
- 1unity最新毛发系统Wig,更有利于高逼真数字人实现_unity3d 毛发系统
- 2Ai创作系统源码的原理是什么?如何开发一套属于企业私有的AIGC工具_ai源码系统
- 3移动端开发知识梳理_移动端小程序开发基础
- 4一张纸对折多少次后能达到珠穆朗玛峰的高度_给一张概念性的纸,可多次对折。计算对折多少次后高度超珠穆朗玛峰的高度?
- 5一般什么情况下使用 | tojson转换
- 6基于微信小程序的校园社团活动管理系统设计与实现_微信小程序 校园活动管理
- 7【从入门到精通】Android稳定性优化深入解析_csdn android稳定性
- 8大数据采集技术有哪些_大数据采集技术中从数据库中获取
- 9华为鸿蒙系统HarmonyOS学习之十一:华为个人开发者账号注册步骤及方法_华为开发认证
- 10springboot入门_java restcontroller import
YOLOv9 | 利用yolov9训练自己的数据集 -> 推理、验证(源码解读 + 手撕结构图)
赞
踩
一、本文介绍
本文给大家带来的是全新的SOTA模型YOLOv9的基础使用教程,需要注意的是YOLOv9发布时间为2024年2月21日,截至最近的日期也没有过去几天,从其实验结果上来看,其效果无论是精度和参数量都要大于过去的一些实时检测模型,其主要创新点是两个分别是提出了Programmable Gradient Information(PGI)的结构以及全新的主干Generalized ELAN(GELAN)下面本文就手把手带大家来教大家如何使用自定义数据集训练YOLOv9模型,以及如何搭建环境,获取数据集/训练/推理/验证/导出/调参,下面的图片为YOLO系列的时间轴。

目录
2.1 Programmable Gradient Information/可编程梯度信息
2.1.1 Auxiliary Reversible Branch/辅助可逆分支
2.1.2 Multi-level Auxiliary Information/多级辅助信息
二、 模型介绍
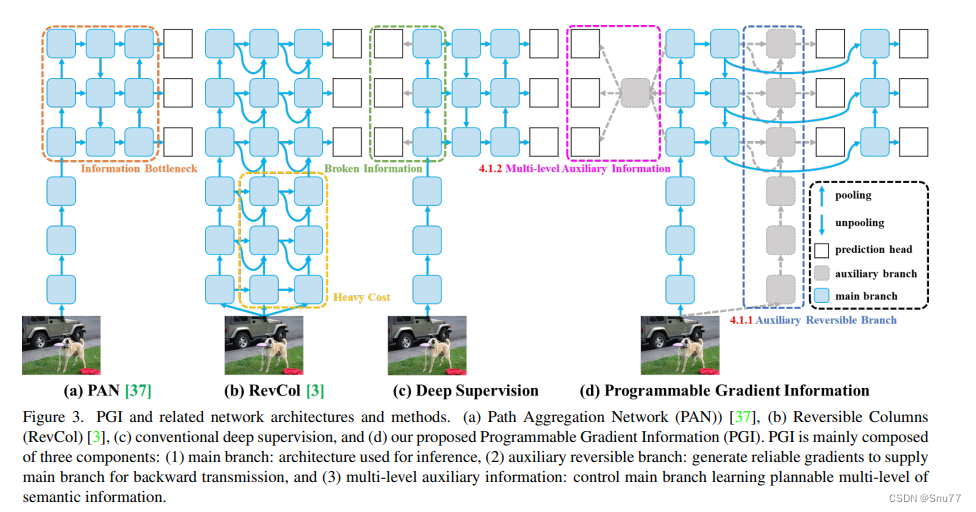
这张图(图3)展示了可编程梯度信息(PGI)及其相关网络架构和方法。图中展示了四种不同的网络设计:
a) PAN (Path Aggregation Network):这种网络结构主要用于改进特征融合,以提高目标检测的性能。然而,由于信息瓶颈的存在,网络中可能会丢失一些信息。
b) RevCol (Reversible Columns):这是一种旨在减少信息丢失的网络设计。它通过可逆的列结构来尝试维持信息流通不受损失,但如图中“Heavy Cost”所示,这种结构会增加计算成本。
c) 深度监督:这种方法通过在网络的多个层次中插入额外的监督信号来提高学习的效率和最终模型的性能。图中显示了通过深度监督连接的各个层。
d) 可编程梯度信息 (PGI):PGI是作者提出的一种新方法(我理解的这种方法就是在前向传播的过程中没有跳级链接),它主要由三个部分组成:
1. 主分支:用于推理的架构。
2. 辅助可逆分支:生成可靠的梯度,以供给主分支进行反向传播。
3. 多级辅助信息:控制主分支学习可规划的多级语义信息。PGI的目的是通过辅助可逆分支(如图中虚线框所示)来解决信息瓶颈问题,以便在不增加推理成本的情况下为深度网络提供更可靠的梯度。通过这种设计,即使是轻量级和浅层的神经网络也可以实现有效的信息保留和准确的梯度更新。如图中的深色方框所示的主分支,通过辅助可逆分支提供的可靠梯度信息,可以获得更有效的目标任务特征,而不会因为信息瓶颈而损失重要信息。
图中的符号代表不同的操作:灰色圆形代表池化操作,白色圆形代表上采样操作,灰色方块代表预测头,蓝色方块代表辅助分支,深色方块代表主分支。这种设计允许网络在保持高效计算的同时,也能够处理复杂的目标检测任务。
2.1 Programmable Gradient Information/可编程梯度信息
为了解决前述问题,我们提出了一种新的辅助监督框架,称为可编程梯度信息(PGI),如图3(d)所示。PGI主要包括三个部分,即(1)主分支,(2)辅助可逆分支和(3)多级辅助信息。从图3(d)我们可以看到,PGI的推理过程只使用主分支,因此不需要任何额外的推理成本。至于其他两个部分,它们用于解决或减缓深度学习方法中的几个重要问题。其中,辅助可逆分支旨在处理由神经网络加深造成的问题。网络加深将导致信息瓶颈,这将使得损失函数无法生成可靠的梯度。至于多级辅助信息,它旨在处理由深度监督造成的误差累积问题,特别是对于具有多个预测分支的架构和轻量型模型。接下来,我们将逐步介绍这两个部分。
2.1.1 Auxiliary Reversible Branch/辅助可逆分支
在PGI中,我们提出了辅助可逆分支来生成可靠的梯度并更新网络参数。通过提供从数据到目标的映射信息,损失函数可以提供指导,并避免从与目标关系较小的不完整前馈特征中找到错误相关性的可能性。我们提出通过引入可逆架构来维持完整信息,但在可逆架构中添加主分支将消耗大量的推理成本。我们分析了图3(b)的架构,并发现在深层到浅层添加额外连接时,推理时间将增加20%。当我们反复将输入数据添加到网络的高分辨率计算层(黄色框),推理时间甚至超过了两倍。
由于我们的目标是使用可逆架构来获取可靠的梯度,因此“可逆”并不是推理阶段的唯一必要条件。鉴于此,我们将可逆分支视为深度监督分支的扩展,并设计了如图3(d)所示的辅助可逆分支。至于主分支,由于信息瓶颈可能会丢失重要信息的深层特征,将能够从辅助可逆分支接收可靠的梯度信息。这些梯度信息将推动参数学习,以帮助提取正确和重要的信息,并使主分支能够获取更有效的目标任务特征。此外,由于复杂任务需要在更深的网络中进行转换,可逆架构在浅层网络上的表现不如在一般网络上。我们提出的方法不强迫主分支保留完整的原始信息,而是通过辅助监督机制生成有用的梯度来更新它。这种设计的优势是,所提出的方法也可以应用于较浅的网络。最后,由于辅助可逆分支可以在推理阶段移除,因此可以保留原始网络的推理能力。我们还可以在PGI中选择任何可逆架构来充当辅助可逆分支的角色。
2.1.2 Multi-level Auxiliary Information/多级辅助信息
在本节中,我们将讨论多级辅助信息是如何工作的。包含多个预测分支的深度监督架构如图3(c)所示。对于对象检测,可以使用不同的特征金字塔来执行不同的任务,例如它们可以一起检测不同大小的对象。因此,连接到深度监督分支后,浅层特征将被引导学习小对象检测所需的特征,此时系统将将其他大小的对象位置视为背景。然而,上述行为将导致深层特征金字塔丢失很多预测目标对象所需的信息。对于这个问题,我们认为每个特征金字塔都需要接收所有目标对象的信息,以便后续主分支能够保留完整信息来学习对各种目标的预测。
