
- 1【计算机毕业设计】java基于springboot+vue的外卖点餐系统_饿了么商家管理功能,菜品管理功能java
- 2OpenCV学习笔记
- 3vscode 常用插件_vscode compare folder插件
- 4SQLite--SQLite的基本介绍和安装
- 540亿次仿真学习:人工智能5:0大胜人类飞行员_人工智能 训练飞行员
- 6接入飞书的 ChatGPT 对话机器人,SAM 来了
- 7【漏洞复现】Hikvision摄像头产品代码执行漏洞(CVE-2021-36260)
- 8async await 面试题_async function async1(){ console.log(1); await asy
- 9Oracle权限详解_oracle comment权限
- 10Dapr中国社区活动之 分布式运行时开发者日 (2022.09.03)
大数据手册(Spark)--Spark Core and RDDs_spark查询的概念
赞
踩
启动 Spark
SparkContext
Spark程序必须做的第一件事是创建一个SparkContext对象,该对象告诉Spark如何访问集群。要创建SparkContext,需要先构建一个包含应用程序信息的SparkConf对象。
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster('yarn').setAppName('myApp')
sc = SparkContext(conf=conf)
- 1
- 2
- 3
- 4
| pyspark.SparkConf | SparkConf 配置 |
|---|---|
SparkConf.setAppName(value) | 应用程序在集群UI上显示的名称 |
SparkConf.setMaster(value) | 配置spark资源管理器 |
SparkConf.contains(key) | Conf中是否包含一个指定配置 |
SparkConf.get(key, defaultValue=None) | 获取配置的某些键值 |
SparkConf.getAll() | 得到所有的键值对 |
SparkConf.set(key, value) | 设置配置属性 |
参数master是Spark、Mesos或YARN集群URL,或者使用字符串 “local”启用本地模式。
- local:采用单线程运行spark,常用于本地开发测
- local[n]:使用n线程运行spark
- local[*]:使用逻辑CPU个数的线程运行
- standalone:利用Spark自带的资源管理与调度器运行Spark集群,采用Master/Slave结构
- yarn : 集群运行在Yarn资源管理器上,资源管理交给Yarn,Spark只负责进行任务调度和计算
一旦SparkConf对象被传递给SparkContext,它就不能被修改。
| pyspark.SparkContext | 获取 SparkContext 信息 |
|---|---|
SparkContext.version | 获取 Spark 版本 |
SparkContext.pythonVer | 获取 Python 版本 |
SparkContext.master | 要连接的 Master URL |
SparkContext.sparkHome | Spark 在工作节点的安装路径 |
SparkContext.sparkUser() | 获取 SparkContext 的 Spark 用户名 |
SparkContext.appName | 返回应用名称 |
SparkContext.applicationId | 获取应用程序ID |
SparkContext.defaultParallelism | 返回默认并行级别 |
SparkContext.defaultMinPartitions | RDD默认最小分区数 |
sparkContext.setLogLevel(logLevel) | 控制日志级别。有效级别:ALL、DEBUG、ERROR、FATAL、INFO、OFF、TRACE、WARN |
SparkContext.range() | 创建一个序列 |
SparkContext.stop() | 终止SparkContext |
每个JVM只能激活一个SparkContext。在创建新SparkContext之前,必须终止活动的SparkContext。
PySpark Shell
若要在 Python 解释器中以交互方式运行 Spark,请使用bin/pyspark。例如:
pyspark --master local[2]
- 1
或者,还要将myTools.py 添加到搜索路径中(以便以后能够import myTools),请使用:
./bin/pyspark --master local[2] --py-files myTools.py
