
【Pytorch神经网络实战案例】31 TextCNN模型分析IMDB数据集评论的积极与消极
赞
踩

卷积神经网络不仅在图像视觉领域有很好的效果,而且在基于文本的NLP领域也有很好的效果。TextCN如模型是卷积神经网络用于文本处理方面的一个模型。
在TextCNN模型中,通过多分支卷积技术实现对文本的分类功能。
1 TextCNN
1.1 TextCNN模型结构
TexCNN模型是利用卷积神经网络对文本进行分类的模型,该模型的结构可以分为以下4个层次:
1.1.1 词嵌入层
将每个词对应的向量转化成多维度的词嵌入向量,将每个句子当作一幅图来进行处理(词的个数词×嵌入向量维度)。
1.1.2 多分支卷积层
使用3、4、5等不同大小的卷积核对词嵌入转化后的句子做卷积操作,生成大小不同的特征数据。
1.1.3 多分支全局最大池化层
对多分支卷积层中输出的每个分支的特征数据做全局最大池化操作。
1.1.4 全连接分类输出层
将池化后的结果输入全连接网络中,输出分类个数,得到最终结果。
1.2 TextCNN模型图解
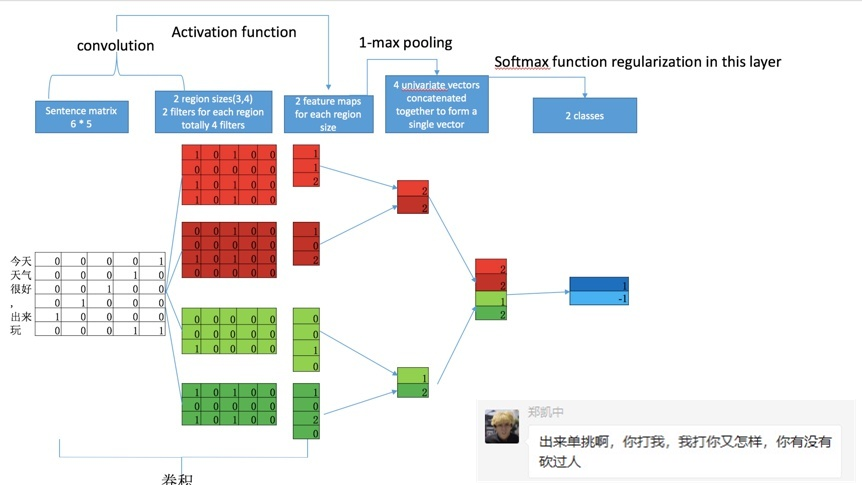
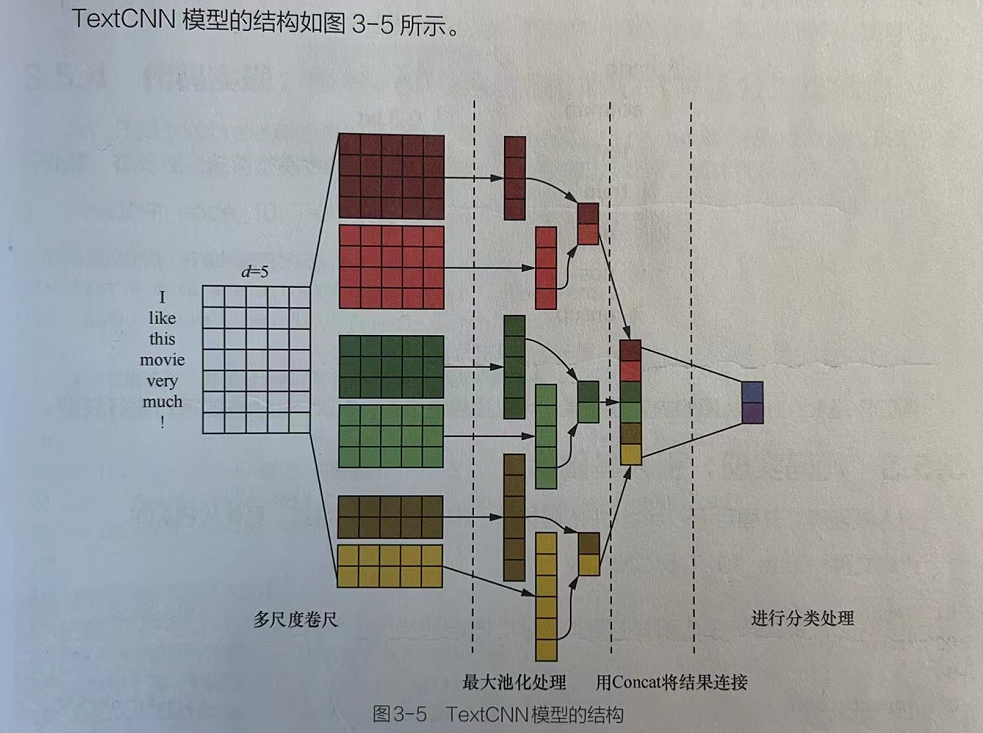
因为卷积神经网络具有提取局部特征的功能,所以可用卷积神经网络提取句子中类似N-Gram算法的关键信息。
1.3 数据集IMDB
MDB数据集相当于图片处理领域的MNIST数据集,在NLP任务中经常被使用。
1.3.1 IMDB结构组成
IMDB数据集包含50000条评论,平均分成训练数据集(25000条评论)和测试数据集(25000条评论)。标签的总体分布是平衡的(25000条正面评论和25000条负面评论)。
另外,还包括额外的50000份无标签文件,用于无监督学习。
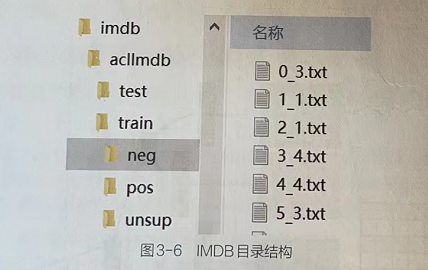
1.3.2 IMDB文件夹组成
IMDB数据集主要包括两个文件夹train与test,分别存放训练数据集与测试数据集。每个文件夹中都包含正样本和负样本,分别放在pos与neg子文件中。rain文件夹下还额外包含一个unsup子文件夹,用于非监督训练。
1.3.3 IMDB文件命名规则
每个样本文件的命名规则为“序号_评级”。其中“评级”可以分为0~9级。
IMDB是torchtext库的内置数据集,可以直接通过运行torchtext库的接口进行获取。
2 代码实现:TextCNN模型分析IMDB数据集评论的积极与消极
2.1 案例描述
同一个记录评论语句的数据集,分为正面和负面两种情绪。通过训练,让模型能够理解正面与负面两种情绪的语义,并对评论文本进行分类。
2.1.1 案例理解分析
本例的任务可以理解为通过句子中的关键信息进行语义分类,这与TextCNN模型的功能是相匹配的。TextCNN模型中使用了池化操作,在这个过程中丢失了一些信息,所以导致该模型所表征的句子特征有限。如果要使用处理相近语义的分类任务,则还需要对其进一步进行调整。
2.2 代码实现:引入基础库: 固定PyTorch中的随机种子和GPU运算方式---TextCNN.py(第1部分)
- # 1.1 引入基础库: 固定PyTorch中的随机种子和GPU运算方式。
- import random #引入基础库
- import time
- import torch#引入PyTorch库
- import torch.nn as nn
- import torch.nn.functional as F
- from torchtext.legacy import data ,datasets,vocab #引入文本处理库
- import spacy
-
- torch.manual_seed(1234) # 固定随机种子,使其每次运行时对权重参数的初始化值一致。
- # 固定GPU运算方式:提高GPU的运算效率,通常PyTorch会调用自动寻找最适合当前配置的高效算法进行计算,这一过程会导致每次运算的结果可能出现不一致的情况。
- torch.backends.cudnn.deterministic = True # 表明不使用寻找高效算法的功能,使得每次的运算结果一致。[仅GPU有效]
2.3 代码实现:用torchtext加载IMDB并拆分为数据集---TextCNN.py(第2部分)
- # 1.2 用torchtext加载IMDB并拆分为数据集
- # IMDB是torchtext库的内置数据集,可以直接通过torchtext库中的datasets.MDB进行处理。
- # 在处理之前将数据集的字段类型和分词方法指定正确即可。
-
- # 定义字段,并按照指定标记化函数进行分词
- TEXT = data.Field(tokenize = 'spacy',lower=True) # data.Field函数指定数据集中的文本字段用spaCy库进行分词处理,并将其统一改为小写字母。tokenize参数,不设置则默认使用str。
- LABEL = data.LabelField(dtype=torch.float)
-
- # 加载数据集,并根据IMDB两个文件夹,返回两个数据集。
- # datasets.MDB.splits()进行数据集的加载。该代码执行时会在本地目录的.data文件夹下查找是否有MDB数据集,如果没有,则下载;如果有,则将其加载到内存。
- # 被载入内存的数据集会放到数据集对象train_data与test_data中。
- train_data , test_data = datasets.IMDB.splits(text_field=TEXT,label_field=LABEL)
- print("-----------输出一条数据-----------")
- # print(vars(train_data.example[0]),len(train_data.example))
- print(vars(train_data.examples[0]),len(train_data.examples))
- print("---------------------------")
-
- # 将训练数据集再次拆分
- # 从训练数据中拆分出一部分作为验证数据集。数据集对象train_data的split方法默认按照70%、30%的比例进行拆分。