多级辅助信息的概念是在辅助监督的特征金字塔层之间和主分支之间插入一个集成网络,然后使用它来结合不同预测头返回的梯度,如图3(d)所示。然后,多级辅助信息将汇总包含所有目标对象的梯度信息,并将其传递给主分支然后更新参数。此时,主分支的特征金字塔层次的特性不会被某些特定对象的信息所主导。因此,我们的方法可以缓解深度监督中的断裂信息问题。此外,任何集成网络都可以在多级辅助信息中使用。因此,我们可以规划所需的语义级别来指导不同大小的网络架构的学习。
2.2 Generalized ELAN
在本节中,我们描述了提出的新网络架构 - GELAN。通过结合两种神经网络架构CSPNet和ELAN,这两种架构都是以梯度路径规划设计的,我们设计了考虑了轻量级、推理速度和准确性的广义高效层聚合网络(GELAN)。其整体架构如图4所示。我们推广了ELAN的能力,ELAN原本只使用卷积层的堆叠,到一个新的架构,可以使用任何计算块。
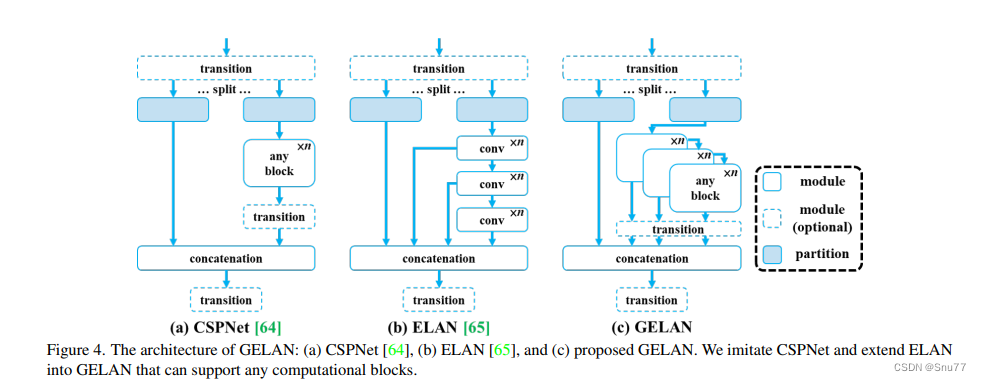
这张图(图4)展示了广义高效层聚合网络(GELAN)的架构,以及它是如何从CSPNet和ELAN这两种神经网络架构演变而来的。这两种架构都设计有梯度路径规划。
a) CSPNet:在CSPNet的架构中,输入通过一个转换层被分割为两部分,然后分别通过任意的计算块。之后,这些分支被重新合并(通过concatenation),并再次通过转换层。
b) ELAN:与CSPNet相比,ELAN采用了堆叠的卷积层,其中每一层的输出都会与下一层的输入相结合,再经过卷积处理。
c) GELAN:结合了CSPNet和ELAN的设计,提出了GELAN。它采用了CSPNet的分割和重组的概念,并在每一部分引入了ELAN的层级卷积处理方式。不同之处在于GELAN不仅使用卷积层,还可以使用任何计算块,使得网络更加灵活,能够根据不同的应用需求定制。
GELAN的设计考虑到了轻量化、推理速度和精确度,以此来提高模型的整体性能。图中显示的模块和分区的可选性进一步增加了网络的适应性和可定制性。GELAN的这种结构允许它支持多种类型的计算块,这使得它可以更好地适应各种不同的计算需求和硬件约束。
总的来说,GELAN的架构是为了提供一个更加通用和高效的网络,可以适应从轻量级到复杂的深度学习任务,同时保持或增强计算效率和性能。通过这种方式,GELAN旨在解决现有架构的限制,提供一个可扩展的解决方案,以适应未来深度学习的发展。
大家看图片一眼就能看出来它融合了什么,就是将CSPHet的anyBlock模块堆叠的方式和ELAN融合到了一起。
2.2.1 Generalized ELAN结构图
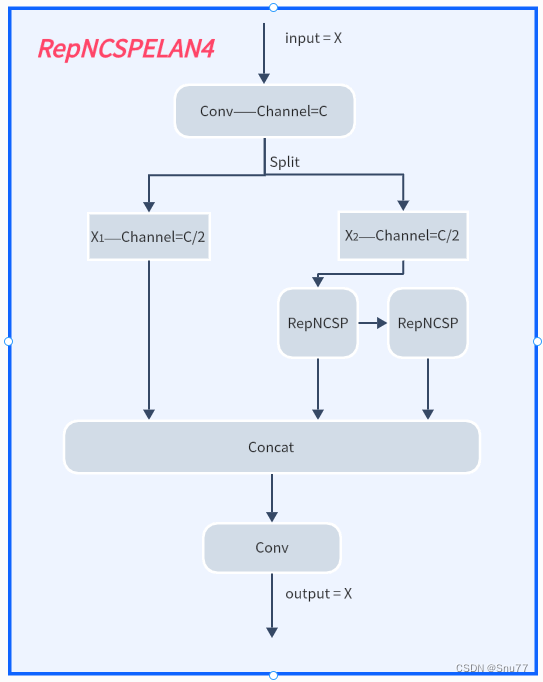
YOLOv9最主要的创新目前能够得到的就是其中的GELAN结构,我也是分析其代码根据论文将其结构图绘画出来。
下面的文件为YOLOv9的yaml文件。可以看到的是其提出了一种结构名字RepNCSPELAN4,其中的结构图concat后的通道数我没有画是因为它有计算中间的参数的变量是根据个人设置来的。
- # YOLOv9
-
- # parameters
- nc: 80 # number of classes
- depth_multiple: 1.0 # model depth multiple
- width_multiple: 1.0 # layer channel multiple
- #activation: nn.LeakyReLU(0.1)
- #activation: nn.ReLU()
-
- # anchors
- anchors: 3
-
- # gelan backbone
- backbone:
- [
- # conv down
- [-1, 1, Conv, [64, 3, 2]], # 0-P1/2
-
- # conv down
- [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
-
- # elan-1 block
- [-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 2
-
- # avg-conv down
- [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 4
-
- # avg-conv down
- [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 6
-
- # avg-conv down
- [-1, 1, Conv, [512, 3, 2]], # 7-P5/32
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 8
- ]
-
- # gelan head
- head:
- [
- # elan-spp block
- [-1, 1, SPPELAN, [512, 256]], # 9
-
- # up-concat merge
- [-1, 1, nn.Upsample, [None, 2, 'nearest']],
- [[-1, 6], 1, Concat, [1]], # cat backbone P4
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 12
-
- # up-concat merge
- [-1, 1, nn.Upsample, [None, 2, 'nearest']],
- [[-1, 4], 1, Concat, [1]], # cat backbone P3
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 15 (P3/8-small)
-
- # avg-conv-down merge
- [-1, 1, Conv, [256, 3, 2]],
- [[-1, 12], 1, Concat, [1]], # cat head P4
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 18 (P4/16-medium)
-
- # avg-conv-down merge
- [-1, 1, Conv, [512, 3, 2]],
- [[-1, 9], 1, Concat, [1]], # cat head P5
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 21 (P5/32-large)
-
- # detect
- [[15, 18, 21], 1, DDetect, [nc]], # Detect(P3, P4, P5)
- ]

其代码和结构图如下所示!
