
- 1巨杉TechDay回顾 | 微服务下的分布式数据库架构演进与实践_分布式数据库和微服务架构
- 2WinCC数据报表控件_wincc报表控件免费版下载
- 3
false - 4Lambda表达式使用及详解
- 5git新建用户和仓库以及设置用户权限_git用户权限设置
- 6Python办公自动化之Excel做表自动化:全网最全,看这一篇就够了!python操作Excel教程_excel办公自动化python
- 7xcode 开发者证书创建流程_xcode 证书
- 8Android Gradle配置详解一:gradle插件和gradle区别_gradle和gradle插件
- 9洛谷P1135 奇怪的电梯 C++ 思路&代码_奇怪的电梯c++
- 10【LeetCode刷题】新手一看就会的——动态规划详解—入门_运筹学动态规划解题思路
Transformer、BERT等模型学习笔记_laynorm
赞
踩
记录一下刷B站教学视频的一些笔记,目前主刷:
1 Transformer从零详细解读(可能是你见过最通俗易懂的讲解)
地址:
Transformer从零详细解读(可能是你见过最通俗易懂的讲解)
关联知乎文章:
万字长文帮你彻底搞定Transformer-不要错过!!
答案解析(2)-3分钟彻底掌握Transformer的Encoder—满满干货!!
答案解析(1)—史上最全Transformer面试题:灵魂20问帮你彻底搞定Transformer
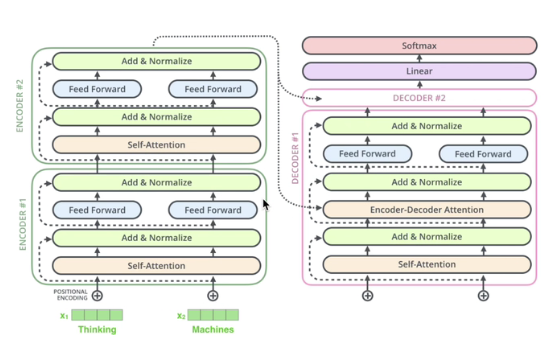
1.1 整体结构
transformer整体结构简图: 6 encoder * 6decoder
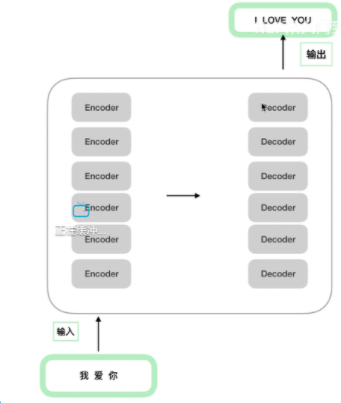
