
- 1图论+线性基高斯消元与主元:1019T2 / P4151
- 299%的时间里只使用这 14 个 Git 命令就够了!!!
- 3创建和使用约束Constraint
- 4从Paddle3D开始3D目标检测-测试版
- 5Feishu(飞书) 聊天机器人应用(3/3)- DevOps 机器人助手,管理 GitLab Issues,BOT 开源示例程序_飞书项目和devops结合
- 6Python 面向对象之封装和装饰器property_装饰器类封装
- 7用MapReduce对文件中各个单词出现的次数进行统计_编写mapreduce程序统计文件中单词的个数
- 8机器学习导论--1.机器学习理论基础详解_机器学习的理论基础
- 9在服务器(Ubuntu20.04)安装用户级别的cuda11.8(以及仿照前面教程安装cuda11.3后安装cudnn和pytorch1.9.0)_cuda11.8下载
- 10Mac设置终端代理快捷命令_mac 设置命令行代理
偏偏不信文心大模型4.0比肩GPT-4!我为它们安排了一场龙虎斗!_文心大模型4.0 写论文
赞
踩
作者 | 卖萌酱
大家好,我是卖萌酱。盲猜点进本文的不少小伙伴也看了昨天的百度世界大会,百度创始人、董事长兼CEO李彦宏官宣文心大模型4.0发布,其中一句话让卖萌酱印象深刻:文心大模型4.0综合水平与GPT-4相比已经毫不逊色!有图有证据:

敢在如此大的场合正式喊出这样的口号,以卖萌酱对百度的了解,说明这个测评至少在百度内部已经做的相当完善了,否则是不可能敢直接这样喊口号的。但卖萌酱多少觉得有点不可思议,这么短的时间内,真就赶上了GPT-4???话不多说,卖萌酱果断搞来了内测码——直!接!上!评!测!
评测维度
众所周知,卖萌酱此前第一时间评测了通义千问、百川智能、讯飞星火等国产大模型,也形成了一套case驱动的比较有意思的评测方式,可以让读者小伙伴们超出冷冰冰的榜单数字,更加真切的感受到两个大模型的真实效果对比。评测整体围绕模型的语言理解、推理、生成、知识、记忆这五个维度展开设计,设计了以下11类评测题:
-
干崩大模型的简单常识推理题
-
打败80%人类的中文语言理解题
-
再上点难度:语言理解+逻辑推理
-
成年人不擅长的古诗生成题
-
本土文化考察:90后专属非主流文字识别
-
弱智吧经典战役
-
知识问答:四大名著考察
-
GPT-4最擅长的数学计算
-
GPT-4最擅长的代码题
-
测测翻译腔
评测开始
干崩大模型的简单常识推理题
首先祭出这个曾经把全体大模型(包括文心一言3.5、通义千问、讯飞星火、ChatGPT等)都干崩了的常识推理Case:
文心大模型4.0

GPT-4

卖萌酱直接惊呆了。文心4.0完胜!几个月过去了,GPT-4还是做不对,但亲测文心4.0成为了目前全世界唯一一个把这个case做对的大模型。再来一题!
文心大模型4.0
GPT-4

都做对了,优秀!本题打平!
打败80%人类的中文语言理解题
在语言理解问题上,简单case测试没意义!来,直接上难度!
文心大模型4.0

GPT-4
好吧,不好意思,难度上调过头了,把文心4.0和GPT4.0都干懵了。这局打平。

再来一个!
文心大模型4.0

GPT-4

本以为这个case两个模型也都要翻车,没想到文心和GPT竟然都做对了,牛了牛了,本题打平。比不出来?那就再来一题!
文心大模型4.0
GPT-4

好吧,竟然又打平了。我承认你俩的语言理解能力都很强,不分伯仲:)
再上点难度:语言理解+逻辑推理
文心大模型4.0

GPT-4

虽然GPT-4和文心4.0答案都对了,但推理过程是错的,这局算打平!再来一道!
文心大模型4.0

GPT-4

可以看到,文心4.0逐步分析,展现出了清晰的推理逻辑,而 GPT-4 则明显晕了,效果惊艳,文心4.0胜!
成年人不擅长的古诗生成题
随手写诗太简单,来,给你们上点难度!
文心大模型4.0