- class RepNCSPELAN4(nn.Module):
- # csp-elan
- def __init__(self, c1, c2, c5=1): # c5 = repeat
- super().__init__()
- c3 = int(c2 / 2)
- c4 = int(c3 / 2)
- self.c = c3 // 2
- self.cv1 = Conv(c1, c3, 1, 1)
- self.cv2 = nn.Sequential(RepNCSP(c3 // 2, c4, c5), Conv(c4, c4, 3, 1))
- self.cv3 = nn.Sequential(RepNCSP(c4, c4, c5), Conv(c4, c4, 3, 1))
- self.cv4 = Conv(c3 + (2 * c4), c2, 1, 1)
-
- def forward(self, x):
- y = list(self.cv1(x).chunk(2, 1))
- y.extend((m(y[-1])) for m in [self.cv2, self.cv3])
- return self.cv4(torch.cat(y, 1))
-
- def forward_split(self, x):
- y = list(self.cv1(x).split((self.c, self.c), 1))
- y.extend(m(y[-1]) for m in [self.cv2, self.cv3])
- return self.cv4(torch.cat(y, 1))
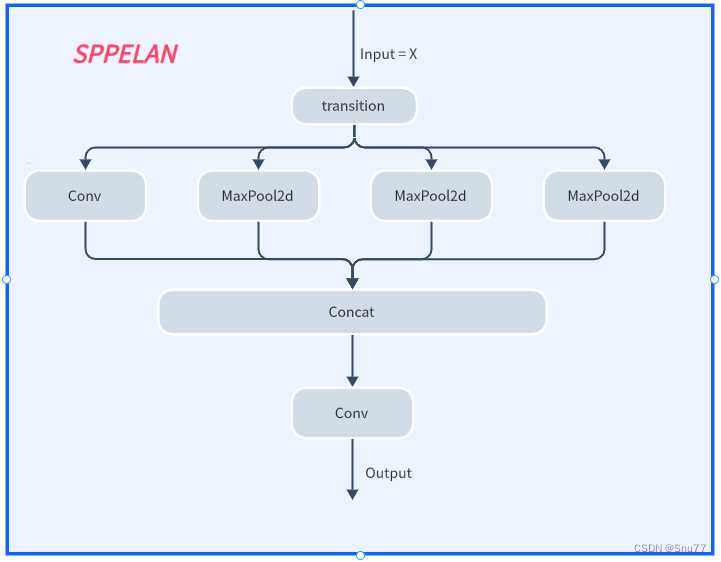
2.3 SPPELAN结构图
其还提出了以结构名为SPPELAN的空间金字塔池化结构,其结构图和代码如下所示!
- class SP(nn.Module):
- def __init__(self, k=3, s=1):
- super(SP, self).__init__()
- self.m = nn.MaxPool2d(kernel_size=k, stride=s, padding=k // 2)
-
- def forward(self, x):
- return self.m(x)
-
-
- class SPPELAN(nn.Module):
- # spp-elan
- def __init__(self, c1, c2, c3): # ch_in, ch_out, number, shortcut, groups, expansion
- super().__init__()
- self.c = c3
- self.cv1 = Conv(c1, c3, 1, 1)
- self.cv2 = SP(5)
- self.cv3 = SP(5)
- self.cv4 = SP(5)
- self.cv5 = Conv(4*c3, c2, 1, 1)
-
- def forward(self, x):
- y = [self.cv1(x)]
- y.extend(m(y[-1]) for m in [self.cv2, self.cv3, self.cv4])
- return self.cv5(torch.cat(y, 1))
下面的链接为YOLOv9的论文解析部分,大家感兴趣的可以看看,全文1.5W字手把手带你学习YOLOv9。
YOLOv9改进 | 一文带你了解全新的SOTA模型YOLOv9(论文阅读笔记,效果完爆YOLOv8)
三、环境搭建
环境搭建的事情也不再本文的说了,我写过教程了,大家点击下面的地址就可以如果你不会搭建Pytorch的地址下面的文章会帮助到你。
跳转地址:Win11上Pytorch的安装并在Pycharm上调用PyTorch最新超详细过程并附详细的系统变量添加过程,可解决pycharm中pip不好使的问题
四、模型获取
4.1 模型下载
YOLOv9已经开源在Github上了,地址如下->
官方论文地址: 官方论文地址点击即可跳转
官方代码地址: 官方代码地址点击即可跳转
针对没有链接Github的读者,我也将其上传到了CSDN平台,大家可以通过下面的链接进行下载。
CSDN地址:YOLOv9CSDN下载链接
4.2 安装依赖
我们下载完模型之后通过各种IDEA打开之后,都会有终端操作的命令行,我们只需要通过命令安装所需要的依赖即可。
pip install requirements.txt
五、数据集获取
在我们开始训练之前,我们需要一份数据集,如何获取一个YOLOv8的数据集大家可以看我的另一篇博客从YOLO官方指定的数据集网站Roboflow下载数据模型训练
超详细教程YoloV8官方推荐免费数据集网站Roboflow一键导出Voc、COCO、Yolo、Csv等格式
我在上面随便下载了一个 数据集用它导出yolov8的数据集,以及自动给转换成txt的格式yaml文件也已经配置好了,我们直接用就可以。
六、模型训练
6.1 项目分析
YOLOv9的模型训练比较特殊,它的检测头分为好几种训练的方式也不同,同时其因为刚刚发布,模型中的Bug有许多,下面的图片大家可以看到YOLOv9给了三个训练文件分别对应着。
train:主分支
train_dual:一个辅助分支+一个主分支。
triple_branch:2个辅助分支+1个主分支

YOLOv9的yaml文件,(同时需要注意YOLOv9和v7一样不支持修改模型的深度和宽度参数,也就是下面两个为1.0的地方)!
