
自然语言处理基础知识入门(四) Transformer模型的positional encoding位置编码详解_transformer中的positional encoding用于表达序列中元素的相对位置关系,使
赞
踩

前言
提示:本章节旨在补充和扩展自然语言处理基础知识入门(四)中关于Transformer模型的位置编码(positional encoding)的讨论,提供更深入的解析以助于对该概念的整体理解。
https://kazemnejad.com/blog/transformer_architecture_positional_encoding/ https://zhuanlan.zhihu.com/p/454482273
https://towardsdatascience.com/master-positional-encoding-part-i-63c05d90a0c3
参考了这两篇博文
Vaswani等人推出了Transformer架构,这是一款创新的、基于纯注意力机制的序列到序列架构。其出色的并行训练能力与性能提升,使其迅速在自然语言处理(NLP)领域以及最新的计算机视觉(CV)研究中获得了广泛的认可和应用。
Transformer因其已被集成至主流的深度学习框架中,成为了许多研究人员进行实验的便利工具。虽然这种易用性增加了其普及率,但也可能带来一个副作用:研究者可能会因此忽略这个模型更深层的精妙之处。
在本篇文章中,我将不会对Transformer的总体架构进行详尽讲解,有兴趣的读者可以阅读当前专栏中的相关文章。我打算专注于讲解Transform架构的一个关键组成部分——位置编码。

本章节主要讨论上图中圈出的红色区域位置编码信息
一、位置编码是什么?为什么我们首先需要它?
在任何语言中,单词的位置和顺序都是极为关键的,它们塑造了语法结构并决定了句子的意义。RNN(循环神经网络)自然地融入了单词顺序的概念;它按顺序处理输入,与人类语言的进程相一致,因而无需特别的位置编码。
然而,Transformer架构摒弃了RNN的递归特性,转而采纳了多头自注意力机制。这种避免递归的策略极大地提升了训练的效率,使模型能够一次性处理整个序列,并在理论上捕捉到更长范围内的依存关系。
由于句子中的每个单词同时流过Transformer的编码器/解码器栈,模型本身没有任何感知每个单词位置/顺序的能力。虽然模型的并行能力增加,但是没法知道单词在句子中的位置,损失了这部分的位置信息因此,因此,依然需要一个机制来让模型感知到词序。
给模型赋予一些顺序感知能力,一个可能的解决方案是为每个单词添加关于其在句子中位置的信息。我们称这种信息为“位置编码”。
1.1 用[0,1]范围标记位置
将时间步在 [0, 1] 范围内为每个单词分配一个数字的想法,初看似乎合理,其中 0 代表句子中的第一个单词,而 1 则代表最后一个时间步。然而,这种方法引入了一个显著的问题,即无法准确知道特定范围内包含了多少个单词。换句话说,不同句子中时间步之间的差值并无统一的含义。
举个例子:
以实例来说明,考虑模型输入的句子“我喜欢喝水”,若采用从0到1的位置编码方式,则编码可能如下:0代表“我”,0.2代表“喜”,0.4代表“欢”,0.6代表“喝”,0.8代表“奶”,1代表“茶”。在这种情况下,0.4实际上指的是句子中的第三个字。
再考虑另一个句子“我喜欢吃东北猪肉炖粉条”,按同一编码方式处理,每个字的位置编码将是:0代表“我”,0.1代表“喜”,0.2代表“欢”,0.3代表“吃”,0.4代表“东”,0.5代表“北”,0.6代表“猪”,0.7代表“肉”,0.8代表“炖”,0.9代表“粉”,1代表“条”。在这个例子中,0.4所代表的依然是一个字的位置信息,但和前一个例子相比,它代表的是第五个字。
因此,此种编码方式存在显著问题:它无法在不同句子中保持时间步差值的一致性的意义。
1.2 用整型值标记位置
另一个想法是线性地为每个时间步分配一个数字。也就是说,第一个单词被赋予“1”,第二个单词被赋予“2”,以此类推。这种方法的问题在于,不仅数值可能会非常大,而且我们的模型可能遇到比训练中的句子更长的句子,这将损害模型的泛化能力。
举个例子:
上文中提到的时间步差值不一致的问题指的是,即使采用相同的编码数值,由于时间步的差值问题,它在不同的句子中可能代表不一致的位置信息。现在考虑一种固定差值为1的方案,也就是说,用1来表示第一个单词,用2来表示第二个单词,以此类推,难道这种方法不好吗?然而,想想看,如果在训练过程中,我们用了200个种不同的数字来作为位置编码,那么当模型遇到需要用到超过200个位置编码的句子时,该怎么办呢?这将极大地限制了模型的泛化能力。
因此,这种编码方式固定了步长但是限制模型的泛化能力。
1.3 用二进制标记位置
考虑到位置信息的作用是施加在输入嵌入(input embedding)上的,因此,与其使用单一的值来表示位置,不如使用一个与输入嵌入维度相同的向量来进行表示。这种情况下,我们自然而然会想到二进制编码作为一种可能的方案。假设模型的维度(d_model)为3,那么我们可以以如下图所示的方式表示位置向量。

