
- 1MyBatisPlusDQL编程控制(条件查询、查询投影、查询条件、映射匹配兼容性)_mybatisplus xml 条件
- 2如何用Jmeter压测
- 3c++二叉树的创建及遍历(前序,中序,后序)带详细注释_c++ 前序和中序遍历构造二叉树
- 4【VSCode】关于VSCode的汉化及插件扩展配置
- 5gitlab拉取tag版本_克隆gitlab tag版本
- 6蓝桥杯A组选数异或_区间异或c++两个数组请计算有多少个区间(l,r)
- 7最新综述!预训练大模型用于医疗健康领域的全面调研
- 8PostMan一次性上传多个文件_postman上传多个文件
- 9【C++】多边形等距放大缩小,支持凹多边形_c++ 缩放多边形
- 10一些基础知识--相机与图像_相机以及图片相关知识
DPO讲解_ppo dpo
赞
踩
PPO算法的pipeline冗长,涉及模型多,资源消耗大,且训练极其不稳定。DPO是斯坦福团队基于PPO推导出的优化算法,去掉了RW训练和RL环节,只需要加载一个推理模型和一个训练模型,直接在偏好数据上进行训练即可:
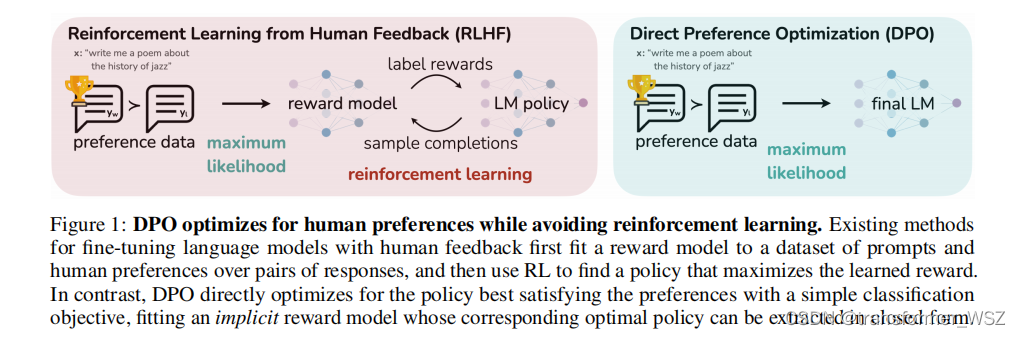
损失函数如下:
L
D
P
O
(
π
θ
;
π
r
e
f
)
=
−
E
(
x
,
y
w
,
y
l
)
∼
D
[
log
σ
(
β
log
π
θ
(
y
w
∣
x
)
π
r
e
f
(
y
w
∣
x
)
−
β
log
π
θ
(
y
l
∣
x
)
π
r
e
f
(
y
l
∣
x
)
)
]
\mathcal{L}_{\mathrm{DPO}}\left(\pi_\theta ; \pi_{\mathrm{ref}}\right)=-\mathbb{E}_{\left(x, y_w, y_l\right) \sim \mathcal{D}}\left[\log \sigma\left(\beta \log \frac{\pi_\theta\left(y_w \mid x\right)}{\pi_{\mathrm{ref}}\left(y_w \mid x\right)}-\beta \log \frac{\pi_\theta\left(y_l \mid x\right)}{\pi_{\mathrm{ref}}\left(y_l \mid x\right)}\right)\right]
LDPO(πθ;πref)=−E(x,yw,yl)∼D[logσ(βlogπref(yw∣x)πθ(yw∣x)−βlogπref(yl∣x)πθ(yl∣x))]
DPO在理解难度、实现难度和资源占用都非常友好,想看具体的公式推导见:
[论文笔记]DPO:Direct Preference Optimization: Your Language Model is Secretly a Reward Model