- train_data,valid_data = train_data.split(random_state = random.seed(1234))
- print("训练数据集: ", len(train_data),"条")
- print("验证数据集: ", len(valid_data),"条")
- print("测试数据集: ", len(test_data),"条")
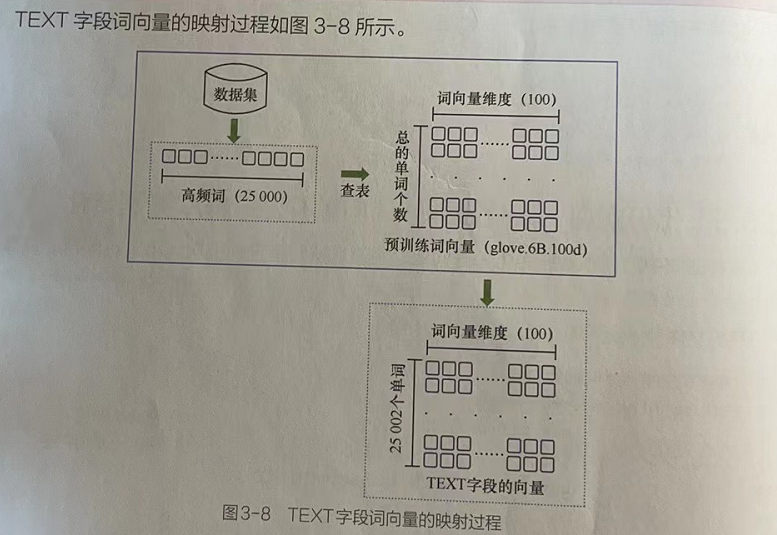
2.4 代码实现:加载预训练词向量并进行样本数据化---TextCNN.py(第3部分)
- # 1.3 加载预训练词向量并进行样本数据化
- # 将数据集中的样本数据转化为词向量,并将其按照指定的批次大小进行组合。
- # buld_vocab方法实现文本到词向量数据的转化:从数据集对象train_data中取出前25000个高频词,并用指定的预训练词向量glove.6B.100d进行映射。
- TEXT.build_vocab(train_data,max_size=25000,vectors="glove.6B.100d",unk_init = torch.Tensor.normal_) # 将样本数据转化为词向量
- # glove.6B.100d为torchtext库中内置的英文词向量,主要将每个词映射成维度为100的浮点型数据,该文件会被下载到本地.vector_cache文件夹下。
- LABEL.build_vocab(train_data)
- # ---start---创建批次数据:将数据集按照指定批次进行组合。
- BATCH_SIZE = 64
- device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
- train_iterator, valid_iterator, test_iterator = data.BucketIterator.splits((train_data, valid_data, test_data), batch_size = BATCH_SIZE, device = device)
- # ---end---创建批次数据:将数据集按照指定批次进行组合。
2.5 代码实现:定义带有Mish激活函数的TextCNN模型---TextCNN.py(第4部分)
- class Mish(nn.Module):
- def __init__(self):
- super(Mish, self).__init__()
- def forward(self,x):
- x = x * (torch.tanh(F.softplus(x)))
- return x
-
- # 在TextCNN类中,一共有两个方法:
- # ①初始化方法.按照指定个数定义多分支卷积层,并将它们统一放在nn.ModuleList数组中。
- # ②前向传播方法:先将输入数据依次输入每个分支的卷积层中进行处理,再对处理结果进行最大池化,最后对池化结果进行连接并回归处理
- class TextCNN(nn.Module): #定义TextCNN模型
- # TextCNN类继承了nn.Module类,在该类中定义的网络层列表必须要使用nn.ModuleList进行转化,才可以被TextCNN类识别。
- # 如果直接使用列表的话,在训练模型时无法通过TextCNN类对象的parameters方法获得权重。
- # 定义初始化方法
- def __init__(self, vocab_size, embedding_dim, n_filters, filter_sizes, output_dim,dropout, pad_idx):
- super().__init__()
- self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx = pad_idx) # 定义词向量权重
- # 定义多分支卷积层
- # 将定义好的多分支卷积层以列表形式存放,以便在前向传播方法中使用。
- # 每个分支中卷积核的第一个维度由参数filter_sizes设置,第二个维度都是embedding_dim,即只在纵轴的方向上实现了真正的卷积操作,在横轴的方向上是全尺度卷积,可以起到一维卷积的效果。
- self.convs = nn.ModuleList([nn.Conv2d(in_channels = 1,out_channels = n_filters,kernel_size = (fs, embedding_dim))
- for fs in filter_sizes]) #########注意不能用list
- # 定义输出层
- self.fc = nn.Linear(len(filter_sizes) * n_filters, output_dim)
- self.dropout = nn.Dropout(dropout)
- self.mish = Mish() # 实例化激活函数对象
-
- # 定义前向传播方法
- def forward(self,text): # 输入形状为[sent len,batch size]
- text = text.permute(1, 0) # 将形状变为[batch size, sent len]
- embedded = self.embedding(text) # 对于输入数据进行词向量映射,形状为[batch size, sent len, emb dim]
- embedded = embedded.unsqueeze(1) # 进行维度变化,形状为[batch size, 1, sent len, emb dim]
- # len(filter_sizes)个元素,每个元素形状为[batch size, n_filters, sent len - filter_sizes[n] + 1]
- # 多分支卷积处理
- conved = [self.mish(conv(embedded)).squeeze(3) for conv in self.convs] # 将输入数据进行多分支卷积处理。该代码执行后,会得到一个含有len(fiter_sizes)个元素的列表,其中每个元素形状为[batchsize,n_filters,sentlen-fltersizes[n]+1],该元素最后一个维度的公式是由卷积公式计算而来的。
