
- 1大三网络安全人工智能实验报告_实现mnist数据集的手写数字识别实验报告
- 2mysql 模糊查询like优化方案(亲测)_mysql模糊查询like优化
- 3C++核心编程类的总结封装案例
- 4初识java代码审计(java web网站)_java代码审计,源码从哪来
- 5一份12W+字数的踩坑总结,覆盖前端、后端、运维三个维度,一步一个脚印,我们一起成长!(实时更新)_nuxt v-for 错误
- 6python常用的集成开发环境有哪些_5个实用的Python IDE,你应该选哪个?(上)
- 7mysql convert函数 解决读取double为科学计数法问题_mysql 将double转成科学计数法的
- 8mysql数据转mongodb_mysql数据转存到mongodb
- 9git中reset、restore、checkout、revert、clean的用法和区别_reset current branch to commit和checkout revision的区
- 10C语言AOE网、关键路径_画aoe网
Elasticsearch:从头开始解释带有 Transformer 的生成式 AI 架构_transformers 人工智能
赞
踩
这篇长篇文章解释了生成式人工智能的工作原理,从基础一直到注重直觉的生成式 transformer 架构。

这篇长篇文章解释了生成式人工智能的工作原理,从基础一直到生成式 transformer 架构。 重点是直觉,而不是严谨性。 当然,许多技术细节都得到了简化。 这是一篇温和的介绍,而不是一篇科学文章。
我们将其分为两部分:第一部分解释人工智能如何理解自然语言。 这包括嵌入、语言模型、transformer 编码器、自注意力 (self-attention)、AI 搜索和 NLP 的微调。 第二部分将在此基础上解释人工智能如何使用这种理解来生成文本,例如对自然语言提示 (prompt) 和翻译的响应,包括仅解码器和完整的转换器架构、大语言模型(LLM)和检索增强生成(RAG) ,Elastic 擅长的一种突出的生成模式。 由于我们将讨论的语言模型涉及神经网络,因此本旅程中的某些部分假定对基本神经网络有基本的了解。
GenAI 的语义阶段:理解自然语言
1. 理解嵌入、向量相似度和语言模型
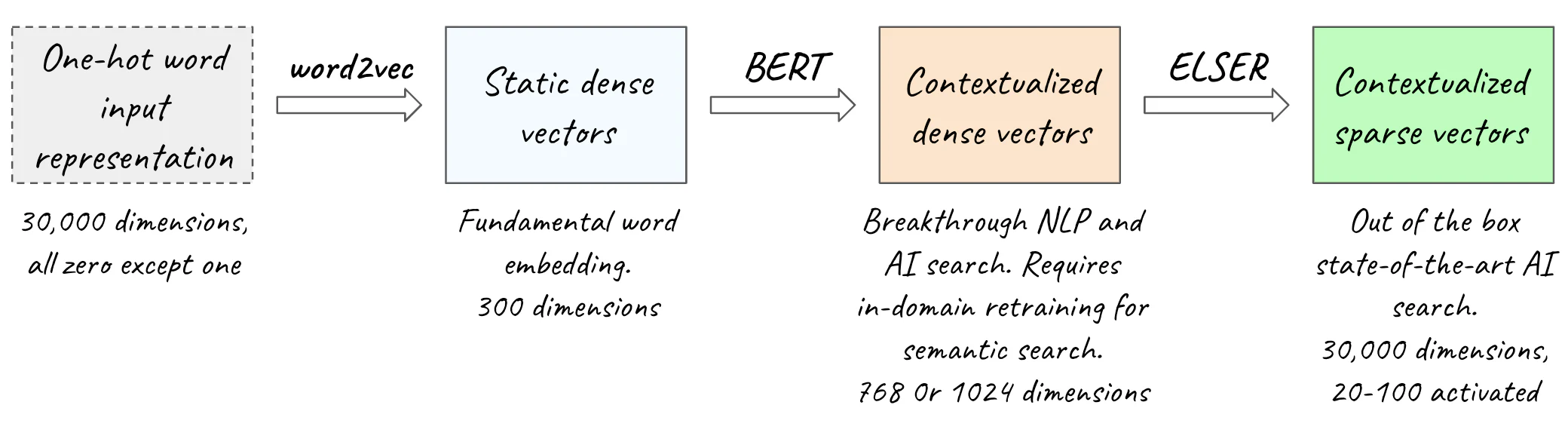
人工智能理解语言的基本结构是向量。 向量代表单词,只是数值的长数组。 从技术上讲,向量还可以表示单词或子单词部分的序列,因此我们用术语标记 (token) 来抽象它(这对于我们的讨论来说不是本质的,我们将互换使用术语单词和标记)。
在最简单的层面上,语言中的每个单词(或标记)都有一个向量表示,即 一长串学习到的数值。 你可能会遇到 “数千维向量” 甚至 “数万维向量” 之类的语言,但是,这确实没有什么奇怪的,请避免挤压你的大脑来理解 “数千维” 可能意味着什么。 对于每个单词,每个维度只是该单词向量中的一个特定位置,仅此而已。 我们很快就会想象这意味着什么,并且它将变得透明。
根据用于表示文本的模型的架构,稀疏模型将使用高维向量(维度为 10,000 到 100,000+ 的向量)以及很少的非零值,称为稀疏向量(sparse vector)。 在稀疏向量中,每个维度对应于词汇表中的一个单词。 词汇表是模型可以接受的所有唯一单词的集合,也就是,它们存在于模型训练所用的自然语言语料库中(我们将在下一节中看到如何训练模型)。 因此,稀疏向量的维度与词汇表中的单词一样多,即 数万或数十万维。 为了简化讨论,我们假设词汇表中有 30,000 个单词(这非常接近以英语为母语的人的平均词汇量)。 在稀疏向量中,大多数维度的值为零,少数维度为非零。
These are not the droid you are looking for. No, I am your father.these:1, are: 2, not: 1, the: 1, droid: 1, you: 1, look: 1, for: 1
no: 1, i: 1, am:1, you: 1, father: 1

与密集向量相反,密集向量具有数百到几个维度,通常包含非零值。 在密集表示中,计算这些数值以便语义相关的单词具有相似的向量表示,即 它们在相应位置具有相似的数值(换句话说,它们在每个维度上具有相似的值)。 现在你已经了解了入门语言模型的最基本描述:简单的语言模型是为语言中的每个单词分配向量值,以便语义相关的单词具有相似的表示。 单词越相关,它们的向量就越相似。 向量相似性是人工智能的核心。
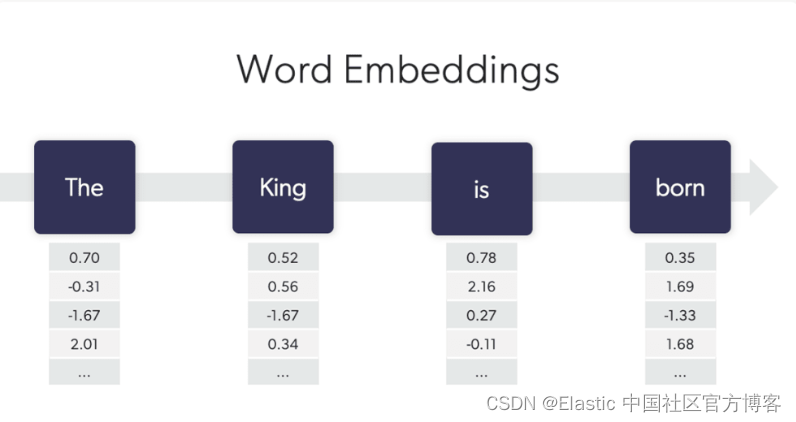
使用向量的一个方便之处在于我们可以测量它们的相似度。 我们使用距离函数来做到这一点,但在本次讨论的其余部分中,我们将直观地探索向量相似性,以使概念变得清晰。 因此,为了继续前面的推理,语言模型在向量空间中生成单词的表示,使得相关单词具有相似的向量,即 向量空间中向量之间的距离很小。 如果这读起来有点神秘,请放心,我们将在接下来的段落中使用直观、真实的可视化来解开它。
生成向量表示和自然起点的最基本方法之一是称为 word2vec 的算法(我们将在下一节中详细研究 word2vec)。 在 word2vec 实现中,每个向量都有 300 个维度。 300 个向量位置中的每一个都包含 -1 到 +1 之间的值。 由于相对于词汇表中单词数量的维数较低,并且大多数向量的位置都持有非零值,因此 word2vec 向量是密集的。 这些密集向量也称为词嵌入,生成它们的 word2vec 嵌入算法称为嵌入模型。
正如所承诺的那样,是时候可视化这些密集向量了。 为了快速、肉眼地观察向量相似性,我们将用颜色表示值。 蓝色代表 -1,白色代表 +1,相应的蓝色代表 -1 和 +1 之间的所有值。
在接下来的可视化中,我们仅显示 300 个位置中的前 50 个位置,以便更轻松地对向量进行视觉比较。 注意它们之间的相似之处。