使用二进制的编码方式,能够通过固定的向量位,来编码足够大的数字,并且满足了上文中说的步长一致的问题,每一个数值都是有界的
(
0
,
1
)
(0,1)
(0,1)。
BUT!!!
但是这种编码方式也存在问题:这样编码出来的位置向量,处在一个离散的空间中,不同位置间的变化是不连续的
在二维空间中,我们可以将数字 0 、 1 、 2 0、1、2 0、1、2 和 3 3 3 用二进制编码表示。其中,数值 0 0 0 表示为点 [ 0 , 0 ] [0,0] [0,0] , 数值 1 1 1 表示为点 [ 0 , 1 ] [0,1] [0,1] ,数值2表示为点 [ 1 , 0 ] [1,0] [1,0] ,而数值 3 3 3 表示为点 [ 1 , 1 ] [1,1] [1,1] 。为了可视化这些向量,我们将它们投射到坐标平面上,并且按照数值顺序依次用直线段连接起来,形成了一个简洁明了的几何图形。通过这个图形,我们能够直观地看到各个二进制编码向量在二维空间中的位置关系。

期望的图像是下图这种。能够解决位置信息不连续的问题。如果是编码整数位置信息
1
,
2
,
3
1,2,3
1,2,3 可以。但是二进制对浮点数的位置信息编码太过复杂冗余,并不利于这样的浮点数位置信息
0.1
,
0.2
0.1,0.2
0.1,0.2的情况,而且表现的点也是有限的,因此需要一种不仅能表示整数还能表示浮点数。表示的点足够多。

重点来了在将二进制编码映射到空间中时,我们得到的是一系列离散的点,这样只能表示有限的并且是整数的点,那么该如何修改呢?离散反之就是连续,期望得到的是一组连续的点。
1.4 用周期函数(sin)来表示位置
上文中通过不断迭代编码方式中认识到了二进制编码的几大优点。
- 多维度二进制编码可以灵活地满足变化的编码数目需求,这为处理不同长度的数据序列提供了便利。
- 步长的确定性。
- 二进制编码的有界性,即所有编码都位于0和1之间,这使得模型在计算后续编码值的时候可以更加高效地进行直接推理,而无需重新计算前面已排除的不可行编码方式。这种方法有效地简化了模型对数字编码的处理流程,为后续研究与实际应用奠定了基础。
现在思考下,位置向量的每一个元素是有界限的,又连续的函数。最简单的就是正弦函数,可以考虑将向量中的每个元素都是用sin函数来表示,则向量的每个位置该如何实现呢?
首先考虑一下正常的二机制每个位置是如何实现的?
下图直观地展示了二进制编码的过程。图中的第一个元素位对应的是 2 0 , 2 1 , 2 2 , 2 3 2^0, 2^1, 2^2, 2^3 20,21,22,23,这些二进制位的组合能够表达一个十进制数列。通过下图我们可以清晰地看到,最低位(第一个位置)的元素在每增加 2 0 2^0 20(即1)时完成一个循环,而次低位(第二个位置)的元素则在每增加 2 1 2^1 21(即2)时完成一个循环,以此类推。根据这个规律,我们无需逐一计算,便可轻松地得出对应的十进制数值。

