
Hugging face 模型微调学习:T5-base的微调
赞
踩
最近想做一点文本生成的小实验,无意发现了NLPer应该了解到了一个网站:Hugging face。
Hugging face 在 github上开源了一个Transformers库,允许用户上传和下载的预训练的模型,并进行原有模型的基础上进行微调。如此,使得每个 NLPer 必须依靠大量美金才能训练出来的预训练模型,可以轻易的在huggingface网站对自己的数据集上进行微调,并达到很好的效果。
这篇文章介绍了自己在探索Hugging face 模型微调的操作过程,希望能帮助到大家。
1.登陆网址,查找需要的模型
1)使用下方命令安装transformers
pip install transformers
- 1
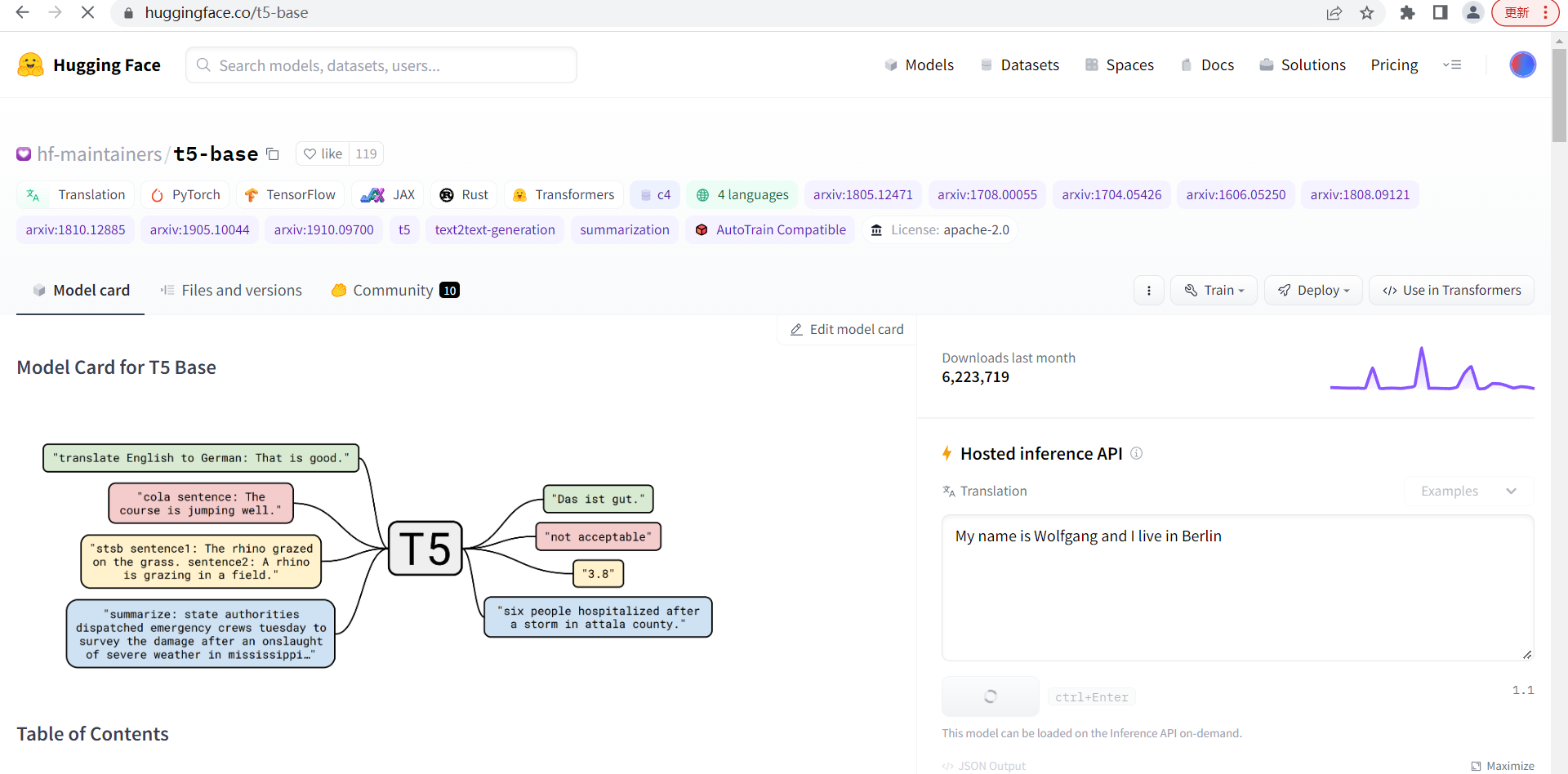
2)查找合适的预训练模型
以T5为例,在huggingface网站搜索t5,进入详情页点files and verisons。就会看到如下方图所示的模型文件和配置文件。
2.进入预训练界面
