spark应用程序的执行_spark 执行用户程序代码
赞
踩
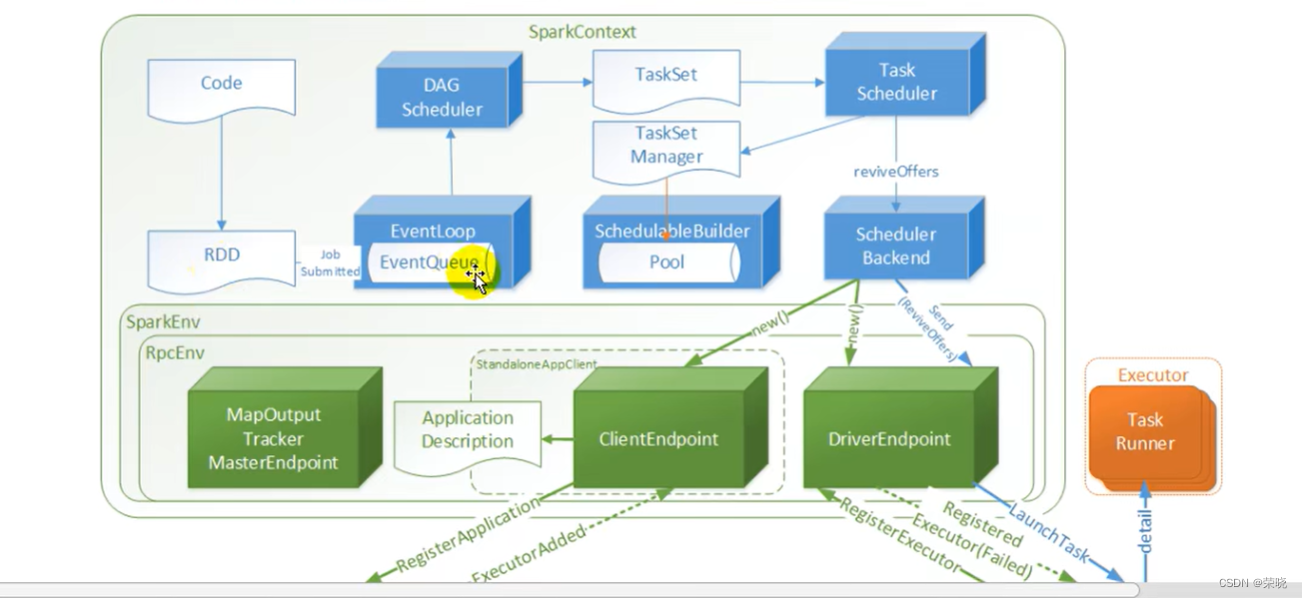
1 SparkContext -》{
sparkconf --配置对象,基础配置
sparkEnv --环境对象,通讯环境
SchedulerBackend --通讯后台 住哟啊用于和Executor之间进行通讯
TaskScheduler – 任务调度器 任务调度
DAGScheduler – 阶段调度器 阶段划分
}
spark.sparkContext.textFile("")
.flatMap(x => {
x.split(",")
}).groupBy(x => x).map { case (word, list) => {
(word, list.size)
}
}.collect()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
1.rdd依赖
1.value1=sc.textFile()
val rdd2=rdd1.flatMap [
new MapPartitionsRDD[U, T](this, (_, _, iter) => iter.flatMap(cleanF)) --外层的rdd把this(上一层的rdd包进去了,该对象依赖于this)
MapPartitionsRDD extends RDDU 【 rdd点进去
def this(@transient oneParent: RDD[_]) =
this(oneParent.context, List(new OneToOneDependency(oneParent))) --窄依赖传进去,rdd1为rdd2的父依赖
】
]
rdd2.groupby[
groupBy[
groupByKey[
combineByKeyWithClassTag[
ShuffledRDD extends RDD[(K, C)](prev.context, Nil) 【–Nil未传入依赖,这里用的是默认值
getDependencies 【
List(new ShuffleDependency
】
】
]
]
]
]

**
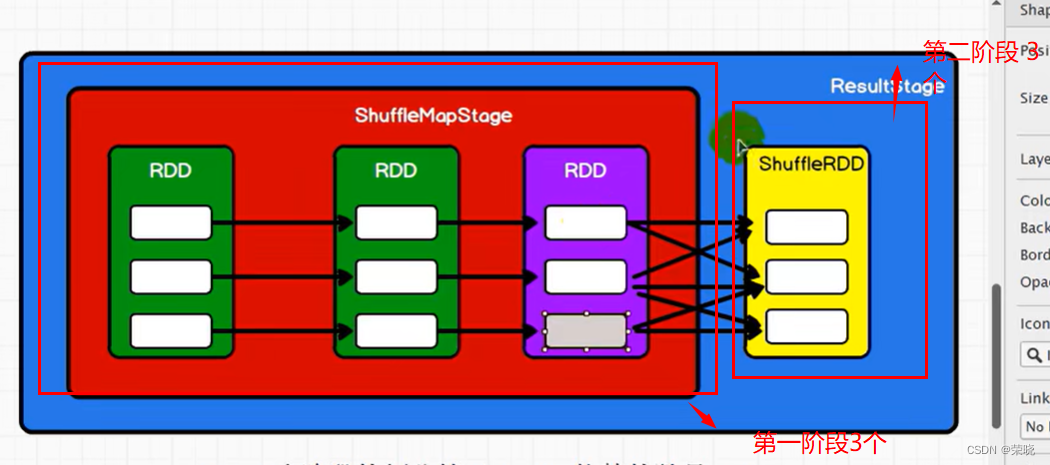
2.阶段划分 spark中阶段的划分等于shuffle依赖的数量+1
**
点击collect【
runJob【
runJob【
dagScheduler.runJob【
submitJob{
eventProcessLoop.post(JobSubmitted(
点post(eventQueue.put(event) --将事件放进去事件队列)[
eventThread { --该线程将事件取出来
val event = eventQueue.take()
try {
onReceive(event)} --实现类DAGSchedulerEventProcessLoop(
doOnReceive(event){
dagScheduler.handleJobSubmitted【–进行阶段的划分
createResultStage—创建结果阶段
val parents = getOrCreateParentStages(rdd, jobId)-》{–获取或创建上级阶段
getShuffleDependencies(rdd)->{
toVisit.dependencies --判断rdd中的依赖是否是shuffle依赖
}.map { shuffleDep =>
getOrCreateShuffleMapStage(shuffleDep, firstJobId)–获取或创建shuffleMap阶段,写磁盘之前的阶段(
createShuffleMapStage-》{
getOrCreateParentStages //判断是否还有shuffle依赖
new ShuffleMapStage
}
)
}.toList
}
new ResultStage
)
】
}
)
]
}
】
】
】
】
- task任务的切分,task总共任务是每个阶段最后一个rdd分区数量之和
回到方法handleJobSubmitted{
val job = new ActiveJob 阶段划分后,提交job
submitStage(finalStage)–提交阶段{
getMissingParentStages(stage)–看你有没有上一级的阶段