6个encoder结构完全相同,但是训练的时候是6个同时训练,独立训练,这里跟alBERT有差别,albert是共享transformer某些层的参数,达到减少参数量的目的。
以下是论文的transformer图,左边是一个encoder的图样,一共会 有Nx个(乘以N个),
右边是一个decoder,一共会有Nx个:
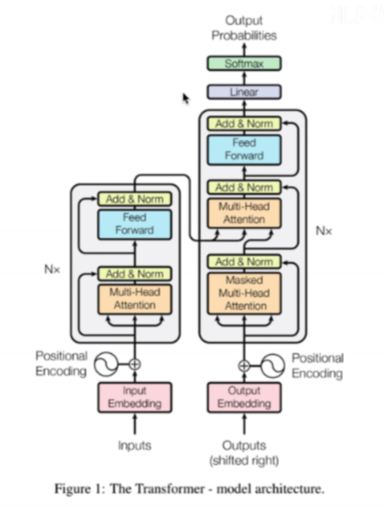
从图中,可以看到,decoder比encoder要多一个模块,就是masked muti-head attention的模块
1.2 encoder部分
单独拿一个出来,来看,一共分为三个部分:
- 输入部分
- 注意力机制
- 前馈神经网络
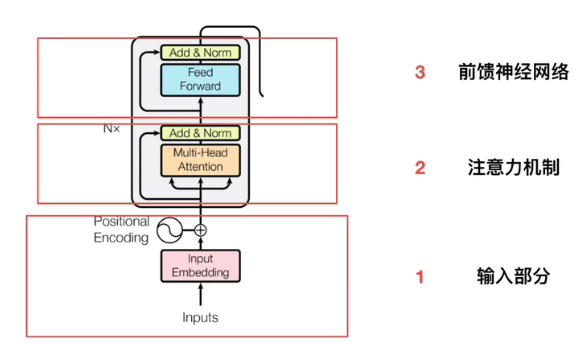
1.2.1 输入部分
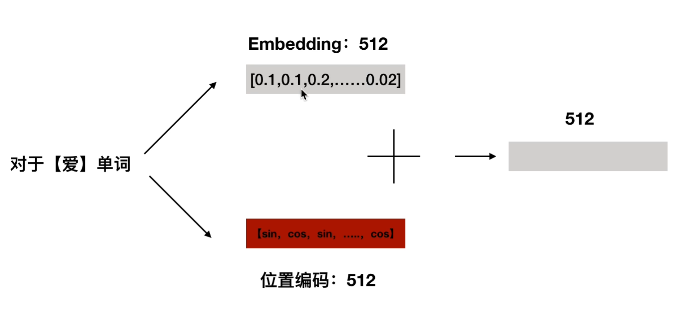
input = embedding + postion bedding
为啥需要位置信息?不适用RNN?
RNN可以获得一套参数,transformer是并行的,丢失了位置信息,就通过编码,加到embedding,让embedding拥有位置信息
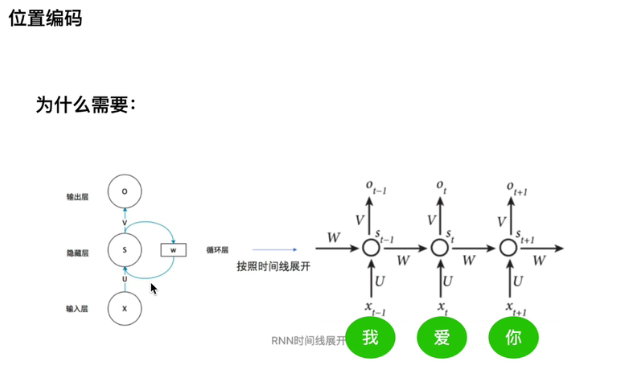
RNN里面,所有的step都 共享 一套参数,包括,U,W,V
那RNN的梯度消失是什么?
RNN的梯度是一个梯度消失和,并不是梯度变为0,
RNN是一套参数的梯度,那么这套参数会更加适应 S t + 1 St+1 St+1 而对 S t − 1 St-1 St−1不友好,忘记重视前面的隐藏层
位置编码的公式:
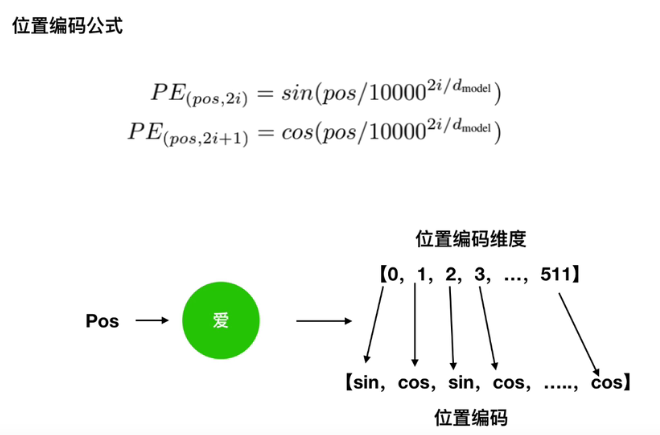
为什么相对位置编码是有用的,可以代表位置?