1)找到首页按钮 train 进入AutoTrain界面
跳转至AutoTrain界面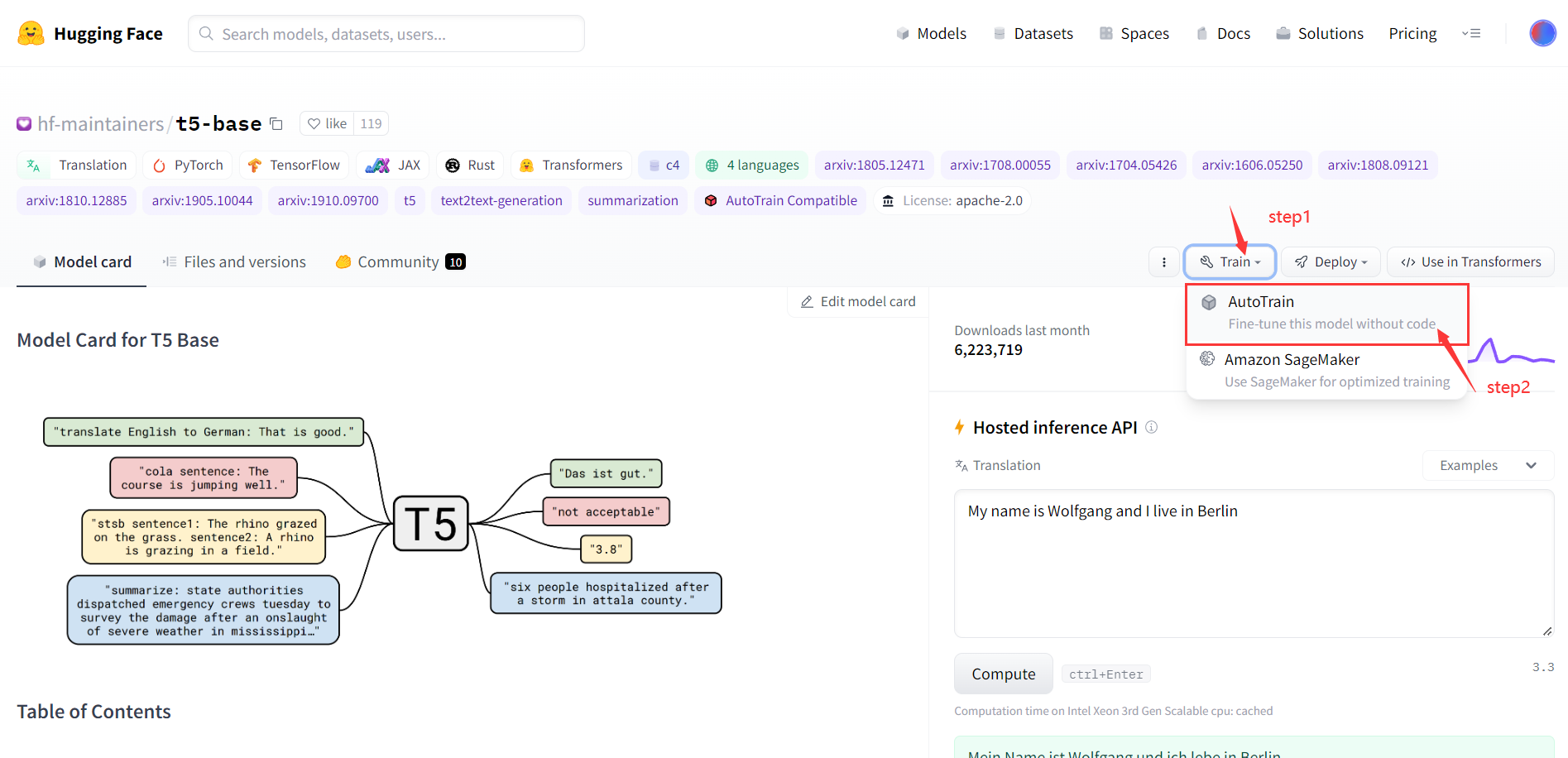
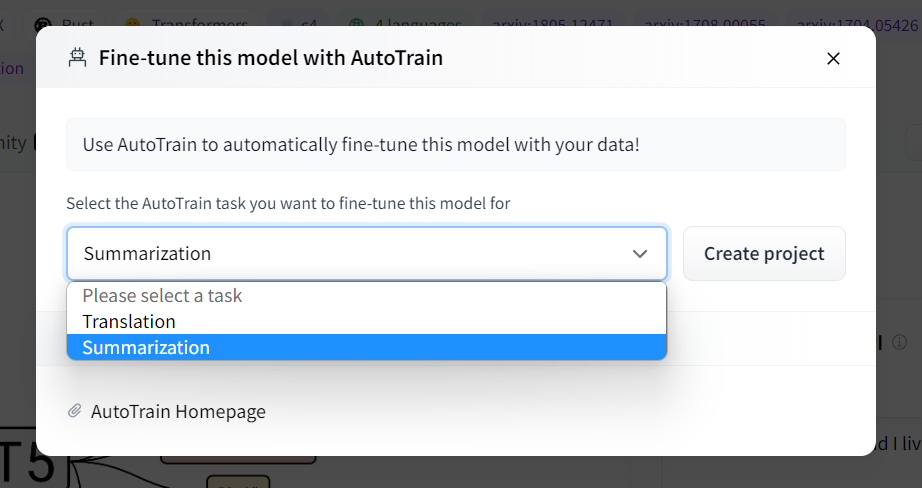
2)选择训练的任务
这里,我希望做生成的任务,因此选择了Summarize摘要类型的来完成。
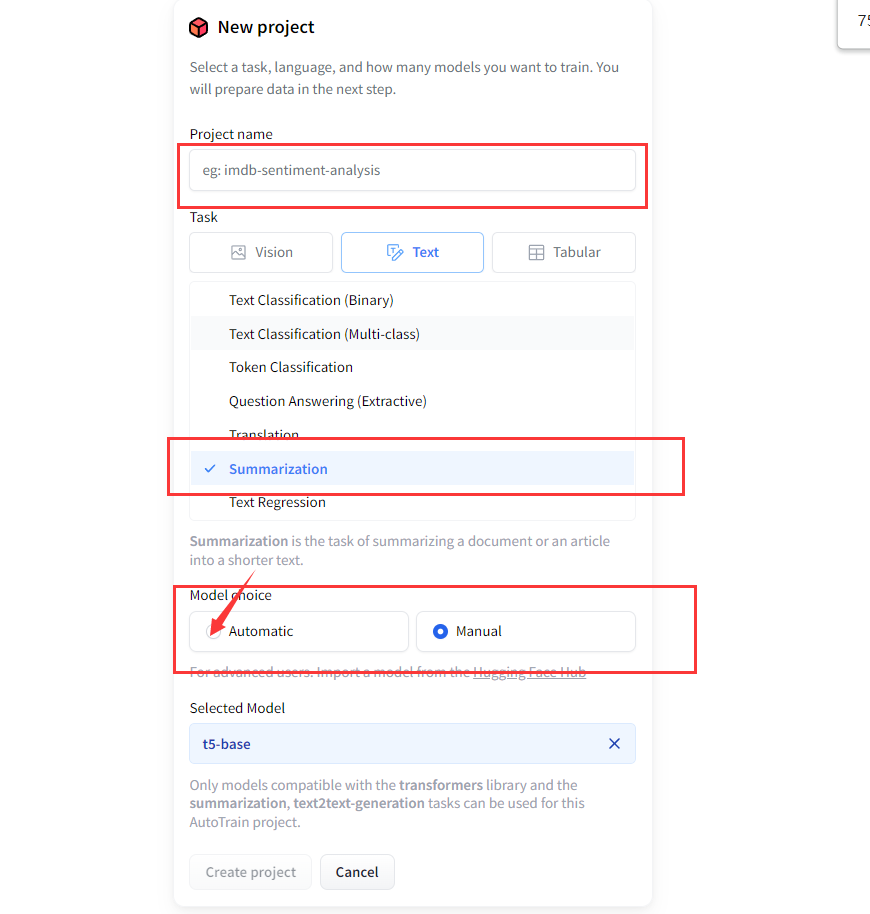
3)填写fine-tune的项目信息
