
- 1【常见的六大排序算法】插入排序、希尔排序、选择排序、冒泡排序、堆排序、快速排序
- 2[机缘参悟-153] :一个软件架构师对佛学的理解 -18- 佛家思想摆脱不了世俗的分等级、分门派
- 3vue项目中使用jsx/render写el-form校验报错_el-form jsx
- 42021秋招数字IC设计岗面试总结 字节\中兴\英伟达\兆易_数字ic设计需要学以太网吗
- 5Gradle sync failed: Cause: error in opening zip file 几个可能的原因_gradle sync failed: error in opening zip file
- 6【高创新!高热点!】基于蚂蚁算法、A*算法、RRT算法的三维无人机路径规划比较与研究(Matlab代码实现)_蚁群算法和rrt算法的区别
- 7MatterSim:人工智能解锁材料设计的无限可能
- 8【微信小程序】一文解忧,事件绑定_微信小程序怎么绑定事件
- 9基于PCIE X16总线架构的4路QSFP28 100G光纤通道适配器(可实现100%国产化)
- 10信号的频谱分析,加噪降噪处理_有噪声情况下信号幅度谱的研究数字信号处理课程设计
Sqoop数据的导入导出与job作业_sqoop job
赞
踩
1. Sqoop导入数据
站在hadoop的立场看:
import:数据导入。RDBMS----->Hadoop
export:数据导出。Hadoop---->RDBMS
创建表
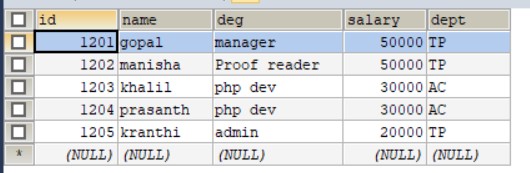
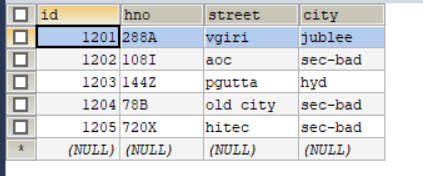
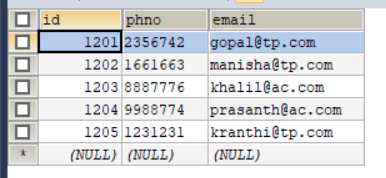
SET FOREIGN_KEY_CHECKS=0; -- ---------------------------- -- Table structure for `emp` -- ---------------------------- DROP TABLE IF EXISTS `emp`; CREATE TABLE `emp` ( `id` INT(11) DEFAULT NULL, `name` VARCHAR(100) DEFAULT NULL, `deg` VARCHAR(100) DEFAULT NULL, `salary` INT(11) DEFAULT NULL, `dept` VARCHAR(10) DEFAULT NULL ) ENGINE=INNODB DEFAULT CHARSET=latin1; -- ---------------------------- -- Records of emp -- ---------------------------- INSERT INTO `emp` VALUES ('1201', 'gopal', 'manager', '50000', 'TP'); INSERT INTO `emp` VALUES ('1202', 'manisha', 'Proof reader', '50000', 'TP'); INSERT INTO `emp` VALUES ('1203', 'khalil', 'php dev', '30000', 'AC'); INSERT INTO `emp` VALUES ('1204', 'prasanth', 'php dev', '30000', 'AC'); INSERT INTO `emp` VALUES ('1205', 'kranthi', 'admin', '20000', 'TP'); -- ---------------------------- -- Table structure for `emp_add` -- ---------------------------- DROP TABLE IF EXISTS `emp_add`; CREATE TABLE `emp_add` ( `id` INT(11) DEFAULT NULL, `hno` VARCHAR(100) DEFAULT NULL, `street` VARCHAR(100) DEFAULT NULL, `city` VARCHAR(100) DEFAULT NULL ) ENGINE=INNODB DEFAULT CHARSET=latin1; -- ---------------------------- -- Records of emp_add -- ---------------------------- INSERT INTO `emp_add` VALUES ('1201', '288A', 'vgiri', 'jublee'); INSERT INTO `emp_add` VALUES ('1202', '108I', 'aoc', 'sec-bad'); INSERT INTO `emp_add` VALUES ('1203', '144Z', 'pgutta', 'hyd'); INSERT INTO `emp_add` VALUES ('1204', '78B', 'old city', 'sec-bad'); INSERT INTO `emp_add` VALUES ('1205', '720X', 'hitec', 'sec-bad'); -- ---------------------------- -- Table structure for `emp_conn` -- ---------------------------- DROP TABLE IF EXISTS `emp_conn`; CREATE TABLE `emp_conn` ( `id` INT(100) DEFAULT NULL, `phno` VARCHAR(100) DEFAULT NULL, `email` VARCHAR(100) DEFAULT NULL ) ENGINE=INNODB DEFAULT CHARSET=latin1; -- ---------------------------- -- Records of emp_conn -- ---------------------------- INSERT INTO `emp_conn` VALUES ('1201', '2356742', 'gopal@tp.com'); INSERT INTO `emp_conn` VALUES ('1202', '1661663', 'manisha@tp.com'); INSERT INTO `emp_conn` VALUES ('1203', '8887776', 'khalil@ac.com'); INSERT INTO `emp_conn` VALUES ('1204', '9988774', 'prasanth@ac.com'); INSERT INTO `emp_conn` VALUES ('1205', '1231231', 'kranthi@tp.com');

