
- 15年时间,从外包测试到自研,最后到阿里,这5年的经历只有自己能知道...._测试培训完去自研
- 2SpringBoot日志关系--及排除模块中的日志框架_jasypt-spring-boot-starter 排除日志模块
- 3使用Python实现深度学习模型:模型监控与性能优化
- 44年外包上岸,我只能说这类公司能不去就不去
- 5GrassRouter多链路聚合路由应用场景拓扑详解_多链路聚合路由器
- 6机器学习算法: 岭回归算法_岭回归c++算法实例
- 7H5--公众号页面如何唤起小程序_jweixin-1.6.0.js
- 8C++入门基础篇(下)
- 92024年前端最新最新的Vue面试题大全含源码级回答,吊打面试官系列,前端初级面试题_2024前端vue面试题
- 10Linux —— 进程间通信
CVPR2023 | 提升图像去噪网络的泛化性,港科大&上海AILab提出 MaskedDenoising,已开源!_cvpr2023降噪
赞
踩
作者 | 顾津锦
首发 | AIWalker
链接 | https://mp.weixin.qq.com/s/o4D4mNM3jL6sYuhUC6VgoQ
当前深度去噪网络存在泛化能力差的情况,例如,当训练集噪声类型和测试集噪声类型不一致时,模型的性能会大打折扣。作者认为其原因在于网络倾向于过度拟合训练噪声,而没有学习图像自身的内在结构。为了解决这个问题,作者提出了一种遮盖图像训练的策略(masked image training)。其核心思想是在训练过程中对输入图像进行大比例的随机遮盖,迫使网络学习重构被遮盖的内容,增强对图像本身分布的建模能力,从而对未见过的噪声类型也有好的去噪效果。

- 论文链接:https://arxiv.org/abs/2303.13132
- 代码链接:https://github.com/haoyuc/MaskedDenoising
图像去噪中的泛化性问题
但是,现有的深度学习去噪方法存在一个关键问题——泛化能力差。大多数方法都是在高斯噪声上训练和测试的。当遇到训练过程中未见过的噪声时,这些方法的效果会急剧下降。因为深度网络很容易过拟合训练数据,普通的学习方式使得网络仅仅学会如何去除高斯噪声,未学会图像的内在结构。