这是第一个关键点:向量相似性捕获语义相关性。 在第一个示例中,“fruit” 和 "pear” 相关,“man” 和 “woman”相关。 它们与同义词不同。 相关性更广泛。

它也更细粒度。 这是第二个关键点:人工智能解决了单词和概念之间的关系。 它不理解含义,但它模拟含义之间的关系! 关系越密切,向量就越相似,同义词位于频谱的末尾。
关于语言的快速注释:这是一个棱镜,在本文和其他地方,任何对 “人工智理解的语言(AI understanding language)” 的引用都应该通过它来解释。 这种语言不应暗示人类水平的理解。 这一事实被称为 “意义的障碍 (the barrier of meaning)”。
让我们更深入地挖掘一下:你可能想知道这些值(向量元素)是如何计算的,因为相关单词肯定有无数种方式具有相似的向量表示。 在训练期间以捕获单词之间关系的方式计算密集向量元素(训练语言模型是我们接下来讨论的重要部分)。 例如,女孩之于女人就像男孩之于男人,因此,希望 “女人” 和 “女孩” 之间的增量与 “男人” 和“ 男孩” 之间的增量相似。

为了进一步扩展它,如果你从 “father” 中减去 “man” 并加上 “woman”,你会得到一个类似于 “mother” 的向量。

事实上,使用 Gensim 的 most_similar,我们可以确认与 “father-man+woman” 向量最相似的向量实际上是 “mother”:

同样,如果从 “France” 中减去 “Paris” 并添加 “Rome”,则最相似的向量是 “Italy”。

主要直觉是语义关系反映在密集向量的某些模式中。 当你训练语言模型时,你正在塑造向量空间以反映语言中单词之间的关系,以便通过最终为所有密集向量获得的元素分配来捕获这些关系。
为了强化这种直觉,让我们想象一个语义上 “中性” 的单词,比如 “the”,并将其与一个更具体的单词进行比较。 在本例中,让我们可视化所有 300 个位置(以 300 维表示形式)。 我们观察到 “the” 的向量更加平滑(所有维度上的值几乎是均匀的)。 它与许多概念同样相关(或不相关)。 相反,一个特定的单词会不同程度地激活不同的维度,编码该单词与单词和概念的语言关系(与技术相关的其他单词可能会显示出与其类似的模式)。

让我们继续看看嵌入是如何计算的。
1.1 学习稠密向量
英国语言学家约翰·弗斯 (John Firth) 在 1957 年引用了一句话:“你应该通过它的同伴来认识一个单词 (You shall know a word by the company it keeps)”。 这种根据单词出现的上下文来定义单词的旧想法正是你将在本节中看到的实际情况。
word2vec 模型(及其变体、改进和扩展以表示句子而不是单词等)是我们的起点,原因有两个:
- 它是用自然语言捕获和表示关系的最流行的基本方法之一,就像我们所看到的那样。
- 因此,它的嵌入经常被用作我们感兴趣的现代 AI Transformer 架构的输入。
训练这种语言模型的策略包括向其提供大量自然语言,同时在某些上下文中屏蔽(隐藏)单词并要求其进行预测。 为了能够成功,它需要学习预测输入序列的屏蔽词,并且在此过程中,它学习了语义一致的单词向量表示。 让我们看看如何实现。
Word2vec 是一个浅层神经网络,其输入和输出神经元层的神经元数量与语言词汇表中的单词一样多(即数万个,我们将坚持讨论的 30,000 个值)。 输入层接受序列。 这些是 one-hot 编码的,即,如果序列中存在单词,则相应的输入神经元接收到 1,否则接收到 0。
大量的自然语言来自于互联网上的新闻和文章爬行。 为了将它们转变为训练示例,我们使用滑动窗口。 从第一个文档的开头开始,在每个步骤中,窗口都包含文本中固定数量的单词,这些单词成为单个训练示例。 下一步是将窗口向右移动一个单词,以捕获下一个训练示例。 滑动窗口移动,在每一步创建一个训练示例,直到到达训练数据集的末尾。

我们可以在滑动窗口的每一步隐藏滑动窗口内的某个单词位置。 例如,如果窗口有 5 个单词,我们可以在每一步隐藏中间的单词。

我们将其他四个输入到 word2vec 网络的输入层(以我们讨论的 one-hot 方式),并使用屏蔽词作为神经网络预测的目标。 这种配置称为连续词袋(Continuous Bag of Words - CBOW)。 总而言之,CBOW 将每个单词周围的上下文输入到网络中,并在给定上下文的情况下预测丢失的单词。
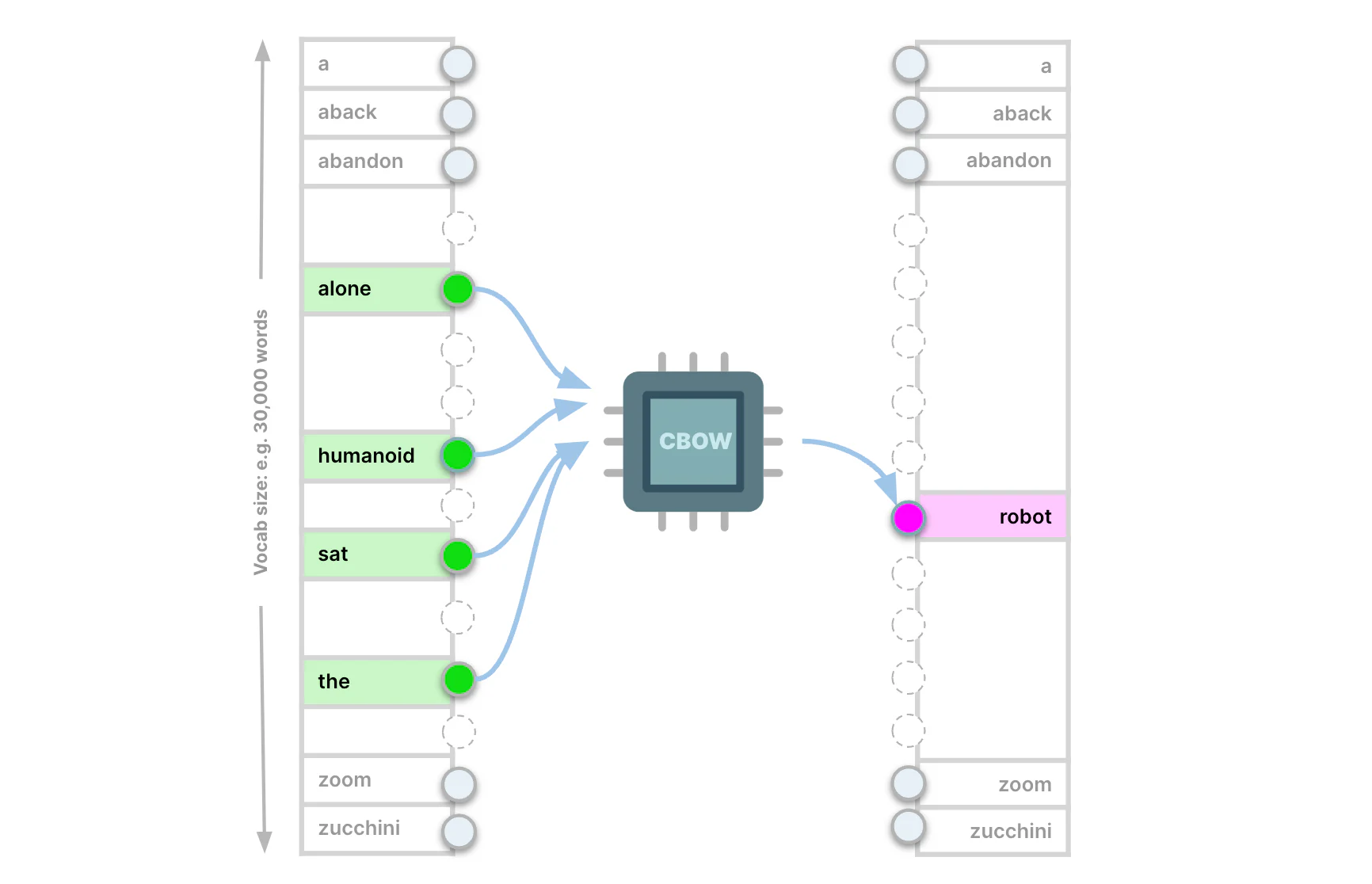
第二种 word2vec 配置称为 Skip-gram:Skip-gram 隐藏窗口中除一个单词之外的所有单词,并预测其周围的单词(仍在窗口内)。 所以 skip-gram 是 CBOW 的镜像:我们在窗口中隐藏某个单词并预测它周围的上下文。 正如你可能怀疑的那样,Skip-gram 执行更具挑战性的任务:你在每个步骤中向其提供较少的信息,并要求它预测更多的信息。 因此,skip-gram 的语言学习更深,训练速度更慢。 因此,在 skip-gram 中,向量相似度主要表示语义 (semantic) 相似度,即,语义相关的词获得相似的向量。 相反,在 CBOW 中,向量相似性主要表示句法 (syntactic) 相似性(较浅的关系,例如 “dog”、“dogs” 等)。 上一节中的嵌入是通过skip-gram获得的。