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
表创建完成,如下图所示
emp:
emp_add:
emp_conn:
1.1 全量导入mysql表数据到HDFS
启动集群
[xiaokang@node01 ~]$ zkServer.sh start
[xiaokang@node02 ~]$ zkServer.sh start
[xiaokang@node03 ~]$ zkServer.sh start
[xiaokang@node01 ~]$ start-dfs.sh
[xiaokang@node03 ~]$ start-yarn.sh
[xiaokang@node01 ~]$ mr-jobhistory-daemon.sh start historyserver
[xiaokang@node02 ~]$ yarn-daemon.sh start resourcemanager
- 1
- 2
- 3
- 4
- 5
- 6
- 7
① 要求:将userdb数据库中emp表的全部数据导入hdfs
[xiaokang@node01 ~]$ sqoop import \
> --connect jdbc:mysql://node01:3306/userdb \
> --username root \
> --password xiaokang \
> --delete-target-dir \
> --target-dir /sqoopresult212 \
> --table emp --m 1
# 注释:
# --delete-target-dir 如果/sqoopresult212 路径已存在,则先删除
# --target-dir /sqoopresult212 在hdfs上创建/sqoopresult 路径
# --m 1 指定maptask的并行度
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
来到 yarn 端口,可以看到一个emp.jar的任务

来到hdfs,可以看到导入的文件。在进行导入导出的时候,是一个特殊的mr程序,只有map阶段,没有reduce阶段。因为导入导出不需要数据的聚合。mysql的默认分隔符是’,’

② 要求:将userdb数据库中emp表的全部数据导入hdfs ,指定分隔符 ‘\t’
[xiaokang@node01 ~]$ sqoop import \
> --connect jdbc:mysql://node01:3306/userdb \
> --username root \
> --password xiaokang \
> --target-dir /sqoopresult213 \
> --fields-terminated-by '\t' \
> --table emp --m 1
# 注释
# --fields-terminated-by '\t' 指定导入内容的分隔符为'\t'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

③ 要求:将userdb数据库中emp表的全部数据导入hdfs ,指定并行度为2
错误命令:
[xiaokang@node01 ~]$ sqoop import
> --connect jdbc:mysql://node01:3306/userdb
> --username root
> --password xiaokang
> --target-dir /sqoopresult214
> --fields-terminated-by '\t'
> --table emp --m 2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
报错如下:emp表没有主键,用 split-by 指明根据哪个字段来分

正确写法:
[xiaokang@node01 ~]$ sqoop import
> --connect jdbc:mysql://node01:3306/userdb
> --username root
> --password xiaokang
> --target-dir /sqoopresult214
> --fields-terminated-by '\t'
> --split-by id
> --table emp --m 2
# 注释
# --split-by id --table emp --m 2 指定根据id字段进行划分并启动2个maptask
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
看到输出的日志,读数据组件已经变成了DBInputFormat。一个边界范围的查询:查询emp表id字段的最大值,最小值。hdfs上有两个文件。