填写项目名称,任务类型,以及手动还是自动(选择了自动的我,并没有探索手动需要怎么做…)的信息,并创建一个自己的项目。
3.准备数据并开始训练
1)准备数据
这里支持上传csv, json格式的数据,并给出了数据样例。
数据量一开始先搞个3000条以下! 后面解释具体的原因。
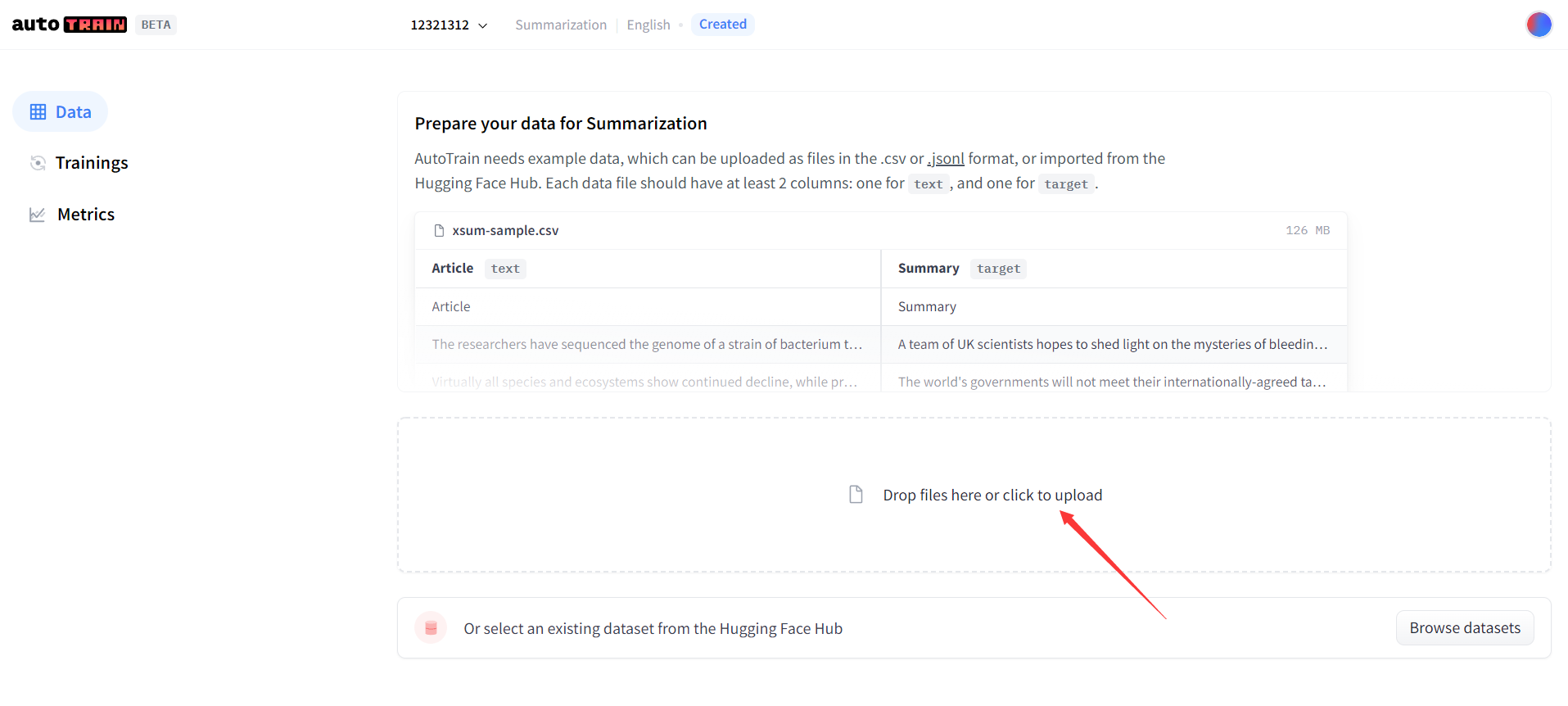
这里给出了我上传的数据样例,是json格式的,数据量3000。

2)选择对应的数据列
传入数据后,系统会简单的识别一下。我这个文件有3列,但是实际只用到2列。因此,后面有两个下拉框,问我选择哪两列数据分别作为源列和目标列。
