个方法底层就是调用了flink 的 StreamExecutionEnvironment.executeAsync方法)
配置文件解析类 YamlPipelineDefinitionParser
看这个类之前先看一下官网给的任务构建的demo yaml
################################################################################ # Description: Sync MySQL all tables to Doris ################################################################################ source: type: mysql hostname: localhost port: 3306 username: root password: 12345678 tables: doris_sync.\.* server-id: 5400-5404 server-time-zone: Asia/Shanghai sink: type: doris fenodes: 127.0.0.1:8031 username: root password: "" table.create.properties.light_schema_change: true table.create.properties.replication_num: 1 route: - source-table: doris_sync.a_\.* sink-table: ods.ods_a - source-table: doris_sync.abc sink-table: ods.ods_abc - source-table: doris_sync.table_\.* sink-table: ods.ods_table pipeline: name: Sync MySQL Database to Doris parallelism: 2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
这个类的主要目标就是要将这个yaml文件解析成一个实体类PipelineDef方便之后的操作
代码解释就直接写到注释中了
package com.ververica.cdc.cli.parser; import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.core.type.TypeReference; import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.JsonNode; import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.ObjectMapper; import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.dataformat.yaml.YAMLFactory; import com.ververica.cdc.common.configuration.Configuration; import com.ververica.cdc.composer.definition.PipelineDef; import com.ververica.cdc.composer.definition.RouteDef; import com.ververica.cdc.composer.definition.SinkDef; import com.ververica.cdc.composer.definition.SourceDef; import java.nio.file.Path; import java.util.ArrayList; import java.util.List; import java.util.Map; import java.util.Optional; import static com.ververica.cdc.common.utils.Preconditions.checkNotNull; /** Parser for converting YAML formatted pipeline definition to {@link PipelineDef}. */ public class YamlPipelineDefinitionParser implements PipelineDefinitionParser { // Parent node keys private static final String SOURCE_KEY = "source"; private static final String SINK_KEY = "sink"; private static final String ROUTE_KEY = "route"; private static final String PIPELINE_KEY = "pipeline"; // Source / sink keys private static final String TYPE_KEY = "type"; private static final String NAME_KEY = "name"; // Route keys private static final String ROUTE_SOURCE_TABLE_KEY = "source-table"; private static final String ROUTE_SINK_TABLE_KEY = "sink-table"; private static final String ROUTE_DESCRIPTION_KEY = "description"; // 这个是 解析的核心工具方法,可以获取yaml文件中的值,或者将其中的值转换成java实体类 private final ObjectMapper mapper = new ObjectMapper(new YAMLFactory()); /** Parse the specified pipeline definition file. */ @Override public PipelineDef parse(Path pipelineDefPath, Configuration globalPipelineConfig) throws Exception { // 首先将 pipelineDefPath (就是传入的mysql-to-doris.yaml文件) 通过readTree 转换成 一个JsonNode 对象,方便之后解析 JsonNode root = mapper.readTree(pipelineDefPath.toFile()); // Source is required SourceDef sourceDef = toSourceDef( checkNotNull( root.get(SOURCE_KEY), // 获取 source 这个json对象 "Missing required field \"%s\" in pipeline definition", SOURCE_KEY)); // 这个和source 同理,不解释了 // Sink is required SinkDef sinkDef = toSinkDef( checkNotNull( root.get(SINK_KEY), // 获取 sink json对象 "Missing required field \"%s\" in pipeline definition", SINK_KEY)); // 这里是路由配置,是个数组,而且是个可选项,所以这里优雅的使用了Optional对root.get(ROUTE_KEY) 做了一层包装 // 然后调用ifPresent方法来判断,如果参数存在的时候才会执行的逻辑,就是遍历数组然后加到 routeDefs 中 // Routes are optional List<RouteDef> routeDefs = new ArrayList<>(); Optional.ofNullable(root.get(ROUTE_KEY)) .ifPresent(node -> node.forEach(route -> routeDefs.add(toRouteDef(route)))); // Pipeline configs are optional // pipeline 参数,是可选项,这个如果不指定,配置就是用的flink-cdc中的配置 Configuration userPipelineConfig = toPipelineConfig(root.get(PIPELINE_KEY)); // Merge user config into global config // 合并用户配置和全局配置 // 这里可以看到是先addAll 全局配置,后addAll 用户配置,这的addAll实际上就是HashMap的putAll,新值会把旧值覆盖,所以用户的配置优先级大于全局配置 Configuration pipelineConfig = new Configuration(); pipelineConfig.addAll(globalPipelineConfig); pipelineConfig.addAll(userPipelineConfig); // 返回 任务的实体类 return new PipelineDef(sourceDef, sinkDef, routeDefs, null, pipelineConfig); } private SourceDef toSourceDef(JsonNode sourceNode) { // 将sourceNode 转换成一个 Map类型 Map<String, String> sourceMap = mapper.convertValue(sourceNode, new TypeReference<Map<String, String>>() {}); // "type" field is required String type = checkNotNull( sourceMap.remove(TYPE_KEY), // 将type 字段移除取出 "Missing required field \"%s\" in source configuration", TYPE_KEY); // "name" field is optional String name = sourceMap.remove(NAME_KEY); // 将 name 字段移除取出 // 构建SourceDef对象 return new SourceDef(type, name, Configuration.fromMap(sourceMap)); } private SinkDef toSinkDef(JsonNode sinkNode) { Map<String, String> sinkMap = mapper.convertValue(sinkNode, new TypeReference<Map<String, String>>() {}); // "type" field is required String type = checkNotNull( sinkMap.remove(TYPE_KEY), "Missing required field \"%s\" in sink configuration", TYPE_KEY); // "name" field is optional String name = sinkMap.remove(NAME_KEY); return new SinkDef(type, name, Configuration.fromMap(sinkMap)); } private RouteDef toRouteDef(JsonNode routeNode) { String sourceTable = checkNotNull( routeNode.get(ROUTE_SOURCE_TABLE_KEY), "Missing required field \"%s\" in route configuration", ROUTE_SOURCE_TABLE_KEY) .asText(); // 从JsonNode 获取String类型的值 String sinkTable = checkNotNull( routeNode.get(ROUTE_SINK_TABLE_KEY), "Missing required field \"%s\" in route configuration", ROUTE_SINK_TABLE_KEY) .asText(); String description = Optional.ofNullable(routeNode.get(ROUTE_DESCRIPTION_KEY)) .map(JsonNode::asText) .orElse(null); return new RouteDef(sourceTable, sinkTable, description); } private Configuration toPipelineConfig(JsonNode pipelineConfigNode) { if (pipelineConfigNode == null || pipelineConfigNode.isNull()) { return new Configuration(); } Map<String, String> pipelineConfigMap = mapper.convertValue( pipelineConfigNode, new TypeReference<Map<String, String>>() {}); return Configuration.fromMap(pipelineConfigMap); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
配置信息工具类 ConfigurationUtils
package com.ververica.cdc.cli.utils; import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.core.type.TypeReference; import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.ObjectMapper; import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.dataformat.yaml.YAMLFactory; import com.ververica.cdc.common.configuration.Configuration; import java.io.FileNotFoundException; import java.nio.file.Files; import java.nio.file.Path; import java.util.Map; /** Utilities for handling {@link Configuration}. */ public class ConfigurationUtils { public static Configuration loadMapFormattedConfig(Path configPath) throws Exception { if (!Files.exists(configPath)) { throw new FileNotFoundException( String.format("Cannot find configuration file at \"%s\"", configPath)); } ObjectMapper mapper = new ObjectMapper(new YAMLFactory()); try { Map<String, String> configMap = mapper.readValue( configPath.toFile(), new TypeReference<Map<String, String>>() {}); return Configuration.fromMap(configMap); } catch (Exception e) { throw new IllegalStateException( String.format( "Failed to load config file \"%s\" to key-value pairs", configPath), e); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
这个类就一个方法,主要的作用就是将一个配置文件转换成 Configuration对象
来看一下具体的实现细节吧
首先是 Files.exists 判断了一下文件是否存在,不存在就直接抛异常
ObjectMapper mapper = new ObjectMapper(new YAMLFactory());
- 1
这行代码主要是用了Jackson库中的两个核心类,ObjectMapper和YAMLFactory