- # 对于每个卷积结果进行最大池化操作
- pooled = [F.max_pool1d(conv, conv.shape[2]).squeeze(2) for conv in conved]
- # 将池化结果进行连接
- cat = self.dropout(torch.cat(pooled, dim=1)) # 形状为[batch size, n_filters * len(filter_sizes)]
- return self.fc(cat) # 输入全连接,进行回归输出
2.6 代码实现:用数据集参数实例化模型---TextCNN.py(第5部分)
- # 1.5 用数据集参数实例化模型
- if __name__ == '__main__':
- # 根据处理好的数据集参数对TextCNN模型进行实例化。
- INPUT_DIM = len(TEXT.vocab) # 25002
- EMBEDDING_DIM = TEXT.vocab.vectors.size()[1] # 100
- N_FILTERS = 100 # 定义每个分支的数据通道数量
- FILTER_SIZES = [3, 4, 5] # 定义多分支卷积中每个分支的卷积核尺寸
- OUTPUT_DIM = 1 # 定义输出维度
- DROPOUT = 0.5 # 定义Dropout丢弃率
- PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token] # 定义填充值:获取数据集中填充字符对应的索引。在词向量映射过程中对齐数据时会使用该索引进行填充。
- # 实例化模型
- model = TextCNN(INPUT_DIM, EMBEDDING_DIM, N_FILTERS, FILTER_SIZES, OUTPUT_DIM, DROPOUT, PAD_IDX)
2.7 代码实现:用预训练词向量初始化模型---TextCNN.py(第6部分)
- # 1.6 用预训练词向量初始化模型:将加载好的TEXT字段词向量复制到模型中,为其初始化。
- # 复制词向量
- model.embedding.weight.data.copy_(TEXT.vocab.vectors)
- # 将填充的词向量清0
- UNK_IDX = TEXT.vocab.stoi[TEXT.unk_token]
- model.embedding.weight.data[UNK_IDX] = torch.zeros(EMBEDDING_DIM) #对未识别词进行清零处理 :使该词在词向量空间中失去意义,目的是防止后面填充字符对原有的词向量空间进行干扰。
- model.embedding.weight.data[PAD_IDX] = torch.zeros(EMBEDDING_DIM) #对填充词进行清零处理 :使该词在词向量空间中失去意义,目的是防止后面填充字符对原有的词向量空间进行干扰。
2.8 代码实现:使用Ranger优化器训练模型---TextCNN.py(第7部分)
- # 1.7 使用Ranger优化器训练模型
- import torch.optim as optim # 引入优化器库
- from functools import partial # 引入偏函数库
- from ranger import * # 载入Ranger优化器
-
- # 为Ranger优化器设置参数
- opt_func = partial(Ranger, betas=(.9, 0.99), eps=1e-6) # betas=(Momentum,alpha)
- optimizer = opt_func(model.parameters(), lr=0.004)
- # 定义损失函数
- criterion = nn.BCEWithLogitsLoss() # nn.BCEWithLogitsLoss函数是带有Sigmoid函数的二分类交叉熵,即先对模型的输出结果进行Sigmoid计算,再对其余标签一起做Cross_entropy计算。
- # 分配运算资源
- model = model.to(device)
- criterion = criterion.to(device)
-
- # 定义函数,计算精确率
- def binary_accuracy(preds, y): # 计算准确率
- rounded_preds = torch.round(torch.sigmoid(preds)) # 把概率的结果 四舍五入
- correct = (rounded_preds == y).float() # True False -> 转为 1, 0
- acc = correct.sum() / len(correct)
- return acc # 返回精确率
-
- #定义函数,训练模型
- def train(model, iterator, optimizer, criterion):
-
- epoch_loss = 0
- epoch_acc = 0
-
- model.train() # 设置模型标志,保证Dropout在训练模式下
-
- for batch in iterator: # 遍历数据集进行训练
- optimizer.zero_grad()
- predictions = model(batch.text).squeeze(1) # 在第1个维度上去除维度
- loss = criterion(predictions, batch.label) # 计算损失
- acc = binary_accuracy(predictions, batch.label) # 计算精确率
- loss.backward() # 损失函数反向
- optimizer.step() # 优化处理
- epoch_loss += loss.item() # 统计损失
- epoch_acc += acc.item() # 统计精确率
- return epoch_loss / len(iterator), epoch_acc / len(iterator)
-
- # 定义函数,评估模型
- def evaluate(model, iterator, criterion):
- epoch_loss = 0
- epoch_acc = 0