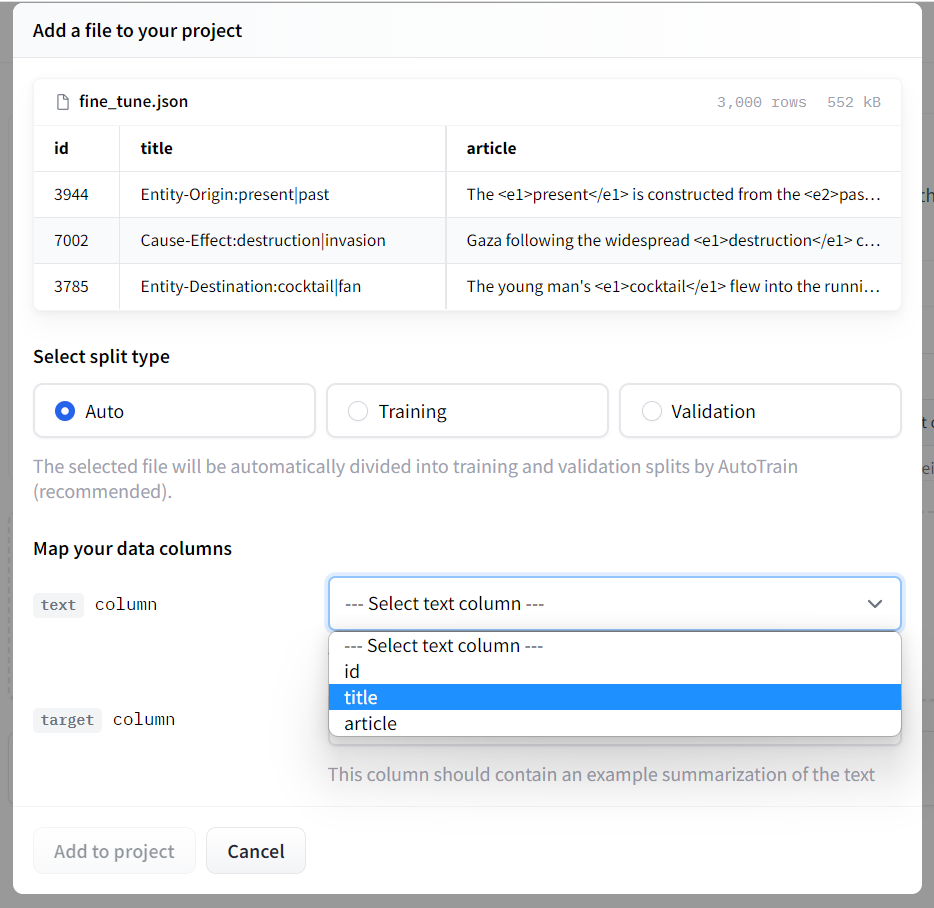
3)准备训练
数据上传成功后,通过Go to trainings进入训练界面。
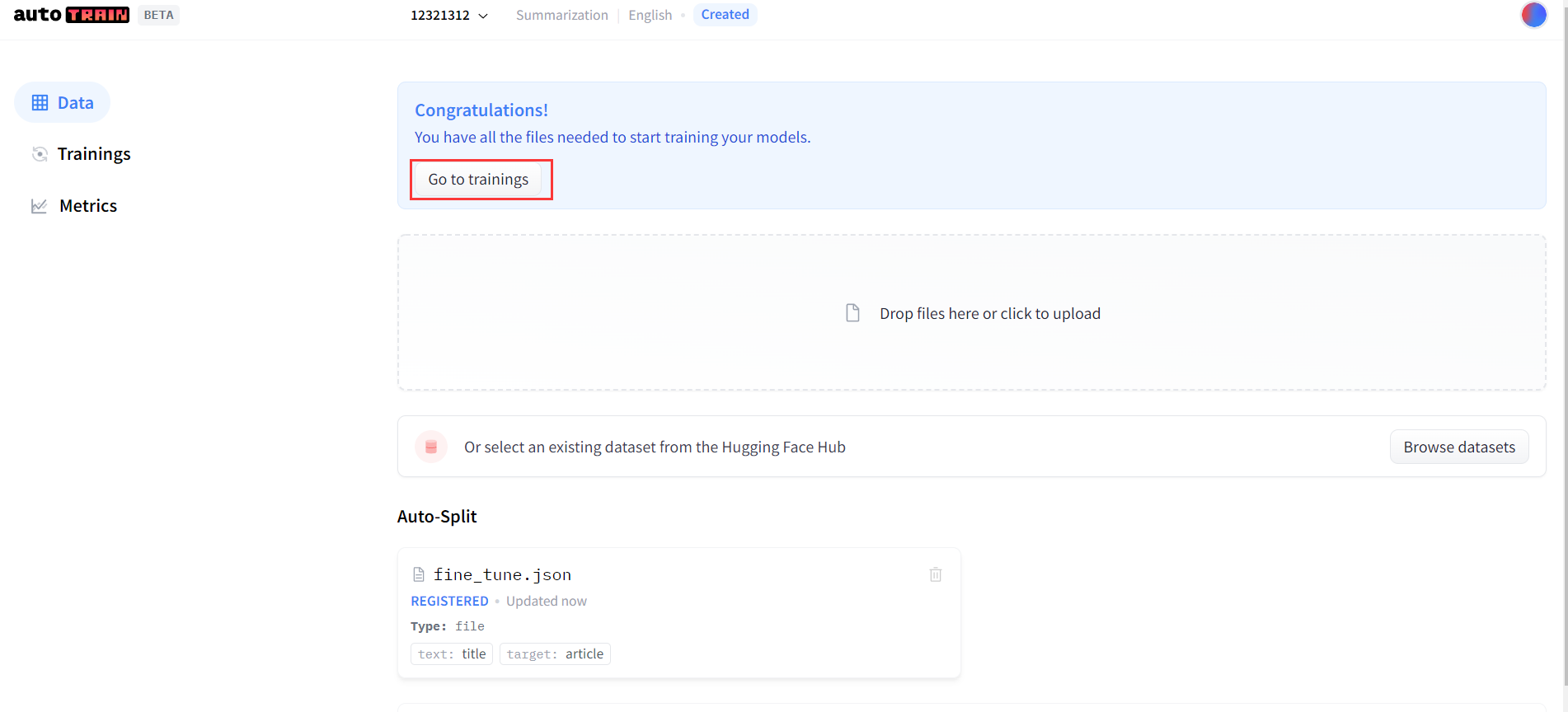
进入训练界面后,需要选择训练模型。我选用了第一个。
这里要解释一下建议3000条以下数据量的原因:因为3000条以上需要使用大模型并交钱了,作为看这篇文章的小白,最好先训练试一试,不要急于一次性解决问题。
