
- 1Hadoop项目实战3—招聘数据预处理_基于hadoop的招聘数据分析项目
- 2(Android)低功耗蓝牙(BLE)开发一文全(详)解_android ble
- 3RabbitMQ 知识点解读_vue rabbitmq
- 4HarmonyOS4-ArkUI组件动画_arkui 小球动画
- 5mac 建立软链接_macOS 上添加链接位置,mac上创建和使用符号链接(又名Symlinks)...
- 6【前端工程化指南】Git常见操作之保存更改相关操作
- 7对已有的docker容器增加新的端口映射_docker 容器添加端口映射
- 8数据结构与算法(十一)-图(Graph)_图结构
- 9亚马逊云科技官方重磅发布GenAI应用开发学习路线(全免费)_aws gen ai
- 10前沿科技应用:AIGC技术的广泛渗透
Spark和Hadoop的安装
赞
踩
实验内容和要求
1.安装Hadoop和Spark
进入Linux系统,完成Hadoop伪分布式模式的安装。完成Hadoop的安装以后,再安装Spark(Local模式)。
2.HDFS常用操作
使用hadoop用户名登录进入Linux系统,启动Hadoop,参照相关Hadoop书籍或网络资料,或者也可以参考本教程官网的“实验指南”栏目的“HDFS操作常用Shell命令”,使用Hadoop提供的Shell命令完成如下操作:
(1)启动Hadoop,在HDFS中创建用户目录“/user/hadoop”;
(2)在Linux系统的本地文件系统的“/home/hadoop”目录下新建一个文本文件test.txt,并在该文件中随便输入一些内容,然后上传到HDFS的“/user/hadoop”目录下;
(3)把HDFS中“/user/hadoop”目录下的test.txt文件,下载到Linux系统的本地文件系统中的“/home/hadoop/下载”目录下;
(4)将HDFS中“/user/hadoop”目录下的test.txt文件的内容输出到终端中进行显示;
(5)在HDFS中的“/user/hadoop”目录下,创建子目录input,把HDFS中“/user/hadoop”目录下的test.txt文件,复制到“/user/hadoop/input”目录下;
(6)删除HDFS中“/user/hadoop”目录下的test.txt文件,删除HDFS中“/user/hadoop”目录下的input子目录及其子目录下的所有内容。
3. Spark读取文件系统的数据
(1)在spark-shell中读取Linux系统本地文件“/home/hadoop/test.txt”,然后统计出文件的行数;
(2)在spark-shell中读取HDFS系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;
(3)编写独立应用程序,读取HDFS系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;通过sbt工具将整个应用程序编译打包成 JAR包,并将生成的JAR包通过 spark-submit 提交到 Spark 中运行命令。
实验环境
VMware 16.1.2 build-17966106
ubuntu-22.04.4-desktop-amd64.iso
Java 11
scala-2.13.13.tgz
hadoop-3.3.6.tar.gz
spark-3.5.1-bin-hadoop3-scala2.13.tgz
sbt-1.9.9.tgz
安装JDK
安装Java
- sudo apt update
- sudo apt upgrade
- sudo apt-get install openjdk-11-jre openjdk-11-jdk
配置环境变量
vim ~/.bashrcexport JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
让路径生效
source ~/.bashrc验证是否成功

安装Scala
下载解压
Scala 2.13.13 | The Scala Programming Language![]() https://www.scala-lang.org/download/2.13.13.html确保文件的路径是~/下载/scala-2.13.13.tgz
https://www.scala-lang.org/download/2.13.13.html确保文件的路径是~/下载/scala-2.13.13.tgz
将文件解压到/usr/local下并且更名为scala
- sudo tar -zxf ~/下载/scala-2.13.13.tgz -C /usr/local
- cd /usr/local/
- sudo mv ./scala-2.13.13 ./scala
配置
让普通用户拥有对scala目录的权限
sudo chown -R hadoop ./scala 配置环境变量
vim ~/.bashrcexport PATH=$PATH:/usr/local/scala/bin
source ~/.bashrc验证是否成功