GPT-4

牛了,果然还是百度更懂中文。文心4.0胜!
本土文化考察:90后专属非主流文字识别
80、90后一定还记得当年在QQ空间上流行的非主流文字,来,看看你俩有没有刷过QQ空间!
文心大模型4.0
GPT-4
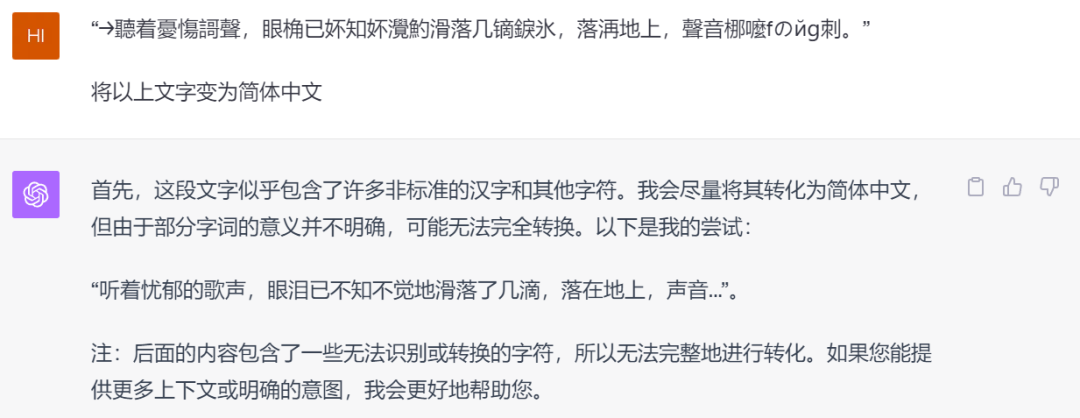
果然,通过这道题,能看出百度是有20年前的互联网记忆的,OpenAI在本土化方面的表现被百度碾压,符合预期!
弱智吧经典战役
这就必须祭出每逢大模型发布时,卖萌酱的必考题:
文心大模型4.0
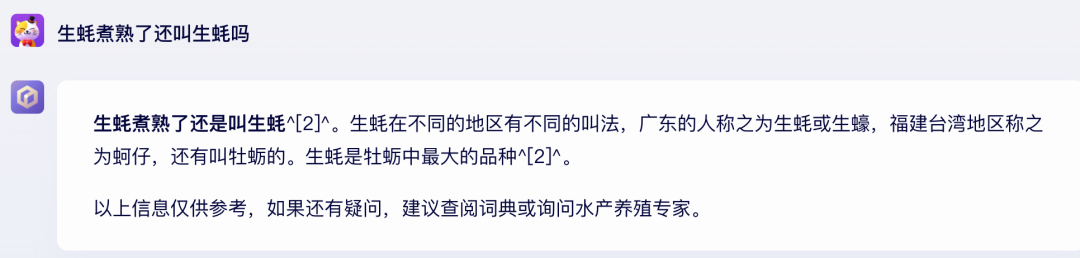
GPT-4
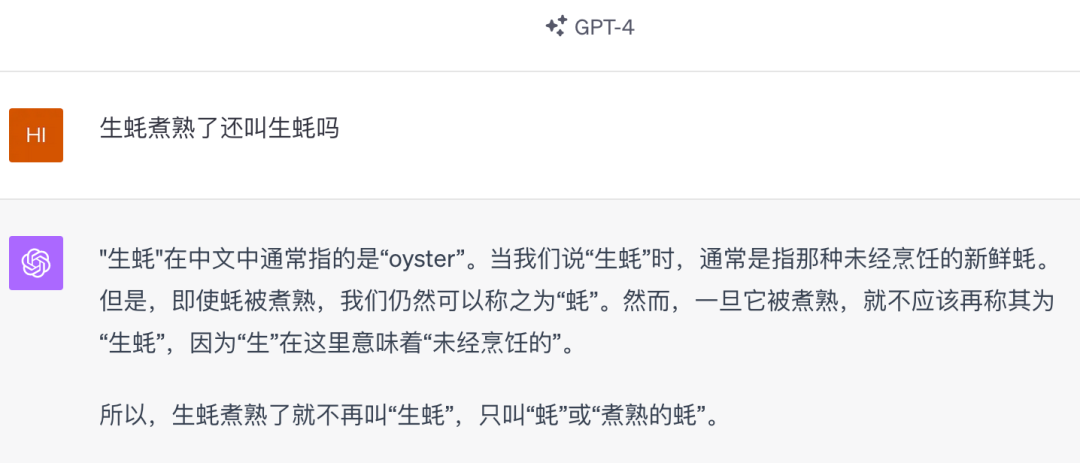
文心4.0完胜!GPT-4太失败了,时隔半年,它还是认为生蚝煮熟后就变成了熟蚝。哦不对,它进化了,它现在认为煮熟后叫做“蚝”或者“煮熟的蚝”。

