
- 1【Angular】angular去除输入的空格,Angular自定义属性指令-禁止input框输入空格-以及删除复制内容中的空格(附有其他解决办法)_angular nz-input 过滤空格
- 2谷歌Gemini API 应用(二):LangChain 加持_langchain4j stream apikey
- 3源码级深度理解 Java SPI_java spi could not be instantiated
- 4线程常用API
- 5mysql日期函数
- 6编程判断元素归类_编程:找出所有符合条件的元素
- 7鸿蒙os 开发语言_鸿蒙os应用开发备忘
- 8怎么开发鸿蒙应用 ,一文讲清楚_鸿蒙系统应用开发工具
- 9前端样式布局flex_flex-warp
- 10vue-element-admin 移除 mock 接入后端接口_vue element vue 去掉mock
#RAG##AIGC#检索增强生成 (RAG) 基本介绍和入门实操示例_rag命名识别
赞
踩
本文包括RAG基本介绍和入门实操示例
RAG 基本介绍
通用语言模型可以进行微调以实现一些常见任务,例如情感分析和命名实体识别。这些任务通常不需要额外的背景知识。
对于更复杂和知识密集型的任务,可以构建基于语言模型的系统来访问外部知识源来完成任务。这使得事实更加一致,提高了生成响应的可靠性,并有助于减轻“幻觉”问题。
Meta AI 研究人员推出了一种称为检索增强生成(RAG)的方法来解决此类知识密集型任务。 RAG 将信息检索组件与文本生成器模型相结合。 RAG 可以进行微调,并且可以有效地修改其内部知识,而无需重新训练整个模型。
RAG 接受输入并检索一组给定来源(例如维基百科)的相关/支持文档。这些文档作为上下文与原始输入提示连接起来,并输入到生成最终输出的文本生成器。这使得 RAG 能够适应事实可能随时间变化的情况。这非常有用,因为 LLMs 的参数知识是静态的。 RAG 允许语言模型绕过再训练,从而能够访问最新信息,从而通过基于检索的生成来生成可靠的输出。
Lewis 等人 (2021) 提出了一种 RAG 的通用微调方法。预训练的 seq2seq 模型用作参数存储器,维基百科的密集向量索引用作非参数存储器(使用神经预训练检索器访问)。下面概述了该方法的工作原理:
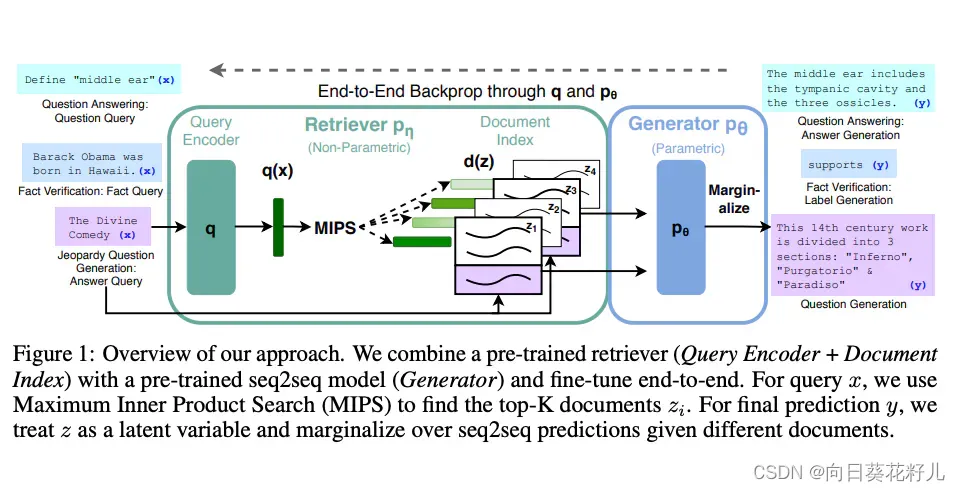
RAG 在自然问题等多项基准测试中表现强劲, WebQuestions , 网络问题,和 CuratedTrec。在针对 MS-MARCO 和 Jeopardy 问题进行测试时,RAG 生成的答案更加真实、具体和多样化。 RAG 还改进了 FEVER 事实验证的结果。
这表明 RAG 作为增强知识密集型任务中语言模型输出的可行选择的潜力。
最近,这些基于检索器的方法变得越来越流行,并与 ChatGPT 等流行的 LLMs 相结合,以提高功能和事实一致性。
RAG 用例:生成友好的 ML 论文标题
下面,我们准备了一个笔记本教程,展示如何使用开源 LLMs 构建 RAG 系统来生成简短的机器学习论文标题:
RAG入门
虽然大型语言模型(LLM)显示出强大的功能来支持高级用例,但它们也存在事实不一致和幻觉等问题。检索增强生成(RAG)是丰富LLM能力和提高其可靠性的一种强大方法。
RAG涉及通过用有助于完成任务的相关信息丰富提示上下文,将LLM与外部知识相结合。
本教程展示了如何利用矢量存储和开源LLM开始使用RAG。
为了展示RAG的强大功能,本用例将涵盖构建一个RAG系统,该系统从原始ML论文标题中建议简短且易于阅读的ML论文标题。
对于普通受众来说,纸质资料可能过于技术化,因此使用RAG在之前创建的短标题的基础上生成小标题可以使研究论文标题更容易访问,并用于科学传播,如以时事通讯或博客的形式。
在开始之前,让我们先安装我们将要使用的库:
%%capture
!pip install chromadb tqdm fireworks-ai python-dotenv pandas
!pip install sentence-transformers
- 1
- 2
- 3
在继续之前,您需要获得Fireworks API密钥才能使用Mistral 7B模型。