- # YOLOv9
-
- # parameters
- nc: 80 # number of classes
- depth_multiple: 1.0 # model depth multiple
- width_multiple: 1.0 # layer channel multiple
- #activation: nn.LeakyReLU(0.1)
- #activation: nn.ReLU()
-
- # anchors
- anchors: 3
-
- # YOLOv9 backbone
- backbone:
- [
- [-1, 1, Silence, []],
- # conv down
- [-1, 1, Conv, [64, 3, 2]], # 1-P1/2
- # conv down
- [-1, 1, Conv, [128, 3, 2]], # 2-P2/4
- # elan-1 block
- [-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 3
- # conv down
- [-1, 1, Conv, [256, 3, 2]], # 4-P3/8
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 5
- # conv down
- [-1, 1, Conv, [512, 3, 2]], # 6-P4/16
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 7
- # conv down
- [-1, 1, Conv, [512, 3, 2]], # 8-P5/32
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 9
- ]
-
- # YOLOv9 head
- head:
- [
- # elan-spp block
- [-1, 1, SPPELAN, [512, 256]], # 10
-
- # up-concat merge
- [-1, 1, nn.Upsample, [None, 2, 'nearest']],
- [[-1, 7], 1, Concat, [1]], # cat backbone P4
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 13
-
- # up-concat merge
- [-1, 1, nn.Upsample, [None, 2, 'nearest']],
- [[-1, 5], 1, Concat, [1]], # cat backbone P3
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 16 (P3/8-small)
-
- # conv-down merge
- [-1, 1, Conv, [256, 3, 2]],
- [[-1, 13], 1, Concat, [1]], # cat head P4
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 19 (P4/16-medium)
-
- # conv-down merge
- [-1, 1, Conv, [512, 3, 2]],
- [[-1, 10], 1, Concat, [1]], # cat head P5
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 22 (P5/32-large)
-
- # routing
- [5, 1, CBLinear, [[256]]], # 23
- [7, 1, CBLinear, [[256, 512]]], # 24
- [9, 1, CBLinear, [[256, 512, 512]]], # 25
-
- # conv down
- [0, 1, Conv, [64, 3, 2]], # 26-P1/2
-
- # conv down
- [-1, 1, Conv, [128, 3, 2]], # 27-P2/4
-
- # elan-1 block
- [-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 28
-
- # conv down fuse
- [-1, 1, Conv, [256, 3, 2]], # 29-P3/8
- [[23, 24, 25, -1], 1, CBFuse, [[0, 0, 0]]], # 30
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 31
-
- # conv down fuse
- [-1, 1, Conv, [512, 3, 2]], # 32-P4/16
- [[24, 25, -1], 1, CBFuse, [[1, 1]]], # 33
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 34
-
- # conv down fuse
- [-1, 1, Conv, [512, 3, 2]], # 35-P5/32
- [[25, -1], 1, CBFuse, [[2]]], # 36
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 37
-
- # detect
- [[31, 34, 37, 16, 19, 22], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)
- ]
YOLOv9-GELAN版本yaml文件!
- # YOLOv9
-
- # parameters
- nc: 80 # number of classes
- depth_multiple: 1.0 # model depth multiple
- width_multiple: 1.0 # layer channel multiple
- #activation: nn.LeakyReLU(0.1)
- #activation: nn.ReLU()
-
- # anchors
- anchors: 3
-
- # gelan backbone
- backbone:
- [
- # conv down
- [-1, 1, Conv, [64, 3, 2]], # 0-P1/2
-
- # conv down
- [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
-
- # elan-1 block
- [-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 2
-
- # avg-conv down
- [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 4
-
- # avg-conv down
- [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 6
-
- # avg-conv down
- [-1, 1, Conv, [512, 3, 2]], # 7-P5/32
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 8
- ]
-
- # gelan head
- head:
- [
- # elan-spp block
- [-1, 1, SPPELAN, [512, 256]], # 9
-
- # up-concat merge
- [-1, 1, nn.Upsample, [None, 2, 'nearest']],
- [[-1, 6], 1, Concat, [1]], # cat backbone P4
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 12
-
- # up-concat merge
- [-1, 1, nn.Upsample, [None, 2, 'nearest']],
- [[-1, 4], 1, Concat, [1]], # cat backbone P3
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 15 (P3/8-small)
-
- # avg-conv-down merge
- [-1, 1, Conv, [256, 3, 2]],
- [[-1, 12], 1, Concat, [1]], # cat head P4
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 18 (P4/16-medium)
-
- # avg-conv-down merge
- [-1, 1, Conv, [512, 3, 2]],
- [[-1, 9], 1, Concat, [1]], # cat head P5
-
- # elan-2 block
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 21 (P5/32-large)
-
- # detect
- [[15, 18, 21], 1, DDetect, [nc]], # Detect(P3, P4, P5)
- ]