但这个过程中的嵌入从何而来,相似的词如何获得相似的向量呢? 让我们进一步了解 word2vec,特别是更有趣的 skip-gram。
在下图中,你可以看到神经网络的描述,其输入层大小为 30,000,等于词汇表中的单词。 在训练期间,它在窗口内接收 skip-gram 的中心词。 输出层是一个 softmax,它生成词汇表中每个单词在输入单词上下文中的概率。
隐藏层(hidden layer)由与我们想要学习的嵌入维度一样多的神经元组成。 我们检查的嵌入有 300 个维度,因此生成它们的网络有一个包含 300 个神经元的隐藏层。
word2vec 嵌入,即,每个单词的向量是训练结束时输入层的权重。 隐藏层充当瓶颈,将信息压缩为 300 维的密集向量。

让我们把所有东西放在一起:语义相关的单词获得相似的密集向量,因为它们在相似的上下文中占有一席之地。 因为,正如我们所讨论的,skip-gram 预测每个单词最可能的上下文,这意味着两个语义相关的单词将学习产生类似的 softmax 结果。 为了实现这一点,相应的输入权重(成为词汇的密集向量)必须相似,没有办法绕过它。
至此,我们知道了现代 NLP 的基本构建模块(密集向量)是如何计算的。
最近的 GenAI 革命发生了,我们有能力生成更加高度情境化的嵌入。 回想一下我们在本节开头所引用的旧想法和引言。 最近的 NLP 引擎能够更深入地处理上下文,这为最近的进步和卓越的人工智能功能提供了动力。 Transformer 在输入中使用静态嵌入(例如 word2vec)来生成编码更丰富、更精细的上下文的密集向量。
2. 背景:GenAI 的血脉
生成式人工智能和语义人工智能搜索是同一脉络,它们的 “血液” 是情境化嵌入,即 通过 Transformer 实现对自然语言的新的更深入的理解。 我们将在本次讨论的其余部分详细解释 transformer 架构。
Transformer 是由 Google 研究人员于 2017 年在著名的 “Attention is all you need” 论文中引入的 [1]。 Transformer 的引入是当今 AI 繁荣的催化剂,它是 ChatGPT(GPT 代表 “生成式预训练 Transformer”)和其他病毒式应用程序的架构。
考虑像 word2vec 这样的静态嵌入存在以下问题:
我们如何捕捉在不同上下文中具有不同含义的单词? 例如:“Fly”:动词 vs 昆虫,“like”:动词 vs 介词(“类似于”),“Apple”:水果 vs 品牌等。
此外,我们如何处理指称物体或人的代词? 在下面的示例中,我们希望根据上下文,用类似于 “robot” 或 “road” 的向量来表示 “it”,而不是代词 “it” 的通用 “neutral”表示。

进入到 transformer 编码器。 BERT(来自 Transformers 的双向编码器表示)是最著名的编码器架构。 它于 2018 年推出,超越了大多数自然语言理解和搜索基准,彻底改变了 NLP。 像 BERT 这样的编码器是现代人工智能的基础:翻译、人工智能搜索、GenAI 和其他 NLP 应用。
随着 BERT 的推出,谷歌实现了搜索突破。 今天的 Google 搜索由 BERT 提供支持。
了解搜索查询中的上下文意味着:
- 我们可以显示使用同义词而不是确切的查询术语的文档。 通过考虑相关单词,它远远超出了同义词的范围。 正如我们在一开始所讨论的,相关性比单独的同义词更强大。
- 我们可以更好地理解用户的意图:我们现在可以关注静态嵌入和简单术语匹配忽略的单词。 否定诸如 “no” 或 “without”之类的词以及涉及某种形式的方向关系(例如 “to” 和 “for”)的词对于捕获用户的意图并帮助呈现最相关的结果非常重要。 例如,在查询 “best smartphones for photography” 时,重点应该放在相机方面。 在查询 “documents required when traveling from Europe to the US” 中,我们不应该显示讨论欧洲国家所需文件的资源。
- 相反,我们可以减少权重或忽略作为文档中复合词的一部分匹配的术语,但它们在查询中的独立含义完全不同。 例如:包含 “stand” 的查询不应显示你正在阅读的文档,尽管其中包含术语 “stand-alone”。
如果你想了解更多有关 BERT 突破的搜索示例,请查看 Google 的博客:[2]。
对上下文的同样理解也为今天的 GenAI 提供了动力,两者齐头并进。 本质上,交互模型通过以自然语言而不是基于术语和文档列表形成查询和结果来改变。 基础是对自然语言更深入的语义理解。
3. Transformer - 编码器架构
认为 BERT 从根本上做了两件事:
- 生成情境化嵌入。
- 根据上下文预测单词。 我们将在接下来的训练部分详细介绍,但从根本上说,BERT 是一种掩码语言模型。 它可以预测给定序列中的屏蔽词(也可滚动回图 10)。
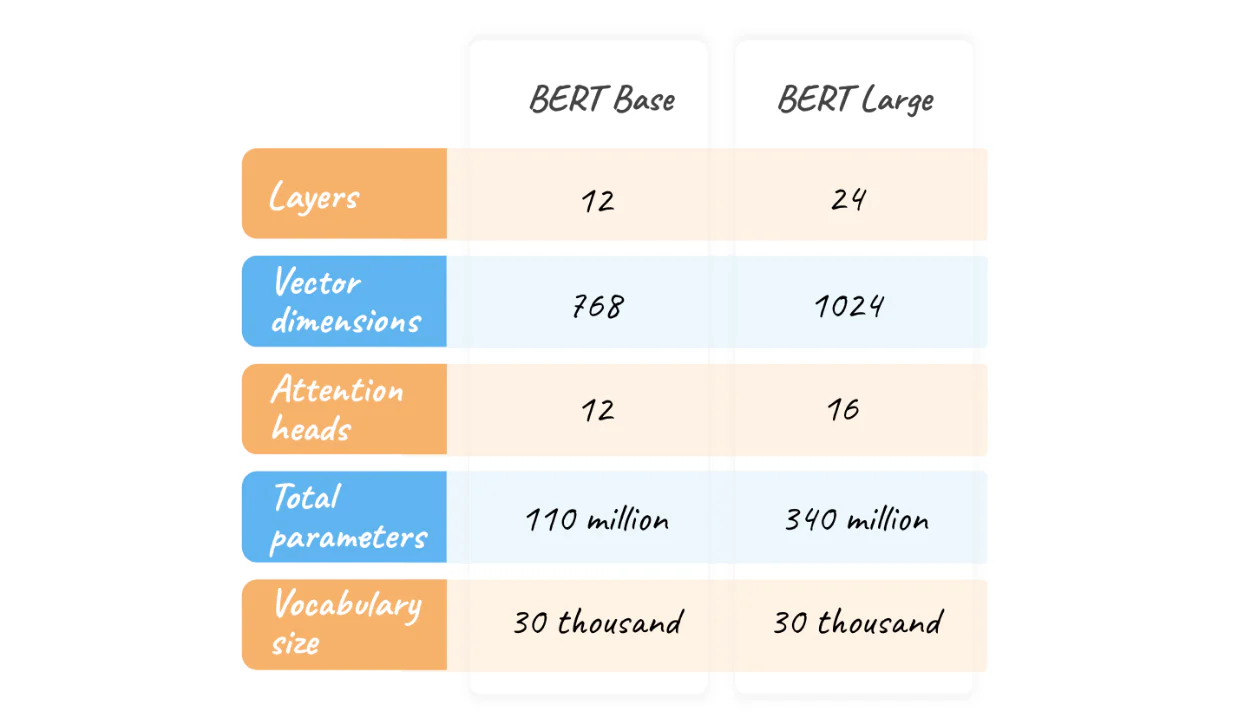
BERT 以静态文本嵌入(如 word2vec)的形式接收自然语言序列,并输出上下文化嵌入。 因此,我们正在从每个单词的单个固定向量转向根据上下文进行调整的独特自定义表示。 BERT 由 12 个编码器块(BERT Large 为 24 个)组成,一个一个地堆叠在一起。