安装ssh
安装
sudo apt install openssh-server登录
ssh localhost切换到root用户
su –修改sshd_config
vim /etc/ssh/sshd_config添加 PasswordAuthentication yes
配置免密登录
- exit
- cd ~/.ssh/
- cat ./id_rsa.pub >> ./authorized_keys
- ssh-keygen -t rsa
一直回车即可
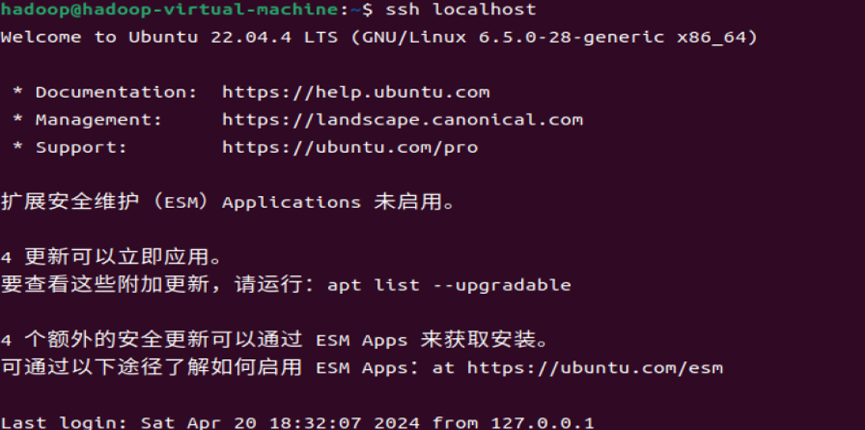
安装hadoop
下载解压
- sudo tar -zxf ~/下载/hadoop-3.3.6.tar.gz -C /usr/local
- cd /usr/local/
- sudo mv ./hadoop-3.3.6/ ./hadoop
配置
sudo chown -R hadoop ./hadoop # 修改文件权限添加hadoop环境变量
vim ~/.bashrcexport HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
修改hadoop-env.sh与yarn-env.sh文件
- cd /usr/local/hadoop/etc/hadoop
- vim hadoop-env.sh
- vim yarn-env.sh
在最后添加
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
修改core-site.xml 和 hdfs-site.xml
- cd /usr/local/hadoop/etc/hadoop/
- vim core-site.xml
将<configuration>内容修改如下:
- <configuration>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>file:/usr/local/hadoop/tmp</value>
- <description>Abase for other temporary directories.</description>
- </property>
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://localhost:9000</value>
- </property>
- <property>
- <name>hadoop.http.staticuser.user</name> #解决web端无法删除上传文件
- <value>hadoop</value>
- </property>
- </configuration>
vim hdfs-site.xml将<configuration>内容修改如下:
- <configuration>
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- <property>
- <name>dfs.namenode.name.dir</name>
- <value>file:/usr/local/hadoop/tmp/dfs/name</value>
- </property>
- <property>
- <name>dfs.datanode.data.dir</name>
- <value>file:/usr/local/hadoop/tmp/dfs/data</value>
- </property>
- </configuration>
格式化NameNode (仅需要执行一次即可,之后不需要执行)
- cd /usr/local/hadoop
- ./bin/hdfs namenode -format
开启 NameNode 和 DataNode 守护进程
- cd /usr/local/hadoop
- ./sbin/start-dfs.sh
配置YARN
修改 mapred-site.xml文件
- cd /usr/local/hadoop/etc/hadoop
- vim mapred-site.xml
将<configuration>内容修改如下:
- <configuration>
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- </configuration>
修改vim yarn-site.xml文件
vim vim yarn-site.xml将<configuration>内容修改如下:
- <configuration>
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- <property>
- <name>yarn.resourcemanager.hostname</name>
- <value>localhost</value>
- </property>
- </configuration>
修改start-yarn.sh和stop-yarn.sh
- cd ./sbin
- vim start-yarn.sh
- vim stop-yarn.sh
在文件中加入以下三行:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
启动YARN
- cd /usr/local/hadoop
- ./sbin/start-yarn.sh
开启历史服务器
- cd /usr/local/hadoop
- ./bin/mapred --daemon start historyserver
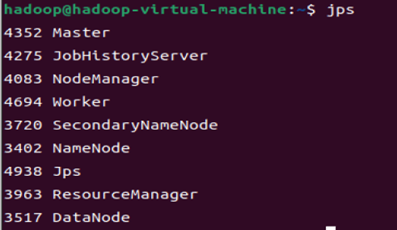
localhost![]() http://localhost:9870/
http://localhost:9870/
安装Spark
下载 |Apache Spark![]() https://spark.apache.org/downloads.html
https://spark.apache.org/downloads.html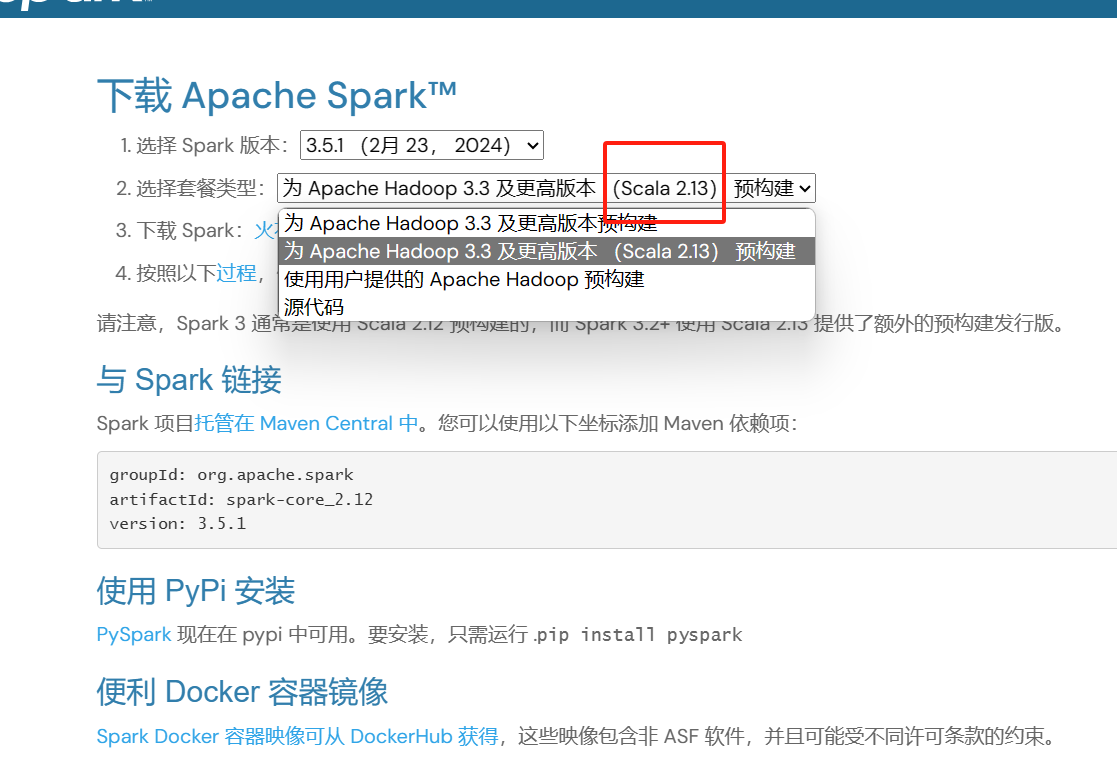
- sudo tar -zxf ./spark-3.5.1-bin-hadoop3-scala2.13.tgz -C /usr/local
- cd /usr/local
- sudo mv spark-3.5.1-bin-hadoop3-scala2.13/ spark
配置
sudo chown -R hadoop:hadoop spark # 此处的 hadoop 为你的用户名修改spark-env.sh
- cd /usr/local/spark
- cp ./conf/spark-env.sh.template ./conf/spark-env.sh
- vim ./conf/spark-env.sh
在第一行下面添加以下配置信息
- export SPARK_MASTER_PORT=7077
- export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
- export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
- export SPARK_MASTER_IP=localhost
- export SPARK_LOCAL_IP=localhost
启动spark
- cd /usr/local/spark
- ./sbin/start-all.sh
测试spark
- cd /usr/local/spark
- bin/run-example SparkPi 2>&1 |grep "Pi is"