那么总结,
最后输入项 = 位置编码 + embedding,对位相加:
1.2.2 多头注意力机制
1.2.2.1 注意力机制原理
注意力机制计算的时候,一定有Q,K,V三个矩阵:
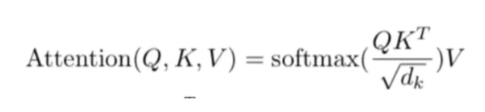
根据公式来看例子:
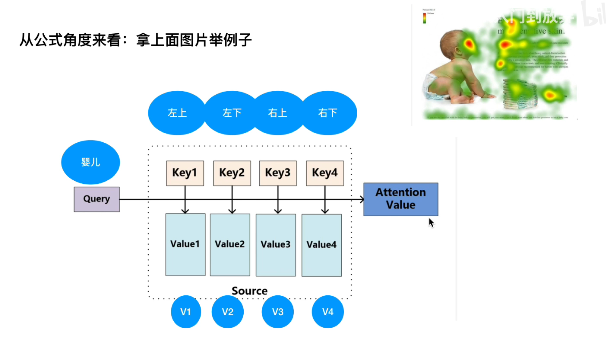
Q,K都分别代表两个向量,点乘代表两个向量的相似程度,
这里婴儿Q,点乘四个K值,就代表婴儿与四个区域,哪个更相似,所以
softmax(Q,K) 代表相似度
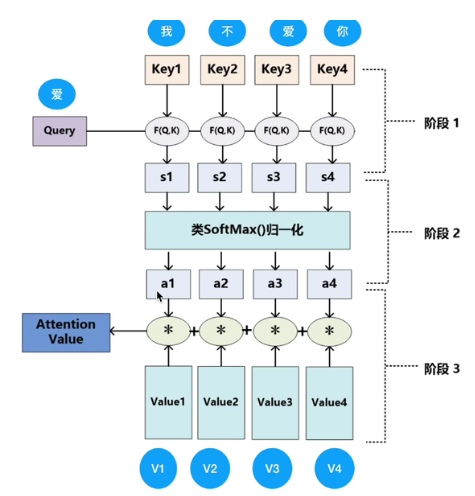
这个图演示了一个attention计算出来的经过
1.2.2.2 QKV的获取方式
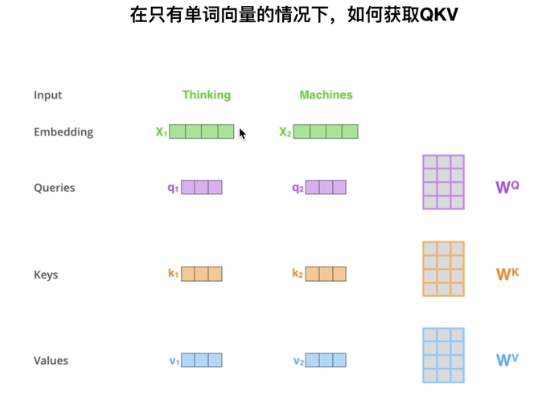
一个input,会跟QKV同时相乘,那么:
- Q = X*Wq
- K = X*Wk
- V = X*Wv
此时Wq、 Wk、 Wv为Q,K,V的参数
得到了q1/q2,就可以跟上述注意力机制计算一样:softmax(q,k) * v
可以来看一下具体相乘的过程:
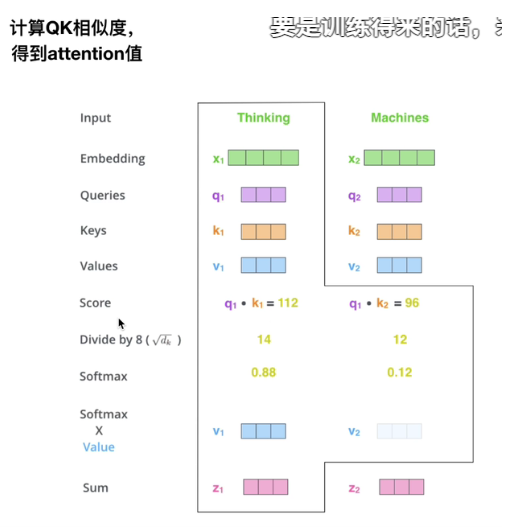
矩阵并行QKV,比较快
多头 => 多套参数Wq、 Wk、 Wv
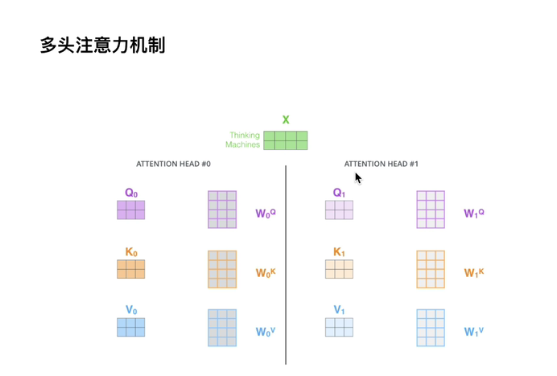
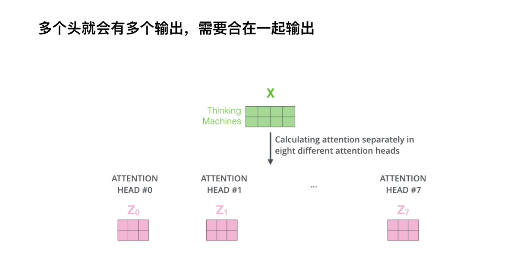