在输入中,静态嵌入与位置信息相结合。 请记住,在 word2vec 训练期间,无论是 CBOW 还是 Skip-gram,每个序列都被视为一个词袋,即,序列中每个单词的位置被忽略。 然而,单词的顺序是重要的上下文信息,我们希望将其输入到变压器编码器中。
让我们双击一个编码器块(图 15 的 12 或 24 个块之一)。 每个编码器层从其下方的前一个编码器层接收输入嵌入,并将嵌入输出到下一个编码器层。 编码器本身由自注意力(self-attention)子层和前馈 (feed-forward) 神经网络子层组成。
Transformer 架构中情境化的动力源是注意力机制。 具体来说,在编码器中,它是自注意力子层。 在编码器中,每个自然语言嵌入序列都经过自注意力子层,然后是前馈子层。 本节的其余部分将主要详细解说 self-attention,包括它的名字的由来。
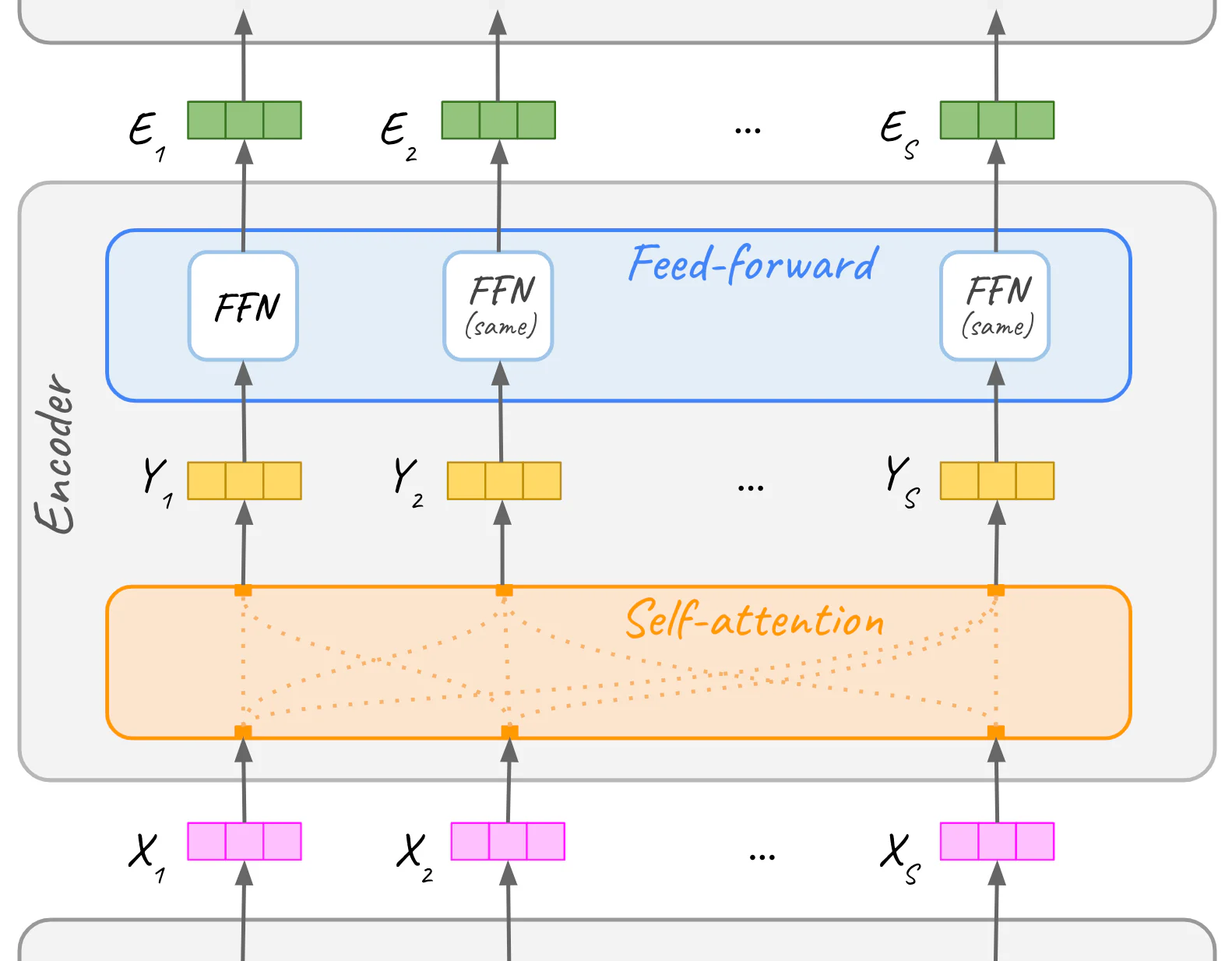
3.1 自注意力 - self attention
自注意力通过 “混合” 输入文本中的上下文信息来增强嵌入。 对于给定文本中的每个单词,它会识别序列中与其最相关的单词,并更新其嵌入以包含上下文信息。
术语 “自注意力” 涉及关注输入序列本身内不同单词的能力(与关注输入序列外部上下文的注意力系统相反,正如我们将在即将到来的第二部分中看到的)。
这样,上下文会影响每个单词的表示,并且静态嵌入会转换为针对特定上下文定制的向量。 上下文嵌入也是密集向量。
从一个低严格的直觉概念图开始(参见下图 17),我们将逐步展示自注意力如何产生真正的情境化嵌入。

它是如何做到的? 当然,向量相似性:相关单词具有相似的向量,这就是自注意力识别它们的方式。 因此,对于文本中的每个给定单词 X,自注意力会识别其上下文中最相关的单词。 然后需要一种方法让识别出的相关词影响给定词 X 的嵌入。
上下文单词通过影响 X 的上下文向量来影响嵌入。X 的向量根据上下文中相关单词的组合效果进行更新。 他们的关系越密切,他们的贡献就越大。
到目前为止,我们已经从视觉上接近了向量相似度,现在是时候更严格地讨论它了(它仍然非常简单)。 我们将使用点积作为相似性的度量。 点积是两个向量逐元素乘法的总和。 两个相似的向量具有高点积。 两个不相似的向量具有较低的点积。
让我们计算 “band” 在两种不同上下文中的上下文嵌入:作为音乐团体和作为发饰,按以下顺序:
- “The blues band played their best songs”
- “The blue band held her hair”
首先,我们将计算点积。