- model.eval() # 设置模型标志,保证Dropout在评估模型下
-
- with torch.no_grad(): # 禁止梯度计算
- for batch in iterator:
- predictions = model(batch.text).squeeze(1) # 计算结果
- loss = criterion(predictions, batch.label) # 计算损失
- acc = binary_accuracy(predictions, batch.label) # 计算精确率
- epoch_loss += loss.item()
- epoch_acc += acc.item()
- return epoch_loss / len(iterator), epoch_acc / len(iterator)
-
- # 定义函数,计算时间差
- def epoch_time(start_time, end_time):
- elapsed_time = end_time - start_time
- elapsed_mins = int(elapsed_time / 60)
- elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
- return elapsed_mins, elapsed_secs
-
- N_EPOCHS = 100 # 设置训练的迭代次数
- best_valid_loss = float('inf') # 设置损失初始值,用于保存最优模型
- for epoch in range(N_EPOCHS): # 按照迭代次数进行训练
- start_time = time.time()
- train_loss, train_acc = train(model, train_iterator, optimizer, criterion)
- valid_loss, valid_acc = evaluate(model, valid_iterator, criterion)
- end_time = time.time()
- # 计算迭代时间消耗
- epoch_mins, epoch_secs = epoch_time(start_time, end_time)
- if valid_loss < best_valid_loss: # 保存最优模型
- best_valid_loss = valid_loss
- torch.save(model.state_dict(), 'textcnn-model.pt')
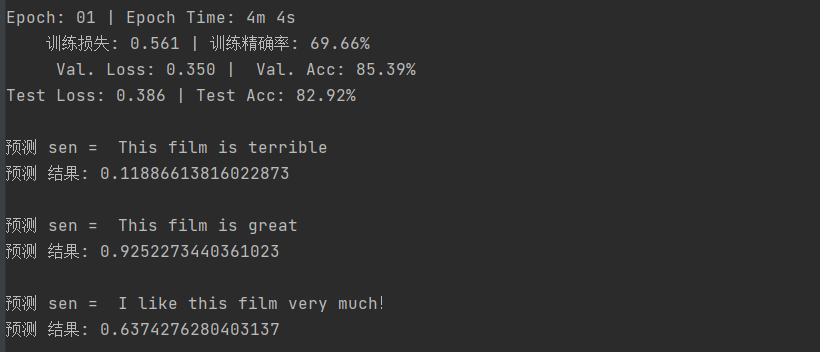
- # 输出训练结果
- print(f'Epoch: {epoch + 1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')
- print(f'\t训练损失: {train_loss:.3f} | 训练精确率: {train_acc * 100:.2f}%')
- print(f'\t Val. Loss: {valid_loss:.3f} | Val. Acc: {valid_acc * 100:.2f}%')
-
- # 测试模型效果
- model.load_state_dict(torch.load('textcnn-model.pt'))
- test_loss, test_acc = evaluate(model, test_iterator, criterion)
- print(f'Test Loss: {test_loss:.3f} | Test Acc: {test_acc * 100:.2f}%')
2.9 代码实现:使用模型进行训练---TextCNN.py(第8部分)
- # 1.8 使用模型进行训练:编写模型预测接口函数,对指定句子进行预测。列举几个句子输入模型预测接口函数进行预测,查看预测结果。
-
- nlp = spacy.load("en_core_web_sm")# 用spacy加载英文语言包
- # 定义函数,实现预测接口
- # (1)将长度不足5的句子用′<pad>'字符补齐。(2)将句子中的单词转为索引。
- # (3)为张量增加维度,以与训练场景下的输入形状保持一致。(4)输入模型进行预测,并对结果进行Sigmoid计算。因为模型在训练时,使用的计算损失函数自带Sigmoid处理,但模型中没有Sigmoid处理,所以要对结果增加Sigmoid处理。
- def predict_sentiment(model, sentence, min_len=5): # 设置最小长度为5
- model.eval() # 设置模型标志,保证Dropout在评估模型下
- tokenized = nlp.tokenizer(sentence).text.split() #拆分输入的句子
- if len(tokenized) < min_len: # 长度不足,在后面填充
- tokenized += ['<pad>'] * (min_len - len(tokenized))
- indexed = [TEXT.vocab.stoi[t] for t in tokenized] # 将单词转化为索引
- tensor = torch.LongTensor(indexed).to(device)
- tensor = tensor.unsqueeze(1) # 为张量增加维度,模拟批次
- prediction = torch.sigmoid(model(tensor)) # 输入模型进行预测
- return prediction.item() # 返回预测结果
-
- # 使用句子进行预测:大于0.5为正面评论,小于0.5为负面评论
- sen = "This film is terrible"
- print('\n预测 sen = ', sen)
- print('预测 结果:', predict_sentiment(model, sen))
-
- sen = "This film is great"
- print('\n预测 sen = ', sen)
- print('预测 结果:', predict_sentiment(model, sen))
-
- sen = "I like this film very much!"
