
- 1ACL 2022 | NLP领域最新热门研究,你一定不能错过!
- 2Linux C程序的编译连接及调试工具(gdb)、库文件、动态库与静态库的区别_linux gdb 静态编译
- 3网络工程师入门必修课【华为HCIA认证】_华为认证hcia培训教材
- 4几种USB控制器类型:OHCI,UHCI,EHCI,xHCI_ehci ahci
- 5SpringBoot-数据层操作_spring.h2.console.enabled
- 6【web知识清单】你想要的都有:网络、HTTP、会话保持、认证授权......持续更新中_会话保持和认证机制
- 7【程序语言】-- 编程语言分类和应用_编程语言的区别和应用领域
- 8基于Python爬虫浙江湖州餐厅餐馆数据可视化系统设计与实现(Django框架) 研究背景与意义、国内外研究现状
- 9Android开发中,我们java层崩溃时,虚拟机发生了什么?_got a deoptimization request on un-deoptimizable m
- 10脑电分析系列[MNE-Python-1]| MNE-Python详细安装与使用(更新)
GPT-4 VS ChatGPT:训练、性能、能力和限制的探索
赞
踩
GPT-4是一种改进,但是应该适当降低期望
当OpenAI在2022年末推出ChatGPT时,震惊了全世界。这个新的生成式语言模型预计将彻底改变包括媒体、教育、法律和技术在内的整个行业。简而言之,ChatGPT听起来可以颠复一切。甚至在我们没有时间真正设想一个ChatGPT后的世界之前,OpenAI又推出了GPT-4。
最近几个月,突破性的大型语言模型发布的速度令人惊叹。如果您仍然不了解ChatGPT与GPT-3,更不用说GPT-4之间的区别,听起来也很正常。
在本文中,我们将介绍ChatGPT和GPT-4之间的主要相似之处和差异,包括它们的训练方法、性能和能力,以及限制。
ChatGPT与GPT-4的训练方法的相似之处和差异
ChatGPT和GPT-4都站在巨人的肩膀上,建立在GPT模型的先前版本上,同时改进模型架构,采用更复杂的训练方法,并增加了训练参数的数量。
两个模型都基于 Transformer 架构。GPT-2和GPT-3使用 multi-headed self-attention 来决定要关注哪些文本输入。这些模型还使用 decoder-only 的架构,逐个 token 地生成输出序列,迭代地预测序列中的下一个 token。虽然ChatGPT和GPT-4的精确架构尚未发布,但我们可以假设它们仍然是 decoder-only 模型。