因为点积取任意值,所以我们将它们标准化为加起来为 1。我们通过缩放和 softmaxing 来实现这一点。 标准化点积是注意力权重。
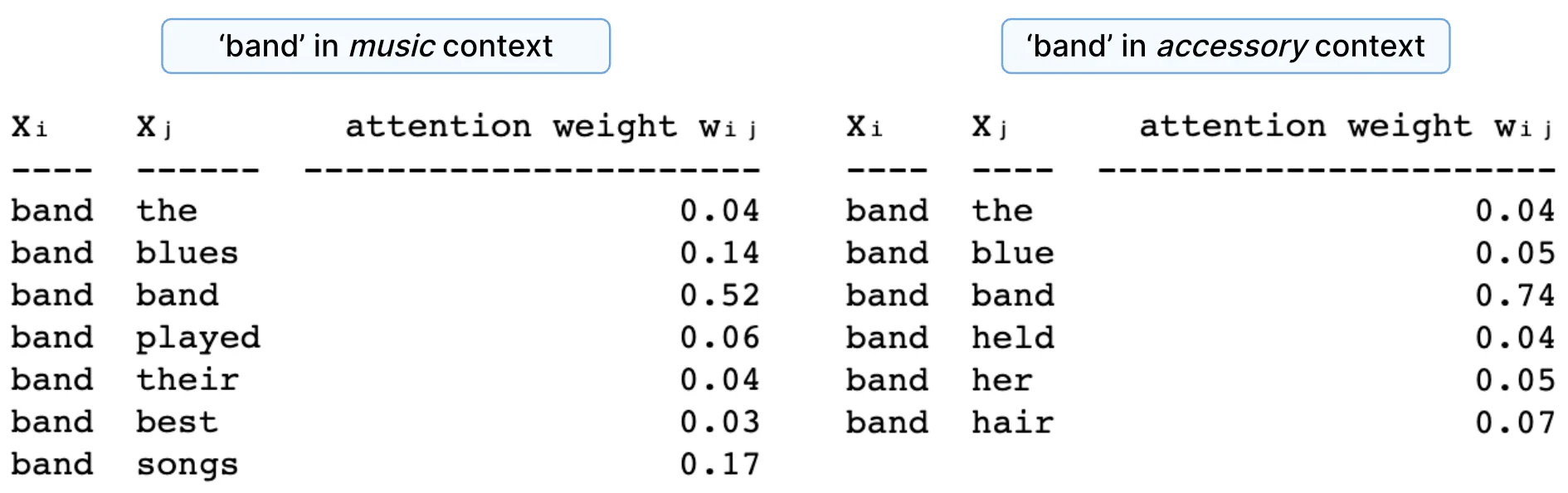
每个单词的上下文嵌入是将上下文中的所有向量(包括其本身)按相应的注意力权重加权的结果相加。 请注意,查询词本身是最终向量中的主要组成部分,因为与其自身的点相似度产生最高分数。 直观上,你可以说我们根据上下文 “推动” 原始向量。
以下是前面示例中 “band” 一词的样子,请参见下图 20:
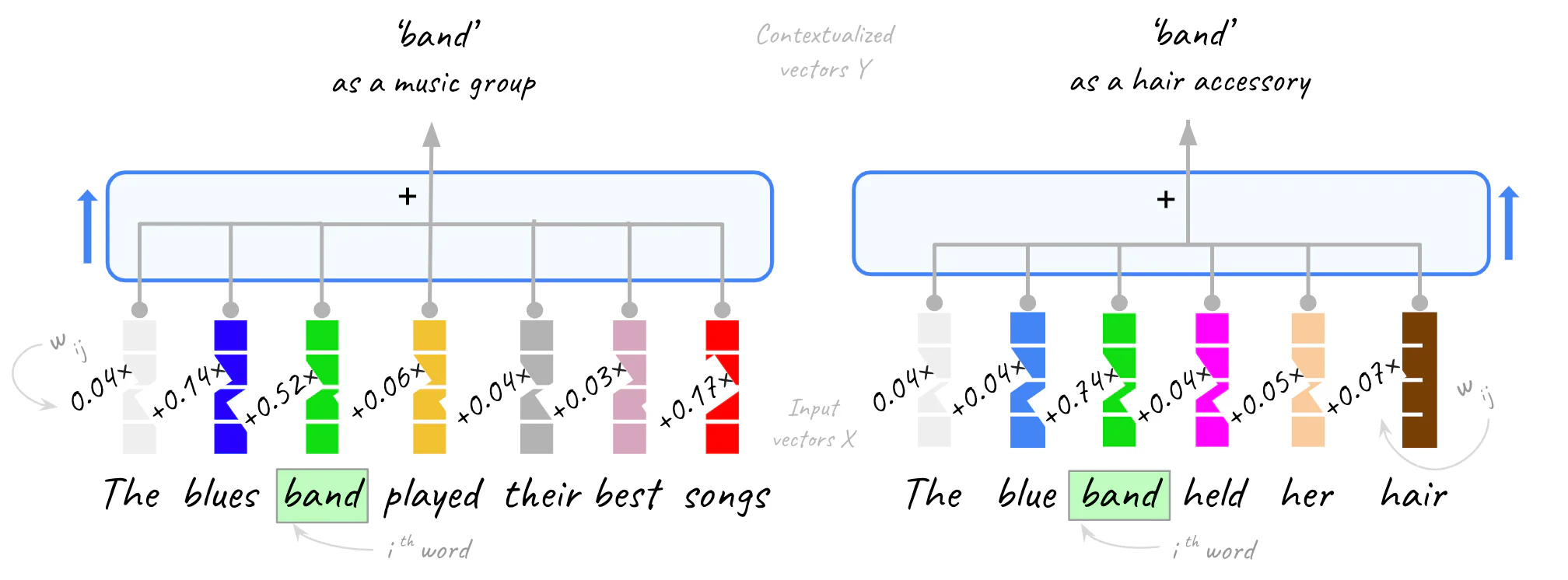
这同样适用于上下文中的所有其他单词,为了简单起见,我们只展示了其中一个单词。
所以上下文向量 为
序列中的第 个单词计算如下:

在这里, 是单词 j 的注意力权重,而
是单词 j 的输入向量。
这是此操作后实际向量的样子。 在本例中,我们将使用三色代码(-1 为蓝色,0 为白色,+1 为红色,中间的实际值是颜色渐变)。 这种选择夸大了差异(两种颜色的差异更微妙,更容易发现),以帮助注意到自注意力的效果。
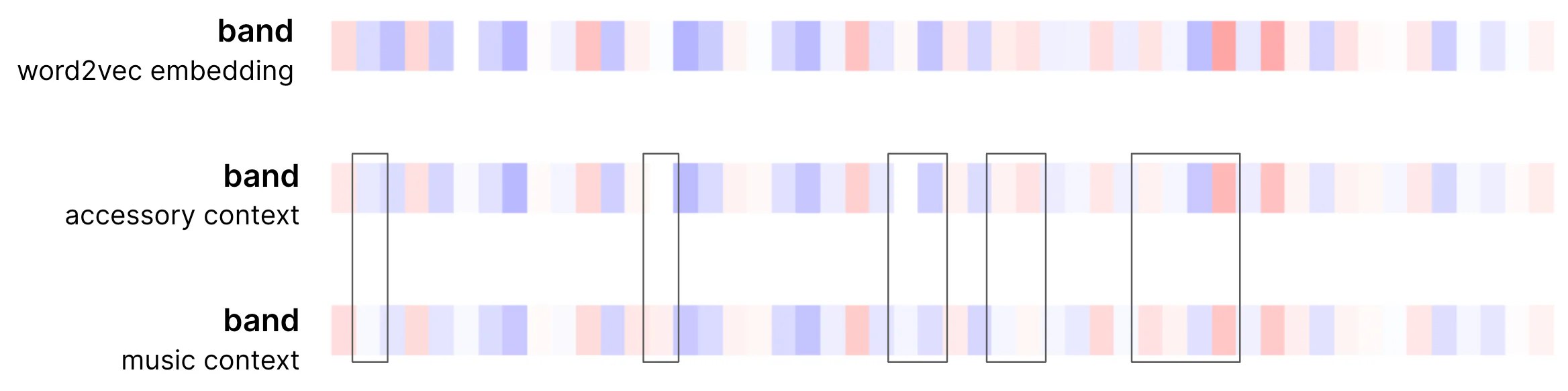
请注意,在音乐示例中,向量的调整更加积极,因为存在更多相关上下文,并且单词相对于其自身的分量接收更小的权重(在发饰示例中为 0.52 与 0.74)。
现在,根据上下文,同一个单词有两种不同的表示形式。 现在你知道了自注意力的基本机制。
此时,你要么已经满足,要么已经在想:
“等一下。 ‘band’ 的两个完全不同含义的向量非常相似,因此你必须突出显示差异。 为什么?”
接得好! 首先,请注意,我们使用的输入是静态 word2vec 嵌入,即我们实际上在底部编码器层上工作。 回想一下,BERT 有 12 个编码器层,BERT Large 有 24 个。每一层都会进一步改变嵌入。 其次,我们尚未在叙述中包含同一编码器块中的第二个子层:前馈网络(我们将在接下来讨论)。
这还不是全部。 我们讨论的核心机制通过另外两种方式得到增强,使 self-attention 能够充分发挥你在 Google 搜索、Elastic 的 AI 搜索和生成 AI 应用程序中看到的力量。
所以第三点是我们到目前为止讨论的自注意力系统还没有引入任何学习参数。 到目前为止,所有值都是根据现有向量计算的。 学习系统需要在训练期间学习参数,以便进行泛化。
为此,自注意力采用了参数矩阵及其运算系统。 我们不会详细介绍,因为它们并不是非常有趣,但因为在阅读其他资源时很可能会感到困惑,我们将在这里描述它的要点。 请随意跳过这一点(当然不要坚持下去):
我们有机会在迄今为止描述的自注意力操作的以下点引入参数:
- 在计算点积时,我们可以参数化向量
和向量
。 我们为这些向量的每个位置引入一个独立的参数。 此时你将遇到以下术语:我们将向量
- 通过将注意力权重(作为上一步的结果)与每个位置 j 的向量
引入这些参数并在训练编码器期间学习它们,可以优化上下文嵌入的创建。
然后是多头 (multi-head) 自注意力。
3.2 多头 (multi-head) 自注意力
我们刚才讨论的参数是架构的基本部分,因为如果没有它们,自注意力就不会成为语言模型核心的学习系统。 更进一步,我们以更大的自由度增强它:可以并行学习更多参数。 毕竟我们正在构建一个大型语言模型,“大型” 意味着数亿个参数(BERT 大约有 1.1 亿个参数,BERT Large 大约有 3.4 亿个参数,GPT-3 大约有 1700 亿个参数),我们可以做到这一点,因为我们训练 它在巨大的语料库上。
这就是我们想要这样做的原因:考虑输入文本比我们迄今为止玩过的玩具句子更长。 上下文越长,相关单词对上下文嵌入的影响越弱(想想标准化的注意力权重,单词越多,每个单词的影响越小)。
为了缓解这个问题,我们通过使用所谓的自注意力头中的独立参数并行执行多次来复制迄今为止描述的机制。 因此,我们将刚刚引入的参数乘以自注意力头 (heads) 的数量。 每个头都独立于所有其他头执行我们到目前为止描述的算法。 BERT Base 特别部署了 12 个注意力头(BERT Large 为 16 个)。
有了一个头,自注意力可能能够也可能无法集中在长序列中的相关术语上。 多个头就可以做到。
让我们从介绍性设置开始,使用 Bertviz 来可视化实际的 BERT 多头自注意力。 在下面的可视化中,每个头都由顶部数组中的一种颜色表示。 连接器显示每个头关注的关系。 在我们之前介绍的自注意力术语中,左列是 “查询” 向量,用于检查右列中它关注的 “键”(相同的序列显示在两列中,以便更清晰地可视化自注意力) 。 颜色越浓,注意力权重越高。

