
热门标签
热门文章
- 1三种梯度下降法对比(Batch gradient descent、Mini-batch gradient descent 和 stochastic gradient descent)_梯度下降的三种形式对比
- 2PicGo插件_picgo文字转图片插件
- 3细粒度分类
- 4java开发工程师p2级别_Java软件开发不同薪资级别-技术要求
- 5Linux开发板-串口连接成功后界面空白问题_xshell连接串口成功但后面不显示
- 6WASubContext.js?t=wechat&s=1670034424984&v=2.28.0:1 routeDone with a webviewId 1 that is not the cur
- 7华为EROFS文件系统的性能测试_squashfs 华为
- 8npm run 运行报错 ./node_modules/docx-preview/dist/docx-preview.min.mjs_error in ./node_modules/docx-preview/dist/docx-pre
- 9webERP安装配置超详细
- 10Android 之 数据存储与访问 —— 文件存储读写_android 读写文件
当前位置: article > 正文
用人工智能取一个超酷的名字(二)_如何训练一个大模型 用于给产品取名
作者:羊村懒王 | 2024-03-31 15:40:48
赞
踩
如何训练一个大模型 用于给产品取名
这篇文章代码有点多,不知道大家有没有兴趣看关于源码的深度解析的文章呢?
留言区和我说说~~
构建模型
接下来,我们要使用 keras.Model 子类构建模型。 (For details see Making new Layers and Models via subclassing).
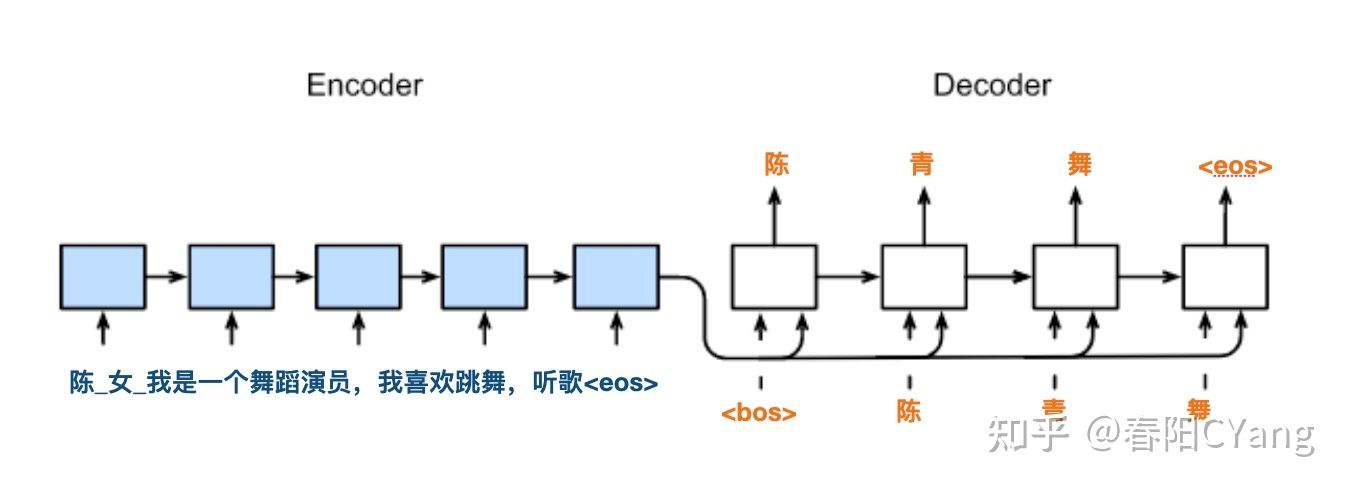
模型分为两大部分:
-
Encoder -
Decoder
使用的主要结构为: LSTM
获取模型构建需要的参数
vocab_inp_size = len(inp_tokenizer.get_vocab()) + 1
vocab_tar_size = len(out_tokenizer.get_vocab()) + 1
max_length_input = example_input_batch.shape[1]
max_length_output = example_target_batch.shape[1]
embedding_dim = 256
units = 1024
steps_per_epoch = num_examples // BATCH_SIZE
- 1
print(
"输入词典大小 {}\n输出词典的大小{}\n输入最大长度{}\n输出最大长度".format(
vocab_inp_size, vocab_tar_size, max_length_input, max_length_output
)
)
- 1
输入词典大小 3910
输出词典的大小2965
输入最大长度469
输出最大长度
- 1
- 2
- 3
- 4
example_input_batch.shape, example_target_batch.shape
- 1
(TensorShape([64, 469]), TensorShape([64, 25]))
- 1
print(example_input_batch)
print(example_target_batch)
- 1
tf.Tensor( [[3907 7 59 ... 0 0 0] [3907 7 808 ... 0 0 0] [3907 7 124 ... 0 0 0] ... [3907 7 2498 ... 0 0 0] [3907 7 350 ... 0 0 0] [3907 7 209 ... 0 0 0]], shape=(64, 469), dtype=int64) tf.Tensor( [[2962 8 8 ... 0 0 0] [2962 1834 311 ... 0 0 0] [2962 759 1676 ... 0 0 0] ... [2962 706 1161 ... 0 0 0] [2962 99 1023 ... 0 0 0] [2962 128 1317 ... 0 0 0]], shape=(64, 25), dtype=int64)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
Encoder 编码器
class Encoder(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, enc_units, batch_sz):
super(Encoder, self).__init__()
self.batch_sz = batch_sz
self.enc_units = enc_units
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
##-------- LSTM layer in Encoder ------- ##
self.lstm_layer = tf.keras.layers.LSTM(
self.enc_units,
return_sequences=True,
return_state=True,
recurrent_initializer="glorot_uniform",
)
def call(self, x, hidden):
x = self.embedding(x)
output, h, c = self.lstm_layer(x, initial_state=hidden)
return output, h, c
def initialize_hidden_state(self):
return [
tf.zeros((self.batch_sz, self.enc_units)),
tf.zeros((self.batch_sz, self.enc_units)),
]

- 1
编码器的验证
encoder = Encoder(vocab_inp_size, embedding_dim, units, BATCH_SIZE)
# sample input
sample_hidden = encoder.initialize_hidden_state()
sample_output, sample_h, sample_c = encoder(example_input_batch, sample_hidden)
print(
"Encoder output shape: (batch size, sequence length, units) {}".format(
