
- 1在数组中找重复数、只出现一次的数或丢失数的题目(Leetcode题解-Python语言)_数组中唯一不出现两次的数字的下标
- 2sqlalchemy相关操作_sqlalchemy between
- 3stable diffusion API 调用,超级详细代码示例和说明_stable diffusio api
- 4pytorch 模型训练时多卡负载不均衡(GPU的0卡显存过高)解决办法(简单有效)_多卡部署大模型还是爆显存
- 5MySQL “Specified key was too long; max key length is 767 bytes”解决办法_specified key was too long; max key length is 767
- 6Pytorch入门实战第六周:VGG-16算法-Pytorch实现人脸识别_pytorch 导入vgg16
- 7实验三:数据选择器_数据选择器实验
- 8kafka生产者RecordAccumulator源码解析_org.apache.kafka.clients.producer.internals.record
- 9Node.js引入模块_node 引用主项目的公共模块
- 10C# SqlBulkCopy sqlserver 批量更新数据_c# sqlserver 批量更新数据
【实战】瀚高数据库安装timescale扩展_瀚高数据库安装部署
赞
踩
本文转自微信公众号“瀚高数据库售前团队”文章
https://mp.weixin.qq.com/s/3GPtX9QN9DLRI8pJcg6gZA
声明:
本文章内容仅用于学习、交流,未经瀚高数据库团队允许,不得任意修改或者增减此文章内容,不得以任何方式将其用于商业目的,利用此文所提供的信息而造成的任何直接或间接的损失,均由使用者本人负责。
概述
时序数据库(Time Series Database,简称TSDB)是一种专门设计用于高效存储、索引和查询时间序列数据的数据库系统。时间序列数据是指按时间顺序记录的数据点集合,每个数据点通常包含一个时间戳以及与该时间相关的测量值或状态信息。在物联网(IoT)、工业自动化、监控系统、金融交易分析、IT运维、能源管理、气象监测等领域,都会产生大量的随时间连续变化的数据。例如,股票实时交易信息、温度传感器每分钟产生的温度读数、服务器CPU使用率的变化、或者车辆运行过程中的各项性能指标等都是典型的时间序列数据。时序数据库一般具备高性能写入、数据压缩、精确的时间处理、数据保留策略的特点或功能。
Timescaledb 是一个时下非常流行的基于 PostgreSQL 构建时序数据库平台,在 DB-Engines 网站时序数据库系列有着较高的排名,其非常适合时间序列、事件和分析数据等场景。
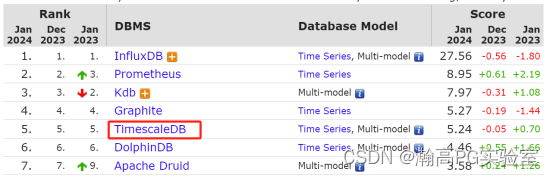
瀚高数据库作为成熟的基于 PostgreSQL 技术路线的国产数据库,自然也支持使用 timescale 插件扩展,作为时序数据库来支撑各种应用场景,接下来,让我们实际操作一下,来看看瀚高数据库如何使用 timescale,并进行简单的场景演示。
演示环境:虚拟机+linux操作系统
软件版本:瀚高安全版数据库4.5.8,timescaledb2.11
部署数据库
