- 1Swoole学习笔记——timer::tick和timer::after_timer tick
- 2反编译小程序详细教程,处理各种异常报错_subpackage.pages is not iterable
- 33399 arm-linux 命令调整声音大小_arm 开发板音频调试 改变音量
- 4SpringBoot集成ES之ElasticsearchRestTemplate_org.springframework.data.elasticsearch.core.elasti
- 5[Unity]腾讯SDK踩坑之路(3)--米大师坑 + MSDK坑 (2)_unity 米大师
- 6dl dt dd标签用法 _dldddt
- 7fastadmin学习01-windows下安装部署
- 8repo. mysql. com_apt-get更新出现W: GPG error: http://repo.mysql.com trusty InRelease
- 9现在java工程师薪资是多少,使用/教程/实例_java编程工程师薪资多少
- 10linux 安装opencv遇到缺失的包
【C++】-- STL之map和set详解_c++ set和map如何遍历
赞
踩
目录
一、关联式容器和键值对
1.关联式容器
前面的STL的容器,如vector、list、deque等都是序列式容器,因为
(1)底层的数据结构是线性的
(2)存储的是元素本身
(3)数据和数据之间没有关联
关联式容器也是用来存储数据的, 不过里面存储的是<key, value>键值对,数据检索时,效率比序列式容器高。STL有两种关联式容器:树形结构和哈希结构。树形结构的关联式容器有4种:set、map 、multiset、mapltimap,它们的底层都是平衡搜索树(红黑树)。
2.键值对
用来表示具有一一对应关系的结构,该结构中一般只包含两个成员变量key和value,key代表键值,value表示与key对应的信息。
比如:英汉互译字典中必然有英文单词与其对应的中文含义,而且,英文单词与其中文含义一一对应,即通过该英文单词,在词典中就可以找到与其对应的中文含义。
二、set
1.set特点
set是按照一定次序存储元素的容器,它有以下特点:
(1)在set中,用value标识元素(value就是key,类型为T),并且每个value必须是唯一的。set中的元素不能在容器中修改(元素总是const),但是可以从容器中插入或删除它们。
(2)在内部,set中的元素总是按照其内部比较对象(类型比较)所指示的特定严格弱排序准则进行排序。
(3)set容器通过key访问单个元素的速度通常比unordered_set容器慢,但它们允许根据顺序对子集进行直接迭代。
(4)set在底层是用二叉搜索树(红黑树)实现的。
注意:
(1)与map/multimap不同,map/multimap中存储的是真正的键值对<key, value>,set中只放value,但在底层实际存放的是由<value, value>构成的键值对。
(2)set中插入元素时,只需要插入value即可,不需要构造键值对。
(3)set中的元素不可以重复(因此可以使用set进行去重)。
(4)使用set的迭代器遍历set中的元素,可以得到有序序列
(5)set中的元素默认按照小于来比较
(6)set中查找某个元素,时间复杂度为:![]()
(7)set中的元素不允许修改,因为底层的二叉搜索树是有序的,如果修改了元素,会破坏有序的性质
(8)set中的底层使用二叉搜索树(红黑树)来实现
2.set类
(1) set类对象构造
- template < class T, // set::key_type/value_type 元素的类型
- class Compare = less<T>, // set::key_compare/value_compare 比较方式,默认小于
- class Alloc = allocator<T> // set::allocator_type 使用STL提供的空间配置器管理方式
- > class set;
-
- //构造set
- explicit set (const key_compare& comp = key_compare(),
- const allocator_type& alloc = allocator_type());
- template <class InputIterator>
-
- //使用迭代器区间构造set
- set (InputIterator first, InputIterator last,
- const key_compare& comp = key_compare(),
- const allocator_type& alloc = allocator_type());
-
- //拷贝构造set
- set (const set& x);

创建set对象:
- #define _CRT_SECURE_NO_WARNINGS 1
- #include<iostream>
- using namespace std;
-
- int main()
- {
- set<int> s;//创建一个set对象s
- //向s中插入元素
-
- set<int> s1(s.begin(),s.end());//用s的区间构造s1
- set<int> s2(s1);//用s1拷贝构造s2
-
- return 0;
- }
(2)insert插入
- s.insert(6);
- s.insert(2);
- s.insert(5);
- s.insert(8);
- s.insert(5);
set的作用:排序+去重
(3)set遍历
①迭代器遍历:
正向迭代器遍历:
- iterator begin();//正向迭代器
- const_iterator begin() const;//正向const迭代器
- //set 排序+去重
- //遍历1:
- set<int>::iterator it= s.begin();
- while (it != s.end())
- {
- cout << *it << " ";
- it++;
- }
- cout << endl;
打印结果:
反向迭代器遍历:
- reverse_iterator rbegin();//反向迭代器
- const_reverse_iterator rbegin() const;//反向const迭代器
- set<int>::reverse_iterator it= s.rbegin();
- while (it != s.rend())
- {
- cout << *it << " ";
- it++;
- }
- cout << endl;
打印是倒序的:

②范围for遍历
- set<string> s1;
- s1.insert("spring");
- s1.insert("summer");
- s1.insert("autumn");
- s1.insert("winter");
-
- for (const auto& e : s1)//如果不加引用,s1中的每个元素都是深拷贝,每次都要调用拷贝构造,代价大
- {
- cout << e << " ";
- }
- cout << endl;
打印结果:

(4)find查找
iterator find (const value_type& val) const;//找到了就返回这个元素的迭代器,否则返回end如:
- set<string>::iterator ret = s1.find("autumn");
- if (ret != s1.end())
- {
- cout << *ret << endl;
- }
- else
- {
- cout << "没找到" << endl;
- }

(5)erase删除
- void erase (iterator position);//删除指定位置元素
- size_type erase (const value_type& val);//从set中删除指定的值
- void erase (iterator first, iterator last);//删除指定区间
①删除指定位置元素:
删除元素5:
- set<int> s;
- s.insert(6);
- s.insert(2);
- s.insert(5);
- s.insert(8);
- s.insert(5);
-
- set<int>::iterator ret = s.find(5);
- if (ret != s.end())
- {
- s.erase(ret);
- }
-
- for (auto e : s)
- {
- cout << e << " ";
- }
- cout << endl;

②删除指定值元素
删除值为8的元素:
- set<int> s;
- s.insert(6);
- s.insert(2);
- s.insert(5);
- s.insert(8);
- s.insert(5);
-
- //删除值为8的元素
- s.erase(8);
-
- for (auto e : s)
- {
- cout << e << " ";
- }
- cout << endl;

③删除指定区间
删除5之前的元素:
- set<int> s;
- s.insert(6);
- s.insert(2);
- s.insert(5);
- s.insert(8);
- s.insert(5);
-
- //删除5之前的元素
- set<int>::iterator ret = s.find(5);
- s.erase(s.begin(), ret);
-
- for (auto e : s)
- {
- cout << e << " ";
- }
- cout << endl;

(6)计数count( )
计算set中值为val的元素的个数:
size_type count (const value_type& val) const;//计算set中值为val的元素的个数由于set中的元素不重复,因此,set的count的计算结果≤1。
计算s中值为5的元素的个数:
- set<int> s;
-
- s.insert(6);
- s.insert(2);
- s.insert(5);
- s.insert(8);
- s.insert(5);
-
- cout << s.count(5) << endl;

(7)交换swap( )
交换*this和x的根
void swap (set& x);- set<int> s;
- s.insert(6);
- s.insert(2);
- s.insert(5);
- s.insert(8);
- s.insert(5);
-
- cout << "交换前s: ";
- for (auto e : s)
- {
- cout << e << " ";
- }
- cout << endl;
-
- set<int> s1;
- s1.insert(12);
- s1.insert(18);
- s1.insert(16);
- s1.insert(11);
- s1.insert(13);
-
- cout << "交换前s1: ";
- for (auto e : s1)
- {
- cout << e << " ";
- }
- cout << endl;
-
- //s.swap(s1);
- swap(s, s1);
-
- cout << "交换后s: ";
- for (auto e : s)
- {
- cout << e << " ";
- }
- cout << endl;
-
- cout << "交换后s1: ";
- for (auto e : s1)
- {
- cout << e << " ";
- }
- cout << endl;

如果将
s.swap(s1);写成
swap(s,s1);那么就会从交换根变成深拷贝。
(8)判空empty( )
判断set是否为空:
bool empty() const;判断s是否为空:
cout << s.empty() << endl; 0表示不为空:
(9)求set的元素个数size( )
求set的元素个数:
size_type size() const;求s的元素个数:
cout << s.size() << endl;
(10)清空所有元素clear( )
清空set中的元素:
void clear();清空s中的所有元素:
- s.clear();
-
- for (auto e : s)
- {
- cout << e << " ";
- }
- cout << endl;