没有的话就
submitMissingTasks(stage, jobId.get)–提交任务{
val tasks: Seq[Task[_]] = 创建task{
case stage: ShuffleMapStage =>
partitionsToCompute-》{
= stage.findMissingPartitions()
}
然后返回点击 ShuffleMapStage -》{
override def findMissingPartitions(): Seq[Int] = {
mapOutputTrackerMaster
.findMissingPartitions(shuffleDep.shuffleId)
.getOrElse(0 until numPartitions) --看看
}
}
}
}
}
task数总共6个
4.任务的调度
类名:DAGScheduler
val tasks: Seq[Task[_]]
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptNumber, jobId, properties))
- 1
- 2
TaskSchedulerImpl 继承taskScheduler 并实现其submitTasks方法 {
val manager = createTaskSetManager(taskSet, maxTaskFailures)-【
new TaskSetManager(this, taskSet, maxTaskFailures, blacklistTrackerOpt) --封装了任务管理器
】
schedulableBuilder.addTaskSetManager --schedulableBuilder是一个调度器,根据调度模式生成不同的调度器(
实现类FIFOSchedulableBuilder:的该方法
rootPool.addSchedulable(manager),将任务管理器放到任务池里边
)
backend.reviveOffers() --取消息点进去实现类CoarseGrainedSchedulerBackend (
case ReviveOffers =>
makeOffers()-》【–得到任务的描述信息
scheduler.resourceOffers(workOffers) --取任务-》{
val sortedTaskSets = rootPool.getSortedTaskSetQueue.filterNot(_.isZombie)》{–得到排过序的taskset
schedulableQueue.asScala.toSeq.sortWith(taskSetSchedulingAlgorithm.comparator) --根据不同的调度策略使用不同的调度算法
}
for (currentMaxLocality <- taskSet.myLocalityLevels) --数据本地化,根据数据本地性,决定将数据和计算是否发送到同一个节点,移动数据不如移动计算
}
if (taskDescs.nonEmpty) {
launchTasks(taskDescs)–如果任务不为空,启动任务 -》{
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask))) --从任务池中取到的序列化后的任务,找到对应的executor的终端,发送启动任务的消息
}
}
】
)
}
5
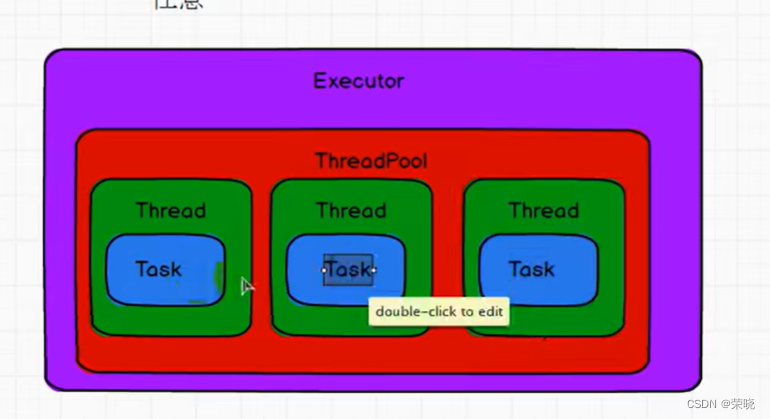
5.任务的执行
CoarseGrainedExecutorBackend收到启动任务的消息
receive -》{
case LaunchTask(data) =>
val taskDesc = TaskDescription.decode(data.value)–反序列化
executor.launchTask–开始执行 -》【
val tr = new TaskRunner(context, taskDescription) --计算对象中有一个线程池 -》(
val res = task.run --点进去{
runTask
}
)
runningTasks.put(taskDescription.taskId, tr)
threadPool.execute(tr)
】
}