查看此快速指南以获取您的Fireworks API密钥:: https://readme.fireworks.ai/docs
import fireworks.client
import os
import dotenv
import chromadb
import json
from tqdm.auto import tqdm
import pandas as pd
import random
# 可以使用 Colab secrets 设置环境
dotenv.load_dotenv()
fireworks.client.api_key = os.getenv("FIREWORKS_API_KEY")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
开始
让我们定义一个函数,从Fireworks推理平台获取完成。
def get_completion(prompt, model=None, max_tokens=50):
fw_model_dir = "accounts/fireworks/models/"
if model is None:
model = fw_model_dir + "llama-v2-7b"
else:
model = fw_model_dir + model
completion = fireworks.client.Completion.create(
model=model,
prompt=prompt,
max_tokens=max_tokens,
temperature=0
)
return completion.choices[0].text
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
让我们首先尝试一个简单提示的函数:
get_completion("Hello, my name is")
- 1
' Katie and I am a 20 year old student at the University of Leeds. I am currently studying a BA in English Literature and Creative Writing. I have been working as a tutor for over 3 years now and I'
- 1
现在让我们使用Mistral-7B-指令进行测试:
mistral_llm = "mistral-7b-instruct-4k"
get_completion("Hello, my name is", model=mistral_llm)
- 1
- 2
- 3
' [Your Name]. I am a [Your Profession/Occupation]. I am writing to [Purpose of Writing].\n\nI am writing to [Purpose of Writing] because [Reason for Writing]. I believe that ['
- 1
Mistral 7B指令模型需要使用特殊的指令标记 [INST] <instruction> [/INST] 进行指令,以获得正确的行为。您可以在此处找到有关如何提示Mistral 7B指令的更多说明:: https://docs.mistral.ai/llm/mistral-instruct-v0.1
mistral_llm = "mistral-7b-instruct-4k"
get_completion("Tell me 2 jokes", model=mistral_llm)
- 1
- 2
- 3
".\n1. Why don't scientists trust atoms? Because they make up everything!\n2. Did you hear about the mathematician who’s afraid of negative numbers? He will stop at nothing to avoid them."