知识问答:四大名著考察
相信大家已经通过上面的评测感受到了文心4.0在中文语言理解等方面对GPT-4形成的碾压。OK,我们继续出击,接着考察一下两个模型对四大名著的掌握程度。
文心4.0

GPT-4

离大谱!GPT-4不仅真的胡乱编造起来林黛玉倒拔垂杨柳的故事,连孙悟空、观音都搬出来了。

GPT-4最擅长的数学计算
在卖萌酱之前的评测中,GPT-4的数学计算完爆一众国产模型。来,时刻半年,再来PK一波!
文心大模型4.0
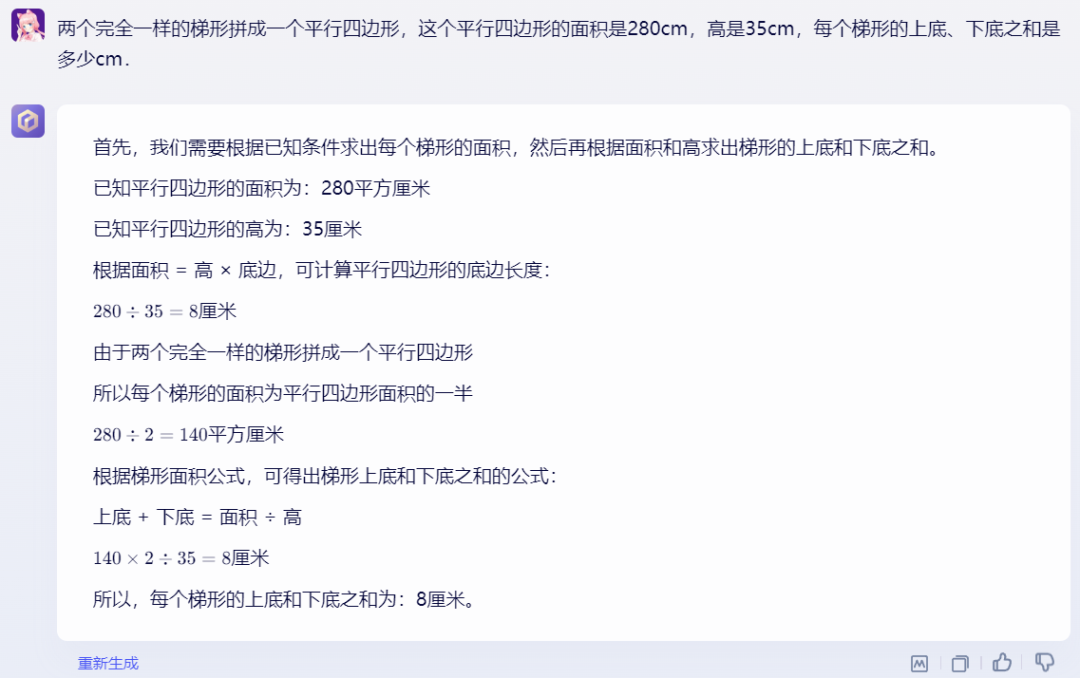
GPT-4

芜湖!GPT-4竟然答错了,文心4.0在这道数学计算题上赢了GPT-4!当然这只是一个例子,有兴趣的小伙伴可以找更多case进行测试。
GPT-4最擅长的代码题
直接上NLP算法工程师最熟悉的分词算法,看看NLP大模型对NLP算法的理解能力。
文心大模型4.0