有一些有趣的事情需要注意。
多头自注意力能够捕获远程关系(该示例适合展示这种关系)。 请注意,在第二个自我注意力头(橙色)中,“ceo” 如何关注 “company” 和 “shareholders”,两者相隔几个词。 同样,对于 “company”,多个负责人关注“股东”和“战略”,所有这些都只有几个词。 这是值得注意的,因为以前的技术无法有效地捕获这种远程关系。
将此行为与第五个头(下一个可视化中左侧的紫色)进行对比。 它错过了 “ceo” 的重要关系,因为像我们讨论的那样,在长序列中可能会发生焦点丧失效应。 多头的附加值在这里受到重视,因为单个头可能会陷入类似于第五个头的行为。

此外,请注意在正确的可视化中,自我注意力如何能够捕获其他句法关系,例如动词 “appointed” 的时间信息(尽管这更具争议性,因为这些单词很接近)。
围绕多头自注意力及其能够(或不能)捕获句法/语言现象的程度有积极的研究。 如果你好奇,“What Does BERT Look At?” [3] 和 “Assessing BERT’s syntactic abilities” [4] 论文是很好的起点。 他们的作者分析了自我注意力如何捕捉不同的语言关系,例如直接宾语与动词的关系、名词修饰语与名词的关系、命题与宾语的关系等。
最后,请注意,每个头都会为输入序列的每个单词计算自己的上下文嵌入。 然而,编码器为每个单词输出一个嵌入,因此我们需要一种方法将每个头的输出组合为单个嵌入。 此时,你不会感到惊讶,为此,我们向模型引入了更多参数,其作用是创建正确的组合。
3.3 前馈 (feed-forward) 神经网络
每个编码器层内的第二个组件是前馈神经网络(feed-forward neural network 简称 FFN),请参阅图 16。这是一个应用于序列的每个位置的全连接神经网络。 在原始 Transformer 架构中,FFN 内层的维数是嵌入维数的四倍,而 BERT Base 为 768,BERT Large 为 1024,完整 Transformer 为 512。
首先要注意的是,虽然在自注意力层中,序列中的输入嵌入相互交互以产生子层的输出,但它们独立地并行通过 FFN 子层。
第二个需要注意的是,每个序列位置都应用相同的 FFN,即具有相同权重的 FFN。 这就是为什么它在文献中被称为逐步 (stepwise) FFN 的原因。 然而,虽然 FFN 在同一编码器层的位置上具有相同的权重,但它在不同编码器层上具有不同的权重。
为什么做出这些选择? 当然,不同层上有不同的 FFN 允许我们引入更多参数并构建更大、更强大的模型。 另一方面,我们想要在同一层中使用相同的 FFN 的原因不太明显。 直觉是:如果我们在 FFN 子层中输入相同重复嵌入(例如相同单词)的序列,则子层的输出嵌入在序列的所有位置上也应该相同。 如果我们允许在同一子层中使用多个具有不同学习权重的 FFN,情况就不会是这样。
随着架构的澄清,以及自注意力的作用是合成上下文嵌入,下一个大问题是:FFN 在 Transformer 中的作用是什么?
在最高级别上,请注意,正如我们在前面几节中所描述的,自注意力子层仅涉及线性变换。 FFN 子层引入了学习最佳上下文嵌入所需的非线性。 我们将尝试在本文的第 2 部分中,在完整的 Transformer 架构的背景下,通过解析该活跃领域中进行的研究提供的一些直觉,来更接近地了解这意味着什么。
让我们通过总结 BERT 架构来结束本节:
4. AI 搜索和 NLP 语言模型的训练和微调
我们已经了解了 Transformer-encoder 和 BERT 的工作原理,现在是时候更详细地检查它们的训练了。
训练涉及学习我们在自注意力和前馈子层中讨论过的所有这些参数(见图 16),并且如上所述,训练基于掩蔽(见图 10):编码器提供了一个庞大的语料库 。 在每个训练序列中,单词可以被屏蔽。
BERT 专门在整个维基百科和 BookCorpus 上进行训练,方法是屏蔽 15% 的输入并要求它预测屏蔽的单词。 15% 是掩蔽过多和掩蔽过少之间的最佳点,掩蔽过多会导致训练成本非常昂贵,掩蔽过少会在训练期间消除有用的上下文。
对于训练,我们在 BERT 的输出中使用掩码语言模型 “head”(简称 MLM 。 MLM 头是预测屏蔽词的神经网络。 它具有与 BERT 密集输入中可能的单词数量一样多的输入神经元(BERT Base 为 768 个),以及与词汇表中的单词一样多的输出神经元。 对于训练期间的每个屏蔽序列,头部接收序列的上下文嵌入(BERT 的输出),并生成词汇表中每个单词作为屏蔽单词的概率(使用典型的 softmax)。
计算预测和实际单词表示之间的增量,并在整个架构中反向传播梯度,调整我们在前面几节中讨论的每个编码器的自注意力和前馈网络子层参数的值(以及头本身)。 参考文献 [5] 是反向传播的复习(如开头所述,我们假设你熟悉神经网络基础知识)。
训练后,我们丢弃 MLM 掩码,编码器已准备好为任何输入序列生成上下文嵌入。