1.2 全量导入mysql表数据到HIVE
1.2.1 先复制表结构,再导入文件
① 将MySQL的表结构复制到hive中
0: jdbc:hive2://node01:11240> create database test; 0: jdbc:hive2://node01:11240> use test; # 执行以下操作可能会出现 缺少环境变量配置问题,jdk配置问题,jar包不兼容问题,自行解决即可 [xiaokang@node01 ~]$ sqoop create-hive-table \ > --connect jdbc:mysql://node01:3306/userdb \ > --table emp_add \ > --username root \ > --password xiaokang \ > --hive-table test.emp_add_sp 0: jdbc:hive2://node01:11240> show tables; +-------------+ | tab_name | +-------------+ | emp_add_sp | +-------------+ 1 row selected (0.196 seconds) 0: jdbc:hive2://node01:11240> select * from emp_add_sp; # 表中并没有数据,说明只复制了表结构 +------------------+-----------------+----------------+--------------------+ | emp_add_sp.city | emp_add_sp.hno | emp_add_sp.id | emp_add_sp.street | +------------------+-----------------+----------------+--------------------+ +------------------+-----------------+----------------+--------------------+ 0: jdbc:hive2://node01:11240> desc formatted emp_add_sp; # 查看表结构
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27

② 从MySQL中导入文件到hive中
来到hdfs,我们看到路径下现在并没有相关文件

[xiaokang@node01 ~]$ sqoop import \
> --connect jdbc:mysql://node01:3306/userdb \
> --username root \
> --password xiaokang \
> --table emp_add \
> --hive-table test.emp_add_sp \
> --hive-import \
> --m 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
看到输出的日志,接收了5条记录:

查看一下表中是否已经有数据:
0: jdbc:hive2://node01:11240> select * from emp_add_sp;
+------------------+-----------------+----------------+--------------------+
| emp_add_sp.city | emp_add_sp.hno | emp_add_sp.id | emp_add_sp.street |
+------------------+-----------------+----------------+--------------------+
| jublee | 288A | 1201 | vgiri |
| sec-bad | 108I | 1202 | aoc |
| hyd | 144Z | 1203 | pgutta |
| sec-bad | 78B | 1204 | old city |
| sec-bad | 720X | 1205 | hitec |
+------------------+-----------------+----------------+--------------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
来到hdfs相应的表目录下:
可以看到,在hive中默认分隔符是不可见分隔符,叫做’\001’。

1.2.2 直接复制表结构数据到hive中
[xiaokang@node01 ~]$ sqoop import \ > --connect jdbc:mysql://node01:3306/userdb \ > --username root \ > --password xiaokang \ > --table emp_conn \ > --hive-import \ > --m 1 \ > --hive-database test 0: jdbc:hive2://node01:11240> show tables; +-------------+ | tab_name | +-------------+ | emp_add_sp | | emp_conn | +-------------+ 2 rows selected (0.161 seconds) 0: jdbc:hive2://node01:11240> select * from emp_conn; +------------------+--------------+----------------+ | emp_conn.email | emp_conn.id | emp_conn.phno | +------------------+--------------+----------------+ | gopal@tp.com | 1201 | 2356742 | | manisha@tp.com | 1202 | 1661663 | | khalil@ac.com | 1203 | 8887776 | | prasanth@ac.com | 1204 | 9988774 | | kranthi@tp.com | 1205 | 1231231 | +------------------+--------------+----------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
1.3 导入表数据子集(where过滤)
将MySQL中的emp_add表的字段 city=‘sec-bad’ 的记录导入hive
[xiaokang@node01 ~]$ sqoop import \
> --connect jdbc:mysql://node01:3306/userdb \
> --username root \
> --password xiaokang \
> --where "city='sec-bad'" \
> --target-dir /wherequery \
> --table emp_add --m 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
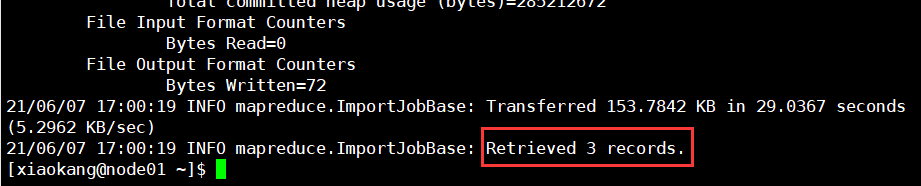
查看输出的日志,接收了三条记录