大家可以对比下上面的两个yaml文件,其实就可以看到Dual版本的yaml文件就是在DDetect版本的yaml文件基础上又扩充了Neck部分, 在Dual的yaml文件开头多了Silence一个操作,这个位置的意义是由于双主干从而进行涉及的(这种结构非常的巧妙,大家如果想要用双主干可以学习下这种方式),所以DDetect和DualDetect的yaml文件在21层之前的操作其实是一模一样的(和YOLOv8也一样只是替换了C2f为RepNCSPELAN4)。
6.2 参数解析
正题开始,我们来讲如何开始训练模型这里我们以train.py为例开始进行训练,具体寻方法看下图我们先配置好地址。
(下面的参数就是我的填写的,再次强调train.py只能运行检测头的DDetect的文件!!)
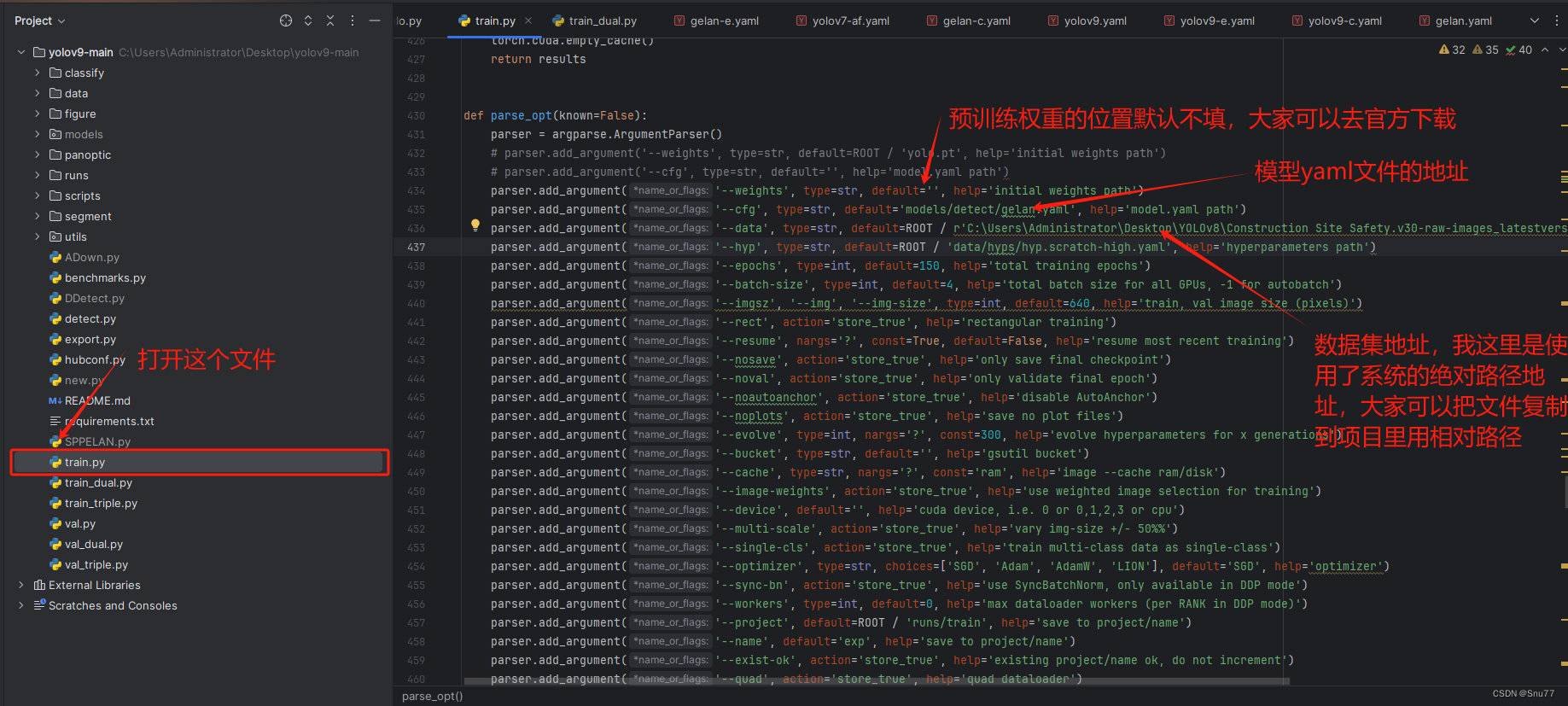
除此之外配置好上面的三个参数之后,还有几个参数需要配置,
| 参数名 | 参数类型 | 参数解析 | |
|---|---|---|---|
| 0 | hyp | str | 这个位置是超参数的地址,目前存在一个Bug就是其没有提供data/hyps/hyp.scratch-low.yaml文件,但是它默认填写的是这个文件地址,所以我们需要将其改为data/hyps/hyp.scratch-high.yaml才可以运行,后面估计会修复这个问题。 |
| 1 | batch-size | int | 批次的大小,大家需要根据自己的显存来设置,如果显存超了会报内存错误关键词是'memory' |
| 2 | workers | int | 显存设置的参数,如果你是Linux系统那么根据你的CPU能力可以随便设置,但是如果你是Windows系统如果设置大了或者设置了都会报错所以建议大家设置为0此处默认为8(Windows想要强行设置就需要设置大量的虚拟内存估计50G起步)。 |
其余的参数解析大家可以看下面的代码,我都已经标注了,上面仅列出了一些影响模型学习的超参数。
- def parse_opt(known=False):
- parser = argparse.ArgumentParser()
- # parser.add_argument('--weights', type=str, default=ROOT / 'yolo.pt', help='initial weights path')
- # parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
- parser.add_argument('--weights', type=str, default='', help='权重初始化的路径,在这里面设置权重的地址')
- parser.add_argument('--cfg', type=str, default='models/detect/gelan.yaml', help='模型的配置文件,我们可以根据自己需求配置yaml文件')
- parser.add_argument('--data', type=str, default=ROOT / r'', help='大家的数据集yaml文件的地址')
- parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-high.yaml', help='用于指定超参数文件,大家根据这个地址就能够找到一个yaml文件里面配置了各种超参数')
- parser.add_argument('--epochs', type=int, default=150, help='训练的轮次')
- parser.add_argument('--batch-size', type=int, default=4, help='训练的批次大小,决定了一次向模型里输入多少张图片')
- parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='输入模型里的图像尺寸,YOLO系列默认都是640')
- parser.add_argument('--rect', action='store_true', help='矩形训练或验证。矩形训练或验证是一种数据处理技术,其中在训练或验证过程中,输入数据会被调整为具有相同宽高比的矩形形状')
- parser.add_argument('--resume', nargs='?', const=True, default=False, help='这个如果设置为True,那么会根据你最新一次没有训练完成的权重进行继续完成训练')
- parser.add_argument('--nosave', action='store_true', help='只保存之后一次训练的权重文件地址,即我们得到的那个权重,默认是这样!')
- parser.add_argument('--noval', action='store_true', help='当设置时,只在最后一个周期(epoch)进行验证,而不是在每个周期都进行')
- parser.add_argument('--noautoanchor', action='store_true', help='当设置时,禁用自动锚定(AutoAnchor)')
- parser.add_argument('--noplots', action='store_true', help='当设置时,不保存任何绘图文件,就是我们runs下面的训练结果')
- parser.add_argument('--evolve', type=int, nargs='?', const=300, help='允许超参数的进化优化,参数是进化的代数。')
- parser.add_argument('--bucket', type=str, default='', help='指定一个gsutil存储桶的路径')
- parser.add_argument('--cache', type=str, nargs='?', const='ram', help='设置图像缓存方式,可以是内存(ram)或磁盘(disk),默认是内存')
- parser.add_argument('--image-weights', action='store_true', help='使用加权图像选择进行训练,简单的说就是,处理一些复杂或不平衡的数据集')
- parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu, 这个不在多说了,我们的GPU设备号')
- parser.add_argument('--multi-scale', action='store_true', help='当设置时,图像大小会在训练过程中变化,上下浮动50%')
- parser.add_argument('--single-cls', action='store_true', help='当设置时,将多类别数据作为单类别数据训练,一般都设置为False')
- parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW', 'LION'], default='SGD', help='优化器的选择,默认为SGD')
- parser.add_argument('--sync-bn', action='store_true', help='当设置时,使用同步批处理归一化(SyncBatchNorm)')
- parser.add_argument('--workers', type=int, default=0, help='工作的线程,Linux系统可以设置,Windows系统必须设置0否则会导致各种问题')
- parser.add_argument('--project', default=ROOT / 'runs/train', help='设置项目保存路径,就是我们训练结果保存的地方')
- parser.add_argument('--name', default='exp', help='保存的项目名称,类似于runs/train/exp/一堆我们训练的结果')
- parser.add_argument('--exist-ok', action='store_true', help='当设置时,如果项目/名称已存在则不会报错,不会自动增加编号')
- parser.add_argument('--quad', action='store_true', help='使用四边形数据加载器, 这些默认都是开启的')
- parser.add_argument('--cos-lr', action='store_true', help='使用余弦学习率调度器, 这些默认都是开启的')
- parser.add_argument('--flat-cos-lr', action='store_true', help='启用一个平坦余弦学习率调度器(Flat Cosine Learning Rate Scheduler')
- parser.add_argument('--fixed-lr', action='store_true', help='启用一个固定学习率调度器(Fixed Learning Rate Scheduler)')
- parser.add_argument('--label-smoothing', type=float, default=0.0, help='参数是用来设置标签平滑的 epsilon 值的,用来提高模型的泛化能力')
- parser.add_argument('--patience', type=int, default=100, help='早停机制,损失超过多少个回合变化的较小就停止训练')
- parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='用于在神经网络训练过程中“冻结”(freeze)一部分层。冻结的意思是在训练过程中保持这些层的权重不变,不对它们进行更新.')