文章 Figure 1 主要说明了当前深度学习去噪模型的泛化问题:
当我们使用高斯噪声(σ=15)训练SwinIR模型,在同样的高斯噪声(σ=15)测试时,SwinIR可以很好去除噪声,效果优秀。
但当测试噪声为复杂的mixture noise时,SwinIR的去噪效果大幅下降,基本失效。
而作者提出的遮挡训练方法即使也是在高斯噪声(σ=15)上训练,但对mixture noise去噪效果仍然可以,泛化能力明显更强。
传统的训练方式是在过拟合训练集噪声

作者做了一个实验来直观地反映当前深度学习去噪模型的工作原理。他们使用免疫组化学图像训练了一个SwinIR模型,这类图像与自然图像非常不同。但加入的是相同的高斯噪声。模型通过拟合图像+噪声的数据集学会了去噪。然后他们测试这个模型在普通自然图像上的去噪效果,结果仍旧有高效的去噪能力。这说明模型是靠识别噪声本身来起去噪作用的,而不是真正理解图像内容。只要是训练过程中见过的噪声类型,不管图像是什么,模型都可以去除。这样就解释了为什么这类模型泛化能力较差,测试噪声一变模型就失效了。
而作者提出的遮挡训练方法可以让模型学会理解和重构图像内容,不仅依赖噪声特征,从而获得更好的泛化能力。这个实验简单直观地反映了现有模型的工作机制和局限性,也支持了遮挡训练可能带来的优势。
作者的分析认为,现有方法之所以泛化能力差,是因为模型仅仅过拟合了训练噪声,而没有真正学习图像的内在结构。所以需要通过改进训练策略,让模型学习重构图像内容,而不是仅仅识别并移除噪声模式。
因此,这篇论文要解决的核心问题是:
如何提高深度学习去噪模型的泛化能力,使其不仅能去除训练使用的噪声类型,还能够很好地处理其他未知的噪声,适应更广泛的场景。
Masked Training
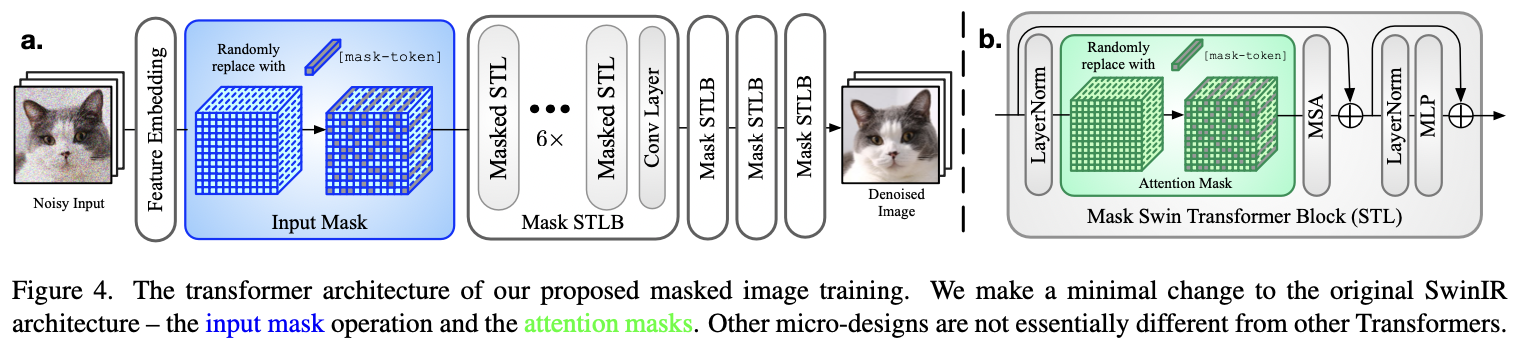
整体网络架构基于了Swin Transformer。
作者提出了一种 masked training 的方法来提高模型的泛化能力。
主要包含两个方面:
- Input Mask
在特征提取之后, 会对输入图像进行随机大比例遮盖(input mask),比如遮盖75%~85%的像素。这将构造一个非常具有挑战性的图像修复问题,迫使模型学习重构被遮盖的图像内容,而不能简单依靠检测并移除噪声模式。
- Attention Mask