- 1
有关选项的完整列表,请运行pyspark --help。
PySpark会选择PATH中默认的python版本启动,可以通过指定PYSPARK_PYTHON选择Python版本,例如:
PYSPARK_PYTHON=python3.8 bin/pyspark
- 1
在运行bin/pyspark时,还可以通过设置PYSPARK_DRIVER_PYTHON变量来选择驱动程序。
若要使用IPython:
PYSPARK_DRIVER_PYTHON=ipython ./bin/pyspark
- 1
若要使用 Jupyter Notebook:
PYSPARK_DRIVER_PYTHON=jupyter
- 1
可以通过设置PYSPARK_DRIVER_PYTHON_OPTS来自定义ipython或jupyter命令。
PYSPARK_DRIVER_PYTHON_OPTS=notebook ./bin/pyspark
- 1
在使用 bin/pyspark命令打开Spark交互式环境后,默认情况下,Spark 已经创建了名为 sc 的 SparkContext 变量,因此创建新的环境变量将不起作用。
但是,在提交的独立spark 应用程序中或者常规的python环境,需要自行创建SparkContext 对象连接集群。
独立应用程序
用户编写完Spark应用程序之后,需要使用 spark-submit 命令将应用程序提交到集群中运行:
spark-submit --master "local[2]" examples/src/main/python/pi.py
- 1
但是,提交的Python独立程序内必须自行创建SparkContext 对象连接集群,例如
from pyspark import SparkContext, SparkConf
conf = SparkConf().setMaster('local').setAppName('myApp')
sc = SparkContext(conf=conf)
- 1
- 2
- 3
- 4
Spark运行基本流程
Spark应用程序的执行流程如下:
- 创建SparkContext对象,然后SparkContext会向Clutser Manager(例如Yarn、Standalone、Mesos等)申请资源
- 资源管理器在worker node上创建executor并分配资源(CPU、内存等)
- SparkContext启动DAGScheduler,将提交的作业(Job)转换成若干Stage,各Stage构成DAG(Directed Acyclic Graph有向无环图),各个Stage包含若干相关 task,这些task的集合被称为TaskSet
- TaskSet发送给TaskSet Scheduler,TaskSet Scheduler将Task发送给对应的Executor,同时SparkContext将应用程序代码发送到Executor,从而启动任务的执行
- Executor执行Task,完成后释放相应的资源。
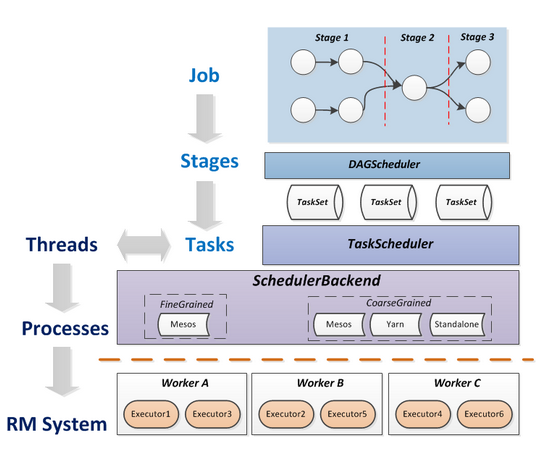
- Job:一个Job包含多个RDD及作用于相应RDD上的各种操作构成的DAG图。
- Stages:是Job的基本调度单位(DAGScheduler),一个Job会分解为多组Stage,每组Stage包含多组任务(Task),称为TaskSet,代表一组关联的,相互之间没有Shuffle依赖关系(最耗费资源)的任务组成的任务集。
- Tasks:负责Stage的任务分发(TaskScheduler),Task分发遵循基本原则:计算向数据靠拢,避免不必要的磁盘I/O开销。
Spark通过分析各个RDD的依赖关系生成有向无环图DAG(Directed Acyclic Graph),通过分析各个RDD中的分区之间的依赖关系来决定如何划分Stage进行任务优化。
RDD
弹性分布式数据集(RDD, Resilient Distributed Dataset)是Spark框架中的核心概念,它们是在多个节点上运行和操作以在集群上进行并行处理的元素。
请注意,在 Spark 2.0 之前,Spark 的主要编程接口是弹性分布式数据集 (RDD)。在 Spark 2.0 之后,RDD 被 Dataset 取代,后者具有与 RDD 类似的强类型,但在后台进行了更丰富的优化。
创建RDD
通过调用SparkContext.parallelize方法来创建一个可以并行操作的分布式数据集。例如:
# Parallelized Collections
distData = sc.parallelize([1, 2, 3, 4, 5])
pairRDD = sc.parallelize([('a', 7),('a', 2),('b', 2)])
emptyRDD = sc.emptyRDD()
- 1
- 2
- 3
- 4