- parser.add_argument('--save-period', type=int, default=-1, help='每隔x个周期保存一次检查点,如果小于1则禁用')
- parser.add_argument('--seed', type=int, default=0, help='训练的随机数种子,计算机其实是没有随机数的,都是根据随机数种子来演变出来的随机数')
- parser.add_argument('--local_rank', type=int, default=-1, help='自动设置用于多GPU DDP训练的局部排名,通常不需要手动修改')
- parser.add_argument('--min-items', type=int, default=0, help='目前还不知道这个参数的含义')
- parser.add_argument('--close-mosaic', type=int, default=0, help='关闭mosaic数据增强的参数,比如设置0则不关闭mosaic数据增强如果设置10则在训练后10轮关闭mosaic增强')
-
- # Logger arguments
- parser.add_argument('--entity', default=None, help='设置实体,用于日志记录')
- parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='设置是否上传数据集,如果指定“val”,则上传验证集')
- parser.add_argument('--bbox_interval', type=int, default=-1, help='设置边界框图像记录间隔')
- parser.add_argument('--artifact_alias', type=str, default='latest', help='设置要使用的数据集工件的版本,默认为latest')
-
- return parser.parse_known_args()[0] if known else parser.parse_args()
6.3 正式训练
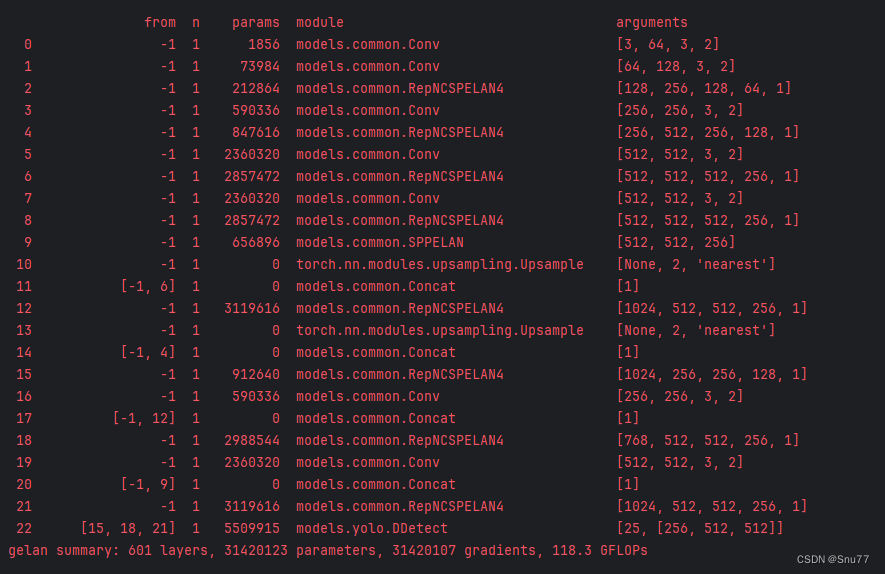
下面我们来正式开始训练,我们填好各项参数配置之后,就可以运行train.py文件了,模型就会开始训练(在此之前大需要配置好环境,安装好依赖,以及拥有一个数据集文件),下面是正式训练之后的控制台输出截图。

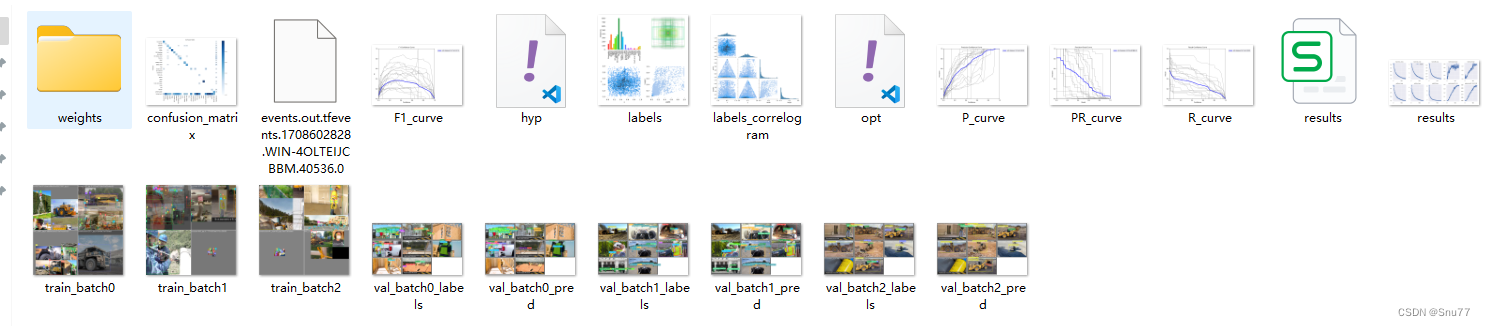
训练好之后的文件就会保存到路径'runs/train/exp12'下面,其中的全部内容如下所示。
七、模型验证
7.1 参数解析
当我们训练一个模型之后,就可以利用其中得到的权重来验证模型的好坏了,相比于训练的众多参数以及需要设置的参数模型的验证需要的超参数比较少,同时YOLOv9也是提供了3个验证的文件,其原理和前面的训练文件一样,这里不再描述了。
我们同样以无辅助分支的检测头验证文件val.py为例,给大家进行示例。
图片中的参数为进行验证必须填写的参数!
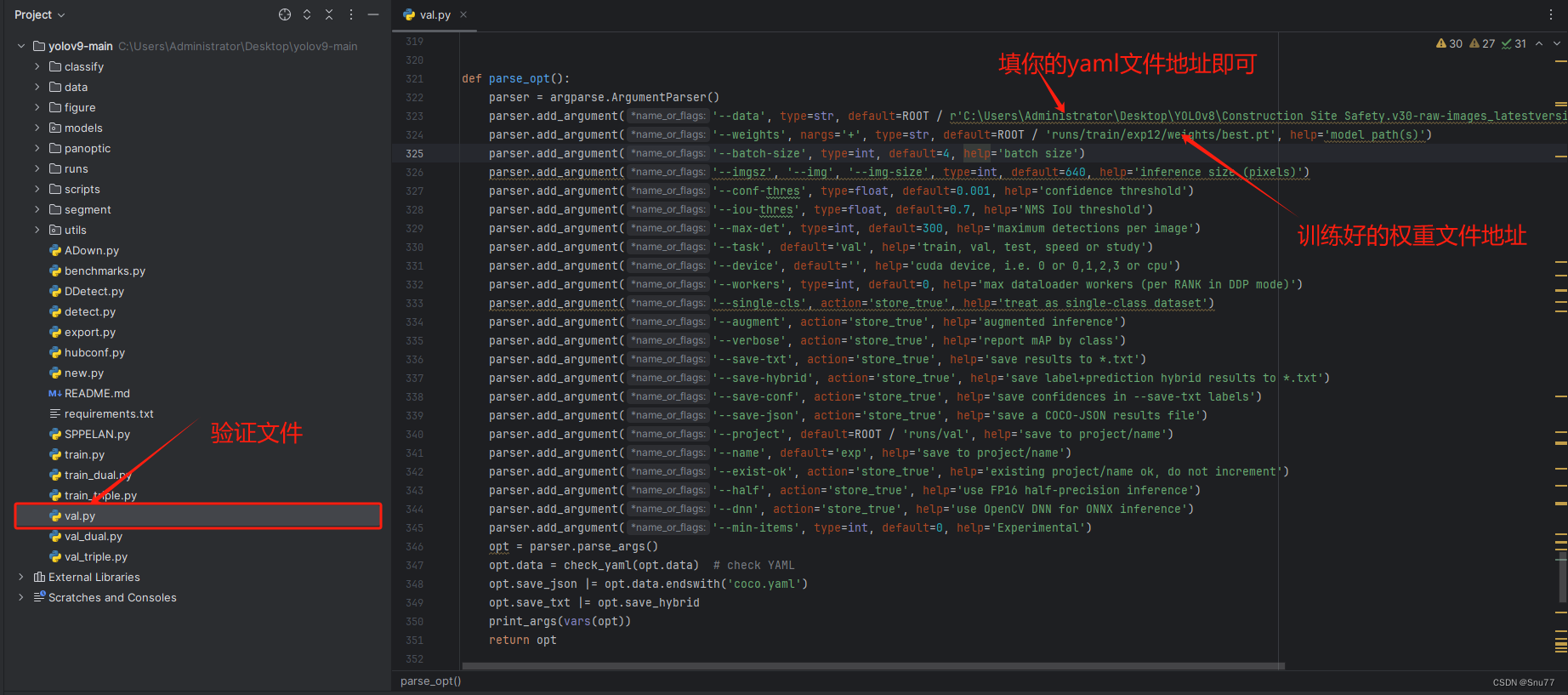
下面的参数是比较重要单独拿出来讲一讲,可能影响运行也可能不影响运行!