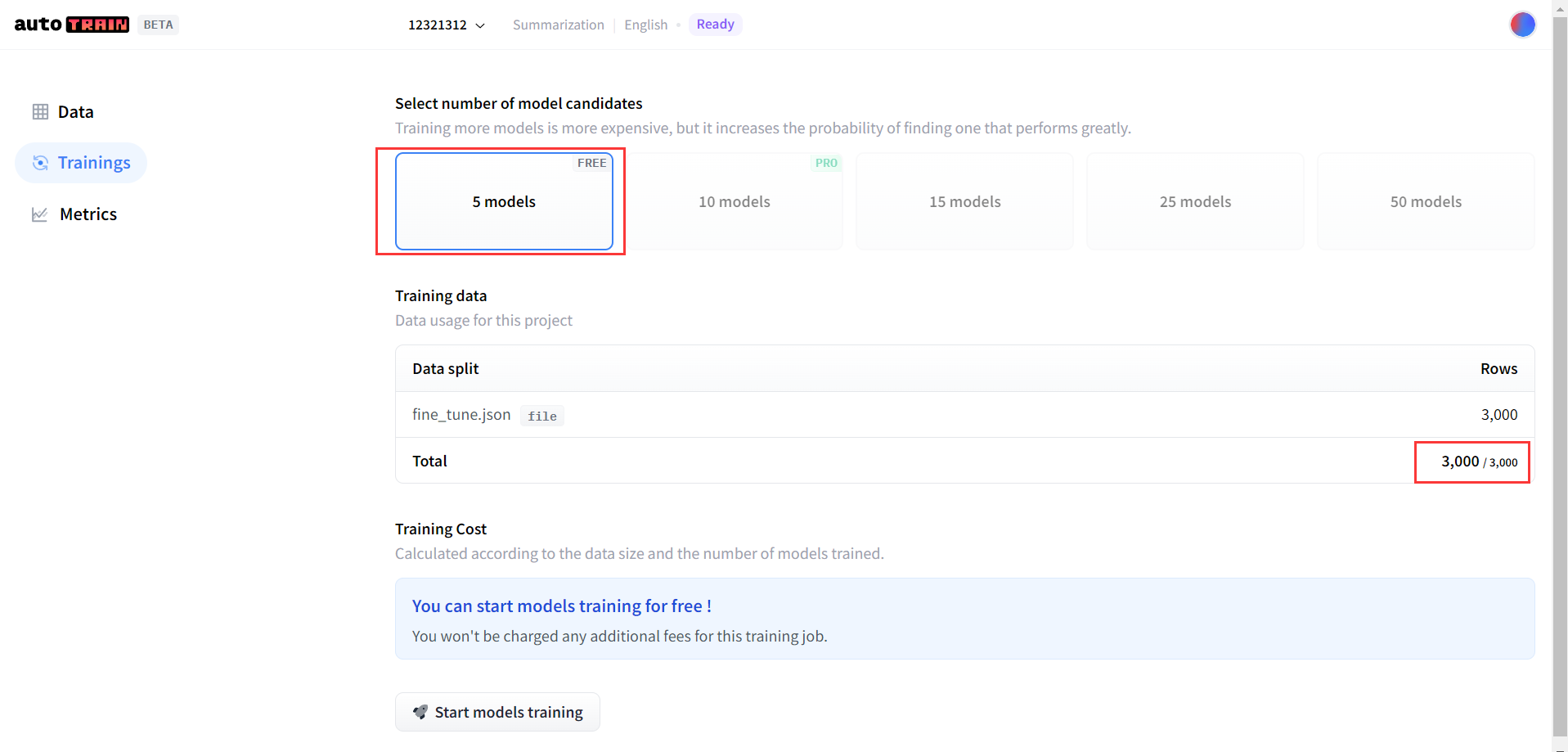
4)开始训练吧
点击Start models training按钮,开始训练模型。需要等待几分钟呢。
4.下载模型并使用
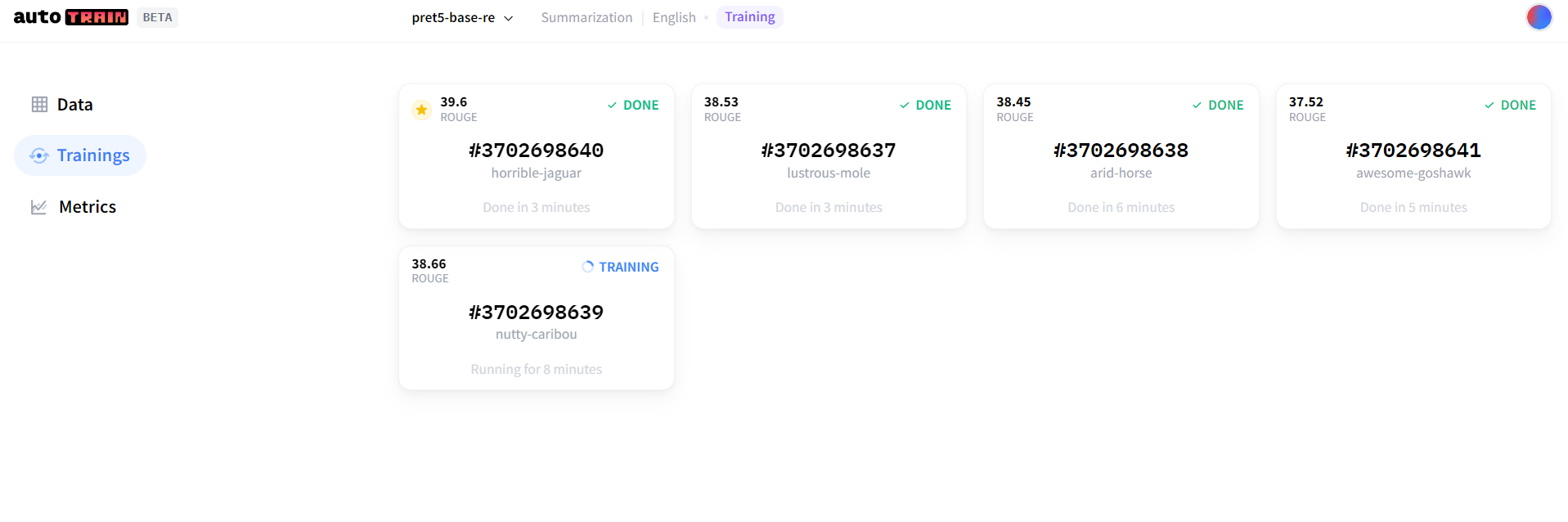
1)这里是训练模型的结果
这5个模型内部包含的文件是有所不同的,可以点击每个模型的详情页查看。但是博主还不太明白区别在哪里,知道的可以下方评论留言。