创建后,分布式数据集可以并行操作。例如,我们可以调用dist_data.reduce(lambda a, b: a + b)来添加列表的元素。
并行集合的一个重要参数是分区,Spark将为集群的每个分区运行一个Task。通常,Spark会尝试根据您的集群自动设置分区数量,一般每个CPU 2-4个分区。但是,您也可以通过``parallelize`的第二个参数进行手动设置分区数量。
外部数据源
PySpark可以从Hadoop支持的任何存储源创建分布式数据集,包括本地文件系统、HDFS、Cassandra、HBase、Amazon S3等。
| pyspark | |
|---|---|
SparkContext.textFile(path, minPartitions) | 读取文本文件 |
RDD.saveAsTextFile(path) | 保存为文本文件 |
SparkContext.wholeTextFiles(path, minPartitions) | 读取文本文件目录 |
SparkContext.sequenceFile(path, keyClass, valueClass) | 读取具有 key-value 的Hadoop SequenceFile |
RDD.saveAsSequenceFile(path) | Python RDD[(K,V)] 输出到Hadoop文件系统 |
SparkContext.pickleFile(path, minPartitions) | 加载之前使用RDD.saveAsPickleFile()方法保存的RDD |
RDD.saveAsPickleFile(path, batchSize) | 保存为序列文件 |
SparkContext.hadoopFile(path, inputFormatClass, keyClass, valueClass) | 读取具有任意key-value类的 ‘old’ Hadoop InputFormat |
RDD.saveAsHadoopFile(path, outputFormatClass) | 使用 ‘old’ Hadoop OutputFormat API将RDD[(K, V)] 输出到Hadoop文件系统 |
SparkContext.newAPIHadoopFile(path, inputFormatClass, keyClass, valueClass) | 读取具有任意key-value类的 ‘new API’ Hadoop InputFormat |
RDD.saveAsNewAPIHadoopFile(path, outputFormatClass) | 使用 ‘old’ Hadoop OutputFormat API将RDD[(K, V)] 输出到Hadoop文件系统 |
以下是一个文本文件 I/O 示例:
# External Datasets
rdd = sc.textFile("path/to/file") # Hadoop path
rdd = sc.textFile("hdfs://path/to/file") # Hadoop path
rdd = sc.textFile("file:///path/to/file") # local path
rdd.saveAsTextFile("path/to/file")
- 1
- 2
- 3
- 4
- 5
- 6
关于使用Spark读取文件的一些注意事项:
- 如果在本地文件系统上使用路径,该文件也必须在worker node的相同路径上。要么将文件复制到所有worker,要么使用网络挂载的共享文件系统。
- Spark的所有基于文件的读取方法,都支持使用目录、压缩文件和通配符路径。例如,您可以使用
SparkContext.textFile("/my/directory"), SparkContext.textFile("/my/directory/*.txt")和SparkContext.textFile("/my/directory/*.gz") textFile和pickleFile方法还可使用第二个参数来控制文件的分区数。默认情况下,Spark为文件的每个块创建一个分区(在HDFS中默认为128MB),但您也可以通过传递更大的值来请求更多数量的分区。请注意,您的分区不能少于块。SparkContext.wholeTextFiles允许您读取包含多个小文本文件的目录,并将每个文件作为(filename, content)对返回。RDD.saveAsPickleFile和SparkContext.pickleFile支持以由pickled Python对象组成的简单格式保存RDD。batchSize用于pickle序列化,默认batchSize大小为10。
变换和行动
在Spark里,对数据的所有操作,基本上就是围绕RDD来的。RDD支持两种类型的操作:变换(Transformation)和行动(Action)。