1.4 导入表数据子集(query查询)
使用 query sql 语句来进行查找不能加参数 --table
并且必须要添加 where 条件
并且 where 条件后面必须带一个 $CONDITIONS 这个字符串
并且这个 sql 语句必须用单引号,不能用双引号
[xiaokang@node01 ~]$ sqoop import \
> --connect jdbc:mysql://node01:3306/userdb \
> --username root \
> --password xiaokang \
> --target-dir /wherequery12 \
> --query 'select id,name,deg from emp where id>1203 and $CONDITIONS' \
> --split-by id \
> --fields-terminated-by '\001' \
> --m 2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

1.5 增量导入
增量导入:仅导入新添加的表中的行
1.5.1 append模式增量导入
先将emp表的数据全量导入hdfs:
[xiaokang@node01 ~]$ sqoop import \
> --connect jdbc:mysql://node01:3306/userdb \
> --username root \
> --password xiaokang \
> --target-dir /appendresult \
> --table emp --m 1
- 1
- 2
- 3
- 4
- 5
- 6

然后向MySQL的emp表中插入2条数据:
insert into `userdb`.`emp` (`id`, `name`, `deg`, `salary`, `dept`) values ('1206', 'allen', 'admin', '30000', 'tp');
insert into `userdb`.`emp` (`id`, `name`, `deg`, `salary`, `dept`) values ('1207', 'woon', 'admin', '40000', 'tp');
- 1
- 2

将新增的两条记录导入hdfs:
[xiaokang@node01 ~]$ sqoop import \
> --connect jdbc:mysql://node01:3306/userdb \
> --username root \
> --password xiaokang \
> --table emp --m 1 \
> --target-dir /appendresult \
> --incremental append \
> --check-column id \
> --last-value 1205
# --incremental append 追加模式
# --check-column id 检测字段id
# --last-value 1205 上次导入的最后一条记录的id是1205
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
看到打印的日志信息,上次导入的最后一条记录的id已经变成了1207:


1.5.2 lastmodified模式增量导入
append
首先创建一个customertest表,指定一个时间戳字段,并插入值:
create table customertest(id int,name varchar(20),last_mod timestamp default current_timestamp on update current_timestamp);
# 一条一条的执行
insert into customertest(id,name) values(1,'neil');
insert into customertest(id,name) values(2,'jack');
insert into customertest(id,name) values(3,'martin');
insert into customertest(id,name) values(4,'tony');
insert into customertest(id,name) values(5,'eric');
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

将数据全量导入hdfs:
[xiaokang@node01 ~]$ sqoop import \
> --connect jdbc:mysql://node01:3306/userdb \
> --username root \
> --password xiaokang \
> --target-dir /lastmodifiedresult \
> --table customertest --m 1
- 1
- 2
- 3
- 4
- 5
- 6

再向customertest表中插入一条记录:
insert into customertest(id,name) values(6,'james')
- 1
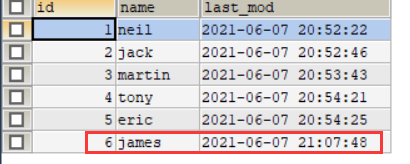
进行增量导入:
[xiaokang@node01 ~]$ sqoop import \ > --connect jdbc:mysql://node01:3306/userdb \ > --username root \ > --password xiaokang \ > --table customertest \ > --target-dir /lastmodifiedresult \ > --check-column last_mod \ > --incremental lastmodified \ > --last-value "2021-06-07 20:54:25" \ > --m 1 \ > --append # --check-column last_mod 检查last_mod字段 # --incremental lastmodified 追加模式 # --上次导入的最后一条记录的last_mod字段为"2021-06-07 20:54:25" # --append 追加模式
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
日志显示,导入了两条记录

可以看到,第5条记录又导入了进来。说明在lastmodified这种情况下,进行数据增量导入,不是大于"2021-06-07 20:54:25",而是将大于等于"2021-06-07 20:54:25"的记录都给导入进来。

小结:
sqoop支持两种模式的增量导入
– append追加 根据数值类型字段进行追加导入大于指定的last-value的记录
– lastmodified 根据时间戳类型的字段进行追加大于等于指定的last-value的记录。在lastmodified模式下分为两种形式:append(追加),merge-key(根据key合并)
merge-key
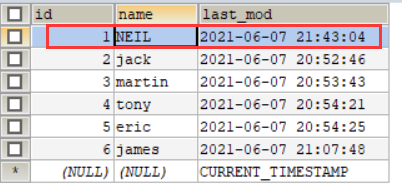
修改customertest 表数据:
update customertest set name = 'NEIL' where id = 1;
- 1
修改之后如图所示:
[xiaokang@node01 ~]$ sqoop import \
> --connect jdbc:mysql://node01:3306/userdb \
> --username root \
> --password xiaokang \
> --table customertest \
> --target-dir /lastmodifiedresult \
> --check-column last_mod \
> --incremental lastmodified \
> --last-value "2021-06-07 20:54:25" \
> --m 1 \
> --merge-key id
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
如果有变化数据,会把变化的数据同步过来。如果有新增数据,会把新增数据同步过来。merge-key模式进行了一次完整的MapReduce操作,避免了数据重复的情况。