- 1
mistral_llm = "mistral-7b-instruct-4k"
get_completion("[INST]Tell me 2 jokes[/INST]", model=mistral_llm)
- 1
- 2
- 3
" Sure, here are two jokes for you:\n\n1. Why don't scientists trust atoms? Because they make up everything!\n2. Why did the tomato turn red? Because it saw the salad dressing!"
- 1
现在,让我们尝试使用一个更复杂的提示,其中包含说明:
prompt = """[INST]
Given the following wedding guest data, write a very short 3-sentences thank you letter:
{
"name": "John Doe",
"relationship": "Bride's cousin",
"hometown": "New York, NY",
"fun_fact": "Climbed Mount Everest in 2020",
"attending_with": "Sophia Smith",
"bride_groom_name": "Tom and Mary"
}
Use only the data provided in the JSON object above.
The senders of the letter is the bride and groom, Tom and Mary.
[/INST]"""
get_completion(prompt, model=mistral_llm, max_tokens=150)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
" Dear John Doe,\n\nWe, Tom and Mary, would like to extend our heartfelt gratitude for your attendance at our wedding. It was a pleasure to have you there, and we truly appreciate the effort you made to be a part of our special day.\n\nWe were thrilled to learn about your fun fact - climbing Mount Everest is an incredible accomplishment! We hope you had a safe and memorable journey.\n\nThank you again for joining us on this special occasion. We hope to stay in touch and catch up on all the amazing things you've been up to.\n\nWith love,\n\nTom and Mary"
- 1
RAG用例:生成短文标题
对于RAG用例,我们将使用a dataset 其中包含每周热门ML论文的列表。
用户将提供原始论文标题。然后,我们将接受该输入,然后使用数据集生成简短而吸引人的论文标题的上下文,这将有助于为原始输入标题生成吸引人的标题。
步骤1:加载数据集
让我们首先加载我们将使用的数据集:
# load dataset from data/ folder to pandas dataframe
# dataset contains column names
ml_papers = pd.read_csv("../data/ml-potw-10232023.csv", header=0)
# remove rows with empty titles or descriptions
ml_papers = ml_papers.dropna(subset=["Title", "Description"])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
ml_papers.head()
- 1
| Title | Description | PaperURL | TweetURL | Abstract | |
|---|---|---|---|---|---|
| 0 | Llemma | an LLM for mathematics which is based on conti... | https://arxiv.org/abs/2310.10631 | https://x.com/zhangir_azerbay/status/171409802... | We present Llemma, a large language model for ... |
| 1 | LLMs for Software Engineering | a comprehensive survey of LLMs for software en... | https://arxiv.org/abs/2310.03533 | https://x.com/omarsar0/status/1713940983199506... | This paper provides a survey of the emerging a... |
| 2 | Self-RAG | presents a new retrieval-augmented framework t... | https://arxiv.org/abs/2310.11511 | https://x.com/AkariAsai/status/171511027707796... | Despite their remarkable capabilities, large l... |
| 3 | Retrieval-Augmentation for Long-form Question ... | explores retrieval-augmented language models o... | https://arxiv.org/abs/2310.12150 | https://x.com/omarsar0/status/1714986431859282... | We present a study of retrieval-augmented lang... |
| 4 | GenBench | presents a framework for characterizing and un... | https://www.nature.com/articles/s42256-023-007... | https://x.com/AIatMeta/status/1715041427283902... | NaN |
# convert dataframe to list of dicts with Title and Description columns only
ml_papers_dict = ml_papers.to_dict(orient="records")
- 1
- 2
- 3
ml_papers_dict[0]
- 1
{'Title': 'Llemma',
'Description': 'an LLM for mathematics which is based on continued pretraining from Code Llama on the Proof-Pile-2 dataset; the dataset involves scientific paper, web data containing mathematics, and mathematical code; Llemma outperforms open base models and the unreleased Minerva on the MATH benchmark; the model is released, including dataset and code to replicate experiments.',
'PaperURL': 'https://arxiv.org/abs/2310.10631',
'TweetURL': 'https://x.com/zhangir_azerbay/status/1714098025956864031?s=20',
