
- 1垂直同步_显示器自适应垂直同步即将大一统:NVIDIA有条件支持FreeSync
- 2微信小程序的常见的面试题(总结)_小程序面试题
- 3VMware中Kali Linux添加源,更新和安装vmtools_kali 2021.3安装vmtools
- 4使用ElasticsearchRepository和ElasticsearchRestTemplate操作Elasticsearch,Spring Boot整合Elasticsearch_idea连接elasticsearch elasticsearchresttemplate
- 5创维E900V22C、E900V22D_S905L3-L3B免拆卡刷固件_e900v22d刷机
- 6GO开发环境配置_go环境配置
- 7react实现HTML调摄像头拍照功能_react 拍照
- 8php GET 和 POST 方法的区别_php get和post 区别
- 9通俗讲解Pytorch梯度的相关问题:计算图、no_grad、zero_grad、retain_grad、detach和backward;Variable、Parameter和torch.tensor_pytorch retain_grad
- 10cortex a7 a53_西昊人体工学椅A7开箱测评
GPT-Engineer:一个提示就能生成完整应用|全自动代码生成神器
赞
踩
一、前言
对于编程初学者或者没有太多时间深入学习开发的人来说,GPT Engineer这个新型人工智能工具具有非常大的吸引力。它可以根据简单的自然语言提示,自动生成完整的应用程序代码,极大地简化了软件开发过程。
GPT Engineer通过大规模预训练语言模型获得了强大的代码生成能力。它可以解析提示中的需求,根据指定的编程语言选择合适的框架,并生成遵循最佳实践的、可直接使用的代码。这使得软件开发无需手动编写重复代码,整个过程可以在几分钟内完成。
GPT Engineer当前支持Python、Javascript、Java等主流编程语言。它还具备持续学习的能力,可以通过用户反馈不断改进生成结果,适应不同用户的代码风格。这些使它成为一个程序员多功能且可个性化的辅助工具。
本文将详细介绍GPT Engineer的工作原理、安装方法以及具体使用场景。我们将借助一个简单的Plotly Dash应用示例,分步展示GPT Engineer如何仅通过几句提示就生成完整可用的代码。希望本文可以让更多对自动编程感兴趣的读者快速上手这个颠覆传统开发方式的新工具。
二、介绍 GPT-Engineer
GPT-Engineer 是一个使用 GPT-4 来自动化软件工程过程的项目。它包括几个与 GPT-4 模型交互的 Python 脚本,以生成代码、阐明需求、生成规范等,目前GitHub上已有四万多颗星。
借助 GPT-Engineer,开发人员不再需要从头开始编码或花费数小时搜索相关代码示例。通过提供描述所需项目或功能的清晰简洁的提示,开发人员可以获得根据其特定要求量身定制的全面代码库。这种简化的流程提高了生产力,并使开发人员能够专注于项目的更高级别方面。让我们更深入地了解 GPT-Engineer 的工作原理。
暂时无法在飞书文档外展示此内容
2.1、GPT-Engineer 的工作原理
GPT-Engineer 利用自然语言处理和机器学习模型的力量来了解您的项目需求。通过提供描述您所需应用程序的提示,GPT-Engineer 会解释指令并生成相应的代码库。它封装了项目所需的基本逻辑和结构,为您节省了大量的时间和精力。这种创新方法使开发人员能够更多地专注于概念化和完善他们的想法,而不是陷入重复的编码任务中。
GPT-Engineer 按照简单的工作流程根据提示生成代码:
2.1.1、提示定义
开发人员使用自然语言在提示中定义他们的项目需求和规范。
2.1.2、代码生成
GPT-Engineer 分析提示并根据给定的指令生成代码片段、函数、类甚至整个应用程序。
2.1.3、细化和优化
虽然 GPT-Engineer 提供了坚实的基础,但开发人员可以细化和优化生成的代码,使其符合他们的特定需求,确保其符合质量标准。
2.2、GPT-Engineer 有什么特点
-
识别:可以通过编辑身份文件夹中的文件来指定AI代理的身份。这使得用户能够根据自己的需求定制人工智能代理。例如,用户可以指定人工智能代理的姓名、性别和个性品质。
-
记忆:人工智能代理可以通过改变身份和进化
prompt来记住项目之间的内容。因此,人工智能代理可以随着时间的推移进行学习和发展。 -