三、map
1.map特点
(1) map是关联容器,它按照特定的次序(按照key来比较)存储由键值key和值value组合而成的元素。
(2)在map中,键值key通常用于排序和惟一地标识元素,而值value中存储与此键值key关联的内容。键值key和值value的类型可能不同,并且在map的内部,key与value通过成员类型value_type绑定在一起,为其取别名称为pair:
typedef pair<const Key, T> value_type;(3) 在内部,map中的元素总是按照键值key进行比较排序的。
(4) map中通过键值访问单个元素的速度通常比unordered_map容器慢,但map允许根据顺序对元素进行直接迭代(即对map中的元素进行迭代时,可以得到一个有序的序列)。
(5) map支持下标访问符,即在[]中放入key,就可以找到与key对应的value。
(6)map通常被实现为平衡二叉搜索树(红黑树)。
2.map类
(1)map类的构造
- template < class Key, // map::key_type,Key的类型
- class T, // map::mapped_type,value的类型
- class Compare = less<Key>, // map::key_compare,比较器类型,默认小于,自定义类型需写函数指针或仿函数
- class Alloc = allocator<pair<const Key,T> > // map::allocator_type 空间配置器
- > class map;
-
- //构造map
- explicit map (const key_compare& comp = key_compare(),
- const allocator_type& alloc = allocator_type());
-
- 使用迭代器区间构造map
- template <class InputIterator>
- map (InputIterator first, InputIterator last,
- const key_compare& comp = key_compare(),
- const allocator_type& alloc = allocator_type());
-
- //拷贝构造map
- map (const map& x);
创建map对象:
- #define _CRT_SECURE_NO_WARNINGS 1
- #include<iostream>
- #include<map>
- using namespace std;
-
- int main()
- {
- map<string, int> m;//创建一个map对象m
- //向m中插入pair
-
- map<string, int> m1(m.begin(), m.end);//用m的区间构造m1
- map<string, int> m2(m1);//用m1拷贝构造m2
-
- return 0;
- }
(2)插入insert( )
- pair<iterator,bool> insert (const value_type& val);//当val的first已存在时返回值pair的second为false,否则返回pair的second为true
-
- iterator insert (iterator position, const value_type& val);//在map的指定位置插入pair
-
- template <class InputIterator>
- void insert (InputIterator first, InputIterator last);//在map中插入一段迭代器区间
①插入pair,由于此时map中没有足球,因此pair的second为true:
- bool b = m.insert(pair<string, int>("足球", 2)).second;
- cout << b << endl;
-
- m.insert (pair<string, int>("篮球", 6));
- m.insert (pair<string, int>("羽毛球", 3));
- m.insert (pair<string, int>("排球", 1));

make_pair对pair进行了包装,构造了pair对象:
- template <class T1,class T2>
- pair<T1,T2> make_pair (T1 x, T2 y)
- {
- return ( pair<T1,T2>(x,y) );
- }
因此,在项目中,不展开命名空间时,都要指定std,make_pair要比pair写起来更简洁一些,对比以下两种写法:
- m.insert(std::pair<std::string, int>("网球", 7));
- m.insert(std::make_pair("网球", 7));
明显make_pair的写法更简洁。
②在map的指定位置插入pair
- map<string, int> m;
- //向m中插入pair
- m.insert (pair<string, int>("足球", 2));
- m.insert (pair<string, int>("篮球", 6));
- m.insert (pair<string, int>("羽毛球", 3));
- m.insert (pair<string, int>("排球", 1));
-
- //在m开始插入乒乓球
- map<string, int>:: iterator it = m.begin();
- m.insert(it, pair<string, int>("乒乓球",5));
监视:
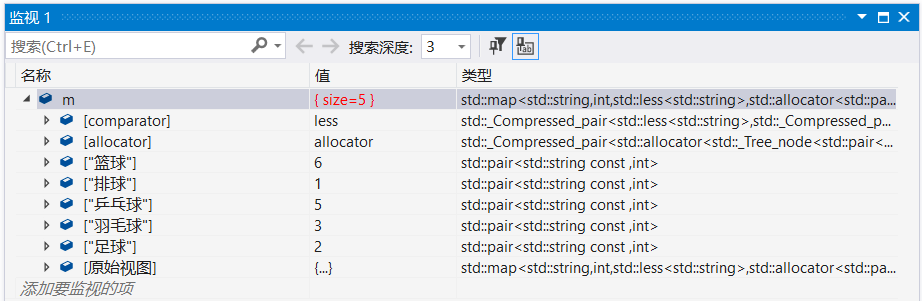
③在map中插入一段迭代器区间
向m1中插入m从第二个位置开始到结束位置的区间:
- map<string, int> m1;
- m1.insert(++m.begin(), m.end());
监视:

这里少了篮球,说明m的第一个pair是<"篮球",6>。
(3)map遍历
auto在变量被定义并初始化之后编译器才能根据初始化表达式来推导auto的实际类型,所以在定义map对象时,不能使用auto关键字,在变量被定义并初始化之后可以使用auto关键字:
- map<string, int> m;
-
- m.insert(pair<string, int>("足球", 2));
- m.insert(pair<string, int>("篮球", 6));
- m.insert(pair<string, int>("羽毛球", 3));
- m.insert(pair<string, int>("排球", 1));
- m.insert(make_pair("网球", 7));
-
- //map<string, int>::iterator mit = m.begin();
- auto mit = m.begin();//同map<string, int>::iterator mit = m.begin();
- while (mit != m.end())
- {
- cout << mit->first << ":" << mit->second<< endl;
- mit++;
- }
- cout << endl;
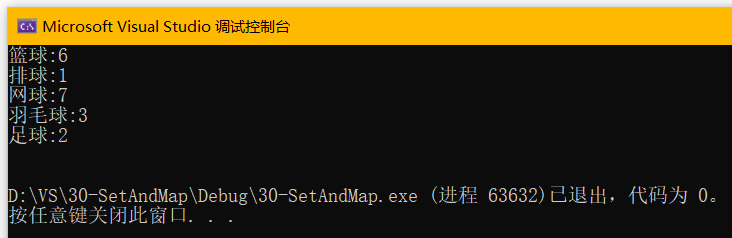
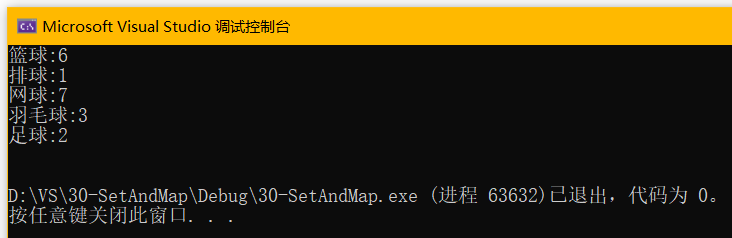
map本身有两个模板参数,会导致有些类型比较长,项目中可以用typedef简化命名:
- typedef std::map<std::string, int> MAP;//简化map命名
- typedef std::pair<std::string, int> MAP_KV;//简化pair命名
- typedef std::map<std::string, int>::iterator MAP_IT;//简化迭代器命名
-
- MAP m;
- m.insert(MAP_KV("足球", 2));
- m.insert(MAP_KV("篮球", 6));
- m.insert(MAP_KV("羽毛球", 3));
- m.insert(MAP_KV("排球", 1));
- m.insert(MAP_KV("网球", 7));
-
- MAP_IT mit = m.begin();
- while (mit != m.end())
- {
- std::cout << mit->first << ":" << mit->second << std::endl;
- mit++;
- }
- std::cout << std::endl;
同set一样,map的key不允许修改
- typedef std::map<std::string, std::string> MAP;//简化map命名
- typedef std::pair<std::string, std::string> MAP_KV;//简化pair命名
- typedef std::map<std::string, std::string>::iterator MAP_IT;//简化迭代器命名
-
- MAP m;
- m.insert(MAP_KV("spring", "春天"));
- m.insert(MAP_KV("summer", "夏天"));
- m.insert(MAP_KV("autumn", "秋天"));
- m.insert(MAP_KV("winter", "冬天"));
-
- MAP_IT mit = m.begin();
- while (mit != m.end())
- {
- mit->first = "night";//修改key为night,报错
- mit++;
- }
- std::cout << std::endl;
报错:

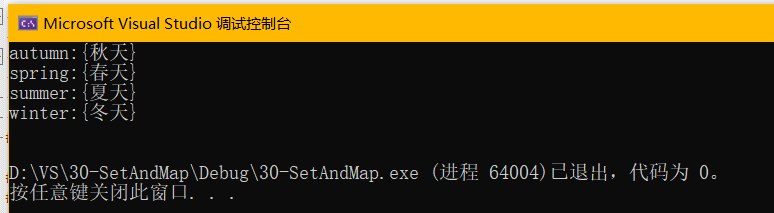
但是map的value可以修改:
先给中文翻译加上{ }
- MAP_IT mit = m.begin();
- while (mit != m.end())
- {
- mit->second.insert(0, "{");
- mit->second += "}";
- std::cout << mit->first << ":" << mit->second << std::endl;
- mit++;
- }
- std::cout << std::endl;
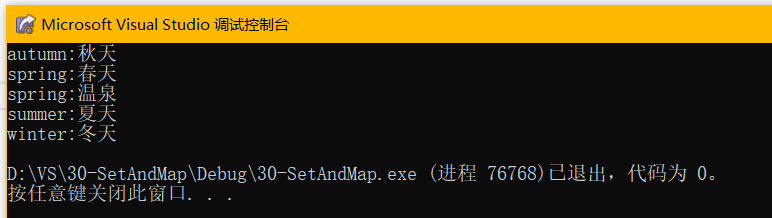
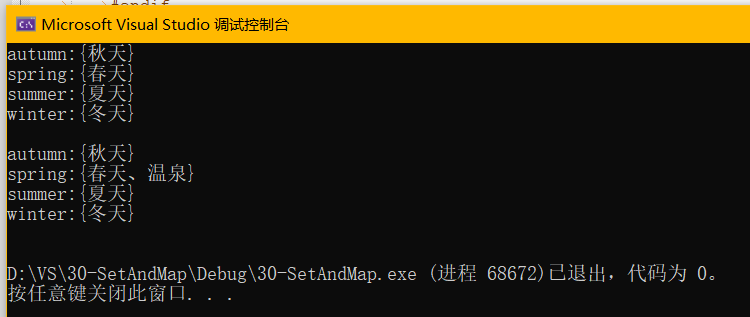
再给spring的中文翻译加上其他释义:
- auto ret = m.find("spring");
-
- mit = m.begin();
- if(ret != m.end())
- {
- std::string& str = ret->second;//用str作为ret->second的别名,因此控制的就是ret的second
- str.insert(str.size() - 1, "、温泉");
- }
-
- while (mit != m.end())
- {
- std::cout << mit->first << ":" << mit->second << std::endl;
- mit++;
- }
- std::cout << std::endl;
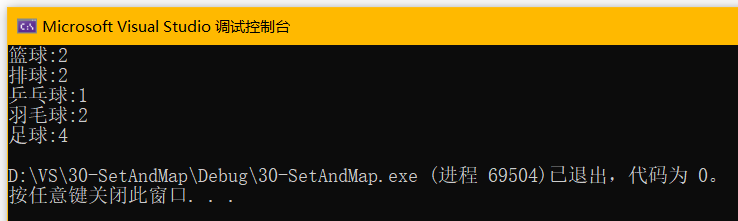
map也可以用来统计次数,比如找出大家最喜欢的球类,统计技术有3种方式:
第一种方式:找到就增加次数,否则就插入
- //1.统计次数
- string arr[] = { "篮球","足球","排球","羽毛球","足球","乒乓球","足球","排球","羽毛球","篮球","足球" };
- map<string, int> countMap;
- for (const auto& str : arr)
- {
- map<string, int>::iterator ret = countMap.find(str);
- if (ret != countMap.end())//找到了,只增加次数
- {
- ret->second++;
- }
- else//没找到就插入
- {
- countMap.insert(make_pair(str, 1));
- }
- }
-
- //2.找出大家最喜欢的球类
- for (const auto& e : countMap)
- {
- cout << e.first << ":" << e.second << endl;
- }
第二种方式:由于insert的返回值类型为pair<iterator, bool>,pair中的第二个值类型为bool,向map中插入时,如果map中已经有了,pair返回的第一个值为插入值所在节点的迭代器,第二个值就为false,否则pair返回的第一个值为插入值所在节点的迭代器,第二个值就为true。
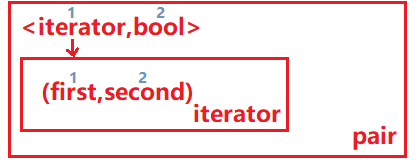
pair<iterator,bool> insert (const value_type& val);因此第二种方式根据插入的返回值pair的第二个值判断为true还是false,决定返回的pair的第一个值即迭代器的第二个值是否++:
- string arr[] = { "篮球","足球","排球","羽毛球","足球","乒乓球","足球","排球","羽毛球","篮球","足球" };
- map<string, int> countMap;
-
- //先插入,如果str已经在map中,insert会返回str所在节点的迭代器,++次数即可
- for (const auto& str : arr)
- {
- //pair<map<string,int>::iterator,bool> ret = countMap.insert(make_pair(str, 1));//可用auto推导
- auto ret = countMap.insert(make_pair(str, 1));
- if (ret.second == false)
- {
- ret.first->second++;
- }
- }
-
- for (const auto& e : countMap)
- {
- cout << e.first << ":" << e.second << endl;
- }