'Abstract': 'We present Llemma, a large language model for mathematics. We continue pretraining Code Llama on the Proof-Pile-2, a mixture of scientific papers, web data containing mathematics, and mathematical code, yielding Llemma. On the MATH benchmark Llemma outperforms all known open base models, as well as the unreleased Minerva model suite on an equi-parameter basis. Moreover, Llemma is capable of tool use and formal theorem proving without any further finetuning. We openly release all artifacts, including 7 billion and 34 billion parameter models, the Proof-Pile-2, and code to replicate our experiments.'}
- 1
- 2
- 3
- 4
- 5
我们将使用PenceTransformer生成嵌入,并将其存储到Chroma文档存储中。
from chromadb import Documents, EmbeddingFunction, Embeddings
from sentence_transformers import SentenceTransformer
embedding_model = SentenceTransformer('all-MiniLM-L6-v2')
class MyEmbeddingFunction(EmbeddingFunction):
def __call__(self, input: Documents) -> Embeddings:
batch_embeddings = embedding_model.encode(input)
return batch_embeddings.tolist()
embed_fn = MyEmbeddingFunction()
# Initialize the chromadb directory, and client.
client = chromadb.PersistentClient(path="./chromadb")
# create collection
collection = client.get_or_create_collection(
name=f"ml-papers-nov-2023"
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
.gitattributes: 100%|██████████| 1.18k/1.18k [00:00<00:00, 194kB/s]
1_Pooling/config.json: 100%|██████████| 190/190 [00:00<00:00, 204kB/s]
README.md: 100%|██████████| 10.6k/10.6k [00:00<00:00, 7.64MB/s]
config.json: 100%|██████████| 612/612 [00:00<00:00, 679kB/s]
config_sentence_transformers.json: 100%|██████████| 116/116 [00:00<00:00, 94.0kB/s]
data_config.json: 100%|██████████| 39.3k/39.3k [00:00<00:00, 7.80MB/s]
pytorch_model.bin: 100%|██████████| 90.9M/90.9M [00:03<00:00, 24.3MB/s]
sentence_bert_config.json: 100%|██████████| 53.0/53.0 [00:00<00:00, 55.4kB/s]
special_tokens_map.json: 100%|██████████| 112/112 [00:00<00:00, 161kB/s]
tokenizer.json: 100%|██████████| 466k/466k [00:00<00:00, 6.15MB/s]
tokenizer_config.json: 100%|██████████| 350/350 [00:00<00:00, 286kB/s]
train_script.py: 100%|██████████| 13.2k/13.2k [00:00<00:00, 12.2MB/s]
vocab.txt: 100%|██████████| 232k/232k [00:00<00:00, 9.15MB/s]
modules.json: 100%|██████████| 349/349 [00:00<00:00, 500kB/s]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
我们现在将为批生成嵌入:
# Generate embeddings, and index titles in batches
batch_size = 50
# loop through batches and generated + store embeddings
for i in tqdm(range(0, len(ml_papers_dict), batch_size)):
i_end = min(i + batch_size, len(ml_papers_dict))
batch = ml_papers_dict[i : i + batch_size]
# Replace title with "No Title" if empty string
batch_titles = [str(paper["Title"]) if str(paper["Title"]) != "" else "No Title" for paper in batch]
batch_ids = [str(sum(ord(c) + random.randint(1, 10000) for c in paper["Title"])) for paper in batch]
batch_metadata = [dict(url=paper["PaperURL"],
abstract=paper['Abstract'])
for paper in batch]
# generate embeddings
batch_embeddings = embedding_model.encode(batch_titles)
# upsert to chromadb
collection.upsert(
ids=batch_ids,
metadatas=batch_metadata,
documents=batch_titles,
embeddings=batch_embeddings.tolist(),
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
100%|██████████| 9/9 [00:01<00:00, 7.62it/s]
- 1
现在我们可以测试寻回器:
collection = client.get_or_create_collection(
name=f"ml-papers-nov-2023",
embedding_function=embed_fn
)
retriever_results = collection.query(
query_texts=["Software Engineering"],
n_results=2,
)
print(retriever_results["documents"])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
[['LLMs for Software Engineering', 'Communicative Agents for Software Development']]
- 1
现在,让我们总结一下最后的提示:
# user query
user_query = "S3Eval: A Synthetic, Scalable, Systematic Evaluation Suite for Large Language Models"
# query for user query
results = collection.query(
query_texts=[user_query],
n_results=10,
)
# concatenate titles into a single string
short_titles = '\n'.join(results['documents'][0])
prompt_template = f'''[INST]
Your main task is to generate 5 SUGGESTED_TITLES based for the PAPER_TITLE
You should mimic a similar style and length as SHORT_TITLES but PLEASE DO NOT include titles from SHORT_TITLES in the SUGGESTED_TITLES, only generate versions of the PAPER_TILE.