如果是8个头,那就是接在一起共同输出,Z0就是注意力层的第一个头,一直有8个
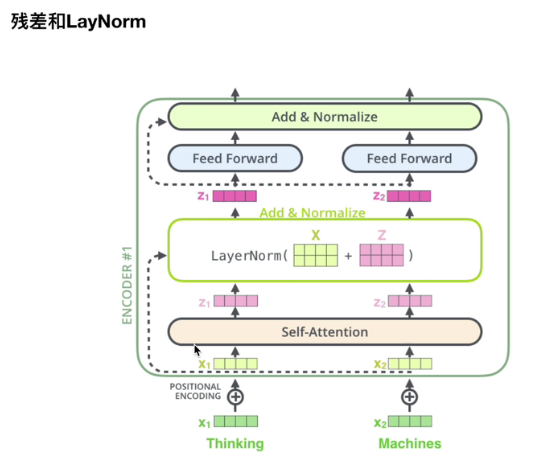
1.2.3 残差
laynorm计算过程:
上面经过多头注意力层,就有Z1,Z2多头注意力层进行输出
这里的laynorm,是把多头注意力层输出的Z + 原始的X,
add之后进行normalize
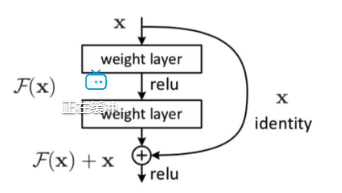
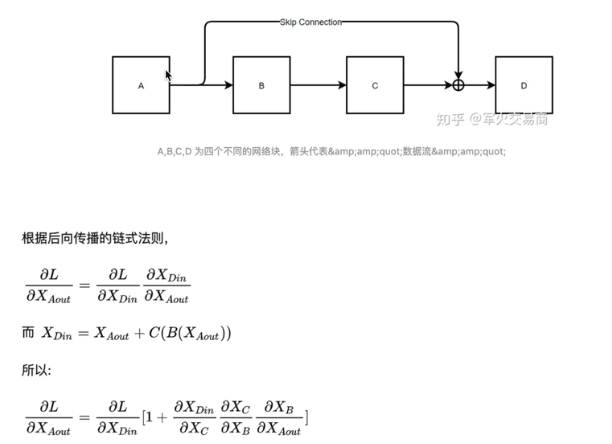
解释一下残差
X经过两个weight layer,最后会得到:f(x)+ x
抽象成以下的公式:
残差这里的1,就可以保证梯度不消失,因为消失较多的情况是,连乘会导致梯度消失,所以残差网络可以让网络变得很长,因为可以保证梯度不会消失;
反观RNN,顶多是bi-lstm,一旦过长容易梯度消失,所以RNN网络做深非常难
1.2.3 layer norm 与BN的差异
另外一个知识点:layer norm(LN) 与 BN的差异
BN效果差,NLP中基本不用,因为RNN不用,一般用LN;
CNN可能会用BN
BN - 进行feature scaling标准化,
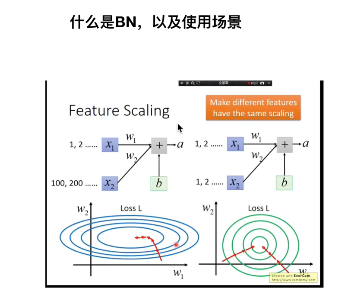
BN进行标准化是一个特征所有进行标准化,如下图的所有人的体重这一行做标准化
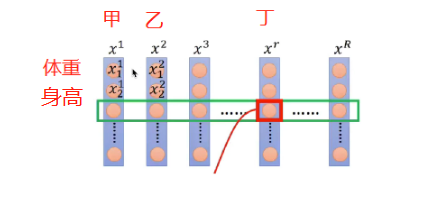