2. Sqoop导出数据
Hadoop --> RDBMS , 数据导出前,目标表必须存在。
export有三种模式:
1. 默认操作是将数据使用insert语句插入到表中。
2. 更新模式:Sqoop生成update替换数据库中现有的语句
3. 调用模式:Sqoop为每一条记录创建一个存储过程调用。
2.1 默认模式
此模式主要用于将记录导出到空表中。
要求:将HDFS数据导出到mysql
① 准备hdfs数据
在hdfs的/emp_data路径下创建一个文件emp_data.txt
[xiaokang@node01 ~]$ vim emp_data.txt
# 插入以下内容:
1201,gopal,manager,50000,TP
1202,manisha,preader,50000,TP
1203,kalil,php dev,30000,AC
1204,prasanth,php dev,30000,AC
1205,kranthi,admin,20000,TP
1206,satishp,grpdes,20000,GR
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
在hdfs上创建路径,并上传数据文件
[xiaokang@node01 ~]$ hadoop fs -mkdir /emp_data/
[xiaokang@node01 ~]$ hadoop fs -put emp_data.txt /emp_data/
- 1
- 2
② 在MySQL中创建目标表
USE userdb;
CREATE TABLE employee (
id INT NOT NULL PRIMARY KEY,
NAME VARCHAR(20),
deg VARCHAR(20),
salary INT,
dept VARCHAR(10))
DEFAULT CHARSET=utf8;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

③ 执行导出命令
[xiaokang@node01 ~]$ sqoop export --connect jdbc:mysql://node01:3306/userdb --username root --password xiaokang --table employee --export-dir /emp_data/
# --export-dir 指定导出路径,导出路径是hdfs上的/emp_data/
- 1
- 2
看到日志信息,导出了6条记录,如下图:

看一下employee表中的数据:
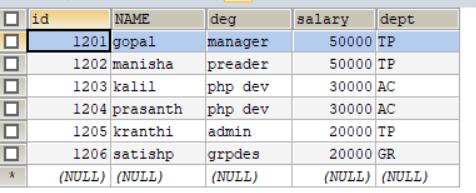
说明:导出的目标表需要自己提前手动创建,Sqoop不会帮我们创建
2.2 常用语法
① --columns
# 创建表employee1
CREATE TABLE employee1 (
id INT NOT NULL PRIMARY KEY,
salary INT,
deg VARCHAR(20),
NAME VARCHAR(20),
dept VARCHAR(10));
- 1
- 2
- 3
- 4
- 5
- 6
- 7

employee表的属性与hdfs上emp_data.txt文件的字段不对应,此时导出数据需要指定emp_data.txt的字段名。
# 导出数据
[xiaokang@node01 ~]$ sqoop export \
> --connect jdbc:mysql://node01:3306/userdb \
> --username root \
> --password xiaokang \
> --table employee1 \
> --columns id,name,deg,salary,dept \
> --export-dir /emp_data/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
结果如下:
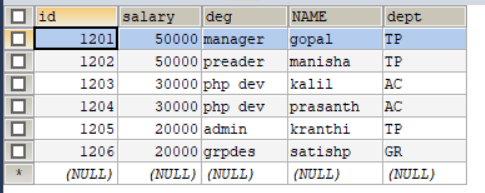
② --input-fields-terminated-by ‘\t’ 指定文件中的字段分隔符,默认",“分隔。
③ --export-dir 指定hdfs上的导出目录或导出文件名
④ --input-null-string “\N” 空的字符串以”\N"来替代,–input-null-non-string “\N” 空的非字符串以"\N"来替代。
2.3 更新导出(updateonly模式)
① --update-key 指定更新的标识字段,标识字段可以是一个或多个
② --update-mode 指定更新模式
# 在hdfs上创建一个新路径并上传文件
[xiaokang@node01 ~]$ hdfs dfs -mkdir /updateonly_1/
[xiaokang@node01 ~]$ cat updateonly_1.txt
1201,gopal,manager,50000
1202,manisha,preader,50000
1203,kalil,php dev,30000
[xiaokang@node01 ~]$ hdfs dfs -put updateonly_1.txt /updateonly_1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
# 创建表
USE userdb;
CREATE TABLE updateonly (
id INT NOT NULL PRIMARY KEY,
NAME VARCHAR(20),
deg VARCHAR(20),
salary INT);
- 1
- 2
- 3
- 4
- 5
- 6
- 7