sample_output.shape
)
)
print("编码器 h vecotr shape: (batch size, units) {}".format(sample_h.shape))
print("编码器 c vector shape: (batch size, units) {}".format(sample_c.shape))
- 1
Encoder output shape: (batch size, sequence length, units) (64, 469, 1024)
编码器 h vecotr shape: (batch size, units) (64, 1024)
编码器 c vector shape: (batch size, units) (64, 1024)
- 1
- 2
- 3
解码器
class Decoder(tf.keras.Model):
def __init__(
self, vocab_size, embedding_dim, dec_units, batch_sz, attention_type="luong"
):
super(Decoder, self).__init__()
self.batch_sz = batch_sz
self.dec_units = dec_units
self.attention_type = attention_type
# Embedding Layer
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
# Final Dense layer on which softmax will be applied
self.fc = tf.keras.layers.Dense(vocab_size)
# Define the fundamental cell for decoder recurrent structure
self.decoder_rnn_cell = tf.keras.layers.LSTMCell(self.dec_units)
# Sampler
self.sampler = tfa.seq2seq.sampler.TrainingSampler()
# Create attention mechanism with memory = None
self.attention_mechanism = self.build_attention_mechanism(
self.dec_units,
None,
self.batch_sz * [max_length_input],
self.attention_type,
)
# Wrap attention mechanism with the fundamental rnn cell of decoder
self.rnn_cell = self.build_rnn_cell(batch_sz)
# Define the decoder with respect to fundamental rnn cell
self.decoder = tfa.seq2seq.BasicDecoder(
self.rnn_cell, sampler=self.sampler, output_layer=self.fc
)
def build_rnn_cell(self, batch_sz):
rnn_cell = tfa.seq2seq.AttentionWrapper(
self.decoder_rnn_cell,
self.attention_mechanism,
attention_layer_size=self.dec_units,
)
return rnn_cell
def build_attention_mechanism(
self, dec_units, memory, memory_sequence_length, attention_type="luong"
):
# ------------- #
# typ: Which sort of attention (Bahdanau, Luong)
# dec_units: final dimension of attention outputs
# memory: encoder hidden states of shape (batch_size, max_length_input, enc_units)
# memory_sequence_length: 1d array of shape (batch_size) with every element set to max_length_input (for masking purpose)
if attention_type == "bahdanau":
return tfa.seq2seq.BahdanauAttention(
units=dec_units,
memory=memory,
memory_sequence_length=memory_sequence_length,
)
else:
return tfa.seq2seq.LuongAttention(
units=dec_units,
memory=memory,
memory_sequence_length=memory_sequence_length,
)
def build_initial_state(self, batch_sz, encoder_state, Dtype):
decoder_initial_state = self.rnn_cell.get_initial_state(
batch_size=batch_sz, dtype=Dtype
)
decoder_initial_state = decoder_initial_state.clone(cell_state=encoder_state)
return decoder_initial_state
def call(self, inputs, initial_state):
x = self.embedding(inputs)
outputs, _, _ = self.decoder(
x,
initial_state=initial_state,
sequence_length=self.batch_sz * [max_length_output - 1],
)
return outputs
- 1
解码器验证
import tensorflow_addons as tfa
decoder = Decoder(vocab_tar_size, embedding_dim, units, BATCH_SIZE, "luong")
sample_x = tf.random.uniform((BATCH_SIZE, max_length_output))