- Transformation是惰性的,因为它们不立即执行。RDD的转换操作会生成新的RDD,新的RDD的数据依赖于原来的RDD的数据,每个RDD又包含多个分区。那么一段程序实际上就构造了一个由相互依赖的多个RDD组成的有向无环图(DAG)。
- 当我们的程序里面遇到一个Action算子的时候,代码才会将这个有向无环图作为一个Job提交给Spark真正执行,这种设计让Spark更加有效率地运行。Spark代码里面至少需要有一个Action算子。
Transformation 延迟执行会产生更多精细查询:DAGScheduler可以在查询中执行优化,包括能够避免shuffle数据。
例如,map是一种Transformation,它将函数传递给每个元素,并返回一个表示结果的新RDD。另一方面,reduce是一个Action,它使用函数聚合RDD的所有元素,并将最终结果返回。
lines = sc.textFile("data.txt")
lineLengths = lines.map(lambda s: len(s))
totalLength = lineLengths.reduce(lambda a, b: a + b)
- 1
- 2
- 3
默认情况下,每次对它运行Action时,每个变换后的RDD都可能会被重新计算。但是,可以使用persist或cache方法在内存中持久化RDD,这时,在首次计算后,Spark会将元素保留在集群上,以便下次查询时更快地访问。
lineLengths.persist()
- 1
RDD预览
| Actions | 提取 |
|---|---|
RDD.collect() | 将RDD以列表形式返回 |
RDD.collectAsMap() | 将RDD以字典形式返回 |
RDD.take(n) | 提取前n个元素 |
RDD.takeSample(replace, n, seed) | 随机提取n个元素 |
RDD.takeOrdered(num, key) | 按指定顺序从RDD中获取num个元素 |
RDD.first() | 提取第1名 |
RDD.top(n) | 提取前n名 |
RDD.keys() | 返回RDD的keys |
RDD.values() | 返回RDD的values |
RDD.isEmpty() | 检查RDD是否为空 |
RDD.toDF(schema,sampleRatio) | 转化为 Spark DataFrame |
>>> pairRDD.collectAsMap()
{'a': 2,'b': 2}
>>> pairRDD.keys().collect()
['a','a','b']
>>> pairRDD.values().collect()
[7,2,2]
- 1
- 2
- 3
- 4
- 5
- 6
注意:在单机模式上,通常使用RDD.foreach(println)或RDD.map(println)打印RDD的所有元素。然而,在集群模式下,调用的stdout输出会出现在worker上,而在本地不会显示。要在本地打印所有元素,可以首先使用 collect()方法将RDD收集到本机,然后 RDD.collect().foreach(println)。然而,这可能会导致本地内存不足,因为collect()将整个RDD获取到一台机器上。如果您只需要打印RDD的几个元素,更安全的方法是使用``take()`。
Map-Reduce
| Transformations | Map |
|---|---|
RDD.map(func) | 将函数应用于RDD中的每个元素并返回 |
RDD.mapValues(func) | 不改变key,只对value执行map |
RDD.flatMap(func) | 先map后扁平化返回 |
RDD.flatMapValues(func) | 不改变key,只对value执行flatMap |
RDD.foreach(func) | 用迭代的方法将函数应用于每个元素 |
RDD.keyBy(func) | 执行函数于每个元素创建key-value对RDD |
RDD.reduceByKey(func) | 合并每个key的value |
| Actions | Reduce |
|---|---|
RDD.reduce(func) | 合并RDD的元素返回 |