- print('\n预测 sen = ', sen)
- print('预测 结果:', predict_sentiment(model, sen))
3 代码总览
3.1 TextCNN.py
- # 1.1 引入基础库: 固定PyTorch中的随机种子和GPU运算方式。
- import random #引入基础库
- import time
- import torch#引入PyTorch库
- import torch.nn as nn
- import torch.nn.functional as F
- from torchtext.legacy import data ,datasets,vocab #引入文本处理库
- import spacy
-
- torch.manual_seed(1234) # 固定随机种子,使其每次运行时对权重参数的初始化值一致。
- # 固定GPU运算方式:提高GPU的运算效率,通常PyTorch会调用自动寻找最适合当前配置的高效算法进行计算,这一过程会导致每次运算的结果可能出现不一致的情况。
- torch.backends.cudnn.deterministic = True # 表明不使用寻找高效算法的功能,使得每次的运算结果一致。[仅GPU有效]
-
- # 1.2 用torchtext加载IMDB并拆分为数据集
- # IMDB是torchtext库的内置数据集,可以直接通过torchtext库中的datasets.MDB进行处理。
- # 在处理之前将数据集的字段类型和分词方法指定正确即可。
-
- # 定义字段,并按照指定标记化函数进行分词
- TEXT = data.Field(tokenize = 'spacy',lower=True) # data.Field函数指定数据集中的文本字段用spaCy库进行分词处理,并将其统一改为小写字母。tokenize参数,不设置则默认使用str。
- LABEL = data.LabelField(dtype=torch.float)
-
- # 加载数据集,并根据IMDB两个文件夹,返回两个数据集。
- # datasets.MDB.splits()进行数据集的加载。该代码执行时会在本地目录的.data文件夹下查找是否有MDB数据集,如果没有,则下载;如果有,则将其加载到内存。
- # 被载入内存的数据集会放到数据集对象train_data与test_data中。
- train_data , test_data = datasets.IMDB.splits(text_field=TEXT,label_field=LABEL)
- print("-----------输出一条数据-----------")
- # print(vars(train_data.example[0]),len(train_data.example))
- print(vars(train_data.examples[0]),len(train_data.examples))
- print("---------------------------")
-
- # 将训练数据集再次拆分
- # 从训练数据中拆分出一部分作为验证数据集。数据集对象train_data的split方法默认按照70%、30%的比例进行拆分。
- train_data,valid_data = train_data.split(random_state = random.seed(1234))
- print("训练数据集: ", len(train_data),"条")
- print("验证数据集: ", len(valid_data),"条")
- print("测试数据集: ", len(test_data),"条")
-
- # 1.3 加载预训练词向量并进行样本数据化
- # 将数据集中的样本数据转化为词向量,并将其按照指定的批次大小进行组合。
- # buld_vocab方法实现文本到词向量数据的转化:从数据集对象train_data中取出前25000个高频词,并用指定的预训练词向量glove.6B.100d进行映射。
- TEXT.build_vocab(train_data,max_size=25000,vectors="glove.6B.100d",unk_init = torch.Tensor.normal_) # 将样本数据转化为词向量
- # glove.6B.100d为torchtext库中内置的英文词向量,主要将每个词映射成维度为100的浮点型数据,该文件会被下载到本地.vector_cache文件夹下。
- LABEL.build_vocab(train_data)
- # ---start---创建批次数据:将数据集按照指定批次进行组合。
- BATCH_SIZE = 64
- device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
- train_iterator, valid_iterator, test_iterator = data.BucketIterator.splits((train_data, valid_data, test_data), batch_size = BATCH_SIZE, device = device)
- # ---end---创建批次数据:将数据集按照指定批次进行组合。
-
- # 1.4 定义带有Mish激活函数的TextCNN模型
-
- class Mish(nn.Module):
- def __init__(self):
- super(Mish, self).__init__()
- def forward(self,x):
- x = x * (torch.tanh(F.softplus(x)))
- return x
-
- # 在TextCNN类中,一共有两个方法:
- # ①初始化方法.按照指定个数定义多分支卷积层,并将它们统一放在nn.ModuleList数组中。
- # ②前向传播方法:先将输入数据依次输入每个分支的卷积层中进行处理,再对处理结果进行最大池化,最后对池化结果进行连接并回归处理
- class TextCNN(nn.Module): #定义TextCNN模型
- # TextCNN类继承了nn.Module类,在该类中定义的网络层列表必须要使用nn.ModuleList进行转化,才可以被TextCNN类识别。
- # 如果直接使用列表的话,在训练模型时无法通过TextCNN类对象的parameters方法获得权重。
- # 定义初始化方法
- def __init__(self, vocab_size, embedding_dim, n_filters, filter_sizes, output_dim,dropout, pad_idx):
- super().__init__()
- self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx = pad_idx) # 定义词向量权重
- # 定义多分支卷积层
- # 将定义好的多分支卷积层以列表形式存放,以便在前向传播方法中使用。
- # 每个分支中卷积核的第一个维度由参数filter_sizes设置,第二个维度都是embedding_dim,即只在纵轴的方向上实现了真正的卷积操作,在横轴的方向上是全尺度卷积,可以起到一维卷积的效果。
- self.convs = nn.ModuleList([nn.Conv2d(in_channels = 1,out_channels = n_filters,kernel_size = (fs, embedding_dim))
- for fs in filter_sizes]) #########注意不能用list
- # 定义输出层
- self.fc = nn.Linear(len(filter_sizes) * n_filters, output_dim)