瀚高数据库支持快速部署,本次不在赘述部署过程,如需了解,请访问瀚高云上支持中心或联系瀚高前端团队。
瀚高云上技术支持中心:
http://sheco.highgo.com/index
如下,已经搭部署完成瀚高安全版数据库4.5.8并可以正常使用 psql 工具本地连接。
部署timescale
1.准备工作
由于 timescale 的安装需要一些常见的依赖库和 cmake,我们首先集中安装下依赖:
yum install -y gcc gcc-c++ \
openssl openssl-devel zlib zlib-devel \
epel-release clang \
libicu-devel perl-ExtUtils-Embed \
readline readline-devel \
pam-devel libxml2-devel libxslt-devel \
openldap-devel systemd-devel \
tcl-devel python-devel \
llvm5.0 llvm5.0-devel
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
然后安装 cmake,从官网直接获取 tar 包解压即可:
https://cmake.org/download/
然后执行文件建立软连接到/usr/bin:
n -s /opt/cmake-3.28.1-linux-x86_64/bin/cmake /usr/bin/cmake
ln -s /opt/cmake-3.28.1-linux-x86_64/bin/ccmake /usr/bin/ccmake
ln -s /opt/cmake-3.28.1-linux-x86_64/bin/cpack /usr/bin/cpack
ln -s /opt/cmake-3.28.1-linux-x86_64/bin/ctest /usr/bin/ctest
- 1
- 2
- 3
- 4
(请使用实际目录)
2.正式部署
2.1编译
首先从 github 项目获取 timescale 包,本次使用2.11版本:
https://codeload.github.com/timescale/timescaledb/tar.gz/refs/tags/2.11.0
下载后上传到服务器;
解压缩:tar -xvf timescaledb-2.11.0.tar.gz;
然后进入到目录开始编译;
按照 timescale 官方文档指导,先执行命令:
./bootstrap
- 1
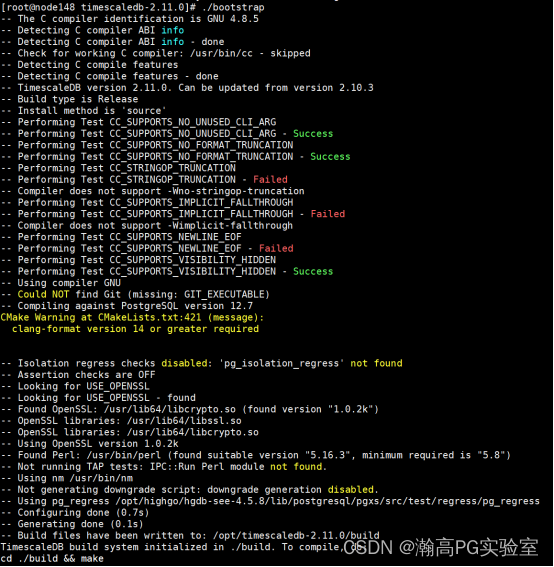
再按照提示进行编译,并解决编译过程中的问题,执行命令:
cd ./build && make
- 1
执行命令:
make install
- 1
2.2瀚高数据库加载扩展
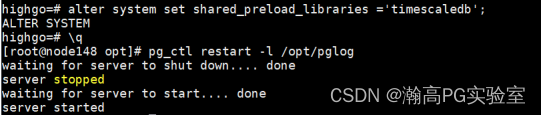
添加 timescaledb 共享库到数据库配置文件并重启数据库,执行命令:
alter system set shared_preload_libraries ='timescaledb';
pg_ctl restart -l /opt/pglog
- 1
- 2
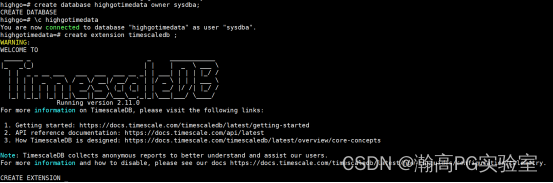