(大家可以注意一下每个模型下的文件大小,虽然使用的是T5-base进行训练,但实际上生成的5个模型,有一个参数量大小与t5-large一样大,很有可能会导致服务器带不动而不能训练)
带有星星标志的模型文件缺少一个spiece.model,因此我没有使用,而是选择了第三个模型(我这里的第三个是t5-base一样大,第二个与t5-large一样大)。
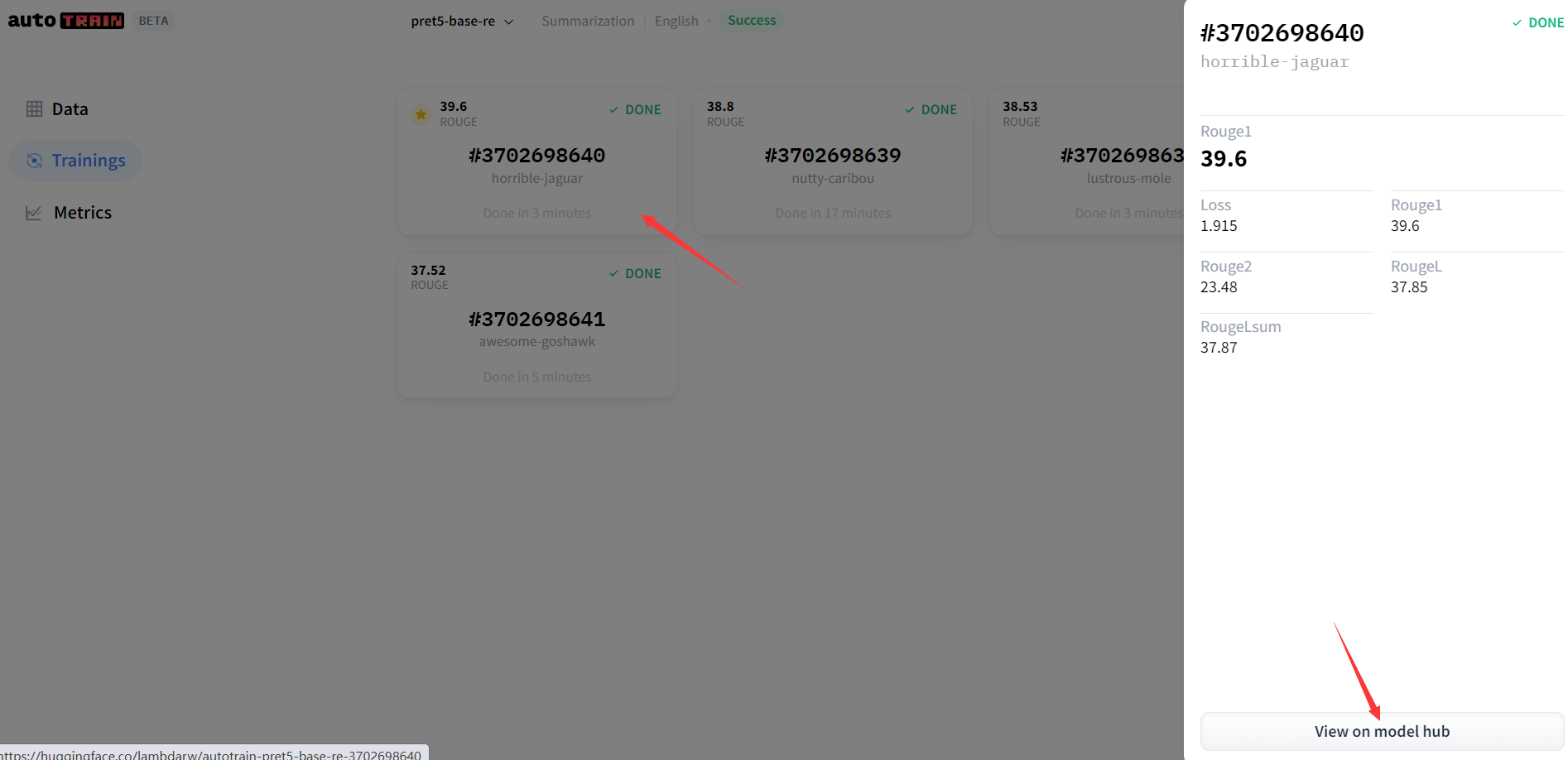
2)使用模型
选择你要使用的模型,并利用如下代码调用。注意,使用过程中,保证外网畅通噢!