# 将updateonly_1.txt 全量导出到updateonly表
[xiaokang@node01 ~]$ sqoop export \
> --connect jdbc:mysql://node01:3306/userdb \
> --username root \
> --password xiaokang \
> --table updateonly \
> --export-dir /updateonly_1/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
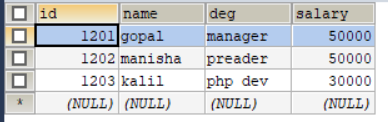
# 再准备一个文件并上传到hdfs
# 说明:updateonly_2.txt文件既对updateonly_1.txt文件的记录做了修改,又新增了记录
[xiaokang@node01 ~]$ cat updateonly_2.txt
1201,gopal,manager,1212
1202,manisha,preader,1313
1203,kalil,php dev,1414
1204,allen,java,1515
[xiaokang@node01 ~]$ hdfs dfs -mkdir /updateonly_2
[xiaokang@node01 ~]$ hdfs dfs -put updateonly_2.txt /updateonly_2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
执行更新导出
[xiaokang@node01 ~]$ sqoop export \
> --connect jdbc:mysql://node01:3306/userdb \
> --username root \
> --password xiaokang \
> --table updateonly \
> --export-dir /updateonly_2 \
> --update-key id \
> --update-mode updateonly
# --update-mode updateonly 指定更新模式为只更新, updateonly只更新已存在的记录,不会执行增加新的数据。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
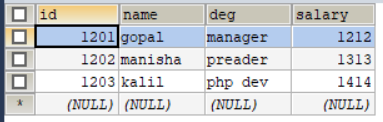
2.4 更新导出(allowinsert模式)
# 创建allowinsert.txt文件并上传至hdfs的/allowinsert_1/路径下
[xiaokang@node01 ~]$ cat allowinsert_1.txt
1201,gopal,manager,50000
1202,manisha,preader,50000
1203,kalil,php dev,30000
[xiaokang@node01 ~]$ hdfs dfs -mkdir /allowinsert_1
[xiaokang@node01 ~]$ hdfs dfs -put allowinsert_1.txt /allowinsert_1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
# 创建表
USE userdb;
CREATE TABLE allowinsert (
id INT NOT NULL PRIMARY KEY,
NAME VARCHAR(20),
deg VARCHAR(20),
salary INT);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
# 全量导出
[xiaokang@node01 ~]$ sqoop export \
> --connect jdbc:mysql://node01:3306/userdb \
> --username root \
> --password xiaokang \
> --table allowinsert \
> --export-dir /allowinsert_1/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
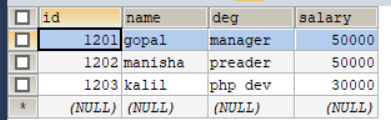
# 创建allowinsert_2.txt文件并上传至hdfs的/allowinsert_2/路径下
[xiaokang@node01 ~]$ cat allowinsert_2.txt
1201,gopal,manager,1212
1202,manisha,preader,1313
1203,kalil,php dev,1414
1204,allen,java,1515
[xiaokang@node01 ~]$ hdfs dfs -mkdir /allowinsert_2
[xiaokang@node01 ~]$ hdfs dfs -put allowinsert_2.txt /allowinsert_2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
# 更新导出
[xiaokang@node01 ~]$ sqoop export \
> --connect jdbc:mysql://node01:3306/userdb \
> --username root \
> --password xiaokang \
> --table allowinsert \
> --export-dir /allowinsert_2/ \
> --update-key id \
> --update-mode allowinsert
# --update-mode allowinsert 指定更新模式为既更新又插入
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
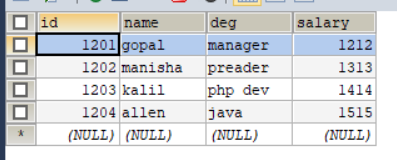
allowinsert 更新已有的数据,插入新的数据,相当于update+insert
3. Sqoop job 作业
① 创建作业(–create)
[xiaokang@node01 ~]$ sqoop job --create youyoujob01 -- import --connect jdbc:mysql://node01:3306/userdb --username root --password xiaokang --target-dir /sqoopresult333 --table emp --m 1
- 1
遇到了一些小问题,参考这篇博客就可以解决
21/06/20 11:22:10 ERROR sqoop.Sqoop: Got exception running Sqoop: java.lang.NullPointerException
java.lang.NullPointerException
at org.json.JSONObject.<init>(JSONObject.java:144)
at org.apache.sqoop.util.SqoopJsonUtil.getJsonStringforMap(SqoopJsonUtil.java:43)
at org.apache.sqoop.SqoopOptions.writeProperties(SqoopOptions.java:785)
at org.apache.sqoop.metastore.hsqldb.HsqldbJobStorage.createInternal(HsqldbJobStorage.java:399)
at org.apache.sqoop.metastore.hsqldb.HsqldbJobStorage.create(HsqldbJobStorage.java:379)
at org.apache.sqoop.tool.JobTool.createJob(JobTool.java:181)
at org.apache.sqoop.tool.JobTool.run(JobTool.java:294)
at org.apache.sqoop.Sqoop.run(Sqoop.java:147)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:183)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:234)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243)
at org.apache.sqoop.Sqoop.main(Sqoop.java:252)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
[xiaokang@node01 ~]$ sqoop job \
> --create youyoujob02 \
> -- import \
> --connect jdbc:mysql://node01:3306/userdb \
> --username root \
> --password xiaokang \
> --target-dir /sqoopresult333 \
> --table emp --m 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
② 验证作业(–list)
# 显示系统当下所保存的job
[xiaokang@node01 ~]$ sqoop job --list
Available jobs:
youyoujob01
youyoujob02
- 1
- 2
- 3
- 4
- 5
③ 检查作业(–show)
[xiaokang@node01 ~]$ sqoop job --show youyoujob02
Enter password: #输入MySQL密码
- 1
- 2