连接瀚高数据库,创建一个测试库 timeData,切换到测试库,创建 timescaledb 扩展,执行命令:
create database highgotimedata owner sysdba;
\c highgotimedata
create extension timescaledb ;
- 1
- 2
- 3
扩展成功:
使用timescale
1.加载测试数据
Timescale 官方为了方便大家学习使用,官方文档中为我们提供了 Twelve Data 的实时股票交易数据,我们获取一下:
https://docs.timescale.com/getting-started/latest/time-series-data/
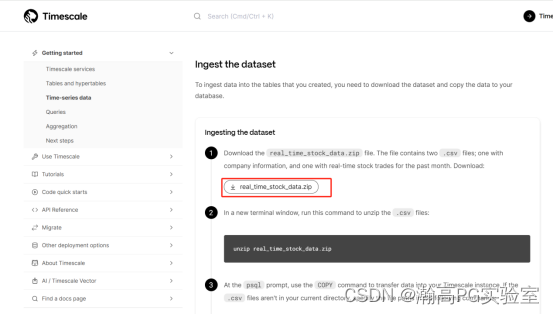
上传到服务器并解压后,我们使用 psql 进入测试数据库,创建表,并将数据导入:
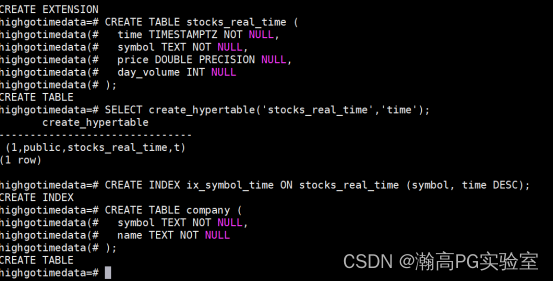
-- 创建普通数据表 CREATE TABLE stocks_real_time ( time TIMESTAMPTZ NOT NULL, symbol TEXT NOT NULL, price DOUBLE PRECISION NULL, day_volume INT NULL ); -- 通过 time 进行分区将普通表转换为超表(时序表) SELECT create_hypertable('stocks_real_time','time'); -- 创建索引以高效查询 symbol 和 time 列 CREATE INDEX ix_symbol_time ON stocks_real_time (symbol, time DESC); -- 创建普通表 CREATE TABLE company ( symbol TEXT NOT NULL, name TEXT NOT NULL );

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
执行:
\COPY stocks_real_time from '/opt/tutorial_sample_tick.csv' DELIMITER ',' CSV HEADER;
\COPY company from '/opt/tutorial_sample_company.csv' DELIMITER ',' CSV HEADER;
- 1
- 2

可能需要手动弥补下模拟交易量数据到 day_volume 列:
UPDATE stocks_real_time SET day_volume=(random()*(100000-1)+1);
- 1

查看下超表的表结构:
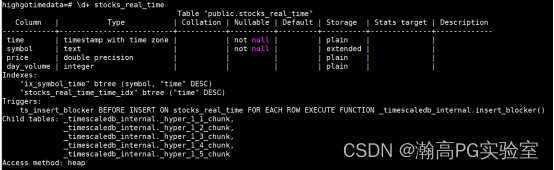
可以看出和普通表的不同,自动做了子分区以及添加了时序相关的触发器。
2.特性测试
我们来使用下时序数据库的部分功能。
2.1特有函数
Timescale 具有自定义 SQL 函数,可帮助进行时间序列分析更简单、更快捷。我们测试几种常见的时间刻度函数:
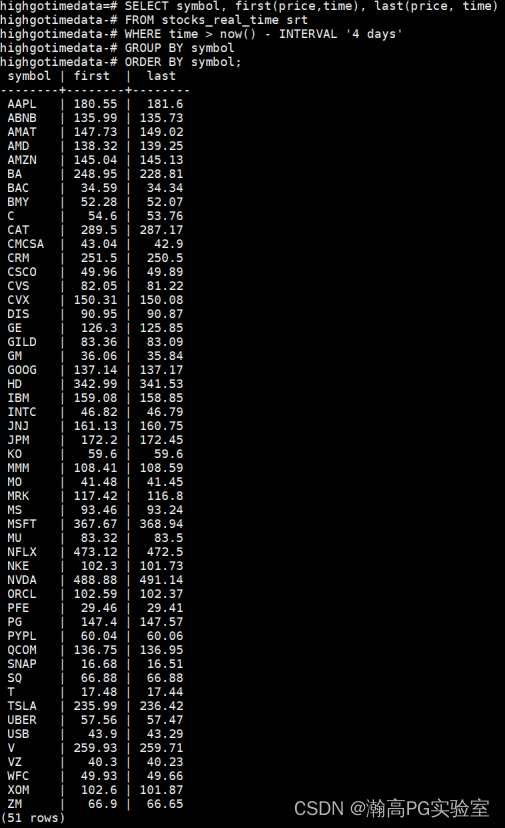
查找组内最早的值和最新值;
-- first() and last()
-- 获取所有公司近4天的第一笔成交价和最后一笔成交价