PAPER_TITLE: {user_query}
SHORT_TITLES: {short_titles}
SUGGESTED_TITLES:
[/INST]
'''
responses = get_completion(prompt_template, model=mistral_llm, max_tokens=2000)
suggested_titles = ''.join([str(r) for r in responses])
# Print the suggestions.
print("Model Suggestions:")
print(suggested_titles)
print("\n\n\nPrompt Template:")
print(prompt_template)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
Model Suggestions:
1. S3Eval: A Comprehensive Evaluation Suite for Large Language Models
2. Synthetic and Scalable Evaluation for Large Language Models
3. Systematic Evaluation of Large Language Models with S3Eval
4. S3Eval: A Synthetic and Scalable Approach to Language Model Evaluation
5. S3Eval: A Synthetic and Scalable Evaluation Suite for Large Language Models
Prompt Template:
[INST]
Your main task is to generate 5 SUGGESTED_TITLES based for the PAPER_TITLE
You should mimic a similar style and length as SHORT_TITLES but PLEASE DO NOT include titles from SHORT_TITLES in the SUGGESTED_TITLES, only generate versions of the PAPER_TILE.
PAPER_TITLE: S3Eval: A Synthetic, Scalable, Systematic Evaluation Suite for Large Language Models
SHORT_TITLES: Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
ChemCrow: Augmenting large-language models with chemistry tools
A Survey of Large Language Models
LLaMA: Open and Efficient Foundation Language Models
SparseGPT: Massive Language Models Can Be Accurately Pruned In One-Shot
REPLUG: Retrieval-Augmented Black-Box Language Models
LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention
Auditing large language models: a three-layered approach
Fine-Tuning Language Models with Just Forward Passes
DERA: Enhancing Large Language Model Completions with Dialog-Enabled Resolving Agents
SUGGESTED_TITLES:
[/INST]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
正如您所看到的,LLM生成的简短标题在某种程度上是可以的。这个用例仍然需要做更多的工作,并且可能也会从微调中受益。为了本教程的目的,我们使用Firework的开源模型提供了一个简单的RAG应用程序
在这里尝试其他开源模型: https://app.fireworks.ai/models
R点击此处了解有关Fireworks API的更多信息: https://readme.fireworks.ai/reference/createchatcompletion
参考文献
· https://arxiv.org/abs/2312.10997 Retrieval-Augmented Generation for Large Language Models: A Survey
大型语言模型的检索增强生成:一项调查
· https://ai.meta.com/blog/retrieval-augmented-generation-streamlining-the-creation-of-intelligent-natural-language-processing-models/ Retrieval Augmented Generation: Streamlining the creation of intelligent natural language processing models
检索增强生成:简化智能自然语言处理模型的创建
· https://arxiv.org/abs/2302.07842 Augmented Language Models: a Survey
增强语言模型:调查