全部的参数解析,以及在代码中注释出来了。
- def parse_opt():
- parser = argparse.ArgumentParser()
- parser.add_argument('--data', type=str, default=ROOT / r'替换你数据集的yaml文件地址', help='数据集配置文件路径。')
- parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'runs/train/exp12/weights/best.pt', help='模型权重文件路径,一般需要替换成你自己训练的权重')
- parser.add_argument('--batch-size', type=int, default=4, help='批处理大小,一次验证图片的多少,影响验证速度')
- parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='推理时的图像大小(像素)。')
- parser.add_argument('--conf-thres', type=float, default=0.001, help='置信度阈值。')
- parser.add_argument('--iou-thres', type=float, default=0.7, help='非最大抑制(NMS)的交并比(IoU)阈值。')
- parser.add_argument('--max-det', type=int, default=300, help='每张图像的最大检测数量。')
- parser.add_argument('--task', default='val', help='任务类型,可以是train, val, test, speed或study。')
- parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu,使用的CUDA设备,例如0或0,1,2,3或cpu。')
- parser.add_argument('--workers', type=int, default=0, help='数据加载器的最大工作线程数,Windows系统建议0Linux系统根据需求设置即可')
- parser.add_argument('--single-cls', action='store_true', help='将数据集视为单类别。')
- parser.add_argument('--augment', action='store_true', help='使用增强的推理。')
- parser.add_argument('--verbose', action='store_true', help='按类别详细报告mAP。')
- parser.add_argument('--save-txt', action='store_true', help='将结果保存为文本文件。')
- parser.add_argument('--save-hybrid', action='store_true', help='将标签和预测的混合结果保存为文本文件。')
- parser.add_argument('--save-conf', action='store_true', help='在保存的文本标签中包含置信度。')
- parser.add_argument('--save-json', action='store_true', help='保存COCO-JSON格式的结果文件。')
- parser.add_argument('--project', default=ROOT / 'runs/val', help='结果保存的项目路径。')
- parser.add_argument('--name', default='exp', help='保存结果的子目录名称。')
- parser.add_argument('--exist-ok', action='store_true', help='如果项目/名称已存在,则不递增编号。')
- parser.add_argument('--half', action='store_true', help='使用FP16半精度推理,半精度会降低精度')
- parser.add_argument('--dnn', action='store_true', help='使用OpenCV DNN进行ONNX推理。')
- parser.add_argument('--min-items', type=int, default=0, help='该参数的作用尚不清楚')
- opt = parser.parse_args()
7.2 正式训练
我们按照自己的文件配置好参数之后,运行val.py文件控制台就会输出内容。
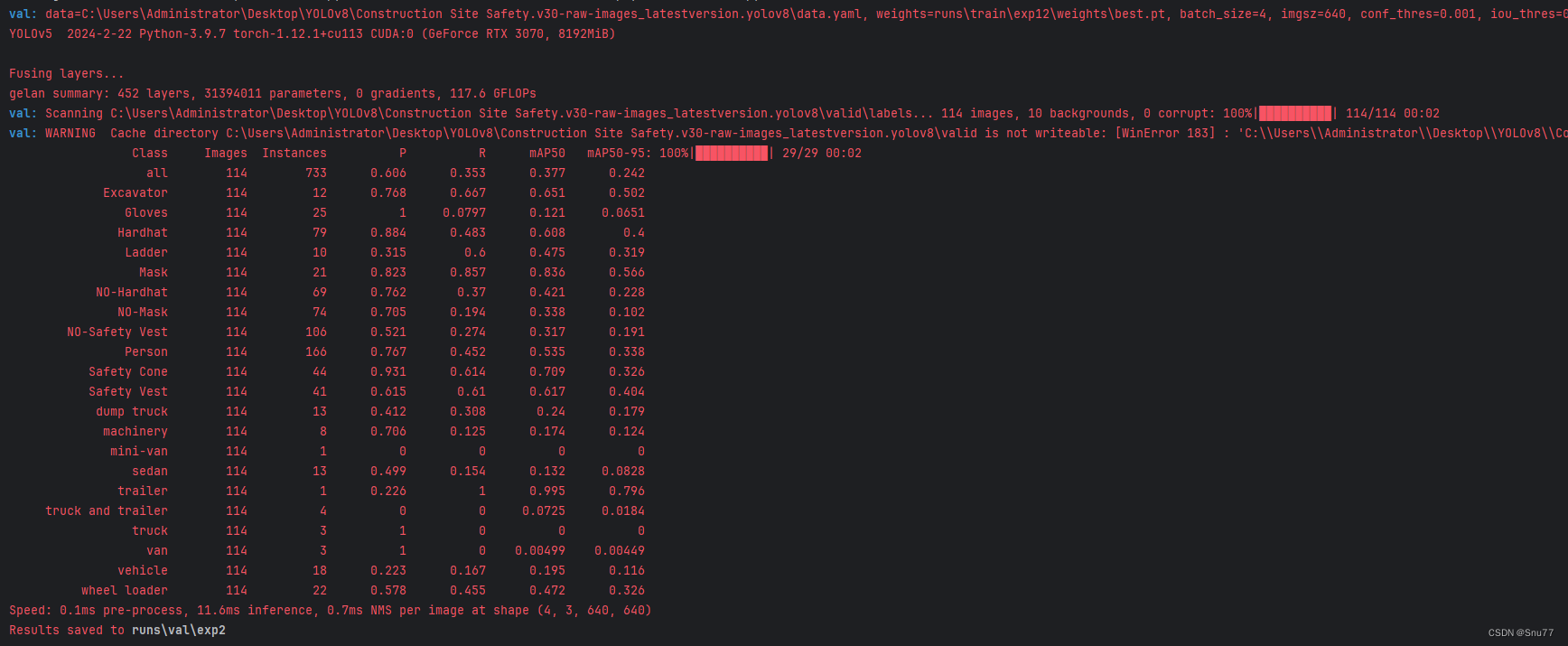
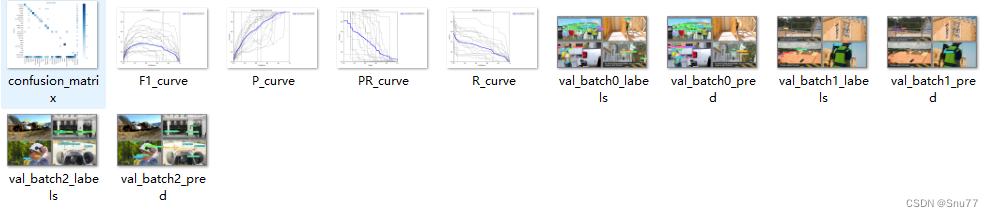
输出的全部文件如下图所示!
八、模型推理
8.1 参数解析
相对于模型的训练和验证,模型的推理仅提供了一个文件即'detect.py'这是为什么,是因为模型的训练和验证都涉及到损失的计算(YOLOv9不同检测头的损失计算方法不一样),但是模型的推理是不需要损失计算的所以YOLOv9仅提供了一个文件供模型的推理。
下面的图片内标记了运行推理文件必须填写的参数!