SELECT symbol, first(price,time), last(price, time)
FROM stocks_real_time srt
WHERE time > now() - INTERVAL '4 days'
GROUP BY symbol
ORDER BY symbol;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
为了轻松查看不同时间范围内的数字,可以使用时间刻度函数时间桶,对数据按时间进行分组,时间桶表示特定时间点,因此数据的所有时间戳都在一个时间桶中使用存储桶时间戳。
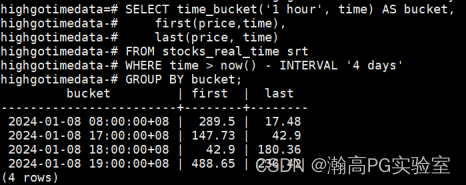
---检索1小时时间存储桶的第一个和最后一个值
SELECT time_bucket('1 hour', time) AS bucket,
first(price,time),
last(price, time)
FROM stocks_real_time srt
WHERE time > now() - INTERVAL '4 days'
GROUP BY bucket;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.2连续聚合
聚合是一种数据梳理常见的方法,计算时间段的均值以对应时间段。首先我们测试使用普通聚合查询:
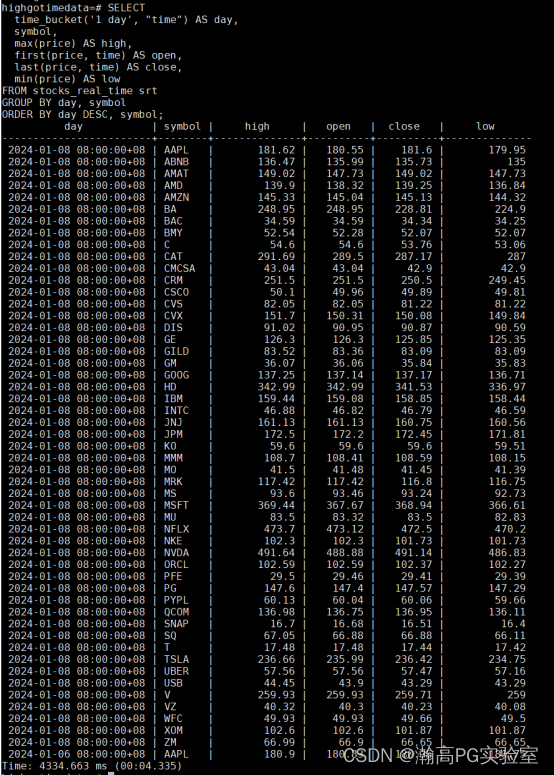
- 普通聚合查询:查询各个股票每天的开盘价格、闭盘价格、以及最高、最低交易价格
SELECT
time_bucket('1 day', "time") AS day,
symbol,
max(price) AS high,
first(price, time) AS open,
last(price, time) AS close,
min(price) AS low
FROM stocks_real_time srt
GROUP BY day, symbol
ORDER BY day DESC, symbol;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
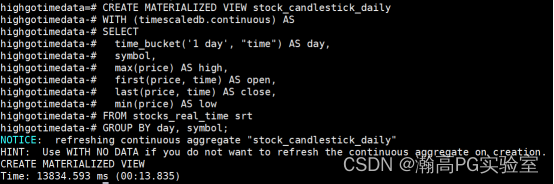
随着数据量增加,聚合计算可能会变缓慢,利用 timescale 可以按时间刻度把数据聚合起来,连续聚合可以最大限度地减少执行查询时需要查找的记录。
-- 创建连续聚合
CREATE MATERIALIZED VIEW stock_candlestick_daily
WITH (timescaledb.continuous) AS
SELECT
time_bucket('1 day', "time") AS day,
symbol,
max(price) AS high,
first(price, time) AS open,
last(price, time) AS close,
min(price) AS low
FROM stocks_real_time srt
GROUP BY day, symbol;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