启动shell
- cd /usr/local/spark
- bin/spark-shell
安装sbt
下载解压
下载 |SBT公司 (scala-sbt.org)![]() https://www.scala-sbt.org/download/
https://www.scala-sbt.org/download/
- sudo tar -zxvf ./sbt-1.9.9.tgz -C /usr/local
- cd /usr/local/sbt
下面慢可以用这个
- echo "deb https://repo.scala-sbt.org/scalasbt/debian all main" | sudo tee /etc/apt/sources.list.d/sbt.list
- echo "deb https://repo.scala-sbt.org/scalasbt/debian /" | sudo tee /etc/apt/sources.list.d/sbt_old.list
- curl -sL "https://keyserver.ubuntu.com/pks/lookup?op=get&search=0x2EE0EA64E40A89B84B2DF73499E82A75642AC823" | sudo apt-key add
- sudo apt-get update
- sudo apt-get install sbt
配置
- sudo chown -R hadoop /usr/local/sbt
- cd /usr/local/sbt
- cp ./bin/sbt-launch.jar ./
- vim /usr/local/sbt/sbt
内容如下:
- #!/bin/bash
- SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M"
- java $SBT_OPTS -jar `dirname $0`/sbt-launch.jar "$@"
chmod u+x /usr/local/sbt/sbt启动sbt
- cd /usr/local/sbt
- ./sbt sbtVersion
新建项目
- sudo mkdir -p /example/sparkapp/src/main/scala
- cd /example/sparkapp/src/main/scala
- sudo touch SimpleApp.scala
- sudo vim SimpleApp.scala
内容如下:
- /* SimpleApp.scala */
- import org.apache.spark.SparkContext
- import org.apache.spark.SparkContext._
- import org.apache.spark.SparkConf
-
- object SimpleApp {
- def main(args: Array[String]) {
- val logFile = "file:///usr/local/spark/README.md" // Should be some file on your system
- val conf = new SparkConf().setAppName("Simple Application")
- val sc = new SparkContext(conf)
- val logData = sc.textFile(logFile, 2).cache()
- val numAs = logData.filter(line => line.contains("a")).count()
- val numBs = logData.filter(line => line.contains("b")).count()
- println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
- }
- }