通信历史记录:steps.py中每个步骤与GPT4的通信历史记录将保存在logs文件夹中。这使用户能够监控 AI 代理的进度并解决问题。Scripts/reruneditedmessage_logs.py 可用于重做通信历史记录。
2.3、GPT-Engineer 有什么优势
2.3.1、节省时间和精力
通过自动化代码生成过程,GPT-Engineer 显着减少了开发软件应用程序所需的时间和精力。开发人员可以利用生成的代码库作为起点,快速启动他们的项目,并专注于增强和自定义代码,而不是从头开始。
2.3.2、提高生产力和效率
GPT-Engineer 使开发人员能够更高效地工作,因为它负责日常编码任务。通过生成的代码库,开发人员可以加速开发过程,更快地迭代,并将时间分配到项目的关键方面,例如设计、测试和优化。
2.3.3、增强代码质量
GPT-Engineer 生成的代码基于软件开发社区中观察到的最佳实践和标准。这确保了生成的代码库具有高质量、结构良好且遵守编码约定,从而减少了引入错误或漏洞的机会。
2.3.4、学习与探索
GPT-Engineer 对于开发人员来说是一个有价值的学习工具。通过检查生成的代码,开发人员可以深入了解不同的编码技术、设计模式和最佳实践。接触不同的代码库可以扩展他们的知识并培养解决编程挑战的创造力。
2.4、GPT-Engineer 有什么限制
虽然 GPT-Engineer 是一个强大的工具,但考虑它的局限性也很重要:
2.4.1、特定领域的知识
GPT-Engineer 基于预先训练的模型进行操作,可能不具备专业领域的专业知识。开发人员在将其用于需要深入领域知识的高度具体或复杂的项目时应谨慎行事。
2.4.2、代码验证和测试
生成的代码应经过严格的测试和验证,以确保其功能和稳健性。开发人员必须彻底审查和测试代码库,根据需要进行必要的修改和改进。
2.4.3、依赖管理
GPT-Engineer 可能不会考虑个别开发人员首选的特定依赖项或框架。检查和配置生成的代码库以与所需的开发环境和首选工具保持一致至关重要。
2.5、GPT-Engineer 有什么影响
GPT-Engineer的推出利用GPT模型的优势对不同领域产生了巨大影响。其出色的技能之一是能够仅使用几个单词作为输入在几秒钟内生成代码。这大大加快了开发过程,并减少了编码活动所需的时间和精力。
此外,GPT-Engineer 提供全面的定制可能性,允许客户在多个项目中改变人工智能代理的行为和记忆。这可以通过修改或添加文件到身份文件夹来实现,允许用户指定人工智能代理的个人功能和专业知识。
此外,GPT-Engineer代码生成过程是可见、可追溯的。代码生成过程的每个阶段都被记录并保存在日志文件夹中。此功能允许用户返回并重新运行某些阶段,从而可以对生成的代码进行迭代细化和调试。它鼓励高效的工作流程,并提高根据必要要求微调和改进输出的能力。
总体而言,GPT-Engineer 的出现通过使用 GPT 模型的功能彻底改变了代码生产,实现了快速高效的编码、高级定制和迭代代码精炼。它在减少开发流程和促进多个领域的创新方面具有巨大的潜力。
三、安装 GPT-Engineer
3.1、先决条件
安装前需要具备以下先决条件:
-
安装 Python(≥3.0)和 Git
-
安装了 conda 或 pip
-
访问 bash(macOS、Linux 或 Windows)
-
代码编辑器(VSCode 或 PyCharm)
3.2、初始设置
在终端中输入以下内容创建并激活python虚拟环境:
- # pip
- python3 -m venv myenv
- source myenv/bin/activate
-
- # conda
- conda create --name myenv python=3.11.3
- conda activate myenv
3.3、下载 GPT-Engineer
首先,我们必须克隆这个 GitHub 存储库。为此,请打开终端并运行以下代码。
git clone https://github.com/AntonOsika/gpt-engineer.git
3.4、设置 GPT-Engineer
将创建一个名为 gpt-engineer 的新文件夹。使用 cd 更改目录,安装项目依赖。
- # 克隆存储库后,使用“ cd" 命令导航到克隆的目录:
- cd gpt-engineer
-
- # 接下来,通过运行以下命令安装必要的依赖项
- make install
- # 或者使用 python -m pip install -e .