④ 执行作业(–exec)
[xiaokang@node01 ~]$ sqoop job --exec youyoujob02
Enter password: # MySQL密码
- 1
- 2


⑤ 删除作业
[xiaokang@node01 ~]$ sqoop job --delete youyoujob01
[xiaokang@node01 ~]$ sqoop job --list
Available jobs:
youyoujob02
- 1
- 2
- 3
- 4
⑥ 免密执行job
sqoop在创建job时,使用 --password-file 参数,可以避免输入mysql密码。sqoop规定密码文件必须存放在hdfs上,权限必须为400。
# 将MySQL的密码添加到youyoumysql.pwd文件中
[xiaokang@node01 ~]$ echo -n "xiaokang" > youyoumysql.pwd
# 在hdfs上创建youyoumysql.pwd文件的存放路径
[xiaokang@node01 ~]$ hdfs dfs -mkdir -p /input/sqoop/pwd/
# 上传youyoumysql.pwd至hdfs
[xiaokang@node01 ~]$ hdfs dfs -put youyoumysql.pwd /input/sqoop/pwd/
# 修改youyoumysql.pwd的权限为400
[xiaokang@node01 ~]$ hdfs dfs -chmod 400 /input/sqoop/pwd/youyoumysql.pwd
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
# 进入sqoop-site.xml,添加以下配置内容:
[xiaokang@node01 ~]$ vim /opt/software/sqoop-1.4.7/conf/sqoop-site.xml
- 1
- 2
<property>
<name>sqoop.metastore.client.record.password</name>
<value>true</value>
<description>If true, allow saved passwords in the metastore.</description>
</property>
- 1
- 2
- 3
- 4
- 5
# 创建sqoop job
[xiaokang@node01 ~]$ sqoop job --create youyoujob03 -- import \
> --connect jdbc:mysql://node01:3306/userdb \
> --username root \
> --password-file /input/sqoop/pwd/youyoumysql.pwd \
> --target-dir /sqoopresult999 \
> --table emp --m 1
# 执行任务
# 这次就不用输入密码了
[xiaokang@node01 ~]$ sqoop job --exec youyoujob03
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11