>>> rdd = sc.parallelize([1, 2, 3, 4, 5]) >>> rdd.map(lambda x: x + 1).collect() [2, 3, 4, 5, 6] >>> rdd.reduce(lambda x, y : x + y) 15 >>> rdd.keyBy(lambda x: x % 2).collect() [(1, 1), (0, 2), (1, 3), (0, 4), (1, 5)] >>> pairRDD = sc.parallelize([('a', 7),('a', 2),('b', 2)]) >>> pairRDD.mapValues(lambda x: x + 1).collect() [('a', 8), ('a', 3), ('b', 3)] >>> pairRDD.reduceByKey(lambda x, y: x + y).collect() [('a', 9), ('b', 2)] >>> names = sc.parallelize(['Elon Musk', 'Bill Gates']) >>> names.map(lambda x: x.split(' ')).collect() [('Elon', 'Musk'), ('Bill', 'Gates')] >>> names.flatMap(lambda x: x.split(' ')).collect() ['Elon', 'Musk', 'Bill', 'Gates']

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
分组和聚合
| Transformations | 分组 |
|---|---|
RDD.groupBy(func) | 将RDD元素通过函数变换分组为key-iterable集 |
RDD.groupByKey() | 将key-value元素集分组为key-iterable集 |
RDD.fold(zeroValue,func) | |
RDD.foldByKey(zeroValue,func) | |
RDD.aggregateByKey(zeroValue, seqOp, combOp) |
| Actions | 聚合 |
|---|---|
RDD.aggregate(zeroValue, seqOp, combOp) |
>>> rdd = sc.parallelize([1, 2, 3, 4, 5])
>>> rdd.groupBy(lambda x: x % 2).mapValues(list).collect()
[(0, [2, 4]), (1, [1, 3, 5])]
>>> pairRDD = sc.parallelize([('a', 7),('a', 2),('b', 2)])
>>> pairRDD.groupByKey().mapValues(list).collect()
[('a', [7, 2]), ('b', [2])]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
统计
| Actions | 统计 |
|---|---|
RDD.count() | 返回RDD中的元素数 |
RDD.countByKey() | 按key计算RDD元素数量 |
RDD.countByValue() | 按RDD元素计算数量 |
RDD.sum() | 求和 |
RDD.mean() | 平均值 |
RDD.max() | 最大值 |
RDD.min() | 最小值 |
RDD.stdev() | 标准差 |
RDD.variance() | 方差 |
RDD.histograme() | 分箱(Bin)生成直方图 |
RDD.stats() | 综合统计(计数、平均值、标准差、最大值和最小值) |
>>> pairRDD = sc.parallelize([('a', 7),('a', 2),('b', 2)])
>>> pairRDD.count()
3
>>> pairRDD.countByKey()
defaultdict(<class 'int'>, {'a': 2, 'b': 1})
>>> pairRDD.countByValue()
defaultdict(<class 'int'>, {('a', 7): 1, ('a', 2): 1, ('b', 2): 1})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
筛选
| Transformations | 筛选 |
|---|---|
RDD.filter(func) | 筛选满足函数的元素(变换) |
>>> rdd = sc.parallelize([1, 2, 3, 4, 5])
>>> rdd.filter(lambda x: x % 2 == 0).collect()
[2, 4]
- 1
- 2
- 3
去重
| Transformations | 去重 |
|---|---|
RDD.distinct() |
排序
| Transformations | 排序 |
|---|---|
RDD.sortBy(func, ascending=True) | 按RDD元素变换后的值排序 |
RDD.sortByKey(ascending=True) | 按key排序 |
连接运算
| Transformations | 连接运算 |
|---|---|
RDD.join(other) | 内连接 |
RDD.cogroup(other) | groupWith |
