- 1Jdk1.6新特性_jdk1.6的新特性
- 2tokenizer.encode()
- 3mysql 数据泵导入导出_使用数据泵导入(impdp)和导出(expdp)
- 4AI Agent在自动化领域产生影响,自主智能体引领超自动化领域的新潮流_智能体:ai agent拉开超自动化智能体时代帷幕
- 5摇杆(magnitude)_deltaposition.magnitude
- 6【小米电脑管家】安装使用教程--非小米电脑_小米电脑管家最新csdn
- 7时间复杂度和空间复杂度计算_时间复杂度和空间复杂度怎么算
- 8JS 删除数组元素( 5种方法 )_js数组批量删除元素
- 9uniapp滚动选择器 picker
- 10最新abogus算法还原之传参加密_抖音abogus逆向
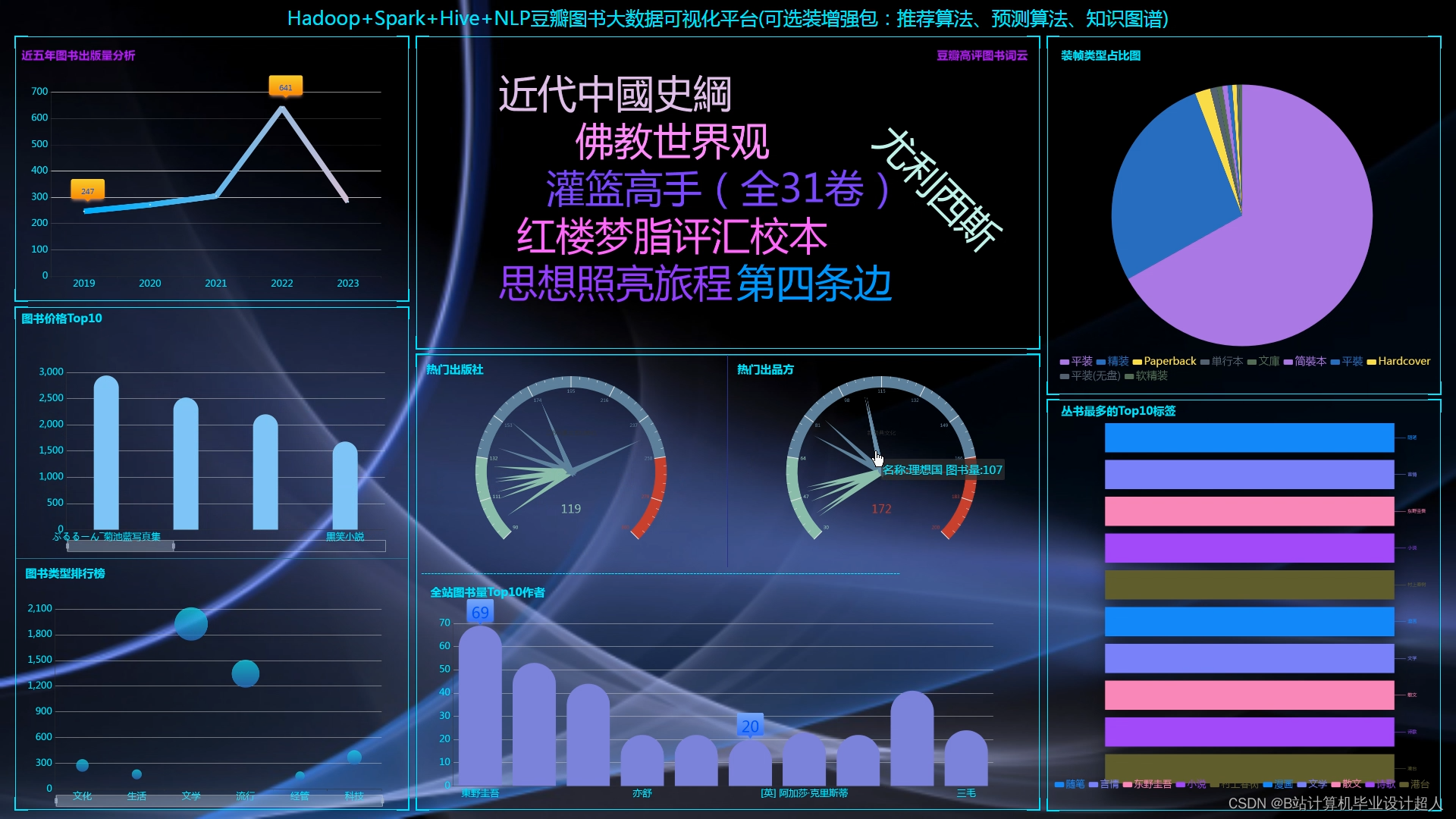
大数据毕业设计hadoop+spark+hive豆瓣图书数据分析可视化大屏 豆瓣图书爬虫 图书推荐系统