- self.dropout = nn.Dropout(dropout)
- self.mish = Mish() # 实例化激活函数对象
-
- # 定义前向传播方法
- def forward(self,text): # 输入形状为[sent len,batch size]
- text = text.permute(1, 0) # 将形状变为[batch size, sent len]
- embedded = self.embedding(text) # 对于输入数据进行词向量映射,形状为[batch size, sent len, emb dim]
- embedded = embedded.unsqueeze(1) # 进行维度变化,形状为[batch size, 1, sent len, emb dim]
- # len(filter_sizes)个元素,每个元素形状为[batch size, n_filters, sent len - filter_sizes[n] + 1]
- # 多分支卷积处理
- conved = [self.mish(conv(embedded)).squeeze(3) for conv in self.convs] # 将输入数据进行多分支卷积处理。该代码执行后,会得到一个含有len(fiter_sizes)个元素的列表,其中每个元素形状为[batchsize,n_filters,sentlen-fltersizes[n]+1],该元素最后一个维度的公式是由卷积公式计算而来的。
- # 对于每个卷积结果进行最大池化操作
- pooled = [F.max_pool1d(conv, conv.shape[2]).squeeze(2) for conv in conved]
- # 将池化结果进行连接
- cat = self.dropout(torch.cat(pooled, dim=1)) # 形状为[batch size, n_filters * len(filter_sizes)]
- return self.fc(cat) # 输入全连接,进行回归输出
-
- # 1.5 用数据集参数实例化模型
- if __name__ == '__main__':
- # 根据处理好的数据集参数对TextCNN模型进行实例化。
- INPUT_DIM = len(TEXT.vocab) # 25002
- EMBEDDING_DIM = TEXT.vocab.vectors.size()[1] # 100
- N_FILTERS = 100 # 定义每个分支的数据通道数量
- FILTER_SIZES = [3, 4, 5] # 定义多分支卷积中每个分支的卷积核尺寸
- OUTPUT_DIM = 1 # 定义输出维度
- DROPOUT = 0.5 # 定义Dropout丢弃率
- PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token] # 定义填充值:获取数据集中填充字符对应的索引。在词向量映射过程中对齐数据时会使用该索引进行填充。
- # 实例化模型
- model = TextCNN(INPUT_DIM, EMBEDDING_DIM, N_FILTERS, FILTER_SIZES, OUTPUT_DIM, DROPOUT, PAD_IDX)
-
- # 1.6 用预训练词向量初始化模型:将加载好的TEXT字段词向量复制到模型中,为其初始化。
- # 复制词向量
- model.embedding.weight.data.copy_(TEXT.vocab.vectors)
- # 将填充的词向量清0
- UNK_IDX = TEXT.vocab.stoi[TEXT.unk_token]
- model.embedding.weight.data[UNK_IDX] = torch.zeros(EMBEDDING_DIM) #对未识别词进行清零处理 :使该词在词向量空间中失去意义,目的是防止后面填充字符对原有的词向量空间进行干扰。
- model.embedding.weight.data[PAD_IDX] = torch.zeros(EMBEDDING_DIM) #对填充词进行清零处理 :使该词在词向量空间中失去意义,目的是防止后面填充字符对原有的词向量空间进行干扰。
-
- # 1.7 使用Ranger优化器训练模型
- import torch.optim as optim # 引入优化器库
- from functools import partial # 引入偏函数库
- from ranger import * # 载入Ranger优化器
-
- # 为Ranger优化器设置参数
- opt_func = partial(Ranger, betas=(.9, 0.99), eps=1e-6) # betas=(Momentum,alpha)
- optimizer = opt_func(model.parameters(), lr=0.004)
- # 定义损失函数
- criterion = nn.BCEWithLogitsLoss() # nn.BCEWithLogitsLoss函数是带有Sigmoid函数的二分类交叉熵,即先对模型的输出结果进行Sigmoid计算,再对其余标签一起做Cross_entropy计算。
- # 分配运算资源
- model = model.to(device)
- criterion = criterion.to(device)
-
- # 定义函数,计算精确率
- def binary_accuracy(preds, y): # 计算准确率
- rounded_preds = torch.round(torch.sigmoid(preds)) # 把概率的结果 四舍五入
- correct = (rounded_preds == y).float() # True False -> 转为 1, 0
- acc = correct.sum() / len(correct)
- return acc # 返回精确率
-
- #定义函数,训练模型
- def train(model, iterator, optimizer, criterion):
-
- epoch_loss = 0
- epoch_acc = 0
-
- model.train() # 设置模型标志,保证Dropout在训练模式下
-
- for batch in iterator: # 遍历数据集进行训练
- optimizer.zero_grad()
- predictions = model(batch.text).squeeze(1) # 在第1个维度上去除维度
- loss = criterion(predictions, batch.label) # 计算损失
- acc = binary_accuracy(predictions, batch.label) # 计算精确率
- loss.backward() # 损失函数反向
- optimizer.step() # 优化处理
- epoch_loss += loss.item() # 统计损失
- epoch_acc += acc.item() # 统计精确率
- return epoch_loss / len(iterator), epoch_acc / len(iterator)
-
- # 定义函数,评估模型
- def evaluate(model, iterator, criterion):
- epoch_loss = 0
- epoch_acc = 0
- model.eval() # 设置模型标志,保证Dropout在评估模型下
-
- with torch.no_grad(): # 禁止梯度计算
- for batch in iterator:
- predictions = model(batch.text).squeeze(1) # 计算结果
- loss = criterion(predictions, batch.label) # 计算损失
- acc = binary_accuracy(predictions, batch.label) # 计算精确率
- epoch_loss += loss.item()
- epoch_acc += acc.item()
- return epoch_loss / len(iterator), epoch_acc / len(iterator)
-
- # 定义函数,计算时间差
- def epoch_time(start_time, end_time):
- elapsed_time = end_time - start_time
- elapsed_mins = int(elapsed_time / 60)
- elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
- return elapsed_mins, elapsed_secs
-
- N_EPOCHS = 100 # 设置训练的迭代次数
- best_valid_loss = float('inf') # 设置损失初始值,用于保存最优模型
- for epoch in range(N_EPOCHS): # 按照迭代次数进行训练
- start_time = time.time()
- train_loss, train_acc = train(model, train_iterator, optimizer, criterion)
- valid_loss, valid_acc = evaluate(model, valid_iterator, criterion)
- end_time = time.time()
- # 计算迭代时间消耗
- epoch_mins, epoch_secs = epoch_time(start_time, end_time)
- if valid_loss < best_valid_loss: # 保存最优模型
- best_valid_loss = valid_loss
- torch.save(model.state_dict(), 'textcnn-model.pt')
- # 输出训练结果
- print(f'Epoch: {epoch + 1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')
- print(f'\t训练损失: {train_loss:.3f} | 训练精确率: {train_acc * 100:.2f}%')
- print(f'\t Val. Loss: {valid_loss:.3f} | Val. Acc: {valid_acc * 100:.2f}%')
-
- # 测试模型效果
- model.load_state_dict(torch.load('textcnn-model.pt'))
- test_loss, test_acc = evaluate(model, test_iterator, criterion)
- print(f'Test Loss: {test_loss:.3f} | Test Acc: {test_acc * 100:.2f}%')
-
- # 1.8 使用模型进行训练:编写模型预测接口函数,对指定句子进行预测。列举几个句子输入模型预测接口函数进行预测,查看预测结果。
-
- nlp = spacy.load("en_core_web_sm")# 用spacy加载英文语言包
- # 定义函数,实现预测接口
- # (1)将长度不足5的句子用′<pad>'字符补齐。(2)将句子中的单词转为索引。
- # (3)为张量增加维度,以与训练场景下的输入形状保持一致。(4)输入模型进行预测,并对结果进行Sigmoid计算。因为模型在训练时,使用的计算损失函数自带Sigmoid处理,但模型中没有Sigmoid处理,所以要对结果增加Sigmoid处理。
- def predict_sentiment(model, sentence, min_len=5): # 设置最小长度为5
- model.eval() # 设置模型标志,保证Dropout在评估模型下
- tokenized = nlp.tokenizer(sentence).text.split() #拆分输入的句子
- if len(tokenized) < min_len: # 长度不足,在后面填充
- tokenized += ['<pad>'] * (min_len - len(tokenized))
- indexed = [TEXT.vocab.stoi[t] for t in tokenized] # 将单词转化为索引
- tensor = torch.LongTensor(indexed).to(device)
- tensor = tensor.unsqueeze(1) # 为张量增加维度,模拟批次
- prediction = torch.sigmoid(model(tensor)) # 输入模型进行预测
- return prediction.item() # 返回预测结果
-
- # 使用句子进行预测:大于0.5为正面评论,小于0.5为负面评论
- sen = "This film is terrible"
- print('\n预测 sen = ', sen)
- print('预测 结果:', predict_sentiment(model, sen))
-
- sen = "This film is great"
- print('\n预测 sen = ', sen)
- print('预测 结果:', predict_sentiment(model, sen))
-
- sen = "I like this film very much!"
- print('\n预测 sen = ', sen)
- print('预测 结果:', predict_sentiment(model, sen))
3.2 ranger.py
- #Ranger deep learning optimizer - RAdam + Lookahead combined.
- #https://github.com/lessw2020/Ranger-Deep-Learning-Optimizer
-
- #Ranger has now been used to capture 12 records on the FastAI leaderboard.
-
- #This version = 9.3.19
-
- #Credits:
- #RAdam --> https://github.com/LiyuanLucasLiu/RAdam
- #Lookahead --> rewritten by lessw2020, but big thanks to Github @LonePatient and @RWightman for ideas from their code.
- #Lookahead paper --> MZhang,G Hinton https://arxiv.org/abs/1907.08610
-
- #summary of changes:
- #full code integration with all updates at param level instead of group, moves slow weights into state dict (from generic weights),
- #supports group learning rates (thanks @SHolderbach), fixes sporadic load from saved model issues.