RDD.leftOuterJoin(other) | 左连接 |
RDD.rightOuterJoin(other) | 右连接 |
RDD.fullOuterJoin(other) | 全连接 |
>>> rdd1 = sc.parallelize([('a', 7), ('a', 2), ('b', 2)])
>>> rdd2 = sc.parallelize([('b', 'B'),('c', 'C')])
>>> rdd1.join(rdd2).collect()
[('b', (2, 'B'))]
>>> rdd1.fullOuterJoin(rdd2).collect()
[('b', (2, 'B')), ('c', (None, 'C')), ('a', (7, None)), ('a', (2, None))]
- 1
- 2
- 3
- 4
- 5
- 6
集合运算
| Transformations | 集合运算 |
|---|---|
RDD.union(other) | 并集(不去重) |
RDD.intersection(other) | 交集(去重) |
RDD.subtract(other) | 差集(不去重) |
RDD.subtractByKey(other) | 差集 by key |
RDD.cartesian(other) | 笛卡尔积 |
RDD.subtractByKey(other) | 按key差集 |
>>> rdd1 = sc.parallelize([1, 1, 3, 5])
>>> rdd2 = sc.parallelize([1, 3])
>>> rdd1.union(rdd1).collect()
[1, 1, 3, 5, 1, 1, 3, 5]
>>> rdd1.intersection(rdd2).collect()
[1, 3]
>>> rdd1.subtract(rdd2).collect()
[5]
>>> rdd2.cartesian(rdd2).collect()
[(1, 1), (1, 3), (3, 1), (3, 3)]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
抽样
| Transformations | |
|---|---|
RDD.sample(replace, frac, seed) | 随机采样 |
RDD.sampleByKey(replace, frac, seed) | 分层采样 |
RDD.takeSample(replace, n, seed) | 随机提取n个元素 |
RDD.randomSplit(weight, seed) | 随机拆分 |
>>> rdd.sample(False, 0.8, seed=42)
- 1
Shuffle
在前面讲的Spark编程模型当中,我们对RDD中的常用transformation与action 函数进行了讲解,我们提到RDD经过transformation操作后会生成新的RDD,前一个RDD与tranformation操作后的RDD构成了lineage关系,也即后一个RDD与前一个RDD存在一定的依赖关系,根据tranformation操作后RDD与父RDD中的分区对应关系,可以将依赖分为两种:
- 窄依赖(narrow dependency):变换操作后的RDD仅依赖于父RDD的固定分区,则它们是窄依赖的。
- 宽依赖(wide dependency):变换后的RDD的分区与父RDD所有的分区都有依赖关系(即存在shuffle过程,需要大量的节点传送数据),此时它们就是宽依赖的。
如下图所示:
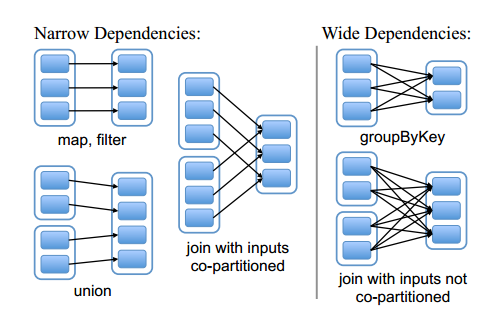
图中的实线空心矩形代表一个RDD,实线空心矩形中的带阴影的小矩形表示分区(partition)。从上图中可以看到, map, filter, union等transformation是窄依赖;而groupByKey是宽依赖;join操作存在两种情况,如果分区仅仅依赖于父RDD的某一分区,则是窄依赖的,否则就是宽依赖。
优化:fork/join
宽依赖需要进行shuffle过程,需要大量的节点传送数据,无法进行优化;而所有窄依赖则不需要进行I/O传输,可以优化执行。
当RDD触发相应的action操作后,DAGScheduler会根据程序中的transformation类型构造相应的DAG并生成相应的stage,所有窄依赖构成一个stage,而单个宽依赖会生成相应的stage。
缓存
默认情况下,每次对RDD运行Action时,每个变换都可能会被重新计算。若RDD在未来的Action中重复利用时,我们可以使用persist()或cache()方法将其标记为持久。首次计算后,它将保存在节点的内存中。这使得未来的行动要快得多(通常超过10倍)。缓存是迭代算法和快速交互使用的关键工具。Spark的缓存是容错的,如果任何分区丢失,它将使用最初创建它的转换自动重新计算。