指的是所有词,样本,一行代表一种特征,第一行体重,第二行身高
BN指的是,选的一个Batch中所有的人,体重这一行做标准化,
BN最大的问题 : 但是有一个问题就是,如果Batch非常小,那么这时候方差/标准差只是局部的,并不能总体,所以波动非常大
意思就是,本来有1w个样本,如果做标准化,就是体重这一列,1w个人标准化,但是现在的情况是,一个batch可能只有100个人,
那么1w和100个人的标准差,均值都不一样了,所以BN代表用100个人的模式,表达这1w个人
所以,LN的意思就是,标准化,不是按行,而是按每个样本,按照一个人,体重,身高,等等特征


在RNN中,比较难,因为有些词padding,后面的都是0,方差不好算
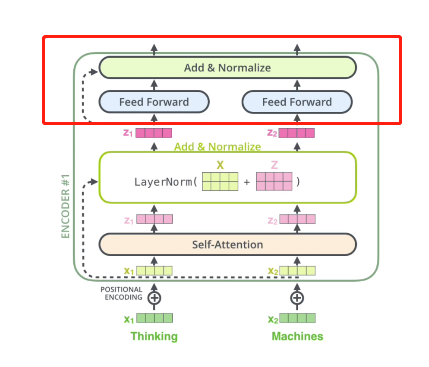
1.2.4 前馈神经网络
就是红框的部分,Z1、Z2分别通过一个feed forward,代表两层的全连接
再过一个残差和Normalize
1.3 Decoder
主要有两个大模块不同
- 改成masked
- 多了一个交互层
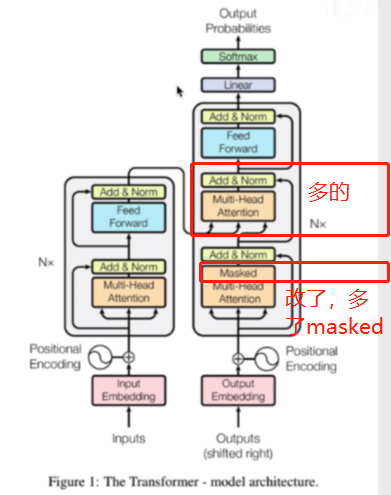
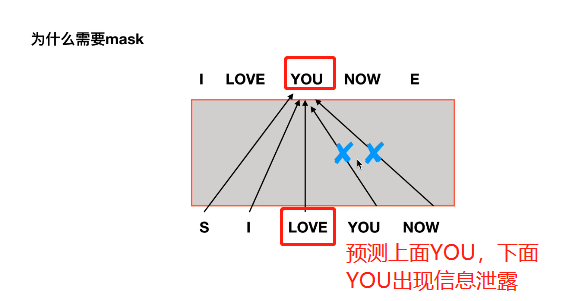
1.3.1 masked
这里有个细节点就是masked,

为什么需要mask,如果要预测YOU这个单词,如果不mask,就会出现信息泄露
decoder是预测型的,需要mask后面的单词
1.3.2 新增的多头注意力机制层