-
- # 根据您的操作系统使用适当的命令激活虚拟环境
- source venv/bin/activate
3.5、设置 API 密钥
以下两种方式任意选择一种,默认使用GPT-4模型,没有GPT-4访问权限的key会自动切换到GPT-3.5。
- 导出环境变量(你可以将其添加到
.bashrc中,这样您就不必每次启动终端时都执行此操作)
- # macOS/linux
- export OPENAI_API_KEY=[your api key]
-
- # Windows(命令提示符)
- set OPENAI_API_KEY=[your api key]
-
- # Windows(PowerShell)
- $env:OPENAI_API_KEY="<your_api_key>"
- .env 文件
创建一个名为 .env 的 .env.template 副本,在 .env 中添加您的 OPENAIAPIKEY。
3.6、运行 GPT-Engineer
GPT-Engineer 通过位于项目文件夹中的 prompt 文件提供交互式界面。默认情况下,项目目录中存在一个“example”文件夹。
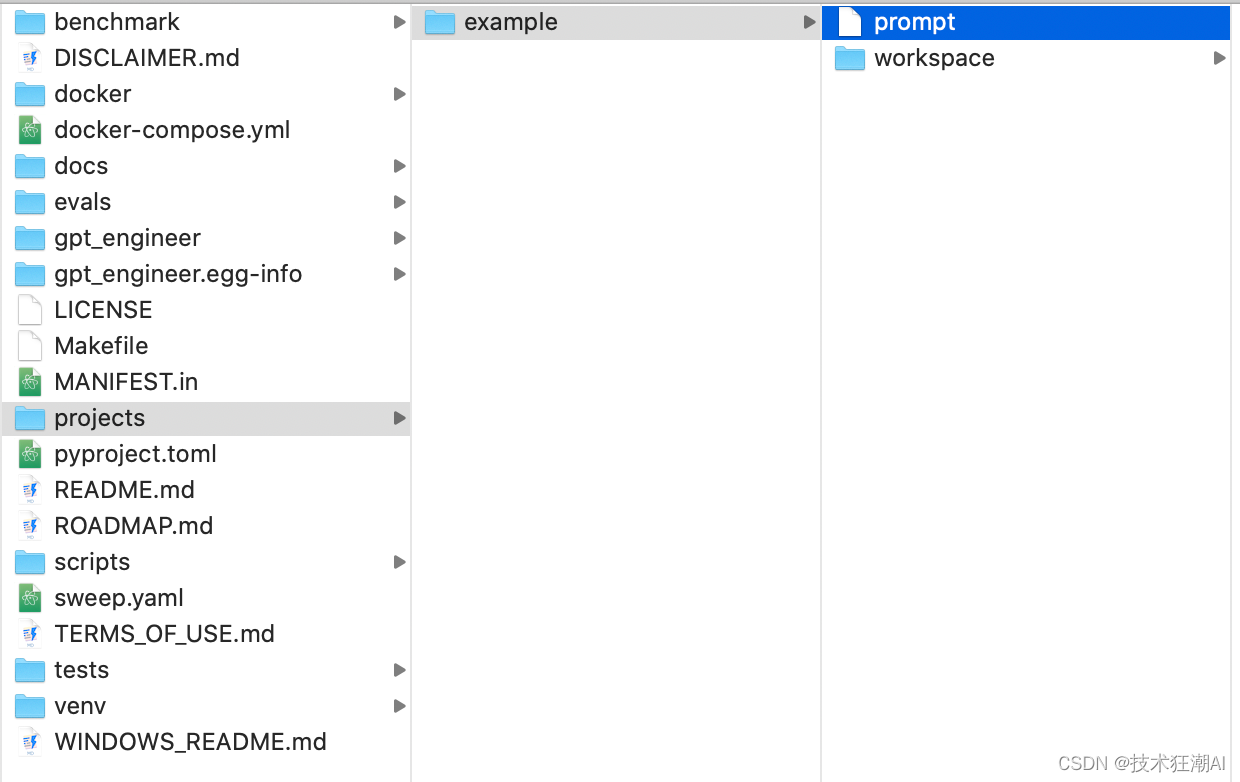
如果您想启动一个新项目,只需使用以下命令创建一个新文件夹即可。
cp -r projects/example/ projects/my-new-project
接下来在文本编辑器中打开 prompt 文件并根据您的项目要求修改提示。您可以在此处描述应用程序所需的功能或目标。您可以随意具体或笼统。
最后,使用以下命令运行 GPT-Engineer,并指定项目文件夹的路径:
gpt-engineer projects/my-new-project
- dream@MacBook-Pro gpt-engineer % source venv/bin/activate
-
- (venv) dream@MacBook-Pro gpt-engineer % export OPENAI_API_KEY=<your-openai-api-key>
- (venv) dream@MacBook-Pro gpt-engineer % make install
- Creating virtual environment...
- Upgrading pip...
- Installing dependencies...
- Installing pre-commit hooks...
- pre-commit installed at .git/hooks/pre-commit
- All done!
- (venv) dream@MacBook-Pro gpt-engineer % gpt-engineer projects/example
- INFO:openai:error_code=model_not_found error_message="The model 'gpt-4' does not exist" error_param=model error_type=invalid_request_error message='OpenAI API error received' stream_error=False
- Model gpt-4 not available for provided API key. Reverting to gpt-3.5-turbo. Sign up for the GPT-4 wait list here: https://openai.com/waitlist/gpt-4-api
-
- Running gpt-engineer in /Volumes/工作盘/gpt-engineer/projects/example