赞
踩
系统总体目标
基于Spark的个性化书籍推荐系统是一种基于大数据技术的智能推荐系统,它可以根据用户的历史行为和偏好,为用户提供个性化的书籍推荐。该系统采用Spark技术,可以实现大数据的实时处理,从而提高推荐系统的准确性和可靠性。此外,该系统还可以根据用户的习惯和偏好,提供更加个性化的书籍推荐,从而满足用户的需求。
系统的使用者包含普通用户和管理员两类,普通用户是系统的主要服务对象,主流人群是经常查看书籍的互联网用户,这一类中以喜欢浏览书籍的年轻人群为主,同时也包括一部分其他年龄段的书籍爱好者;管理员是系统后台的管理者,负责管理书籍信息和用户信息,并在推荐和分类出现偏差时予以校正。
2)系统可行性分析
技术可行性:本系统采用Spark技术实现。Spark 是一种与 Hadoop 相似的开源集群计算环境,但 Spark 在部分工作负载方面表现得更加优越,更适合中小型系统,从使用场景和运算速度上说spark更适合本系统。Spark可以实现实时处理大量数据,提高推荐系统的准确性和可靠性,同时也可以支持多种推荐算法,如基于内容的推荐、基于协同过滤的推荐等,从而实现个性化的书籍推荐。
系统可行性:本系统采用Mysql数据库存储用户数据,使用SQL语句进行调用和分析,节约了大数据背景下对数据的提取的工作时间,提高了对书籍数据推荐工作的运转效率,有效地提高系统的运行速度,同时也可以满足用户的需求。
经济可行性:本系统采用开源技术,Mysql和Spark都是当今大数据技术方面比较主流的,开发和运营成本较低,同时能提高系统的可靠性和稳定性。
社会可行性:本系统可以满足用户对书籍的需求,提供个性化的书籍推荐,从而提高用户的阅读体验,同时也可以提高用户的阅读兴趣,促进社会文化的发展。
综上所述,本系统的技术方案具有较高的可行性,可以有效地满足用户的需求,促进社会文化的发展,无论从系统技术角度、经济运营角度还是社会文化角度都能迎合当今的形势和诉求。
3)系统需求分析