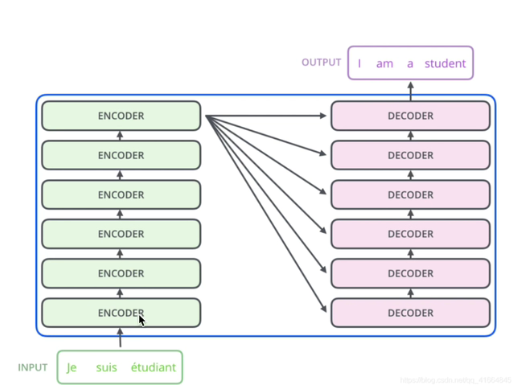
这里encoder的输出(KV矩阵,如下图),会同时给到所有的decoder(生成Q矩阵)
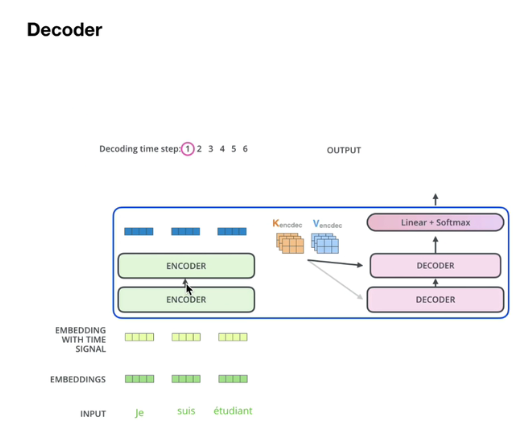
所以这里新增多头注意力机制,KV来自encoder的输出层,而且给到每一个decoder
下面有一个encoder(K、V) -> decoder(Q,下图的encoder-decoder attention)的详细图解:
2 BERT从零详细解读,看不懂来打我
2.1 BERT整体架构
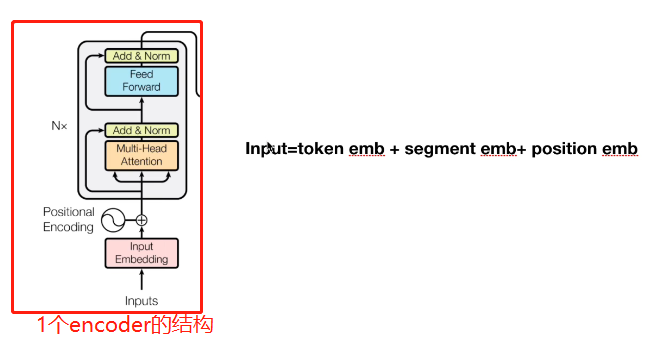
BERT是tansformer中剥离多个encoder,然后堆叠在一起
而不是12层transformer(6*encoder + 6 * decoder)

展开其中一个encoder如下,input跟transformer不太一样,
- transformer input = positional encoding + embedding
- bert input = token emb + segment emb + position emb
解析一下input:
- segment emb 是一句话为0,一句话全为1
- postion emb是初始化后,让模型自己训练出位置信息
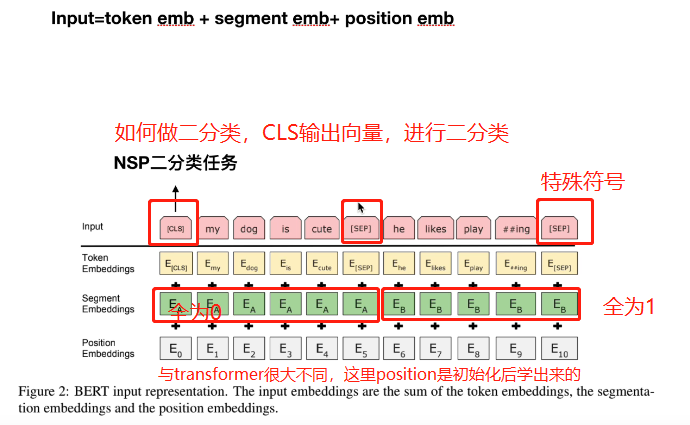
提问:那么[cls]是否可以作为句向量来表征这个句子?