-
- Let's start by creating the file structure for our Snake game project. We will have three main components: Model, View, and Controller. Additionally, we will need a main entry point file to start the game.
- Here is the proposed file structure:
- ```
- snake_game/
- ├── main.py
- ├── model/
- │ ├── snake.py
- │ └── game.py
- ├── view/
- │ └── display.py
- └── controller/
- └── input_handler.py
- ```
- Now, let's start by creating the main entry point file `main.py`. This file will initialize the game and handle the game loop.
-
- main.py
- ```python
- from model.game import Game
- from view.display import Display
- from controller.input_handler import InputHandler
-
- def main():
- game = Game()
- display = Display()
- input_handler = InputHandler()
-
- while not game.is_game_over():
- # Update game state
- game.update()
-
- # Render game state
- display.render(game.get_state())
-
- # Handle user input
- input_handler.handle_input(game)
-
- if __name__ == "__main__":
- main()
- ```
-
- Next, let's create the `snake.py` file under the `model` directory. This file will define the Snake class, which represents the snake in the game.
- model/snake.py
- ```python
- from dataclasses import dataclass
- @dataclass
- class Snake:
- body: list
- direction: str
- def move(self):
- # Logic to move the snake based on the current direction
- pass
- def change_direction(self, new_direction):
- # Logic to change the direction of the snake
- pass
- ```
- Now, let's create the `game.py` file under the `model` directory. This file will define the Game class, which represents the game state and logic.