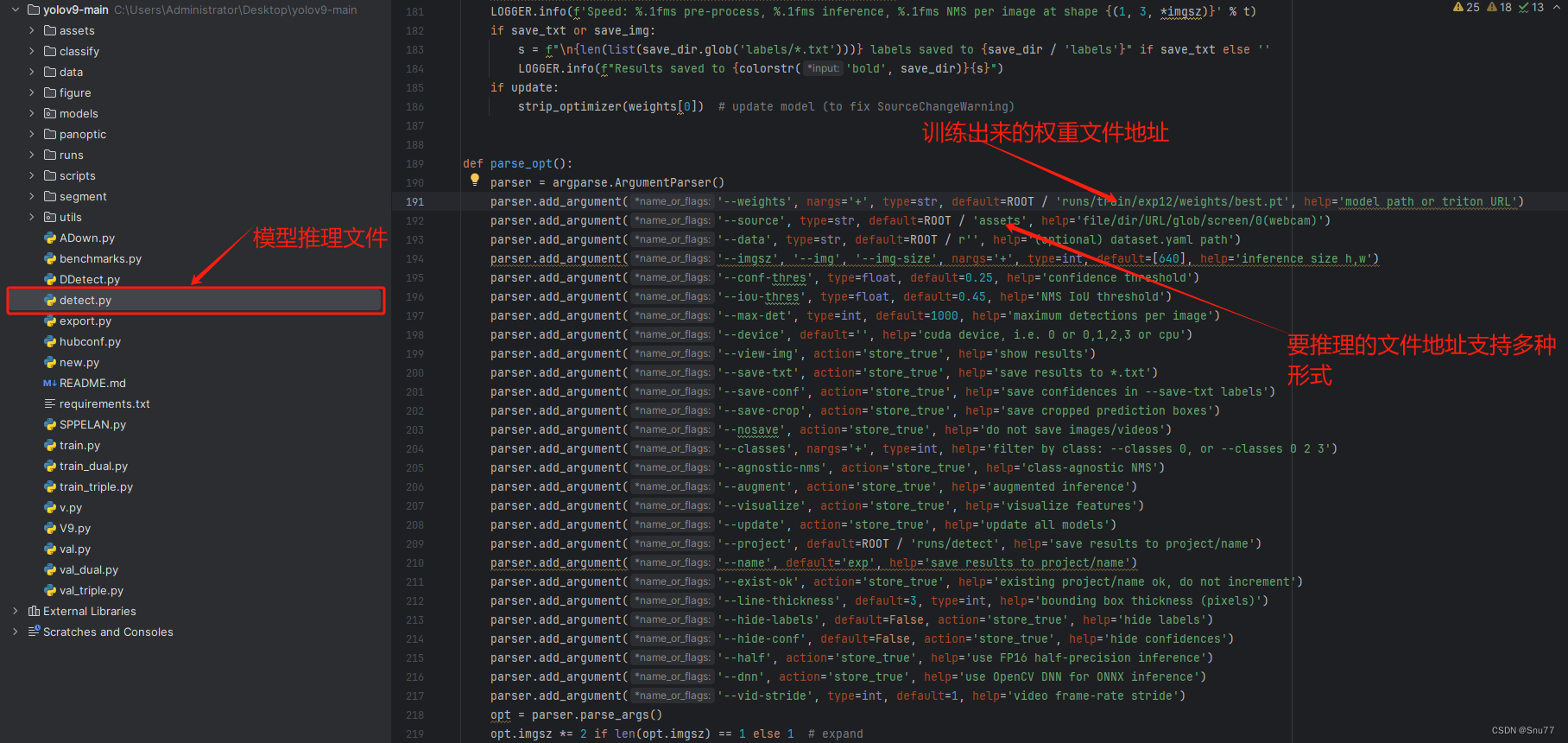
- parser.add_argument('--weights', nargs='+', type=str, default=ROOT / '', help='模型权重的路径或Triton URL。')
- parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='输入数据的来源,可以是文件、目录、URL、glob模式、屏幕捕获或网络摄像头。默认为ROOT/data/images。')
- parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='数据集配置文件的路径,例如coco128.yaml。默认为ROOT/data/coco128.yaml。')
- parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='推理时的图像大小(高度、宽度)。默认为[640]。')
- parser.add_argument('--conf-thres', type=float, default=0.25, help='检测的置信度阈值。默认为0.25,就是我们判断一个物体概率为0-1,如果大于0.25则判断是该类别')
- parser.add_argument('--iou-thres', type=float, default=0.45, help='非最大抑制(NMS)的交并比(IoU)阈值。默认为0.45。')
- parser.add_argument('--max-det', type=int, default=1000, help='每张图像的最大检测数量。默认为1000。')
- parser.add_argument('--device', default='', help='指定运行设备,例如CUDA设备(0或0,1,2,3)或CPU。')
- parser.add_argument('--view-img', action='store_true', help='如果设置,展示检测结果。')
- parser.add_argument('--save-txt', action='store_true', help='如果设置,将检测结果保存为文本文件。')
- parser.add_argument('--save-csv', action='store_true', help='如果设置,将检测结果保存为CSV格式。')
- parser.add_argument('--save-conf', action='store_true', help='如果设置,在文本文件中保存置信度信息。')
- parser.add_argument('--save-crop', action='store_true', help='如果设置,保存被检测对象的裁剪图像。')
- parser.add_argument('--nosave', action='store_true', help='如果设置,不保存图像或视频结果。')
- parser.add_argument('--classes', nargs='+', type=int, help='过滤指定的类别,例如0或 0 2 3。')
- parser.add_argument('--agnostic-nms', action='store_true', help='如果设置,使用与类别无关的NMS。')
- parser.add_argument('--augment', action='store_true', help='如果设置,使用增强的推理。')
- parser.add_argument('--visualize', action='store_true', help='如果设置,可视化特征。')
- parser.add_argument('--update', action='store_true', help='如果设置,更新所有模型。')
- parser.add_argument('--project', default=ROOT / 'runs/detect', help='设置结果保存的项目目录。默认为ROOT/runs/detect。')
- parser.add_argument('--name', default='exp', help='设置保存结果的子目录名称。默认为exp。')
- parser.add_argument('--exist-ok', action='store_true', help='如果设置,允许已存在的项目/名称,不自动增加编号。')
- parser.add_argument('--line-thickness', default=3, type=int, help='设置边界框的线条粗细(像素)。默认为3。')
- parser.add_argument('--hide-labels', default=False, action='store_true', help='如果设置,隐藏标签。')
- parser.add_argument('--hide-conf', default=False, action='store_true', help='如果设置,隐藏置信度。')
- parser.add_argument('--half', action='store_true', help='如果设置,使用FP16半精度推理,推理速度更快,但精度会下降。')
- parser.add_argument('--dnn', action='store_true', help='如果设置,使用OpenCV DNN模块进行ONNX推理。')
- parser.add_argument('--vid-stride', type=int, default=1, help='设置视频帧率步长。默认为1。')
8.2 正式推理
我们填好参数之后运行detect.py文件即可控制台就会输出推理的进程。

同时结果文件会保存到'runs/detect'文件夹下,下面是我进行推理的一个内容。

九、模型导出
具官方作者在Github上回复来说,YOLOv9提供的repo目前尚不支持模型的导出功能,作者说后面会更新(目前项目很不成熟,大家可以稍微观望一下,后面更新我也会第一时间给大家更新教程)
十、全文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv9改进有效涨点专栏,本专栏目前为新开的,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,如果大家觉得本文帮助到你了,订阅本专栏(目前免费订阅,后期不迷路),关注后续更多的更新~