创建.sbt文件
- cd /example/sparkapp
- sudo touch build.sbt
- sudo vim build.sbt
- name := "Simple Project"
- version := "1.0"
- scalaVersion := "2.13.13"
- libraryDependencies += "org.apache.spark" %% "spark-core" % "3.5.1"
打包
/usr/local/sbt/sbt package如果出现无法创建文件的错误,需要在前面加一个sudo.或者整个在root用户下面安装配置。
[error] [launcher] error during sbt launcher: java.io.IOException: Could not create directory /sparkapp/target/global-logging: java.nio.file.AccessDeniedException: /sparkapp/target执行
- cd /example/sparkapp
- spark-submit --class "SimpleApp" ./target/scala-2.13/simple-project_2.13-1.0.jar 2>&1 | grep "Lines"

安装Maven
安装
apt install maven新建测试项目
- midir -p /example/sparkapp2/src/main/scala
- cd /example/sparkapp2/src/main/scala
- sudo touch SimpleApp.scala
- sudo vim SimpleApp.scala
- /* SimpleApp.scala */
- import org.apache.spark.SparkContext
- import org.apache.spark.SparkContext._
- import org.apache.spark.SparkConf
-
- object SimpleApp {
- def main(args: Array[String]) {
- val logFile = "file:///usr/local/spark/README.md" // Should be some file on your system
- val conf = new SparkConf().setAppName("Simple Application")
- val sc = new SparkContext(conf)
- val logData = sc.textFile(logFile, 2).cache()
- val numAs = logData.filter(line => line.contains("a")).count()
- val numBs = logData.filter(line => line.contains("b")).count()
- println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
- }
- }
创建pom.xml文件
- cd /example/sparkapp2
- sudo touch pom.xml
- sudo vim pom.xml
- <project>
- <groupId>shuda.hunnu</groupId>
- <artifactId>simple-project</artifactId>
- <modelVersion>4.0.0</modelVersion>
- <name>Simple Project</name>
- <packaging>jar</packaging>
- <version>1.0</version>
- <repositories>
- <repository>
- <id>jboss</id>
- <name>JBoss Repository</name>
- <url>http://repository.jboss.com/maven2/</url>
- </repository>
- </repositories>
- <dependencies>
- <dependency> <!-- Spark dependency -->
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-core_2.13</artifactId>
- <version>3.5.1</version>
- </dependency>
- </dependencies>
-
- <build>
- <sourceDirectory>src/main/scala</sourceDirectory>
- <plugins>
- <plugin>
- <groupId>org.scala-tools</groupId>
- <artifactId>maven-scala-plugin</artifactId>
- <executions>
- <execution>
- <goals>
- <goal>compile</goal>
- </goals>
- </execution>
- </executions>
- <configuration>
- <scalaVersion>2.13.13</scalaVersion>
- <args>
- <arg>-target:jvm-11</arg>
- </args>
- </configuration>
- </plugin>
- </plugins>
- </build>
- </project>
修改setting.xml文件
- sudo vim /usr/share/maven/conf/settings.xml
- sudo vim /etc/maven/settings.xml
需要把文件中原本mirror标题的地方给取消注释,然后添加如下内容:
- <mirror>
- <id>alimaven</id>
- <name>aliyun maven</name>
- <url>
- http://maven.aliyun.com/nexus/content/groups/public/</url>
- <mirrorOf>central</mirrorOf>
- </mirror>
如果标签缺失就会出现如下报错(双标签变成单标签)
- [ERROR] Error executing Maven.
- [ERROR] 1 problem was encountered while building the effective settings
- [FATAL] Non-parseable settings /usr/share/maven/conf/settings.xml: end tag name </settings> must match start tag name <mirrors> from line 146 (position: TEXT seen ...</activeProfiles>\n -->\n</settings>... @261:12) @ /usr/share/maven/conf/settings.xml, line 261, column 12
打包执行
.jar文件的路径可能会发生改变。
- sudo /usr/share/maven/bin/mvn package
- spark-submit --class "SimpleApp" ./target/simple-project-1.0.jar 2>&1 | grep "Lines"