-
- model/game.py
- ```python
- from model.snake import Snake
-
- class Game:
- def __init__(self):
- self.snake = Snake()
- self.game_over = False
-
- def update(self):
- # Logic to update the game state
- pass
-
- def is_game_over(self):
- # Logic to check if the game is over
- pass
-
- def get_state(self):
- # Logic to get the current game state
- pass
- ```
-
- Next, let's create the `display.py` file under the `view` directory. This file will define the Display class, which handles rendering the game state.
- view/display.py
- ```python
- class Display:
- def render(self, game_state):
- # Logic to render the game state on the screen
- pass
- ```
- Finally, let's create the `input_handler.py` file under the `controller` directory. This file will define the InputHandler class, which handles user input.
-
- controller/input_handler.py
- ```python
- class InputHandler:
- def handle_input(self, game):
- # Logic to handle user input and update the game state accordingly
- pass
- ```
-
- Now that we have implemented all the necessary components, we can run the Snake game by executing the `main.py` file.
-
- This concludes a fully working implementation of the Snake game in Python, following the MVC architecture and separating the components into separate files.To install dependencies, we need to make sure we have Python and pip installed. Assuming they are already installed, we can proceed with the following commands:
-
- ```bash
- # Create a virtual environment
- python -m venv snake_env
-
- # Activate the virtual environment
- source snake_env/bin/activate
-
- # Install dependencies