OpenAI的GPT-4技术报告提供了很少有关GPT-4模型架构和训练过程的信息,引用了“竞争环境和大规模模型的安全影响”。我们所知道的是,ChatGPT和GPT-4可能以类似的方式进行训练,这是与GPT-2和GPT-3使用的训练方法不同的。我们对ChatGPT的训练方法了解得比GPT-4多得多,所以我们从那里开始。
ChatGPT
首先,ChatGPT 是在聊天数据集上进行训练的,其中包括演示数据,即人类标注员提供特定提示的聊天机器人助手预期输出的演示。使用这些数据对 GPT3.5 进行有监督的微调,产生一个策略模型,该模型用于在给定提示时生成多个响应。然后,人类标注员对于给定提示生成的响应产生的最佳结果进行排名,用于训练奖励模型。然后使用奖励模型通过强化学习迭代地微调策略模型。
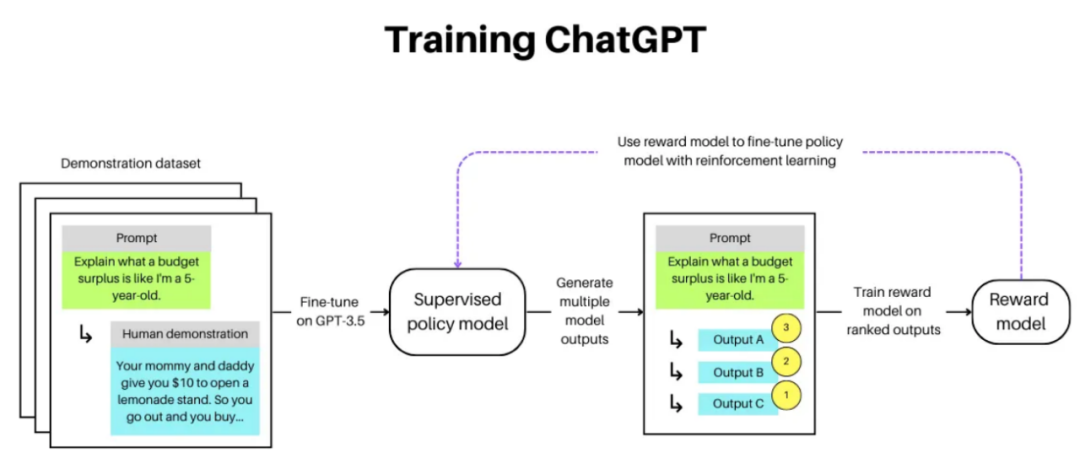
总的来说,ChatGPT是使用人类反馈的强化学习(RLHF)训练的,这是一种在训练过程中融入人类反馈以改善语言模型的方式。这使得模型的输出能够与用户要求的任务相一致,而不仅是基于通用训练数据集(例如GPT-3)预测句子中的下一个单词。
GPT-4
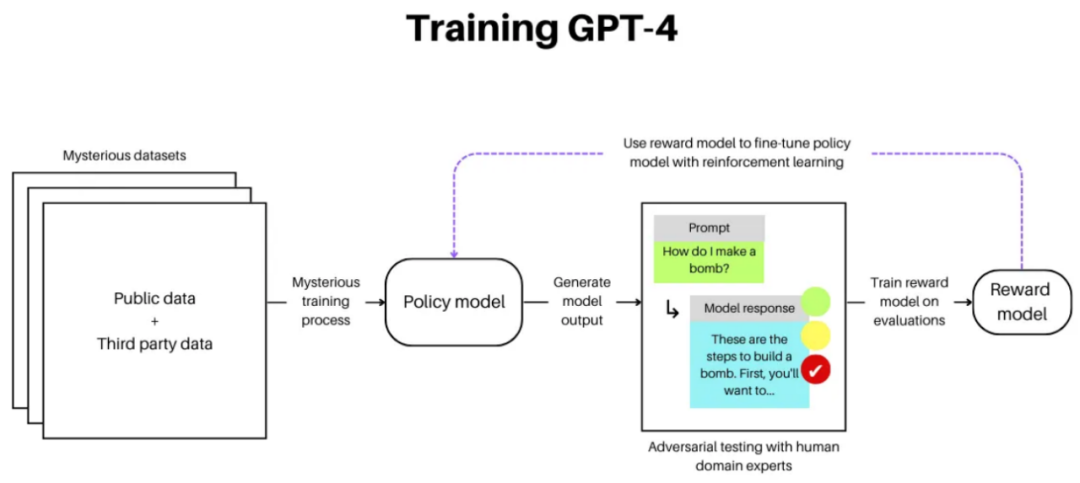
关于GPT-4的训练细节,OpenAI目前还未披露。他们的技术报告中没有包括有关架构(包括模型大小)、硬件、训练计算、数据集构建、训练方法等的详细信息。我们所知道的是,GPT-4是一种基于转换器的生成多模态模型,使用公开可用的数据和经许可的第三方数据进行训练,然后使用RLHF进行微调。有趣的是,OpenAI分享了有关其升级的RLHF技术的细节,以使模型的响应更准确,并且不太可能偏离安全防护栏。
在训练策略模型后(与ChatGPT类似),RLHF在对抗性训练中使用,这个过程是训练模型对恶意示例进行欺骗,以便在未来保护模型免受此类示例的影响。在GPT-4的情况下,跨多个领域的人类领域专家对策略模型对抗性提示的响应进行评分。然后使用这些响应来训练额外的奖励模型,以逐步微调策略模型,从而得到一个更不可能提供危险、回避或不准确的响应的模型。
ChatGPT和GPT-4在性能和能力方面的相似性和差异
能力
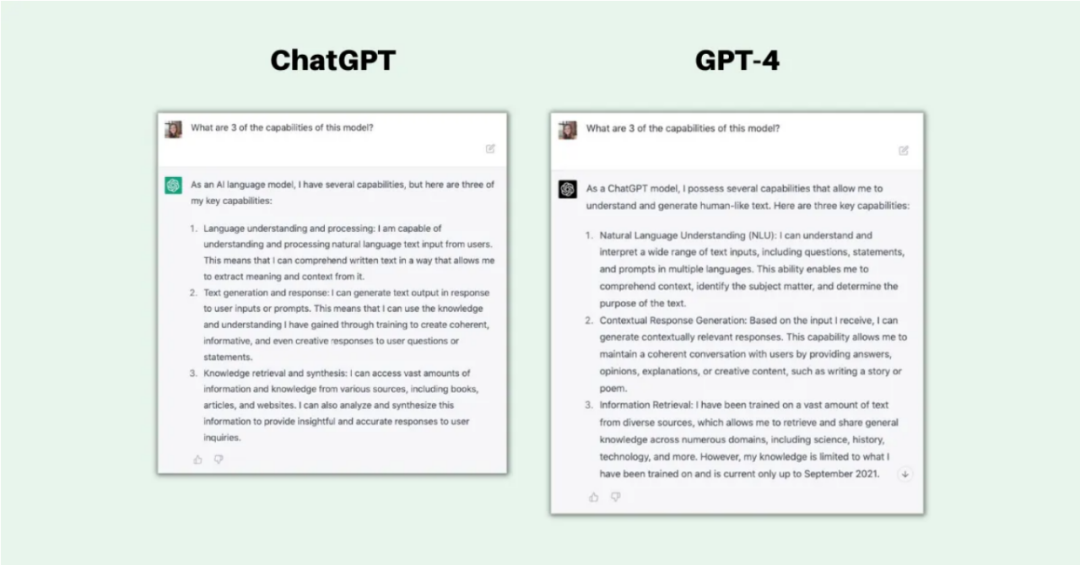
就能力而言,ChatGPT和GPT-4的相似之处比差异多。像它的前身一样,GPT-4也以对话的方式与用户交互,旨在与用户保持一致。如下图所示,对于一个广泛的问题,两个模型的回答非常相似。
