
热门标签
热门文章
- 1Krpano全景制作_krpano官网
- 2了解Node.js事件循环和事件驱动模型
- 3cmd窗口输入python跳转到微软商店_命令行窗口输入python跳转到微软
- 4阶段二29_面向对象高级_IO[字节输出流FileOutputStream写数据到文件]_fileoutputstream追加写入文件
- 5Python《外星人入侵》_外星人入侵小游戏代码大全
- 6ArcGIS教程:创建散点图_arcgis如何做莫兰散点图
- 7Tkinter教程之Event篇_tkinter event
- 8基于BP算法的SAR成像matlab仿真
- 9Ant Design Vue组件中的Select 选择器实现全选/全不选功能_a-select 全选
- 10免费稳定几乎无门槛,我的ChartGPT助手免费分享给你_chart gpt免费版
当前位置: article > 正文
python实现情感分析_python情感分析
作者:繁依Fanyi0 | 2024-03-06 11:38:14
赞
踩
python情感分析
一、python实现情感分析
自然语言处理中一个很重要的研究方向是语义的情感分析(SentimentAnalysis),情感分析是指通过对给定文本的词性分析,判断该文本是消极的还是积极的过程。当然,在某些特定场景中,也会加入“中性”这个选项。
情感分析的应用场最也非常广泛,在购物网站或者微博中,人们会发表评论,淡论集商品、事件或人物。商家可以利用情感分析工具知道用户对自己的产品的使用体验和评价。当需要大规模的情感分析时,肉眼的处理能力就变得十分有限了。情感分析的本质就是根据已知的文字和情感符号.推测文字是正面的还是负面的。处理好情感分析,可以大大提高人们对于事物的理解效率,也可以利用情感分析的结论为其他人或事物服务。例如,不少基金公司利用人们对于某家公司、某个行业、某件事情的看法态度来预测未来股票的涨跌。
下面将使用NLTK模块中的朴素贝叶斯分类器来进行情感分析,实现文档的分类。在特征提取函数中,我们提取了所有的词。但是,NLTK分类器的输入数据格式为字典格式,因此,我们要先创建字典格式的数据,以便NLTK分类器可以使用这些数据。同时,在创建完字典型数据后,我们要将数据分成训练数据集和测试数据集.目的是使用训练数据训练我们的分类器,以便分类器可以将数据分类为积极与消极。当我们查看哪些单词包含的信息量最大,也就是最能体现其情感的单词的时候,会发现有些单词表示积极情感(如out-standing),有些单词表示消极 情感(如isutin .这是非常有意义的信息。
二、使用步骤
1.引入库
代码如下():
import random
import numpy as np
import csv
import jieba
import re
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.pipeline import Pipeline
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2.读入数据
代码如下:
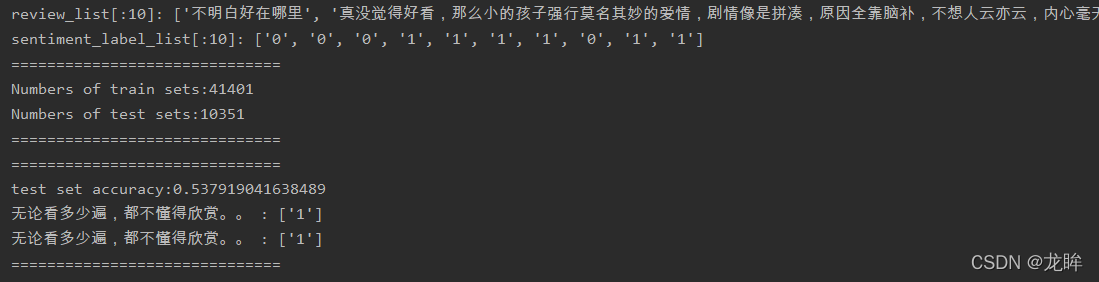
import random import numpy as np import csv import jieba import re from sklearn.feature_extraction.text import CountVectorizer from sklearn.pipeline import Pipeline from sklearn.naive_bayes import MultinomialNB from sklearn.model_selection import train_test_split jieba.setLogLevel(jieba.logging.INFO) # 电影评论数据集 file_path = 'review.csv' # 用户自定义字典 userdict = "userdict.txt" # 停用词 stopword_path = 'stopwords.txt' # 加载用户自定义字典 jieba.load_userdict(userdict) # 加载语料库 def load_file_to_list(file_path): with open(file_path,'r',encoding='utf8') as f: reader = csv.reader(f) rows = [row for row in reader] # 将语料库转换为list review_data = np.array(rows).tolist() # 对语料库执行洗牌操作 random.seed(100) random.shuffle(review_data) # 定义评论列表 review_list = [] # 定义情感标签列表 sentiment_label_list = [] # 填充评论列表和情感标签列表 for words in review_data: review_list.append(words[1]) sentiment_label_list.append(words[0]) # 返回评论列表和情感标签列表 return review_list,sentiment_label_list # 获取评论列表和情感标签列表 review_list,sentiment_label_list = load_file_to_list(file_path) # 输出top10评论,输出top10情感标签 print('review_list[:10]:',review_list[:10]) print('sentiment_label_list[:10]:',sentiment_label_list[:10]) print('='*30) # 分割训练测试集 train_review_list,test_review_list,train_sentiment_label_list,test_sentiment_label_list=\ train_test_split(review_list,sentiment_label_list,test_size=0.2,random_state=0) # 输出训练集测试集的大小 print('Numbers of train sets:{}'.format(str(len(train_review_list)))) print('Numbers of test sets:{}'.format(str(len(test_review_list)))) print('='*30) # 加载停用词 def load_stopwords(file_path): stop_words = [] with open(file_path,encoding='UTF-8') as words: stop_words.extend([i.strip() for i in words.readlines()]) return stop_words # 对评论进行分词 def review_to_text(review): stop_words = load_stopwords(stopword_path) # 移除英文字符 review = re.sub("[^\u4e00-\u9fa5^a-z^A-Z]",'',review) # 使用jieba切分评论 review = jieba.cut(review) # 移除停用词 if stop_words: all_stop_words =set(stop_words) words = [w for w in review if w not in all_stop_words] # 返回分词结果 return words # 训练集评论 review_train = [''.join(review_to_text(review)) for review in train_review_list] # 训练集标签 sentiment_label_train = train_sentiment_label_list # 测试集评论 review_test = [''.join(review_to_text(review)) for review in test_review_list] # 测试集标签 sentiment_label_test = test_sentiment_label_list # 将分词转换成词频矩阵 count_vec = CountVectorizer(max_df=0.8,min_df=3) # 定义管道 def bayes_Classifier(): return Pipeline([ ('count_vec',CountVectorizer()), ('mnb',MultinomialNB()) ]) # 实例化分类器 bayes_clf = bayes_Classifier() # 训练模型 bayes_clf.fit(review_train,sentiment_label_train) print('='*30) # 测试集精度 print('test set accuracy:{}'.format(bayes_clf.score(review_test,sentiment_label_test))) strpre = '无论看多少遍,都不懂得欣赏。。' strpre1 = '很好看的一部电影' prelabel = bayes_clf.predict([''.join(review_to_text(strpre))]) prelabel1 = bayes_clf.predict([''.join(review_to_text(strpre1))]) # 输出指定评论的情感分析结果 print(strpre,':',prelabel) print(strpre,':',prelabel1) print('='*30)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
#运行结果
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/198478?site
推荐阅读

相关标签