在self-attention层也进行类似的随机遮盖。这是为了减轻训练和测试的不一致性。由于 input mask 只在训练使用, 测试时的输入是完整的图像。因此我们使用attention mask 可以平衡这一差异。
训练过程中,模型需要在大量信息被移除的情况下,依靠图像的内在结构去重构内容。这样可以减少模型对训练噪声的过拟合,增强对图像本身分布的建模能力。

Figure 3 展示了我们提议的 mask-and-complete 的训练策略。每一组图片左侧是 mask 后的效果,右侧是重建后的效果。可以看到,即使有大量的像素被遮罩,模型仍然可以在一定程度上重建输入。
实验结果
视觉效果

Figure 8 展示了不同去噪算法在各种未出现在训练中的噪声下的视觉效果。
测试噪声类型包括Spatially correlated Gaussian、Speckle noise和Salt-and-pepper noise,都不属于训练使用的高斯噪声。
对比算法包括DnCNN、RIDNet、RNAN、SwinIR、Restormer等当前主流算法。
结果显示这些对比算法完全失效,无法有效去除测试噪声,图像效果很差。
而作者提出的遮挡训练方法在所有的测试噪声下都获得了很好的去噪视觉效果。
这直观地反映了作者方法相比其他算法在泛化性上的明显提高。
尤其是在其他方法完全失败的情况下,遮挡训练仍能有效去噪,突出了方法的优势。
这验证了遮挡训练可以减少对训练噪声的依赖,提高模型对复杂未知噪声的适应性。
性能指标
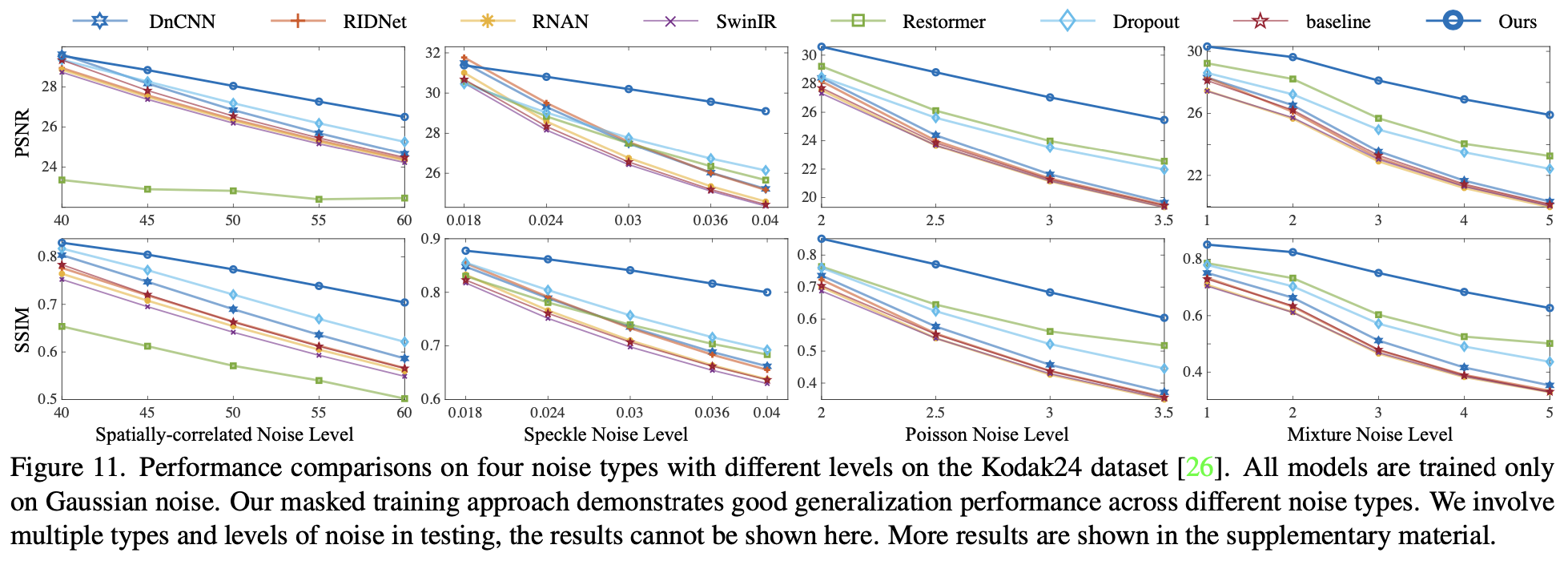
图 11 是性能数值对比,作者测试了 4 种不同的噪声类型,并且每一种噪声都测试了不同的噪声 level 。深蓝色的是使用 masked training 的方法。
可以看到,使用 masked training 的方法在训练集外的噪声类别上的性能要远优于其他方法,并且随着噪声 level 的增加,性能优势也更加明显。
说明这样的方法在训练集和测试机噪声区别越大的情况下,会有更大的优势。
Mask 比例的权衡
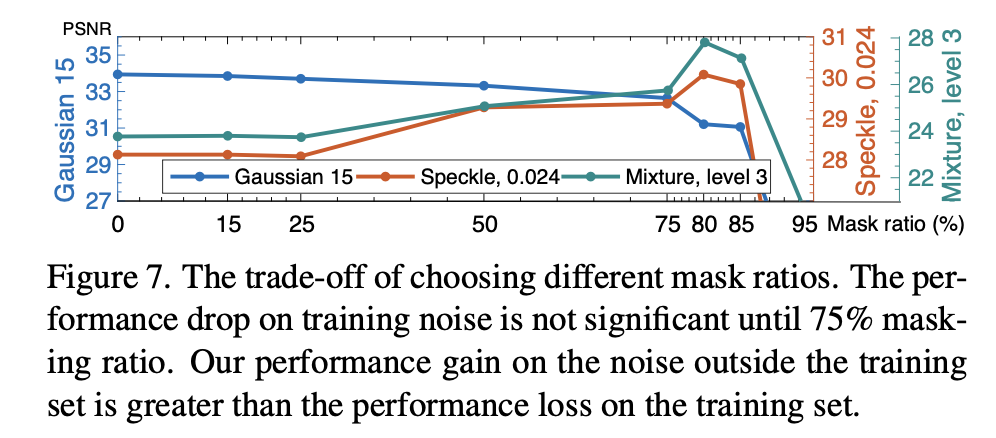
当然,由于使用了 mask,这无疑会对训练集噪声上的性能造成影响。因此,在训练集上的性能和在未见过的测试机噪声上的性能是一种权衡。