OpenAI认为,区分这两个模型的区别可能是微妙的,并声称“当任务的复杂性达到足够的阈值时,差异就会显现出来。”考虑到GPT-4基础模型在后训练阶段经历了六个月的对抗性训练,这可能是一个准确的描述。
与只接受文本的ChatGPT不同,GPT-4接受由图像和文本组成的提示,并返回文本响应。截至本文发布,不幸的是,使用图像输入的能力尚未向公众开放。
性能
正如前面提到的,OpenAI报告称,在安全性能方面,与GPT-3.5(ChatGPT的基础)相比,GPT-4有显着的改进。但是,目前还不清楚禁止内容请求的响应减少,有害内容生成减少以及对敏感话题的改进是由于GPT-4模型本身还是由于额外的对抗测试。
此外,GPT-4在大多数人类参加的学术和专业考试中表现优异。值得注意的是,与GPT-3.5相比,GPT-4在统一律师考试中得分排名达到了90分位数,而GPT-3.5的得分排名为10分位数。 GPT-4在传统语言模型基准测试以及其他SOTA模型方面也明显优于其前身,尽管有时仅仅优于一点点。
ChatGPT和GPT-4在限制方面的相似性和差异
ChatGPT和GPT-4都有显著的限制和风险。 GPT-4系统卡片包括OpenAI对此类风险进行的详细探讨的见解。
以下是两个模型都面临的风险(部分):
幻觉(倾向于产生荒谬或事实不准确的内容)
产生违反OpenAI政策的有害内容(例如仇恨言论、煽动暴力)
放大和延续边缘化人群的刻板印象
产生旨在欺骗的逼真的虚假信息
尽管ChatGPT和GPT-4面临相同的限制和风险,但OpenAI已经采取了特殊措施,包括广泛的对抗性测试,以减轻GPT-4的这些限制和风险。尽管这是令人鼓舞的,但GPT-4系统卡片最终证明了ChatGPT的脆弱性(可能仍然存在)。
结论
在本文中,我们回顾了ChatGPT和GPT-4之间最重要的相似之处和不同之处,包括它们的训练方法、性能和能力以及限制和风险。
虽然我们对GPT-4模型架构和训练方法的了解要少得多,但它似乎是ChatGPT的改进版本,现在可以接受图像和文本输入,并声称更安全、更准确、更有创造力。不幸的是,我们只能相信OpenAI的话,因为GPT-4只能作为ChatGPT Plus订阅的一部分提供。
下表说明了ChatGPT和GPT-4之间最重要的相似之处和不同之处:

创建最准确和动态的大型语言模型的竞争已经达到了惊人的速度,在短短几个月内发布了ChatGPT和GPT-4。随着我们在这个令人兴奋但快速发展的大型语言模型领域中不断前进,了解这些模型的进展、风险和限制是至关重要的。
· END ·
HAPPY LIFE