- pip install pygame
- ```
-
- To run the Snake game, we need to execute the `main.py` file. We can do this with the following command:
-
- ```bash
- python main.py
- ```
-
- Note: Make sure you are in the root directory of the Snake game project before running the above commands.
-
- Do you want to execute this code? (Y/n)
-
- # Create a virtual environment
- python -m venv snake_env
-
- # Activate the virtual environment
- source snake_env/bin/activate
-
- # Install dependencies
- pip install pygame
-
- python main.py
-
-
- y
- Executing the code...
-
- Note: If it does not work as expected, consider running the code in another way than above.
-
- You can press ctrl+c *once* to stop the execution.
-
- Collecting pygame
- Downloading pygame-2.5.2-cp310-cp310-macosx_10_9_x86_64.whl (12.9 MB)
- ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 12.9/12.9 MB 714.6 kB/s eta 0:00:00
- Installing collected packages: pygame
- Successfully installed pygame-2.5.2
-
- [notice] A new release of pip is available: 23.0.1 -> 23.2.1
- [notice] To update, run: pip install --upgrade pip
- Traceback (most recent call last):
- File "/Volumes/工作盘/gpt-engineer/projects/example/workspace/main.py", line 21, in <module>
- main()
- File "/Volumes/工作盘/gpt-engineer/projects/example/workspace/main.py", line 6, in main
- game = Game()
- File "/Volumes/工作盘/gpt-engineer/projects/example/workspace/model/game.py", line 5, in __init__
- self.snake = Snake()
- TypeError: Snake.__init__() missing 2 required positional arguments: 'body' and 'direction'
-
- Is it ok if we store your prompts to learn? (y/n)y