图 7 展示了在不同的 input mask 比例时,模型在训练集噪声(高斯 15)和训练集外的噪声(Speckle, Mixture noise)上的性能。
可以看到,在掩码比率为75%之前,训练噪声的性能下降并不明显。而在 mask 比例为 50%左右时,就已经体现出较高的性能。
而在训练集之外的噪声上的性能提升大于在训练集上的性能损失。
较小的比率不足以使网络学习到图像的分布,因为更多的噪声模式被保留下来。较大的比率提高了模型的泛化能力,因为模型更加关注重构。但与此同时,一些图像细节可能会丢失。
分析
训练曲线
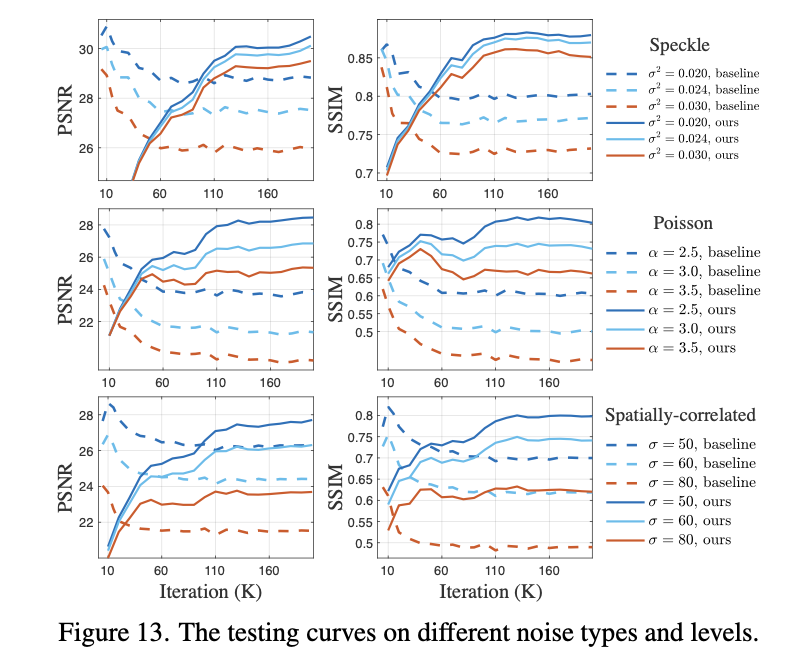
图13展示了遮挡训练模型和基准模型的训练曲线,用来分析训练过程。
每一行对应了一种噪声类别;第一列和第二列分别是 PSNR 和 SSIM 指标。
而每一个子图中 x 轴对应了训练的 iteration(K)。
- baseline 模型(没有使用 Masked training)的性能在训练一开始就达到了峰值,然后随着训练越久会逐渐下降,说明在峰值之后,模型就已经在过拟合训练集噪声,从而导致在其他噪声类别上的泛化能力越来越差。
- Masked training 模型在三种噪声上的性能曲线都是缓慢上升的,且最终效果优于基准模型,说明泛化能力更强,没有过拟合。
不同噪声的特征分布
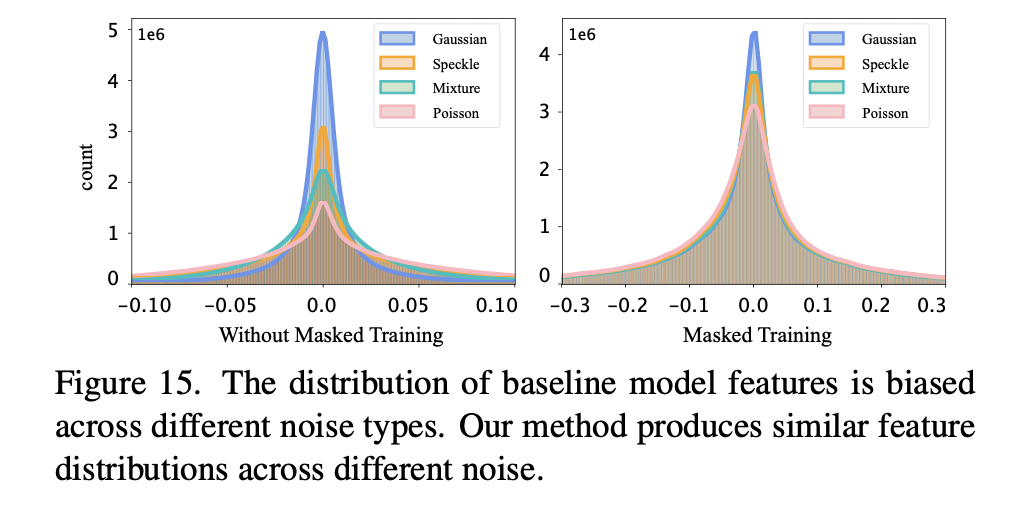
我们在不同噪声类型下可视化了深度特征的分布,如图15所示。我们可以看到:
- baseline 模型中,不同噪声类型下的特征分布明显偏离彼此。
- 而对于经过 masked training 的模型,不同噪声类型下的深度特征分布彼此接近。
这从侧面印证了 masked training 的模型的泛化能力以及有效的原因。
局限性和未来方向
正如文章中所提到的,能够让这个方法发挥出优势需要找到合适的场景,因此训练集和测试集的选择比较重要。
具体来说,
- 训练集和测试集的区别越大,就越能体现优势
- 训练集的退化分布越有限,也越能体现优势
因此,如何将这样的训练方法能够在更多更广泛的场景下同样发挥出优势,是一个非常有意义的未来研究方向。