4.1 训练模式和语言模型迁移学习
从高层次上来说,训练模型涉及三个阶段:
预训练:该架构在大型数据集上训练为掩码语言模型,具有 MLM 头,就像我们到目前为止所看到的那样。 该方法的优点是,使用滑动窗口等策略进行掩蔽,我们可以预训练模型,而无需任何标记数据。
领域适应:为了获得最佳结果,我们在域内数据上重新训练预训练模型。 为此,我们必须使用目标领域(即模型将使用的主题领域或知识领域)的语料库,以帮助它获取特定领域的术语和语言模式。 我们可能拥有较小的领域内数据语料库,但事实上我们已经在大型语料库上对模型进行了预训练,这使得它在域内再训练后能够表现良好。 域适应也可以使用 MLM 头来完成,无需标记数据。
微调:除了搜索之外,像 BERT 这样的编码器还用于许多 NLP 任务,包括情感分析和其他文本分类、命名实体识别(NER)、问题回答等。在最后阶段,我们在顶部的 transformer 编码器使用特定于任务的头,专为手头的特定任务而设计。 例如,对于情感分析任务,头(head)是一个小型前馈神经网络,经过训练以输出每个类别的概率。 在此阶段,编码器用作特征提取器:它生成上下文化嵌入,用作 NLP Head 的输入。 这种策略称为迁移学习,在应用于 NLP 之前已应用于训练计算机视觉模型。 此阶段需要标记数据。
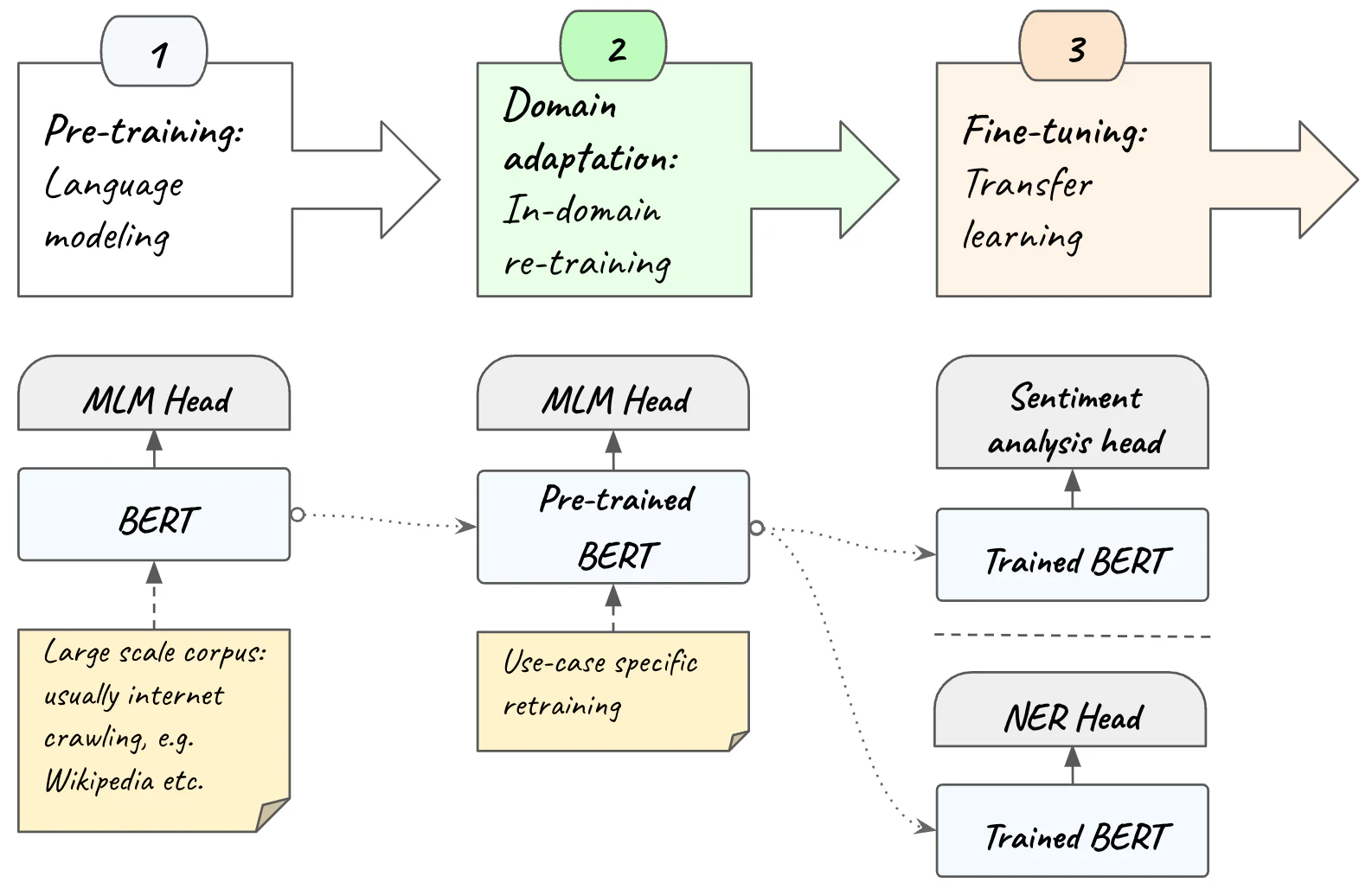
请注意,通过迁移学习,我们可以使用预先训练的 transformer 编码器来训练其上的文本分类头。 与选择在训练期间调整整个架构的权重相比,这极大地简化了我们需要做的机器学习工作。 在实践中,这意味着采用现有的预训练 BERT 模型,“冻结” 其所有参数,向其添加输出层,并仅训练手头任务的最后一层。 这样,我们只需要调整最后一层的权重,而不是 BERT 包含的数亿个权重。 迁移学习非常强大,通过冻结 BERT 的数百万个参数,训练时间、资源和域内数据要求都大大放松。
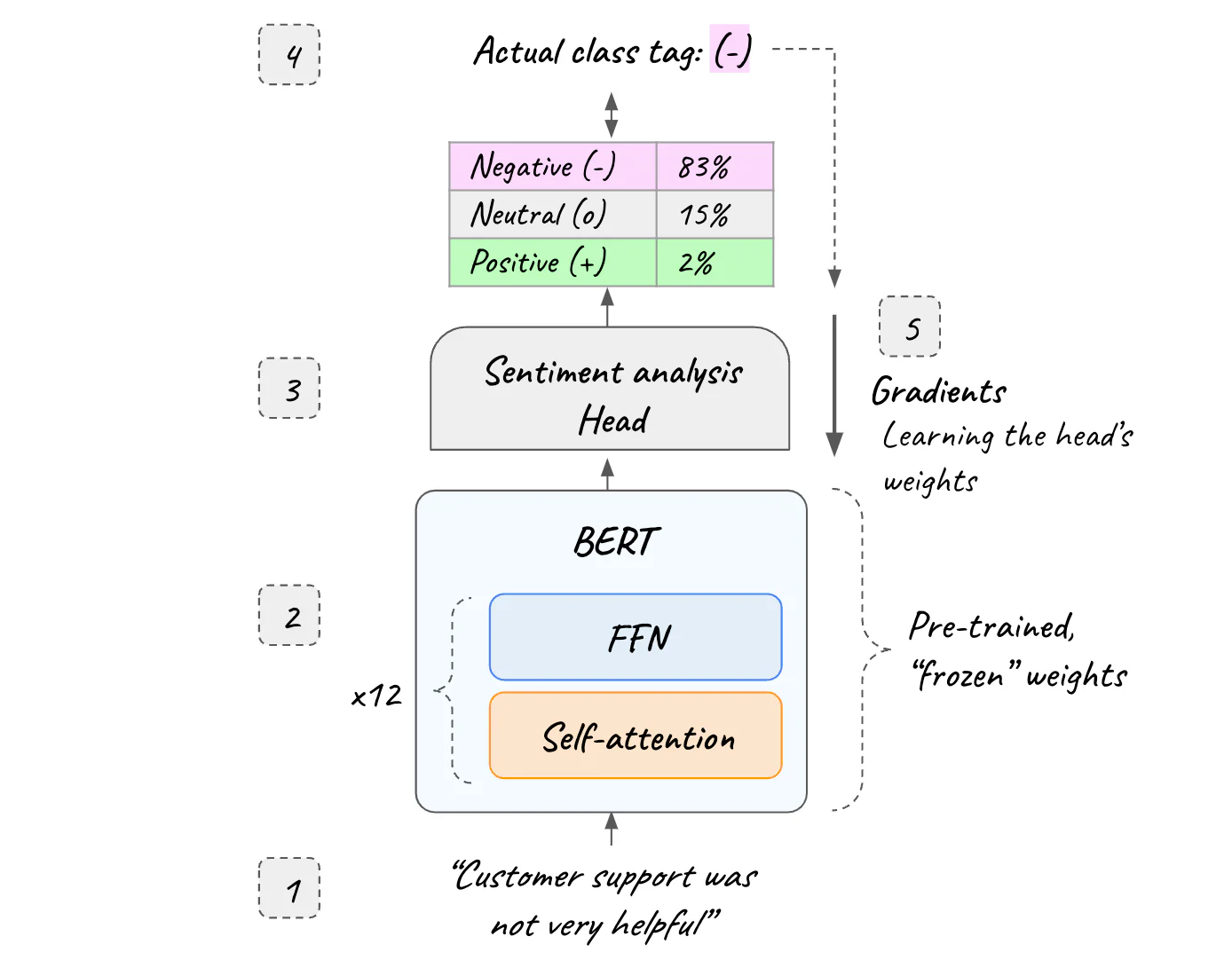
Elastic Machine Learning 让你可以极其轻松地上传和部署 HuggingFace 中受支持的预训练 Transformer-Encoder NLP 模型或环境中的自定义模型,以与 Elastic 数据一起使用。
4.2 人工智能障碍
培训、领域内适应和微调语言模型存在物质障碍:它们需要大量的人力和计算资源:一方面,机器学习专业知识需要远远超出传统软件工程的科学人才。 另一方面,训练模型是资源密集型的,通常需要 GPU 硬件和几周或几个月的处理时间,所有这些都会产生巨大的成本。
这还远远不是全部:在将模型部署到生产环境之前,你还需要离线和在线验证和测试模型。
微调需要标记数据,这意味着你需要花费人力或外包数据标记,或者生产能够以非常高的准确度自动标记数据的系统。
你的生产数据管道可能需要进行重大更改才能适应训练的预处理数据。 此外,如果你的生产数据与测试环境数据不同步(通常是这种情况),这可能会导致更深层次的数据工程和运营工作。
此外,模型和数据不是静态的,你可能需要构建模型漂移和数据漂移检测以减轻任何训练服务偏差。
由于特殊的硬件和软件要求,你的 MLOps 很可能需要与其他软件不同的发布周期。 你将需要与软件的其余部分建立适当的集成。
由于所有这些原因以及更多原因,人工智能驱动的自然语言理解和搜索对大多数组织来说都是一个非常高的障碍。
5. 用于开箱即用的 AI 搜索的 Elastic Learned Sparse Encoder
Elastic 学习稀疏编码器 (ELSER) 为搜索用例解决了这个问题。 它以 BERT 为基础,提供开箱即用的卓越人工智能搜索 [6]。 你只需在 Elastic UI 中单击几下即可下载 ELSER 并进行部署。 ELSER 真正需要零 ML 工作:它使你完全摆脱了上一节中简要描述的 AI 障碍。 它也不需要任何外部组件即可开始与熟悉的 Elastic search API 一起使用。
这样,Elastic 现在提供了两种选择:
- 其开箱即用的专有人工智能搜索模型。
- 部署第三方向量模型以与 Elastic 数据一起使用。
以下是 ELSER 的工作原理。