# Persists the data in the disk by specifying the storage level.
from pyspark.storagelevel import StorageLevel
rdd.persist(StorageLevel.DISK_ONLY)
- 1
- 2
- 3
**注意:**在Python中,存储的对象将始终使用Pickle库进行序列化,因此您是否选择序列化级别并不重要。Python中的可用存储级别包括MEMORY_ONLY、MEMORY_ONLY_2、MEMORY_AND_DISK、MEMORY_AND_DISK_2、DISK_ONLY、DISK_ONLY_2和DISK_ONLY_3。
| 持久化 | 说明 |
|---|---|
RDD.persist() | 标记为持久化 |
RDD.cache() | 等价于rdd.persist(MEMORY_ONLY) |
RDD.unpersist() | 释放缓存 |
共享变量
默认情况下,当Spark在不同节点上作为一组任务并行运行函数时,它会将函数中使用的所有变量的复制到每台机器上。有时,变量需要在任务之间共享,或在任务和驱动程序之间共享,而集群机器上变量的更新不会传播回驱动程序。Spark支持两种类型的共享变量(Shared Variables):广播变量和累加器。
广播变量
广播变量(Broadcast Variables)在集群上广播一个只读变量。创建广播变量后,在集群上运行的任何函数中都可以使用它,而不用多次发送副本。此外,对象在广播后不应进行修改,以确保所有节点获得广播变量的值是相同的。
| PySpark | |
|---|---|
SparkContext.broadcast(value) | 创建广播变量 |
Broadcast.value | 返回广播变量的值 |
Broadcast.destroy() | 永久释放广播变量使用的所有资源 |
Broadcast.unpersist() | 释放广播变量复制到执行器的资源 |
>>> broadcastVar = sc.broadcast([1, 2, 3])
<pyspark.broadcast.Broadcast object at 0x102789f10>
>>> broadcastVar.value
[1, 2, 3]
- 1
- 2
- 3
- 4
- 5
累加器
Spark中的累加器(Accumulators)专门用于在集群中的工作节点之间安全更新变量。
| Pyspark | |
|---|---|
SparkContext.accumulator(value) | 创建一个初始值为value的累加器 |
Accumulator.add(term) | 在此累加器的值中添加一项 |
Accumulator.value | 获取累加器的值,仅在驱动程序中可用 |
通过调用SparkContext.accumulator(value)从初始值value创建累加器。然后在集群上运行的任务可以使用add方法或+=运算符添加到集群中。然而,他们无法读取它的值。只有驱动程序程序可以使用其value方法读取累加器的值。
下面的代码显示了用于添加数组元素的累加器:
>>> accum = sc.accumulator(0)
>>> accum
Accumulator<id=0, value=0>
>>> sc.parallelize([1, 2, 3, 4]).foreach(lambda x: accum.add(x))
...
10/09/29 18:41:08 INFO SparkContext: Tasks finished in 0.317106 s
>>> accum.value
10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
内置累加器只支持数字类型,但我们可以新建AccumulatorParam子类来自定义数据类型。AccumulatorParam接口有两种方法:zero用于为您的数据类型提供“零值”,以及用于将两个值一起添加的addInPlace。例如,假设我们有一个表示数学向量的Vector类,我们可以写:
class VectorAccumulatorParam(AccumulatorParam):
def zero(self, initialValue):
return Vector.zeros(initialValue.size)
def addInPlace(self, v1, v2):
v1 += v2
return v1
# Then, create an Accumulator of this type:
vecAccum = sc.accumulator(Vector(...), VectorAccumulatorParam())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
对于仅在Actions中执行的累加器更新,Spark保证每个任务对累加器的更新将只应用一次,即重新启动的任务不会更新值。在Transformation中,如果重新执行任务或作业阶段,每个任务的更新可能会被应用超过一次。
累加器不会改变Spark的惰性,如果它们在RDD的Actions中更新,则仅在RDD作为Actions的一部分计算后,其值才会更新。因此,当在map()等惰性转换时,不能保证执行累加器更新。
accum = sc.accumulator(0)
def g(x):
accum.add(x)
return f(x)
data.map(g)
# Here, accum is still 0 because no actions have caused the `map` to be computed.
- 1
- 2
- 3
- 4
- 5
- 6