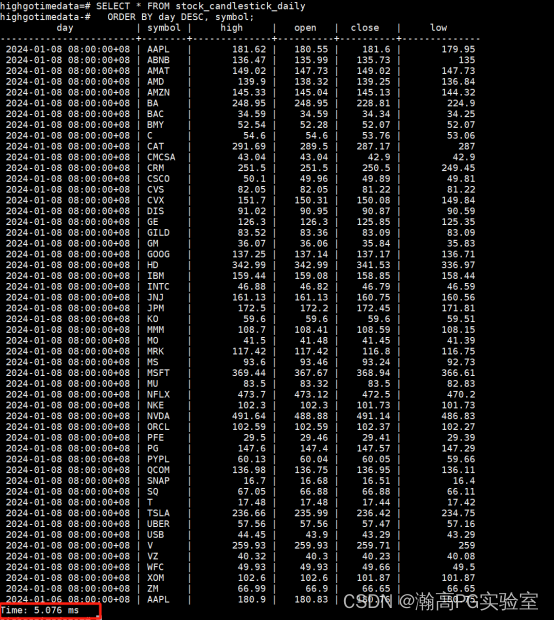
-- 查询聚合结果,相比直接查询时间大幅提升
SELECT * FROM stock_candlestick_daily
ORDER BY day DESC, symbol;
- 1
- 2
- 3
--查询单个股票
SELECT * FROM stock_candlestick_daily
WHERE symbol='TSLA';
- 1
- 2
- 3
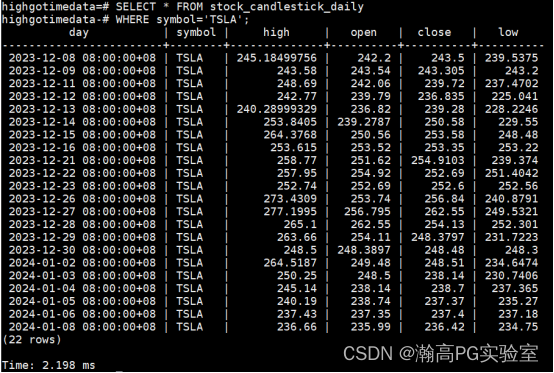
当连续聚合被创建时,其默认开启实时聚合功能,即未被聚合到视图中的数据将被实时聚合并记录到视图当中。
2.3数据压缩
可以压缩时间序列数据以减少所需的存储量,并且提高某些查询的速度。 TimescaleDB 的压缩原理是把许多宽行数据转换为单行数组,新的宽行字段可能包含整个列或者多列数据。基于此,有不同的压缩算法,简单测试一下。
-- 数据压缩
-- 首先需要设置允许超表进行数据压缩
ALTER TABLE stocks_real_time SET (
timescaledb.compress,
timescaledb.compress_orderby = 'time DESC',
timescaledb.compress_segmentby = 'symbol'
);
-- 自动压缩策略
-- 自动对一周之前的数据进行压缩,并创建循环规则
-- 被压缩的分区可以执行数据的插入,但是无法更新和删除
SELECT add_compression_policy('stocks_real_time', INTERVAL '1 weeks');
-- 查看压缩策略的统计信息
SELECT * FROM timescaledb_information.job_stats;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
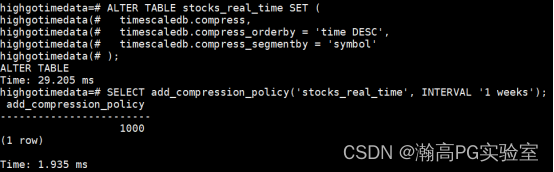

-- 查看压缩后数据的结果
SELECT pg_size_pretty(before_compression_total_bytes) as "before compression",
pg_size_pretty(after_compression_total_bytes) as "after compression"
FROM hypertable_compression_stats('stocks_real_time');
- 1
- 2
- 3
- 4

2.4数据保留策略
在时间序列应用程序中,数据通常会随着年龄的增长而适用性性降低。Timescale 可以设置自动数据保留策略以丢弃旧数据。
-- 自动保留策略
-- 自动删除 3周 之前的数据,并创建循环规则
SELECT add_retention_policy('stocks_real_time', INTERVAL '3 weeks');
-- 查询保留策略的相关细节
SELECT * FROM timescaledb_information.jobs;
- 1
- 2
- 3
- 4
- 5


本次仅测试部分时序功能,瀚高数据库融合 timescale 扩展后,可以有效支撑时序数据应用场景,应用于工业、制造业、金融业等领域。