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("lambdarw/autotrain-pret5-base-re-3702698639") # 你的用户名/项目名称
model = AutoModelForSeq2SeqLM.from_pretrained("lambdarw/autotrain-pret5-base-re-3702698639") # 你的用户名/项目名称
- 1
- 2
- 3
- 4
- 5
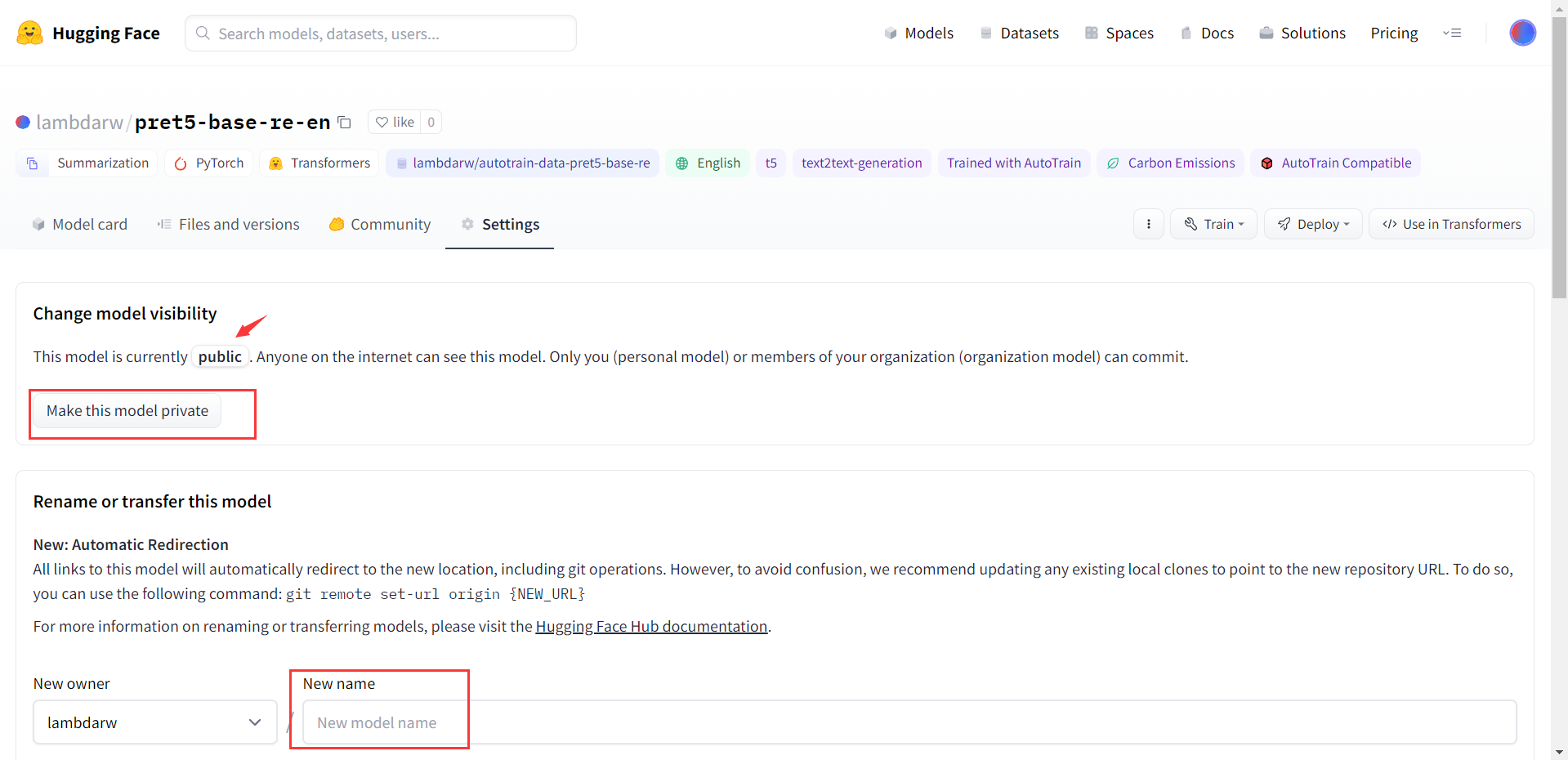
3)修改名称并公开
想要使用自己的模型,必须将它设置为pulic,否则会报Unauthorized错误。如下:
requests.exceptions.HTTPError: 401 Client Error: Unauthorized for url: https://huggingface.co/lambdarw/pret5-base-re-en/resolve/main/spiece.model
- 1
如果希望自己的模型更加有辨识度,方便记忆,也可以给模型修改一下名称。在settings标签页中,可以修改项目名称,删除项目,公开项目或私有项目,等等操作。
不希望使用外网,选用离线的方式fine-tune的小伙伴推荐参考博文:Hugging face 模型微调系列1—— 实战transfomers文本分类