decoder.attention_mechanism.setup_memory(sample_output)
initial_state = decoder.build_initial_state(
BATCH_SIZE, [sample_h, sample_c], tf.float32
)
sample_decoder_outputs = decoder(sample_x, initial_state)
print("解码器输出 Shape: ", sample_decoder_outputs.rnn_output.shape)
- 1
解码器输出 Shape: (64, 24, 2965)
- 1
定义优化器
optimizer = tf.keras.optimizers.Adam()
def loss_function(real, pred):
# real shape = (BATCH_SIZE, max_length_output)
# pred shape = (BATCH_SIZE, max_length_output, tar_vocab_size )
cross_entropy = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True, reduction="none"
)
loss = cross_entropy(y_true=real, y_pred=pred)
mask = tf.logical_not(tf.math.equal(real, 0)) # output 0 for y=0 else output 1
mask = tf.cast(mask, dtype=loss.dtype)
loss = mask * loss
loss = tf.reduce_mean(loss)
return loss
- 1
检查点(Checkpoints)
import os
checkpoint_dir = "./training_checkpoints"
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(optimizer=optimizer, encoder=encoder, decoder=decoder)
- 1
定义训练中一步的操作
@tf.function
def train_step(inp, targ, enc_hidden):
loss = 0
with tf.GradientTape() as tape:
enc_output, enc_h, enc_c = encoder(inp, enc_hidden)
dec_input = targ[:, :-1] # Ignore <end> token
real = targ[:, 1:] # ignore <start> token
# Set the AttentionMechanism object with encoder_outputs
decoder.attention_mechanism.setup_memory(enc_output)
# Create AttentionWrapperState as initial_state for decoder
decoder_initial_state = decoder.build_initial_state(
BATCH_SIZE, [enc_h, enc_c], tf.float32
)
pred = decoder(dec_input, decoder_initial_state)
logits = pred.rnn_output
loss = loss_function(real, logits)
variables = encoder.trainable_variables + decoder.trainable_variables
gradients = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(gradients, variables))
return loss
- 1

训练模型
# 使用 GPU 进行训练
gpus = tf.config.list_physical_devices("GPU")
if gpus:
# 强制使用第一块GPU
try:
tf.config.set_visible_devices(gpus[0], "GPU")
logical_gpus = tf.config.list_logical_devices("GPU")
print(len(gpus), "Physical GPUs,", len(logical_gpus), "Logical GPU")
except RuntimeError as e:
# Visible devices must be set before GPUs have been initialized
print(e)
- 1
1 Physical GPUs, 1 Logical GPU
- 1
import time
EPOCHS = 50
print("模型训练..")
for epoch in range(EPOCHS):
start = time.time()
enc_hidden = encoder.initialize_hidden_state()
total_loss = 0
# print(enc_hidden[0].shape, enc_hidden[1].shape)
for (batch, (inp, targ)) in enumerate(train_dataset.take(steps_per_epoch)):
batch_loss = train_step(inp, targ, enc_hidden)
total_loss += batch_loss
if batch % 100 == 0:
print(
"Epoch {} Batch {} Loss {:.4f}".format(
epoch + 1, batch, batch_loss.numpy()
)
)
# saving (checkpoint) the model every 2 epochs
if (epoch + 1) % 2 == 0:
checkpoint.save(file_prefix=checkpoint_prefix)
print("Epoch {} Loss {:.4f}".format(epoch + 1, total_loss / steps_per_epoch))
print("每个 epoch 消耗时间 {} sec\n".format(time.time() - start))
print("模型训练结束")
- 1
模型训练..
Epoch 1 Batch 0 Loss 1.8893
Epoch 1 Batch 100 Loss 1.3055
Epoch 1 Loss 1.4054
每个 epoch 消耗时间 107.30223488807678 sec
Epoch 2 Batch 0 Loss 1.2897
Epoch 2 Batch 100 Loss 1.2302
Epoch 2 Loss 1.2439
每个 epoch 消耗时间 99.80383324623108 sec
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
使用模型起名字
def generate_name(surname, gender, desc):
# 输入文本
gender = gender if gender else ""
desc = desc if desc else ""
text = "<bos>" + surname + "_" + gender + "_" + desc + "<eos>"
inp_text = inp_tokenizer.encode(text)
inp_tensor = tf.constant(inp_text.ids)
inp_tensor = tf.expand_dims(inp_tensor, axis=0)
# 恢复最近的 checkpoint
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
# 前向计算过程
inference_batch_size = inp_tensor.shape[0]
enc_start_state = [
tf.zeros((inference_batch_size, units)),
tf.zeros((inference_batch_size, units)),
]
enc_out, enc_h, enc_c = encoder(inp_tensor, enc_start_state)
dec_h = enc_h
dec_c = enc_c
start_tokens = tf.fill([inference_batch_size], out_tokenizer.token_to_id("<bos>"))
end_token = out_tokenizer.token_to_id("<eos>")
greedy_sampler = tfa.seq2seq.GreedyEmbeddingSampler()
beam_width = 3
# 创建解码器实例
decoder_instance = tfa.seq2seq.BasicDecoder(
cell=decoder.rnn_cell,
sampler=greedy_sampler,
output_layer=decoder.fc,
maximum_iterations=4,
)
# 设置注意力机制
decoder.attention_mechanism.setup_memory(enc_out)
decoder_initial_state = decoder.build_initial_state(
inference_batch_size, [enc_h, enc_c], tf.float32
)
# 使用解码器生成文本
decoder_embedding_matrix = decoder.embedding.variables[0]
outputs, _, _ = decoder_instance(
decoder_embedding_matrix,
start_tokens=start_tokens,
end_token=end_token,
initial_state=decoder_initial_state,
)
print(outputs.sample_id.numpy().tolist()[0])
return surname + "".join(
out_tokenizer.decode(outputs.sample_id.numpy().tolist()[0])
)
- 1
generate_name("刘", "女", "喜欢篮球运动")
- 1
通过模型,我们可以看到生成了名字是: 刘兰淇。怎么样,是不是还不错。
使用 beam 生成名字
def beam_generate_name(surname, gender, desc, beam_width=3):
# 输入文本
gender = gender if gender else ""
desc = desc if desc else ""
text = "<bos>" + surname + "_" + gender + "_" + desc + "<eos>"
inp_text = inp_tokenizer.encode(text)
inp_tensor = tf.constant(inp_text.ids)
inp_tensor = tf.expand_dims(inp_tensor, axis=0)
inference_batch_size = inp_tensor.shape[0]
result = ""
enc_start_state = [
tf.zeros((inference_batch_size, units)),
tf.zeros((inference_batch_size, units)),
]
enc_out, enc_h, enc_c = encoder(inp_tensor, enc_start_state)
dec_h = enc_h
dec_c = enc_c
start_tokens = tf.fill([inference_batch_size], out_tokenizer.token_to_id("<bos>"))
end_token = out_tokenizer.token_to_id("<eos>")
enc_out = tfa.seq2seq.tile_batch(enc_out, multiplier=beam_width)
decoder.attention_mechanism.setup_memory(enc_out)
print(
"beam_with * [batch_size, max_length_input, rnn_units] : 3 * [1, 16, 1024]] :",
enc_out.shape,
)
hidden_state = tfa.seq2seq.tile_batch([enc_h, enc_c], multiplier=beam_width)
decoder_initial_state = decoder.rnn_cell.get_initial_state(
batch_size=beam_width * inference_batch_size, dtype=tf.float32
)
decoder_initial_state = decoder_initial_state.clone(cell_state=hidden_state)
decoder_instance = tfa.seq2seq.BeamSearchDecoder(
decoder.rnn_cell, beam_width=beam_width, output_layer=decoder.fc
)
decoder_embedding_matrix = decoder.embedding.variables[0]
outputs, final_state, sequence_lengths = decoder_instance(
decoder_embedding_matrix,
start_tokens=start_tokens,
end_token=end_token,
initial_state=decoder_initial_state,
)
final_outputs = tf.transpose(outputs.predicted_ids, perm=(0, 2, 1))
beam_scores = tf.transpose(
outputs.beam_search_decoder_output.scores, perm=(0, 2, 1)
)
result, beam_scores = final_outputs.numpy(), beam_scores.numpy()
for beam, score in zip(result, beam_scores):
print(beam.shape, score.shape)
print(beam.tolist())
for i in range(beam_width):
output = out_tokenizer.decode(beam.tolist()[i])
print(surname + "".join(output))
- 1
beam_generate_name("白", "男", "喜欢跳舞")
- 1
这个模型生成的名字是,白慕,是不是也还不错呢。
这篇文章代码有点多,不知道大家有没有兴趣看关于源码的深度解析的文章呢?
留言区和我说说~~
本文由 mdnice 多平台发布
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/羊村懒王/article/detail/345035
推荐阅读
相关标签