- #changes 8/31/19 - fix references to *self*.N_sma_threshold;
- #changed eps to 1e-5 as better default than 1e-8.
-
- import math
- import torch
- from torch.optim.optimizer import Optimizer, required
- import itertools as it
-
-
-
- class Ranger(Optimizer):
-
- def __init__(self, params, lr=1e-3, alpha=0.5, k=6, N_sma_threshhold=5, betas=(.95,0.999), eps=1e-5, weight_decay=0):
- #parameter checks
- if not 0.0 <= alpha <= 1.0:
- raise ValueError(f'Invalid slow update rate: {alpha}')
- if not 1 <= k:
- raise ValueError(f'Invalid lookahead steps: {k}')
- if not lr > 0:
- raise ValueError(f'Invalid Learning Rate: {lr}')
- if not eps > 0:
- raise ValueError(f'Invalid eps: {eps}')
-
- #parameter comments:
- # beta1 (momentum) of .95 seems to work better than .90...
- #N_sma_threshold of 5 seems better in testing than 4.
- #In both cases, worth testing on your dataset (.90 vs .95, 4 vs 5) to make sure which works best for you.
-
- #prep defaults and init torch.optim base
- defaults = dict(lr=lr, alpha=alpha, k=k, step_counter=0, betas=betas, N_sma_threshhold=N_sma_threshhold, eps=eps, weight_decay=weight_decay)
- super().__init__(params,defaults)
-
- #adjustable threshold
- self.N_sma_threshhold = N_sma_threshhold
-
- #now we can get to work...
- #removed as we now use step from RAdam...no need for duplicate step counting
- #for group in self.param_groups:
- # group["step_counter"] = 0
- #print("group step counter init")
-
- #look ahead params
- self.alpha = alpha
- self.k = k
-
- #radam buffer for state
- self.radam_buffer = [[None,None,None] for ind in range(10)]
-
- #self.first_run_check=0
-
- #lookahead weights
- #9/2/19 - lookahead param tensors have been moved to state storage.
- #This should resolve issues with load/save where weights were left in GPU memory from first load, slowing down future runs.
-
- #self.slow_weights = [[p.clone().detach() for p in group['params']]
- # for group in self.param_groups]
-
- #don't use grad for lookahead weights
- #for w in it.chain(*self.slow_weights):
- # w.requires_grad = False
-
- def __setstate__(self, state):
- print("set state called")
- super(Ranger, self).__setstate__(state)
-
-
- def step(self, closure=None):
- loss = None
- #note - below is commented out b/c I have other work that passes back the loss as a float, and thus not a callable closure.
- #Uncomment if you need to use the actual closure...
-
- #if closure is not None:
- #loss = closure()
-
- #Evaluate averages and grad, update param tensors
- for group in self.param_groups:
-
- for p in group['params']:
- if p.grad is None:
- continue
- grad = p.grad.data.float()
- if grad.is_sparse:
- raise RuntimeError('Ranger optimizer does not support sparse gradients')
-
- p_data_fp32 = p.data.float()
-
- state = self.state[p] #get state dict for this param
-
- if len(state) == 0: #if first time to run...init dictionary with our desired entries
- #if self.first_run_check==0:
- #self.first_run_check=1
- #print("Initializing slow buffer...should not see this at load from saved model!")
- state['step'] = 0
- state['exp_avg'] = torch.zeros_like(p_data_fp32)
- state['exp_avg_sq'] = torch.zeros_like(p_data_fp32)
-
- #look ahead weight storage now in state dict
- state['slow_buffer'] = torch.empty_like(p.data)
- state['slow_buffer'].copy_(p.data)
-
- else:
- state['exp_avg'] = state['exp_avg'].type_as(p_data_fp32)
- state['exp_avg_sq'] = state['exp_avg_sq'].type_as(p_data_fp32)
-
- #begin computations
- exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']
- beta1, beta2 = group['betas']
-
- #compute variance mov avg
- exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad)
- #compute mean moving avg
- exp_avg.mul_(beta1).add_(1 - beta1, grad)
-
- state['step'] += 1
-
-
- buffered = self.radam_buffer[int(state['step'] % 10)]
- if state['step'] == buffered[0]:
- N_sma, step_size = buffered[1], buffered[2]
- else:
- buffered[0] = state['step']
- beta2_t = beta2 ** state['step']
- N_sma_max = 2 / (1 - beta2) - 1
- N_sma = N_sma_max - 2 * state['step'] * beta2_t / (1 - beta2_t)
- buffered[1] = N_sma
- if N_sma > self.N_sma_threshhold:
- step_size = math.sqrt((1 - beta2_t) * (N_sma - 4) / (N_sma_max - 4) * (N_sma - 2) / N_sma * N_sma_max / (N_sma_max - 2)) / (1 - beta1 ** state['step'])
- else:
- step_size = 1.0 / (1 - beta1 ** state['step'])
- buffered[2] = step_size
-
- if group['weight_decay'] != 0:
- p_data_fp32.add_(-group['weight_decay'] * group['lr'], p_data_fp32)
-
- if N_sma > self.N_sma_threshhold:
- denom = exp_avg_sq.sqrt().add_(group['eps'])
- p_data_fp32.addcdiv_(-step_size * group['lr'], exp_avg, denom)
- else:
- p_data_fp32.add_(-step_size * group['lr'], exp_avg)
-
- p.data.copy_(p_data_fp32)
-
- #integrated look ahead...
- #we do it at the param level instead of group level
- if state['step'] % group['k'] == 0:
- slow_p = state['slow_buffer'] #get access to slow param tensor
- slow_p.add_(self.alpha, p.data - slow_p) #(fast weights - slow weights) * alpha
- p.data.copy_(slow_p) #copy interpolated weights to RAdam param tensor
-
- return loss
-