启动Hadoop,在HDFS中创建用户目录“/user/hadoop”
- cd /usr/local/hadoop
- ./sbin/start-dfs.sh #启动HDFS
- ./sbin/start-yarn.sh #启动YARN
- hadoop fs -mkdir -p /user/Hadoop #创建用户目录/user/hadoop
- hadoop fs -ls /user #检查目录是否创建成功

在Linux系统的本地文件系统的“/home/hadoop”目录下新建一个文本文件test.txt,并在该文件中随便输入一些内容,然后上传到HDFS的“/user/hadoop”目录下
- sudo vim test.txt
- hadoop fs -put test.txt /user/hadoop
不能重复上传put: `/user/hadoop/test.txt': File exists
把HDFS中“/user/hadoop”目录下的test.txt文件,下载到Linux系统的本地文件系统中的“/home/hadoop/下载”目录下
- sudo rm test.txt #先将原始位置上面的test.txt删除
- hadoop fs -get /user/hadoop/test.txt /home/hadoop/

将HDFS中“/user/hadoop”目录下的test.txt文件的内容输出到终端中进行显示
hadoop fs -cat /user/hadoop/test.txt在HDFS中的“/user/hadoop”目录下,创建子目录input,把HDFS中“/user/hadoop”目录下的test.txt文件,复制到“/user/hadoop/input”目录下
hadoop fs -mkdir -p /user/hadoop/input


删除HDFS中“/user/hadoop”目录下的test.txt文件,删除HDFS中“/user/hadoop”目录下的input子目录及其子目录下的所有内容
hadoop fs -rm /user/hadoop/test.txt
hadoop fs -rm -r /user/hadoop/input #用hdfs dfs 替代hadoop fs也行

这里删除目录是用-r,不能用-rf。-rm: Illegal option -rf
在spark-shell中读取Linux系统本地文件“/home/hadoop/test.txt”,然后统计出文件的行数
- cd /usr/local/spark
- ./sbin/start-all.sh
- bin/spark-shell #启动spark-shell
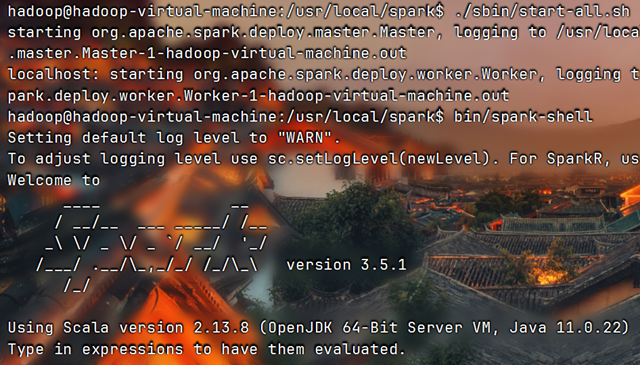
- val fileData=sc.textFile("file:/home/hadoop/test.txt")
- val count=fileData.count()