GPT-4
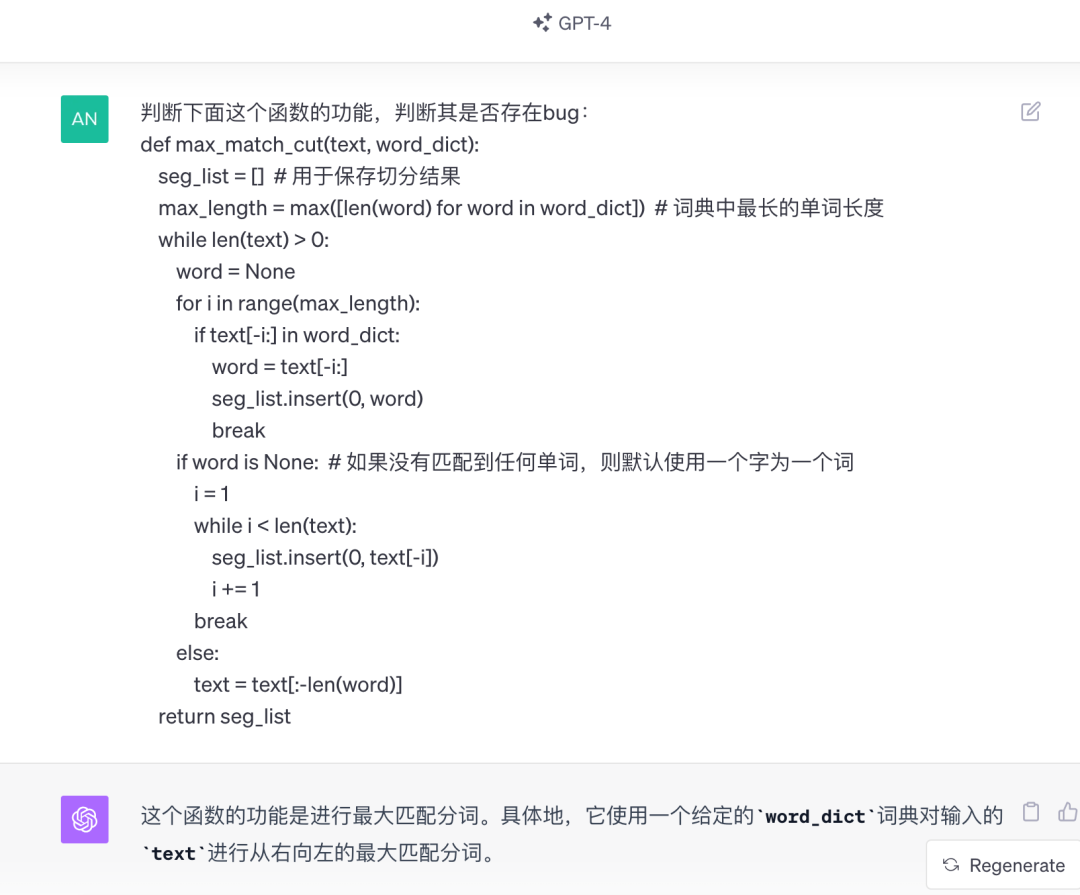

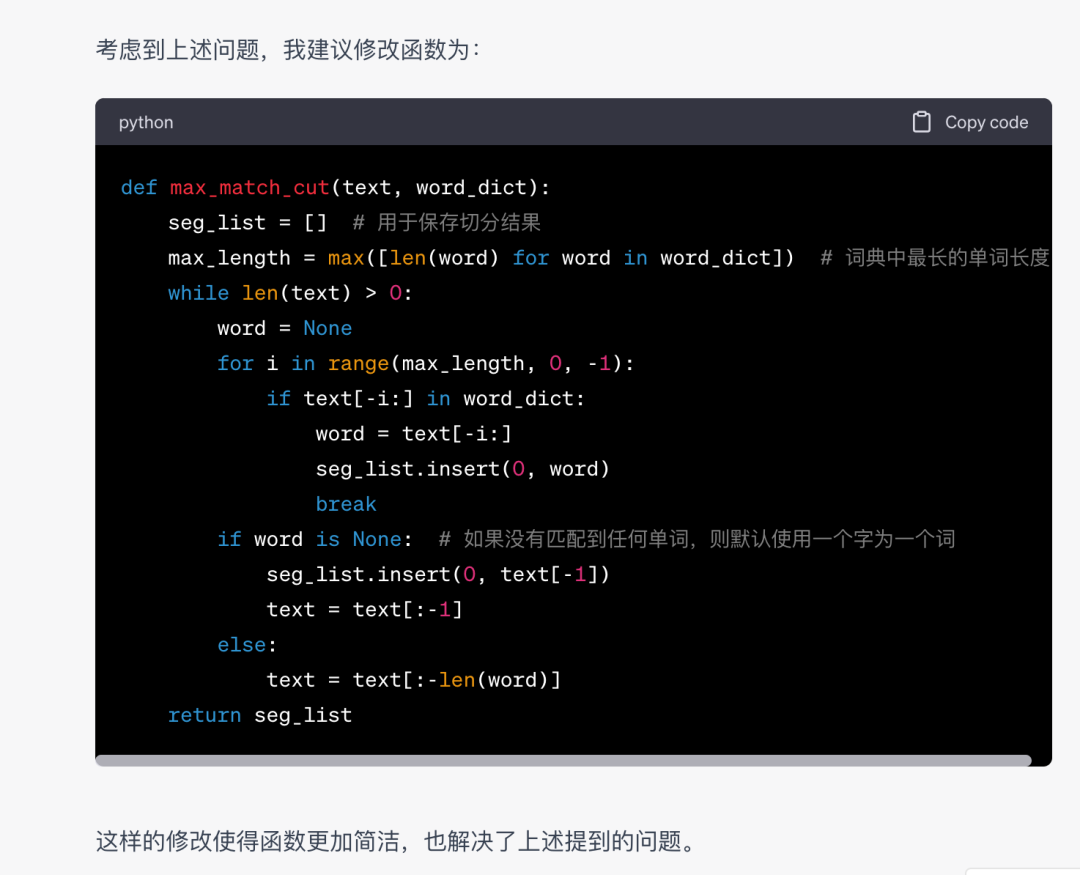
文心大模型4.0的代码能力的确有了不错的提升,本题打平!
测测翻译腔
做机器翻译容易,但想要翻译出来的内容非常地道,不带翻译腔,其实很难。
文心大模型4.0