[cls]表征的向量不是句向量,输出是为了二分类,如果拿[cls]表征的向量来做相似性聚类,效果非常差,不如Word embedding
2.2 MLM + NSP如何做预训练
2.2.1 MLM
AR自回归模型 与 AE自编码模型 的差异


AR模型就是用到单侧信息,是从左到右顺序的
AE模型打乱文本,让文本进行重建,不仅是单侧信息,周边信息都会使用到
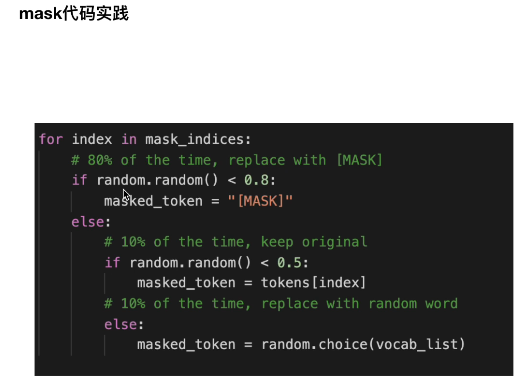
mask的缺点是什么
mask字之间不是独立的,可能是有关联的,
而mask模型中是认为独立的
那么BERT里面mask的具体操作是

2.2.2 NSP

- 主题预测 - 两个段落是否来自同一个主题,因为在抽样的时候,就是不同的文章,当然大概率就不是一个主题了
- 连贯性预测 - 两个段落是否有顺序
但是从这两个任务来看,主题任务是非常简单的,导致效果不是特别好
所以后面的albert不要主题预测,只使用连贯性预测(预测句子顺序,正负样本来自同一个文章,正样本就是两个有序的句子,负样本就是把有序句子进行颠倒)
2.3 微调BERT,提升BERT在下游任务的效果
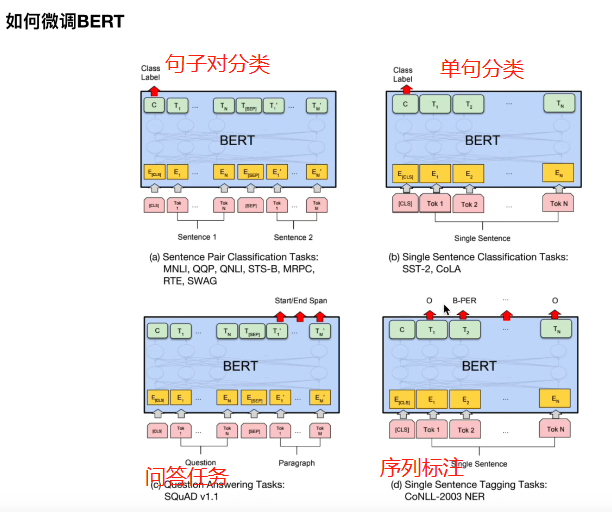
文本分类就是[cls]输出句子
序列标注就是对每一个输出token接入一个softmax
句子对分类,就是两个句子接起来,然后[cls]分类输出
一般工业界的做法是:
- 直接获取谷歌中文BERT
- 自己训练
关于预训练模型,有几种等级的预训练阶段:

比如沿着2展开,大量微博文本继续训练BERT时候,讲师推荐两种技巧:

- 动态mask,之前训练,比如“我爱吃饭”,一般都是固定mask某一个,比如,“爱”;现在动态,每一次mask不一样的好一些
- n-gram mask,是使用n-gram,使用实体词的mask

其他的一些训练技巧
2.4 脱敏数据使用BERT预训练模型
作者的建议是,如果语料非常大,那么:
- 第一种,直接从新训练
- 第二种,先把脱敏内容随机映射到文本中,比如脱敏是"abbbdda",那么可以直接随机映射为"我你你你她她我",将中文已经训练的作为初始化