- Thank you️
-
- (If you change your mind, delete the file .gpte_consent)
-
- To help gpt-engineer learn, please answer 3 questions:
-
- Did the generated code run at all? y/n/u(ncertain): y
- Did the generated code do everything you wanted? y/n/u(ncertain): y
- Total api cost: $ 0.005503000000000001
- (venv) dream@MacBook-Pro gpt-engineer %

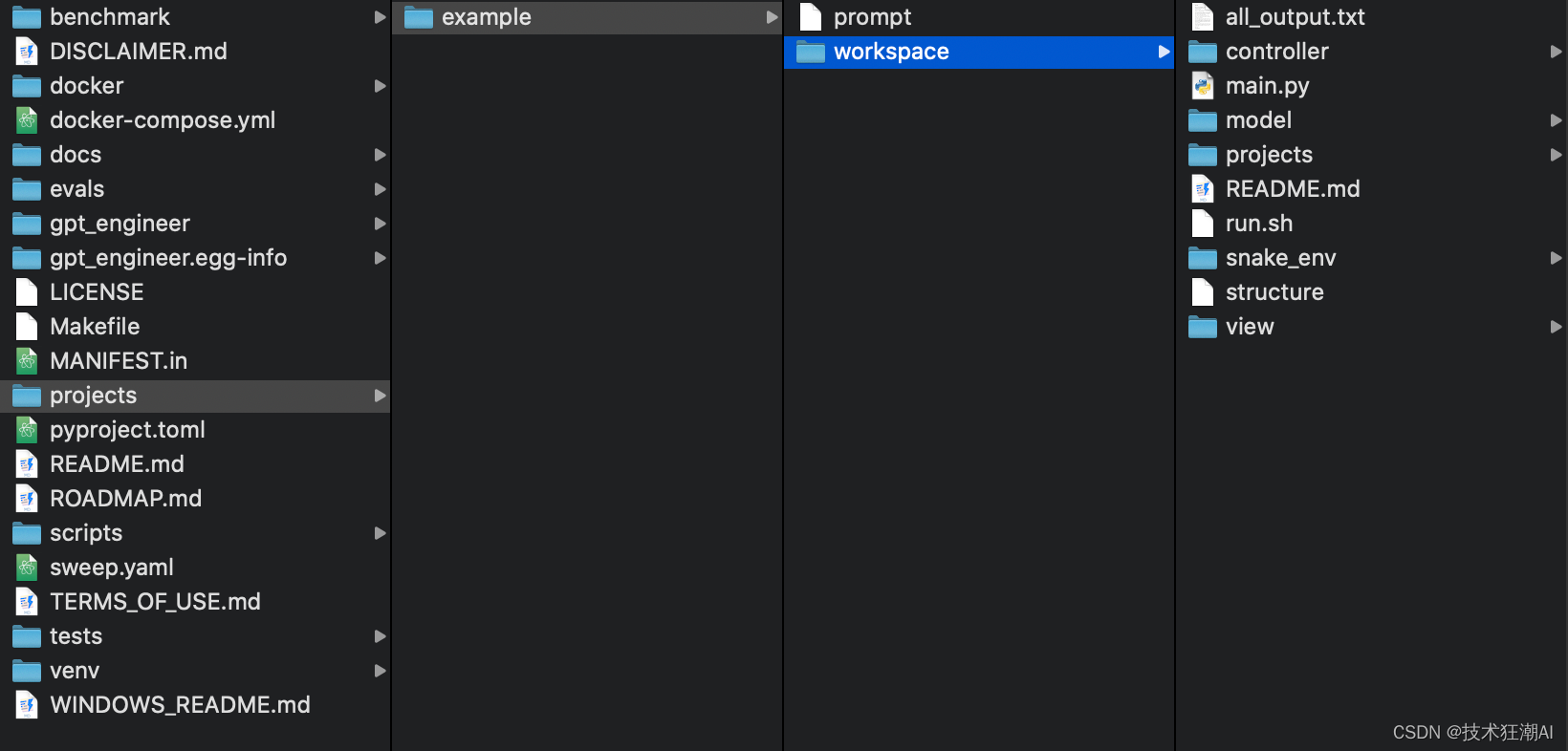
稍微等待几分钟的时间,很快我们的项目工程就生成好了,检查 projects/my-new-project/workspace 中生成的文件。
四、应用案例
首先我们需要在projects目录新建web-scraping-ainews项目文件夹,然后在项目根目录下创建prompt文本文件并添加以下的提示词。
从该网站 https://blog.csdn.net/nav/aigc-0/aigc 中抓取文章标题。文章标题位于 <span class="blog-text"> 标签内。将数据导出到 CSV 文件
最后,开始运行 gpt-engineer,我们必须使用以下命令。
gpt-engineer projects/web-scraping-ainews
由于我的文件夹被命名为“web-scraping-ainews”,因此该命令对我来说将是 gpt-engineer projects/**web-scraping-ainews** 。
执行完成后,查看生成的项目文件,所有生成的文件都将位于 projects/web-scraping-ainews/workspace 中。以下是我得到的文件。
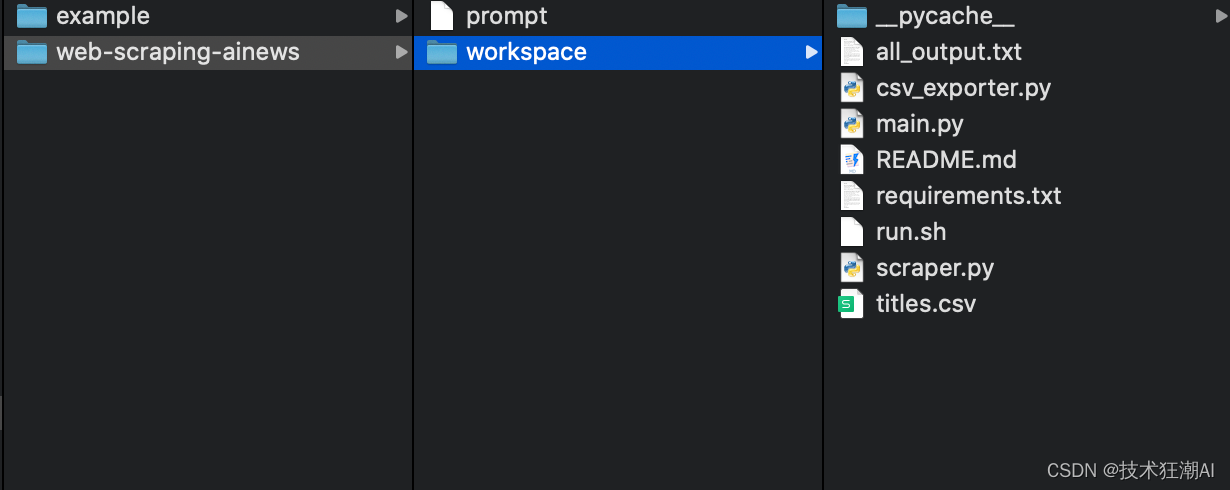
从生成的代码可以看到完整的应用程序已经生成好了,并且执行完也生成了导出的文件,查看文件发现我需要的文章标题全部导出来了。

需要注意的是,我们在执行 gpt-engineer 的时候,可能仍会遇到一些错误。
-
requirements.txt 文件可能不会生成。如果是这种情况,请复制
all_output.txt文件(应该已生成),并找到requirements.txt 部分。删除该部分中指定的库以外的所有内容。 -
如果您收到错误
openai.error.ServiceUnavailableError: The server is overloaded or not ready yet,请稍后再试,应该没问题。
虽然 gpt-engineer 生成完的程序不一定一直很完美,可能有些时候仍然需要做一些调整才能让网络应用程序运行,但 GPT-Engineer 仍然简化了整个过程,用 GPT-4 模型生成程序的可用性会更高一些。
五、总结
GPT Engineer 代表了下一代人工智能驱动的开发工具。凭借其根据提示生成整个代码库的能力及其灵活和适应性强的特性,它简化了代码生成和定制的过程。从高级提示到无缝的人机交互,GPT Engineer 使开发人员能够高效地构建和扩展他们的项目,为人工智能驱动的软件开发领域开辟了新的可能性。请随时在下面的评论部分分享您的想法和反馈。
如果你对这篇文章感兴趣,而且你想要了解更多关于AI领域的实战技巧,可以关注「技术狂潮AI」公众号。在这里,你可以看到最新最热的AIGC领域的干货文章和案例实战教程。