在spark-shell中读取HDFS系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数
- val fileData=sc.textFile("/user/hadoop/test.txt")
- val count=fileData.count()

不写file,默认是hdfs
- val fileData=sc.textFile("hdfs:/user/hadoop/test.txt")
- val count=fileData.count()

编写独立应用程序,读取HDFS系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;通过sbt工具将整个应用程序编译打包成 JAR包,并将生成的JAR包通过 spark-submit 提交到 Spark 中运行命令
创建项目
- sudo mkdir -p /example/sparkapp3/src/main/scala
- cd /example/sparkapp3/src/main/scala
- sudo touch SimpleApp.scala
- sudo vim SimpleApp.scala
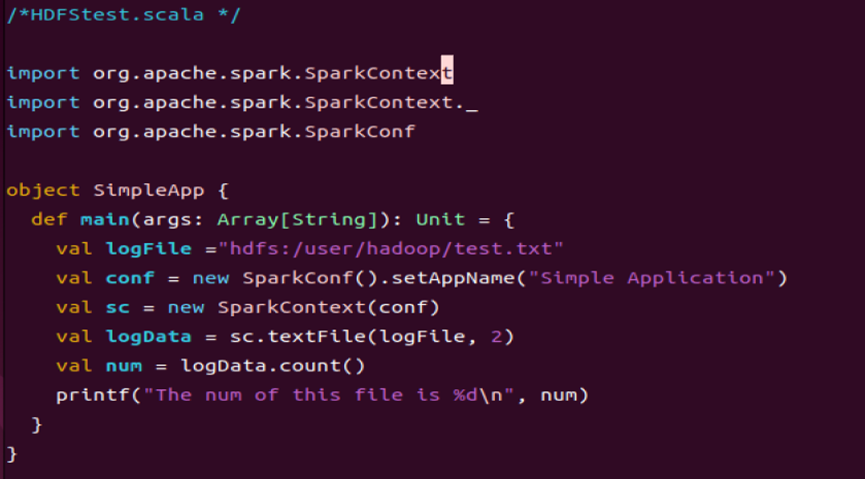
- /*HDFStest.scala */
-
- import org.apache.spark.SparkContext
- import org.apache.spark.SparkContext._
- import org.apache.spark.SparkConf
-
- object SimpleApp {
- def main(args: Array[String]): Unit = {
- val logFile ="hdfs:/user/hadoop/test.txt"
- val conf = new SparkConf().setAppName("Simple Application")
- val sc = new SparkContext(conf)
- val logData = sc.textFile(logFile, 2)
- val num = logData.count()
- printf("The num of this file is %d\n", num)
- }
- }
创建.sbt文件
- cd /example/sparkapp3
- sudo touch build.sbt
- sudo vim build.sbt
- name := "Simple Project"
- version := "1.0"
- scalaVersion := "2.13.13"
- libraryDependencies += "org.apache.spark" %% "spark-core" % "3.5.1"
打包执行
这个--class,应该是需要和类名保持一致的,为了方便,我把类名还是改成了SimpleApp.
- /usr/local/sbt/sbt package
- spark-submit --class " SimpleApp " ./target/scala-2.13/simple-project_2.13-1.0.jar 2>&1 | grep "num"
如果这个是直接抄网上的话,有的路径不对(这个路径最好与前面保持一致,网上的就是端口,两种方法的路径都不一样,简直是误人子弟),我也不知道他们是怎么运行出来的,就很无语,而且都是给图片。

总结
在HDFS中使用命令和本地差不多,但是还是有点小区别,前面是用hadoop fs -,或者hdfs dfs -,然后命令的参数可能发生了变化,编写scala程序还是有点小问题,主要卡的最久的就是在网上看了一个觉得可以运行出来,结果一直显示路径错误了,结果仔细一看,放的位置都不一样,服了。
需要在.bashrc中粘贴这些语句。
- export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
- export PATH=$PATH:/usr/local/scala/bin
- export HADOOP_HOME=/usr/local/hadoop
- export PATH=$PATH:$HADOOP_HOME/bin
- export PATH=$PATH:$HADOOP_HOME/sbin
- export SPARK_HOME=/usr/local/spark
- export PATH=$PATH:$SPARK_HOME/bin
- export PATH=$PATH:$SPARK_HOME/sbin
- export LD_LIBRARY_PATH=/usr/local/hadoop/lib/native
- export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
- export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"