ObjectMapper 是 Jackson 库中用于序列化(将对象转换为字节流或其他格式)和反序列化(将字节流或其他格式转换为对象)的核心类。它提供了各种方法来处理 JSON、YAML 等格式的数据。
YAMLFactory 是 Jackson 库中专门用于处理 YAML 格式的工厂类。在这里,我们通过 new YAMLFactory() 创建了一个 YAML 格式的工厂实例,用于处理 YAML 数据。
new ObjectMapper(new YAMLFactory()):这部分代码创建了一个 ObjectMapper 实例,并使用指定的 YAMLFactory 来配置它,这样 ObjectMapper 就能够处理 YAML 格式的数据了。
Map<String, String> configMap =
mapper.readValue(
configPath.toFile(), new TypeReference<Map<String, String>>() {});
- 1
- 2
- 3
这行的意思就是传入yaml配置文件,容纳后将其转换成一个Map类型,kv都是String
因为这个类的主要用途是解析global-conf的,也就是conf目录下的flink-cdc.yaml,这个文件仅只有kv类型的,所以要转换成map
flink-cdc.yaml
# Parallelism of the pipeline
parallelism: 4
# Behavior for handling schema change events from source
schema.change.behavior: EVOLVE
- 1
- 2
- 3
- 4
- 5
这里再简单看一下mapper的readValue方法
Jackson ObjectMapper的readValue方法主要用途就是将配置文件转换成java实体,主要可以三个重载
public <T> T readValue(File src, Class<T> valueType); // 将配置转换成一个实体类
public <T> T readValue(File src, TypeReference<T> valueTypeRef); // 针对一些Map,List,数组类型可以用这个
public <T> T readValue(File src, JavaType valueType); // 这个一般不常用
- 1
- 2
- 3
最后这行就是将一个map转换成Configuration对象
return Configuration.fromMap(configMap);
- 1
这里的Configuration就是将HashMap做了一个封装,方便操作
FLink环境工具类 FlinkEnvironmentUtils
package com.ververica.cdc.cli.utils; import com.ververica.cdc.common.configuration.Configuration; import com.ververica.cdc.composer.flink.FlinkPipelineComposer; import java.nio.file.Path; import java.util.List; /** Utilities for handling Flink configuration and environment. */ public class FlinkEnvironmentUtils { private static final String FLINK_CONF_DIR = "conf"; private static final String FLINK_CONF_FILENAME = "flink-conf.yaml"; public static Configuration loadFlinkConfiguration(Path flinkHome) throws Exception { Path flinkConfPath = flinkHome.resolve(FLINK_CONF_DIR).resolve(FLINK_CONF_FILENAME); return ConfigurationUtils.loadMapFormattedConfig(flinkConfPath); } public static FlinkPipelineComposer createComposer( boolean useMiniCluster, Configuration flinkConfig, List<Path> additionalJars) { if (useMiniCluster) { return FlinkPipelineComposer.ofMiniCluster(); } return FlinkPipelineComposer.ofRemoteCluster( org.apache.flink.configuration.Configuration.fromMap(flinkConfig.toMap()), additionalJars); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
public static Configuration loadFlinkConfiguration(Path flinkHome) throws Exception {
Path flinkConfPath = flinkHome.resolve(FLINK_CONF_DIR).resolve(FLINK_CONF_FILENAME);
return ConfigurationUtils.loadMapFormattedConfig(flinkConfPath);
}
- 1
- 2
- 3
- 4
这个方法的主要目的就是通过找到FLINK_HOME/conf/flink-conf.yaml文件,然后将这个文件转换成一个Configuration对象,转换的方法在上一节中介绍过了
这里还用到了Path 的 resolve 方法,就是用于拼接两个Path然后形成一个新Path的方法
public static FlinkPipelineComposer createComposer(
boolean useMiniCluster, Configuration flinkConfig, List<Path> additionalJars) {
if (useMiniCluster) {
return FlinkPipelineComposer.ofMiniCluster();
}
return FlinkPipelineComposer.ofRemoteCluster(
org.apache.flink.configuration.Configuration.fromMap(flinkConfig.toMap()),
additionalJars);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这个是通过一些参数来初始化Composer,Composer就是将用户的任务翻译成一个Pipeline作业的核心类
这里首先是判断了一下是否使用miniCluster,如果是的话就用minicluster ,这个可以在启动的时候用–use-mini-cluster 来指定,具体在上文中介绍过.
如果不是那么就用remoteCluster,这里就不多介绍了,之后的文章会介绍
总结
上面几个类写的比较多,这里做一个总结,简单的来总结一下这个模块
flink-cdc-cli 模块的主要作用
1.解析任务配置yaml文件,转换成一个PipelineDef任务实体类
2.通过FLINK_HOME获取flink的相关配置信息,然后构建出一个PipelineComposer 对象
3.调用composer的comoose方法,传入任务实体类获取PipelineExecution任务执行对象,然后启动任务
再简单的概述一下 : 解析配置文件生成任务实体类,然后启动任务
通过阅读这模块的源码的收获 :
1.学习使用了Apache Commons CLI 工具,之后如果自己写命令行工具的话也可以用这个
2.学习了 Jackson 解析yaml文件
3.加深了对Optional类判断null值的印象,之后对于null值判断有个一个更优雅的写法
4.对flink-cdc-cli模块有了个全面的认识,但是具体还有些细节需要需要深入到其他模块再去了解
总之阅读大佬们写的代码真是收获很大~
参考
[mini-cluster介绍] : https://www.cnblogs.com/wangwei0721/p/14052016.html
[Jackson ObjectMapper#readValue 使用] : https://www.cnblogs.com/del88/p/13098678.html