在探讨如何通过连续有界的函数来替代(0,1)区间内的数值时,我们预期会用到正弦函数因其周期特性。在设计时,考虑到每个二进制位置表达的周期性是有规律变化的——第一个元素的周期是最短的,随着位置的提升,周期呈现递增的特性。正弦函数( sin \sin sin)允许我们通过调整其波形参数来控制周期,因此可以用来模拟每个二进制元素的周期性变化。通过精确控制正弦函数的频率,我们可以在不同位置应用不同的周期,从而实现具有类似二进制计数特性的连续函数,如下所示:

t t t 则表示是第几个单词, i i i 则用来确定这是第几位元素,即向量的第几个元素。通过 i i i 来控制频率。
看下二维空间中的状态吧,即只用两个元素来表示位置信息。

看起来没什么问题和预期的差不多,都在正负1之间震荡。呈现出一条平滑的曲线表现了他的连续性,当使用3维来表示的时候是什么样子呢?

上图使用三维来表示图位置,当维度增加到3的时候出现了一种情况图中颜色越深表明点重合的就越多,就出现了这样的一个问题:
当使用表达式 sin ( t i ) \sin(\frac{t}{i}) sin(it) 时,随着 i i i 的增大,函数变化的速度会变慢。这意味着对于更大的 i i i值,相同 t t t的增量将导致函数值的变化更小。在三维空间中,可能导致相邻点之间的距离减小,使得这些点在视觉上更加接近,特别是当 i i i 非常大时。
再具体点就是 i i i变得很大, t t t 变化对整体数值的影响就不敏感了。
这种情况在可视化数据时尤其需要注意,因为它可能导致重要数据特征不明显。例如,如果 z z z 轴使用了 sin ( t 4 ) \sin(\frac{t}{4}) sin(4t) ,在较大的 t t t范围内,数据点变化较小。如果 i i i 值继续增加,例如 sin ( t 8 ) \sin(\frac{t}{8}) sin(8t) 或 sin ( t 16 ) \sin(\frac{t}{16}) sin(16t) 等,这种效应将更为明显,导致点重合。
因此要对分母进行修改。

为了避免这种情况,对分母部分做出修改, d d d是整个位置的向量的维度。上图的例子那就是3,可以按照需求设置,Transformer中则是和输入的input embedding一致便于做加法。
1.5 用sin和cos交替来表示位置
现在困难一步步的解决,让我们来看最后一个问题,让两个位置信息之间能够通过计算得到,则也就表明两个位置间是可以被度量,被转换的。那么就能够知道他们之间的相对位置关系。这样表示的位置不再是单纯的编码,还能够通过向量比较衡量。
那么如何实现这个问题呢?

这个
P
E
t
PE_t
PEt是一个位置向量,那么
T
Δ
t
T_{\Delta t}
TΔt 就是一个矩阵啊,用于线性变换。希望通过线性变换得到这样的一个
Δ
t
{\Delta t}
Δt 是一个增量,就会得到
P
E
t
+
Δ
t
PE_{t + \Delta t}
PEt+Δt 这样的位置信息。进一步的细化这样的公式。
哈?这不就简单了吗?
sin ( a + b ) = sin ( a ) cos ( b ) + cos ( a ) sin ( b ) \sin(a+b) = \sin(a)\cos(b) + \cos(a)\sin(b) sin(a+b)=sin(a)cos(b)+cos(a)sin(b)
cos ( a + b ) = cos ( a ) cos ( b ) − sin ( a ) sin ( b ) \cos(a+b) = \cos(a)\cos(b) - \sin(a)\sin(b) cos(a+b)=cos(a)cos(b)−sin(a)sin(b)
现在将原本的都是由sin构成的向量,做一个替换,变成两两一组,分别用sin和cos的函数对来表示它们,就能实现相对位置的能
力了。