本系统的主要使用场景是:普通浏览查询书籍,并根据用户的浏览查询信息推荐用户可能喜欢的其他书籍;管理员用户在需要时,可以对系统进行管理,如修改和删除错误信息等。基于这个使用场景可以得到系统的基本需求如下:
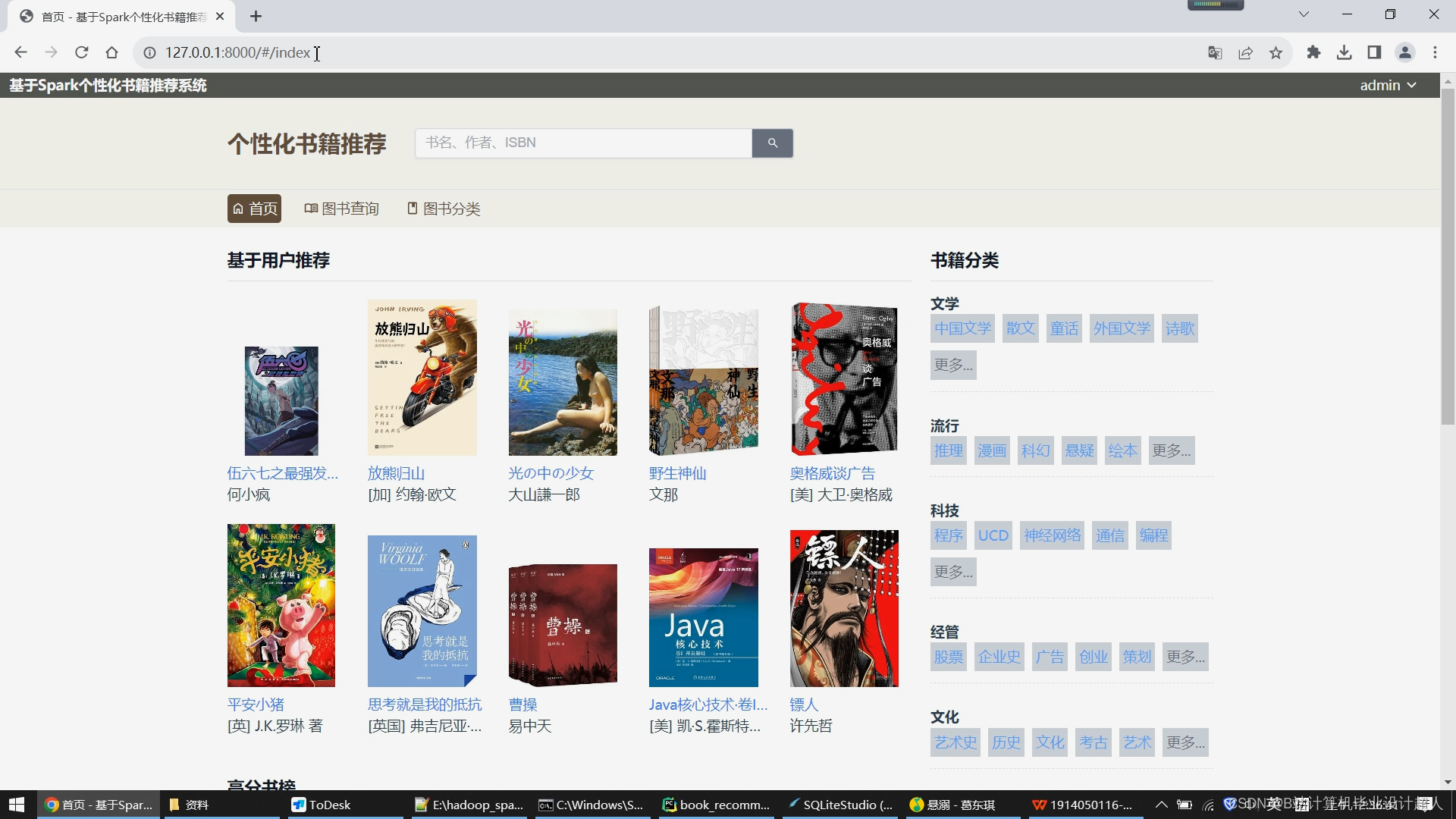
用户的浏览需求:用户需要可以查看指定的书籍,网站需要为用户展示对应的书籍名称、作者等基本信息。同时用户的行为数据将被系统后台记录,作为分析用户喜好的依据,进而为用户推荐可能喜欢的其他书籍;
用户的推荐需求:这是本系统的核心。从上述浏览过程中产生的访问行为将经过后台分析,从而得出针对不同用户的个性化定制推荐列表,帮助用户找到其他相似的可能感兴趣的书。
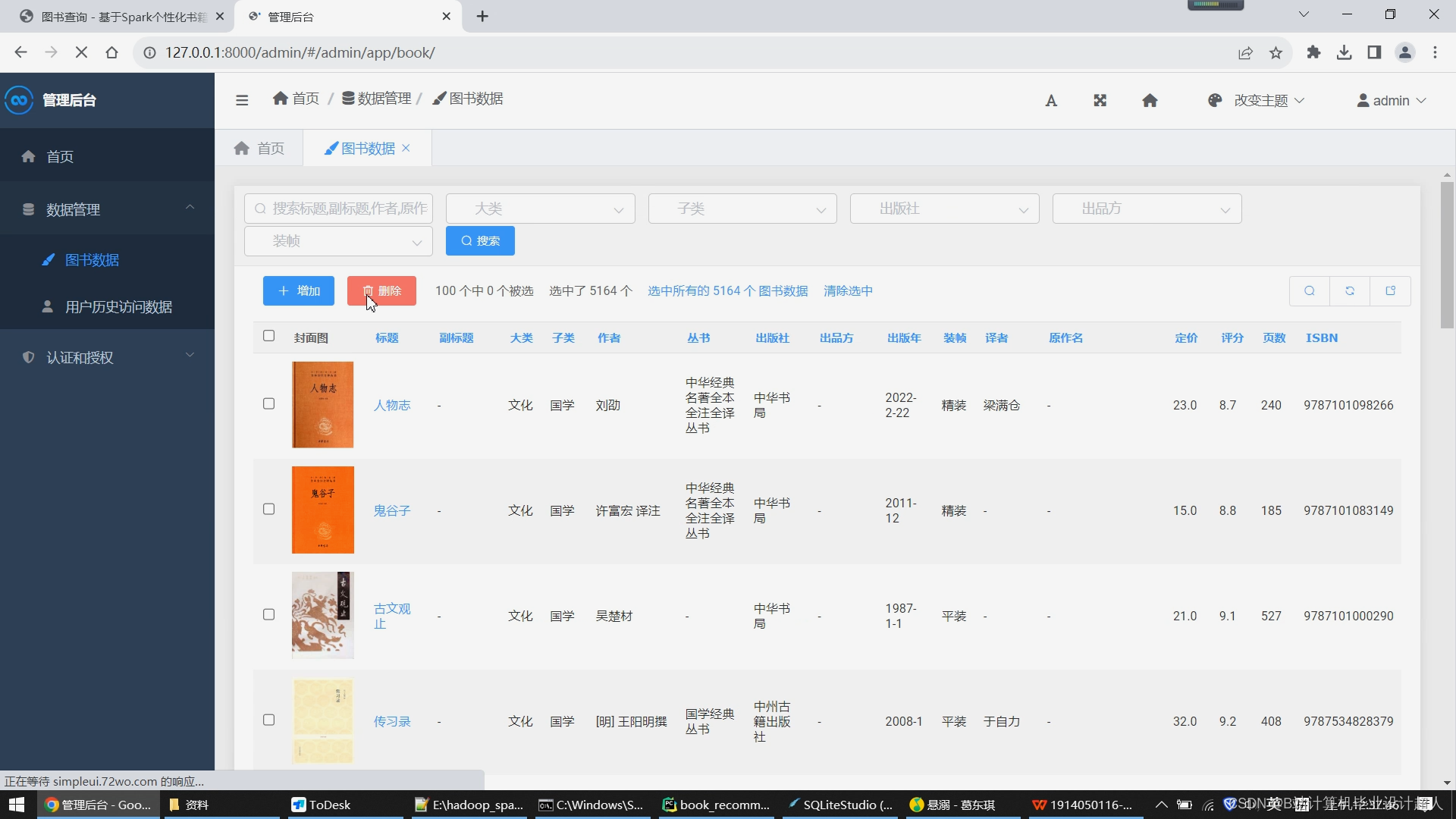
后台管理需求:系统需要设置管理员,给运行留下一些容错,遇到系统本身无法处理的问题或者误区时,需要有管理员人工介入修正,因此系统除了面向普通用户的部分以外,还要有单独的管理员界面。