第三种方式:借助计数排序思想,使用operator[ ]运算符重载获取value
mapped_type& operator[] (const key_type& k);//返回k对应的value的引用返回:
(*((this->insert(make_pair(k,mapped_type()))).first)).second即:
- mapped_type& operator[](const key_type& k)
- {
- pair<iteerator, bool> ret = insert(make_pair(k, mapped_type()));
- return ret.first->second;
- }
operator[ ]的本质就是插入:
①如果k不在map中,先插入<k,V( )>,返回节点中V对象的引用
②如果k已经在map中,返回k所在节点中对应V对象的引用
- //第三种统计方法-计数排序
- string arr[] = { "篮球","足球","排球","羽毛球","足球","乒乓球","足球","排球","羽毛球","篮球","足球" };
- map<string, int> countMap;
-
- for (const auto& str : arr)
- {
- countMap[str]++;//等价于countMap.operator[](str),会调用mapped type()的默认构造函数构造一个匿名对象。其中str是key,++的是key对应的value,即返回值
- }
-
- for (const auto& e : countMap)
- {
- cout << e.first << ":" << e.second << endl;
- }
这三种方式中,operator[ ]最简洁,更好使用。
计数结束后,排序有2种方式:
第一种排序:用sort排序
可以使用sort进行排序,先包含sort的头文件:
#include<algorithm>vector里面如果要存pair,得把每个pair拿出来拷贝,再插入到vector中,而且string是深拷贝,代价大。
sort要排序,必须支持整数比较大小,传的是迭代器,迭代器指向的数据必须要能比较大小,v里面存的是pair,需要重载pair的比较大小。 sort的第3个参数是compare,要传对象,用实际对象推compare的类型,可以用仿函数比较,给sort的第3个参数传个匿名对象
sort的第3个参数是Compare比较方式,默认是按小于比较的,要找排名前面的球类,必须要传入大于的比较方式,就需要重新写仿函数:
- template <class RandomAccessIterator, class Compare>
- void sort(RandomAccessIterator first, RandomAccessIterator last, Compare comp);
大于的比较方式的仿函数:
- struct MapItCompare
- {
- bool operator()(map<string, int>::iterator x, map<string, int>::iterator y)
- {
- return x->second > y->second;
- }
- };
- void Map_test2()
- {
- string arr[] = { "篮球", "足球", "排球", "羽毛球", "足球", "乒乓球", "足球", "排球", "羽毛球", "篮球", "足球" };
- 1.统计计数
- map<string, int> countMap;
- for (const auto& str : arr)
- {
- countMap[str]++;
- }
-
- 2.排序(第一种用sort排序)
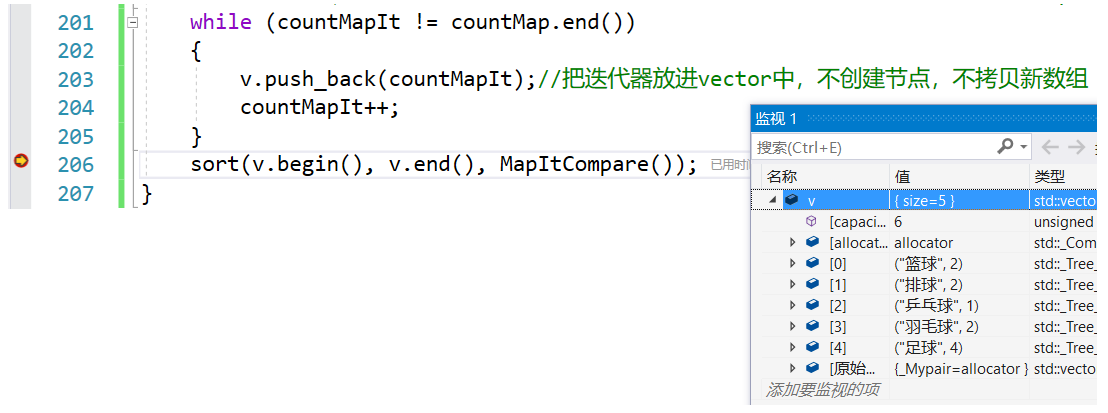
- vector<map<string, int>::iterator> v;
- map<string, int>::iterator countMapIt = countMap.begin();
-
- while (countMapIt != countMap.end())
- {
- v.push_back(countMapIt);//把迭代器放进vector中,不创建节点,不拷贝新数组
- countMapIt++;
- }
- sort(v.begin(), v.end(), MapItCompare());
- }
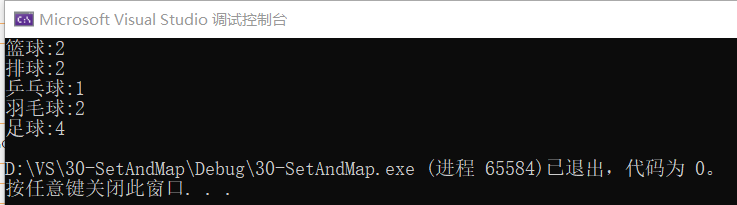
统计计数完毕后:
排序完毕后:

这就找出了排名前3的球类。
第二种排序:用map排序:map这个结构是天生的可以用来排序的结构,不过map的比较方式默认是less,也就是按照升序排的:
- template < class Key, // map::key_type
- class T, // map::mapped_type
- class Compare = less<Key>, // map::key_compare
- class Alloc = allocator<pair<const Key,T> > // map::allocator_type
- > class map;
但是现在需要按照降序排,就要传比较方式:
- //第二种排序,借助map排序
- map<int, string,greater<int>> sortMap;//将次数作为first,将字符串作为second,比较方式为大于greater
- for (auto e : countMap)
- {
- sortMap.insert(make_pair(e.second, e.first));
- }
由于int作为key,所以有相同key的球类只存第一种,篮球、排球和羽毛球的个数都是2(举的例子有点不恰当,应该往所有球类的个数都不相同),只会出现篮球,不会出现排球和羽毛球:
这种方式用了拷贝,如果不想拷贝的话,可以存到set中。
第三种排序方式:
给set的迭代器传个仿函数:
- // 利用set排序 --不拷贝pair数据
- set<map<string, int>::iterator, MapItCompare> sortSet;//set传模板参数,传MapItCompare类型
- countMapIt = countMap.begin();
- while (countMapIt != countMap.end())
- {
- sortSet.insert(countMapIt);
- ++countMapIt;
- }
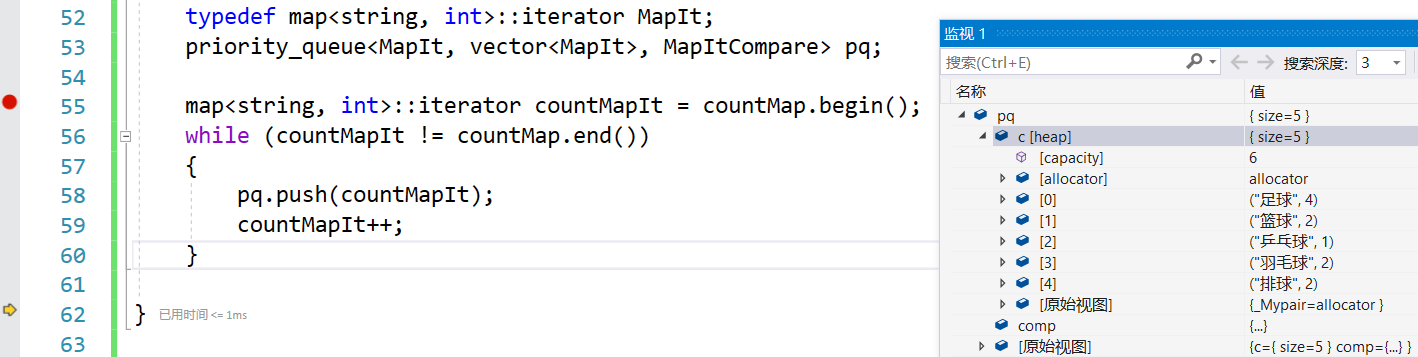
第四种比较方式: 用优先级队列,向优先级队列中存放迭代器,减少拷贝,要找个数最大的,要建小堆
- struct MapItCompare
- {
- bool operator()(map<string, int>::iterator x, map<string, int>::iterator y)
- {
- return x->second < y->second;
- }
- };
- typedef map<string, int>::iterator MapIt;
- priority_queue<MapIt, vector<MapIt>, MapItCompare> pq;
-
- map<string, int>::iterator countMapIt = countMap.begin();
- while (countMapIt != countMap.end())
- {
- pq.push(countMapIt);
- countMapIt++;
- }
堆顶元素就是找到的个数最多的球类,足球:
(4)删除erase( )
size_type erase (const key_type& k);//通过k删除- map<string, string> dict;
- dict.insert(make_pair("spring", "春天"));