二、Transformer位置编码
大功告成,现在让我们看看Transformer的位置编码吧
设 t t t 为输入句子中的期望位置,向量 P E t ∈ R d PE_t\in \mathbb{R}^d PEt∈Rd 为其对应的编码, d d d 为编码维度(其中 d = 512 d =512 d=512)。则 f : N → R d f: \mathbb{N} \rightarrow \mathbb{R}^d f:N→Rd 将是产生输出向量 P E t PE_t PEt 的函数,并且定义如下:
P
E
t
(
i
)
=
f
(
t
)
(
i
)
:
=
{
sin
(
ω
k
.
t
)
,
if
i
=
2
k
cos
(
ω
k
.
t
)
,
if
i
=
2
k
+
1
PE_t{(i)}= f(t)^{(i)} :=
其中:
ω k = 1 1000 0 2 k / d \omega_k = \frac{1}{10000^{2k/d}} ωk=100002k/d1
根据函数定义可以推导出,频率沿着向量维度递减。因此,它从 2 π 2\pi 2π 到 10000 ⋅ 2 π 10000 \cdot 2\pi 10000⋅2π 形成了一个在波长上的几何级数。
也可以将位置嵌入
P
E
t
{PE_t}
PEt 想象成一个向量,该向量对每个频率包含了正弦余弦对(注意,
d
d
d 可以被2整除):
P
E
t
=
[
sin
(
ω
1
⋅
t
)
cos
(
ω
1
⋅
t
)
sin
(
ω
2
⋅
t
)
cos
(
ω
2
⋅
t
)
⋮
sin
(
ω
d
2
⋅
t
)
cos
(
ω
d
2
⋅
t
)
]
d
×
1
{PE_t} =
2.1Transformer位置编码可视化
下图是一串序列长度为50,位置编码维度为128的位置编码可视化结果:
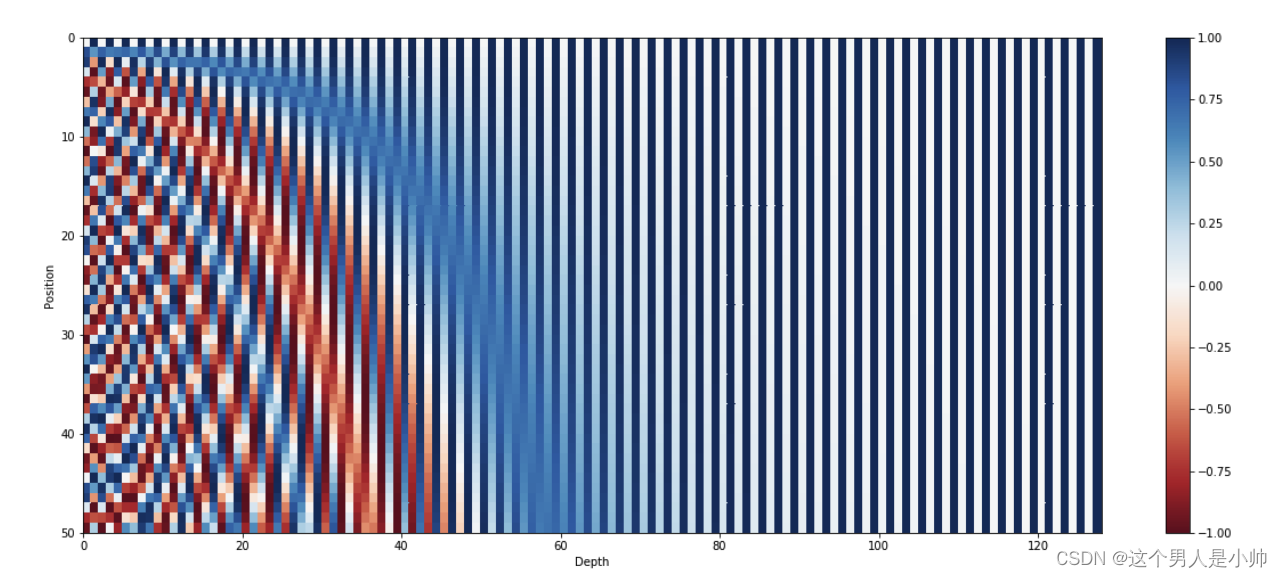
可以看到图形的右半部分主要呈现为蓝色。这是因为随着位置的增加,频率逐渐降低,波动变得更加稳定,从而使得不同时间点的变化对结果的影响变得不那么显著。然而,在图的左侧,颜色的变换就显得相对频繁,反映了在较高频率下,相应位置的波动更加剧烈。
总结
本章只是对Transformer位置编码部分内容的补充,值得注意的是原始论文中指出通过学习的方式得到的位置编码和本文中的效果一致,故此使用这种不占用计算单元的方式提高模型性能。在编写这部分内容的时候参考了上述两篇大佬博文的内容,如果对这部分内容感兴趣的话可以去阅读原文哦。