正如我们所讨论的,在预训练(以及域适应,如果执行了)之后,我们通常会丢弃 MLM 掩码,因为编码器的主要目的是为任何输入序列生成上下文化嵌入(如果我们的用例不涉及特定于任务的调整)。
然而,在训练过程结束时,MLM 头是一个经过训练的神经网络,它为任何输入句子中的每个屏蔽输入术语(上下文化,因为 BERT 在幕后发挥其魔力)生成所有词汇的概率分布。
在搜索用例中,输入序列是我们的查询。 输入序列/查询的每个位置通过以不同程度激活不同的单词,在词汇上产生不同的分布。
ELSER 背后的想法不是丢弃 MLM 头,而是使用它来为序列/查询中的每个单词生成这些分布。 由于 MLM 头在设计上并不稀疏,因此我们对其进行了适当修改并调整训练目标,使其稀疏并针对检索进行了优化。
如果我们将每个单词的分布聚合为整个序列/查询的分布,我们将生成一个向量,其值表示词汇表中每个单词被输入查询激活的程度。
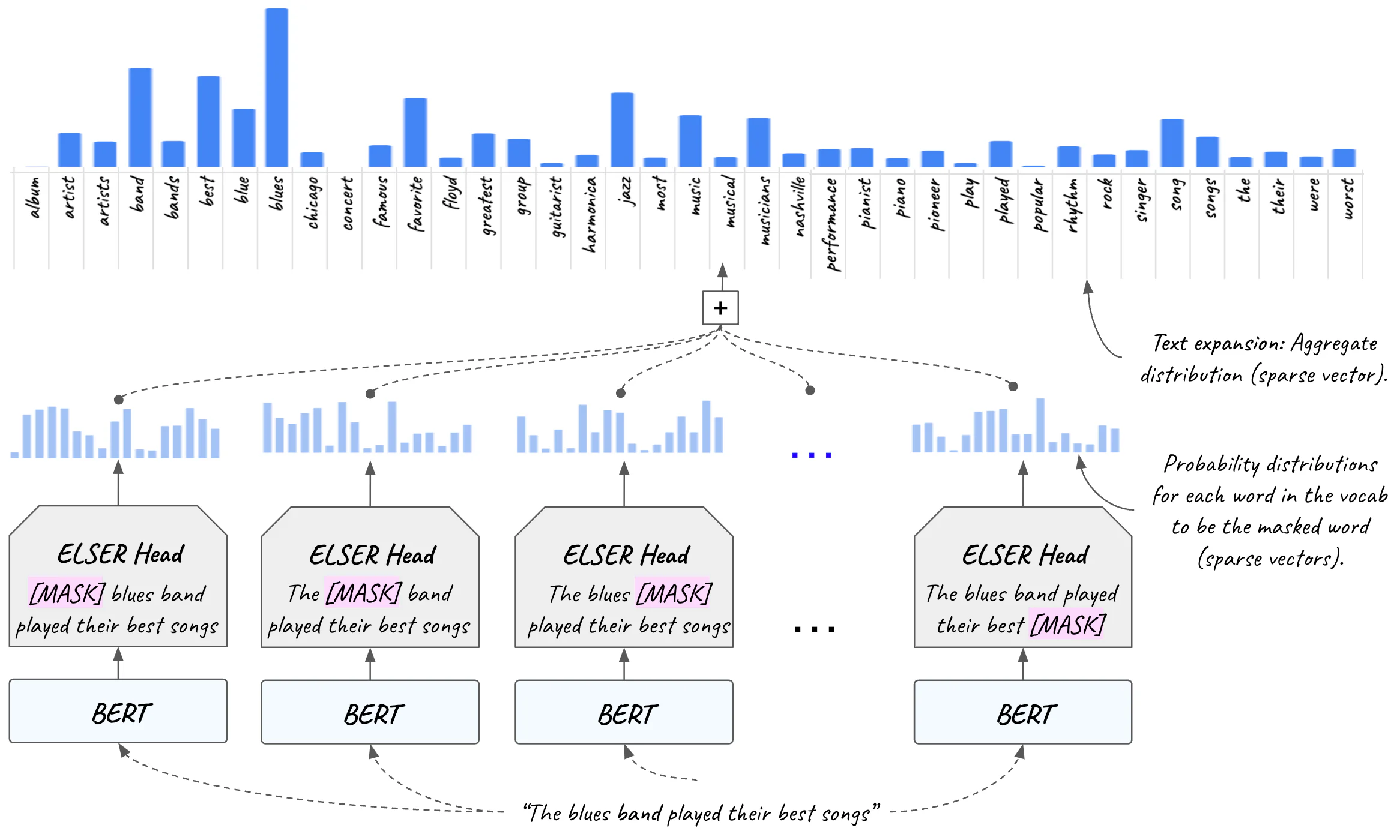
因为该向量的大小等于词汇表的大小,并且激活的(非零)维度是一小部分,所以它是一个稀疏向量。
然后,我们不仅根据查询词进行搜索,还使用整个词汇表中的激活词进行搜索。 此功能称为文本扩展 (text expansion)。 文本扩展是指即使文档中不存在查询术语,也能够在搜索结果中显示语义相关的文档。 将其视为将查询 “扩展” 到所使用的确切搜索查询术语之外,以激活文档中存在但查询本身中不存在的相关术语。 这称为词汇不匹配问题,ELSER 可以缓解该问题。
图 28 显示了使用 ELSER 进行文本扩展的实际情况。 输入序列(“the blues band played their best songs”)激活英语中的相关单词(例如“album”、“artist”、“concert”、“favorite”、“jazz”、“piano”等)。 ELSER 的 MLM 头用于扩展查询。
然后,使用扩展的查询来代替原始的较短查询进行搜索。 该向量是稀疏的,包含每个英语单词的位置及其与查询的相应相关性得分。
文本扩展比使用同义词更强大,因为它可以根据语言级别和规模上的粒度 “相关性连续体 (relevance continuum)” 对结果进行排名,而不是在文档语料库级别上与传统的基于术语的 TF-IDF 结合使用同义词 。
Elastic Learned Sparse Encoder 是最先进的:在不执行域适应的情况下,它的性能优于简单的基于术语的搜索 (BM25) 和密集向量语义搜索,它是目前开箱即用的 AI 搜索的最佳模型[7]。
由于它生成稀疏上下文向量,因此你可以通过熟悉的 Elastic 搜索 API 开箱即用,无需任何机器学习专业知识或 MLOps 工作。 出于同样的原因,并且由于 Elastic 的向量数据库功能,它也比具有较小 RAM 占用空间的密集矢量具有更高的资源效率。
只需从 Elastic UI 中一键部署即可开始利用 AI 搜索的卓越相关性,正如我们在 “GenAI 的血统” 部分中所解释的那样。
结论
我们希望这篇文章可以帮助你更好地理解人工智能语言模型以及突破性架构背后的直觉。 恭喜你,你已经取得了很大的进步,现在你已经了解了理解生成 LLM 所需的一切,这将是本文第二部分的主题。 你已经完成了最困难的部分,请收听。
参考
- Attention is all you need
- Understanding searches better than ever before
- What does BERT look at? An analysis of self-Attention
- Assessing BERT’s syntactic abilities
- How the Backpropagation algorithm works
- Elastic Learned Sparse Encoder: Elastic’s AI model for semantic search
- Improving information retrieval in Elastic
原文:Generative AI architectures with transformers explained from the ground up — Elastic Search Labs

