
- 1GitHub 星标 5k+,北大学弟的硬核 CS 指南,太强了_北大cs自学指南
- 2Java网络爬虫——jsoup快速上手,爬取京东数据。同时解决‘京东安全’防爬问题_爬取京东app
- 3
- 4医疗器械FDA | 常见的网络安全材料发补问题都有哪些?
- 5c++STL set函数运用遍历 排序_c++ 遍历std set
- 6xilinx Vivado的使用详细介绍(2):创建工程、添加文件、综合、实现、管脚约束、产生比特流文件、烧写程序、硬件验证_vivado详细介绍
- 7Java项目:宠物医院预约管理系统设计和实现(java+springboot+mysql+ssm)_宠物服务预约管理的设计与实现
- 8OpenHarmony实战:烧录Hi3516DV300开发板
- 9A ConvNet for the 2020s
- 10【实体关系抽取】之——OneRel代码学习笔记(一)_onerel 模型代码实战
pytorch bert文本分类_一起读Bert文本分类代码 (pytorch篇 五)
赞
踩

Bert是去年google发布的新模型,打破了11项纪录,关于模型基础部分就不在这篇文章里多说了。这次想和大家一起读的是huggingface的pytorch-pretrained-BERT代码examples里的文本分类任务run_classifier。
关于源代码可以在huggingface的github中找到。
huggingface/pytorch-pretrained-BERTgithub.com
在前四篇文章中我分别介绍了数据预处理部分和部分的模型:
周剑:一起读Bert文本分类代码 (pytorch篇 一)zhuanlan.zhihu.com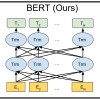
我们可以看到BertForSequenceClassification类中调用关系如下图所示。本篇文章中我会带着大家继续读BertLayer类中的BertIntermediate和BertOutput类。

打开pytorch_pretrained_bert.modeling.py,找到BertIntermediate类,代码如下:
- class BertIntermediate(nn.Module):
- def __init__(self, config):
- super(BertIntermediate, self).__init__()
- self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
- self.intermediate_act_fn = ACT2FN[config.hidden_act]
- if isinstance(config.hidden_act, str) else config.hidden_act
-
- def forward(self, hidden_states):
- hidden_states = self.dense(hidden_states)
- hidden_states = self.intermediate_act_fn(hidden_states)
- return hidden_states
我们可以看到dense是一个线形Linear层,输入size是config.hidden_size,输出size是config.intermediate_size。ACT2FN是激活函数的字典,它的代码如下:
ACT2FN = {"gelu": gelu, "relu": torch.nn.functional.relu, "swish": swish}所以BertIntermediate是一个线形Linear层加激活函数。
再找到BertOutput类,代码如下:
- class BertOutput(nn.Module):
- def __init__(self, config):
- super(BertOutput, self).__init__()
- self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
- self.LayerNorm = BertLayerNorm(config.hidden_size, eps=1e-12)
- self.dropout = nn.Dropout(config.hidden_dropout_prob)
-
- def forward(self, hidden_states, input_tensor):
- hidden_states = self.dense(hidden_states)
- hidden_states = self.dropout(hidden_states)
- hidden_states = self.LayerNorm(hidden_states + input_tensor)
- return hidden_states
可以看到BertOutput是一个输入size是config.intermediate_size,输出size是config.hidden_size。又把size从BertIntermediate中的config.intermediate_size变回config.hidden_size。然后又接了一个Dropout和一个归一化。
到此为止,我就已经和大家一起读了model里调用的所有函数。我们再从数据的forward向来总结一下代码中的BertForSequenceClassification模型。
在BertForSequenceClassification这个model中,输入的数据首先经过BertEmbeddings类。在BertEmbeddings中将每个单词变为words_embeddings + position_embeddings +token_type_embeddings三项embeddings的和。
然后,把已经变为词向量的数据输入BertSelfAttention类中。BertSelfAttention类中是一个Multi-Head Attention(少一个Linear层), 也就是说数据流入这个少一个Linear层的Multi-Head Attention。
之后,数据流入BertSelfOutput类。BertSelfOutput是一个Linear+Dropout+LayerNorm。补齐了BertSelfAttention中少的那个Linear层,并且进行一次LayerNorm。这样就完成了Transformer中前半的任务,即下图的红框部分。
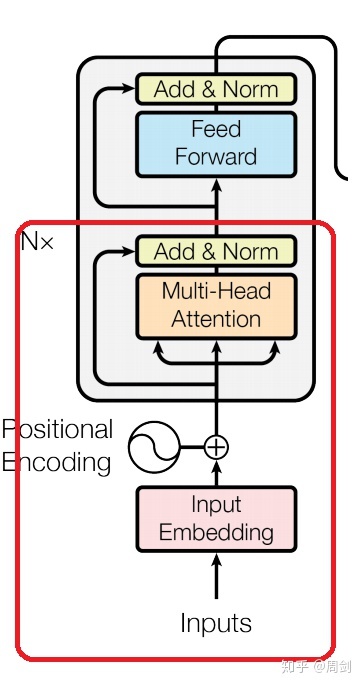
再之后,数据经过BertIntermediate和BertOutput。他们分别是今天介绍的Linear层+激活函数和Linear+Dropout+LayerNorm。这样整个Transformer的部分就算完成了。
最后,数据再流回BertForSequenceClassification这个类中,经过一个Linear层分类,输出变为一个和标签size大小一致的列表。这就是整个BertForSequenceClassification模型。
在下一篇文章中,我会重回run_classifier.py的主函数。和大家一起读代码中优化器,训练和预测部分。
周剑:一起读Bert文本分类代码 (pytorch篇 六)zhuanlan.zhihu.com