GPT-4

仔细对比下,文心4.0的英翻中的结果翻译腔明显更弱,翻译的更加地道,本题文心4.0胜!再来一道!
文心大模型4.0

GPT-4

这道题,是真牛了,文心4.0竟然翻译成了古诗…文心4.0胜!好啦,Case层面就测试到这里。需要注意的是,由于case有限,尽管从这不到20个case中,看起来文心大模型4.0效果比GPT-4效果好很多,但实际上由于测试类型覆盖不够全,因此不能得出置信的文心大模型4.0比GPT-4强的结论,仅能作为一个对两个大模型能力特色的感性认知。整体上,卖萌酱感觉非常的超出预期,文心大模型4.0相比3.5版本的提升实在是太太太太太大了!这也难怪,李彦宏可以这么自信的做官宣。
一些想法
最后,卖萌酱想借此重要的时间节点,谈一谈自己的看法。伴随着8月底《生成式人工智能服务管理暂行办法》的颁布,国产大模型开始从“做出来”走向“用起来”。用?好不好用?怎么用?当下大模型作为通用人工智能的“基础模型”,整个生成式 AI 赋予全产业万亿级别的想象力几乎都基于这些大模型的综合能力。那么,什么是大模型的综合能力?如果从人类智能上推及己身,人类可以对基于复杂自然语言或图像的符号进行理解与处理,对抽象符号的理解奠定了智能产生的基础,人类智能也可以流畅地输出符合语法规范且有意义的语言符号。此外,人类具有更加高级的逻辑推理与判断的能力,这类逻辑能力可以排除许多“不可行解”,使得人类智能可以高效的完成任务。最后,人类智能还具有记忆的能力,我们可以顺畅的和任何一个人进行多轮的对话,对话间的上下文信息都可以被我们的大脑储存,从单轮到多轮,记忆能力赋予了智能更大的想象空间。简单归纳,大模型带来的智能涌现,主要体现在理解、生成、逻辑与记忆四大能力之上。 然而一直以来,国内外无数大模型测评榜单来来去去回回,其中哪怕是在中文能力之上,始终位居榜首纹丝不动的仍然是目前世界上最先进的大模型——GPT-4。早在世界大会之前,文心大模型4.0要来了的爆料早早就在坊间里疯传,关于文心4.0到底能不能打过 GPT-4 的讨论热闹非凡,包括小瑶读者群里也有不少讨论。而昨天伴随着文心大模型4.0的发布,经卖萌酱测评后,可以带有主观色彩的给出答案了:“文心大模型4.0综合水平与GPT-4相比确实已经毫不逊色!”

事实上,对于任何一个目标朝向通用人工智能的大模型而言,理解、生成、逻辑、记忆这四大能力并不是严格可分互相排斥的,在几乎所有的大模型落地场景之中,比如文本生成创作、代码辅助、智能解题等等都依赖于四大能力的通力配合。这四大能力相辅相成,才有可能敲开未来 AI 原生应用时代的大门。通过上面从四大能力出发并且不断切换不同展示能力的视角与问题,可以看到文心大模型4.0已然在综合能力上可以逼近并比肩 GPT-4,甚至在一些强调文化背景的问题中展现了超越 GPT-4 的态势。然而,在大模型目前飞速发展急速迭代的今天,文心大模型4.0综合能力比肩 GPT-4 的意义,不仅仅是在某一个单一的数据集、单一的指标中小小的超越或做到了一些 GPT-4 没有做到的事。也许正如李彦宏在百度世界大会上谈到的那样:“大模型带来的智能涌现,是开发AI原生应用的基础。”文心大模型在4.0时代综合能力的进化,是为未来一个智能时代的到来奠基。除了文心大模型4.0以外,2023百度世界上还展现了基于基础模型带来的搜索、GBI、文库、网盘、地图等十余款应用。这些基于基础模型的 AI 原生应用才是文心大模型4.0比肩 GPT-4 的真正意义!百度,或许已经占据了AI原生时代的高地。

- 不允许mysql ...
赞
踩