- dict["spring"] += "、温泉";
- dict["summer"] = "夏天";
- dict["autumn"] = "秋天";
- dict["winter"] = "冬天";
-
- auto mit = dict.begin();//同map<string, int>::iterator mit = m.begin();
- while (mit != dict.end())
- {
- cout << mit->first << ":" << mit->second << endl;
- mit++;
- }
- cout << endl;
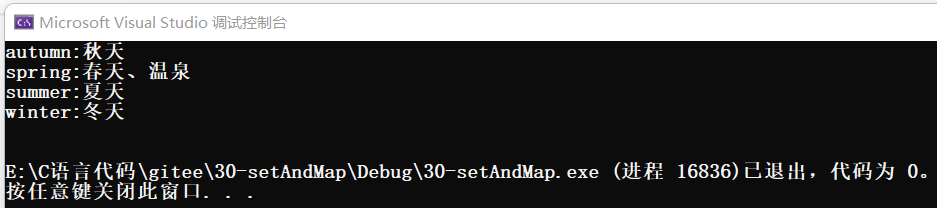
dict.erase("spring");再遍历打印:
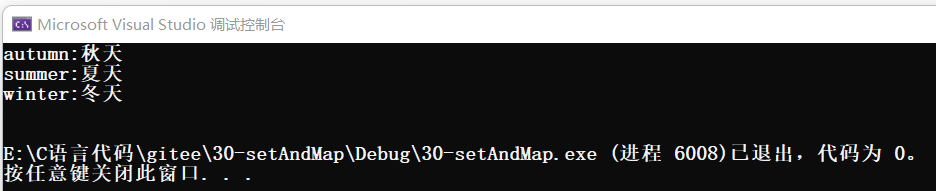
四、multiset 和 multimap
set中和map中存储的元素不可以重复,但是multiset和multimap中的元素是可以重复的,它们中的元素不可以修改,但是可以插入和删除:
multiset:头文件为#include<set>
- template < class T, // multiset::key_type/value_type
- class Compare = less<T>, // multiset::key_compare/value_compare
- class Alloc = allocator<T> > // multiset::allocator_type
- > class multiset;
- multiset<int> mls1;
- int arr[] = { 2,3,2,5,3,3};
-
- mls1.insert(arr, arr + 6);
- for (auto e : mls1)
- {
- cout << e << endl;
- }
允许存在key相同的元素: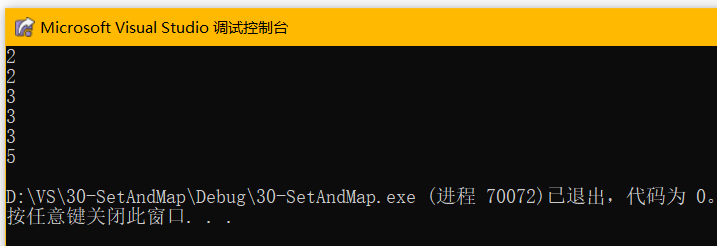
multimap:头文件为#include<map>
- template < class Key, // multimap::key_type
- class T, // multimap::mapped_type
- class Compare = less<Key>, // multimap::key_compare
- class Alloc = allocator<pair<const Key,T> > // multimap::allocator_type
- > class multimap;
- multimap<string,string> mlp1;
- mlp1.insert(make_pair("spring", "春天"));
- mlp1.insert(make_pair("summer", "夏天"));
- mlp1.insert(make_pair("autumn", "秋天"));
- mlp1.insert(make_pair("winter", "冬天"));
-
- mlp1.insert(make_pair("spring", "温泉"));
-
- for (auto e : mlp1)
- {
- cout << e.first << ":" << e.second << endl;
- }
允许存在key相同的pair: