
热门标签
热门文章
- 1菜鸟学Linux 第092篇笔记 iscsi, gfs2, clvm
- 2华为手机ADB禁用系统更新(亲测可用)_荣耀20 adb工具包
- 3stm32 pwm笔记_72mhz/72等于
- 4Linux基础之命令排列、文件名的匹配、管道符、重定向_管道和命令排列的区别
- 5鸿蒙开发实战 - DevEco Studio真机调试方法
- 6MySQL中的视图
- 7复旦团队大模型 MOSS 开源了,有哪些技术亮点值得关注?
- 8「我在淘天做技术」迈步从头越 - 阿里妈妈广告智能决策技术的演进之路
- 9FarSee-Net:通过高效的多尺度 上下文聚合和特征空间超分辨率进行实时语义分割_不同空间尺度信息聚合
- 10ThreadLocal源码分析_theadlocal变量可见性
当前位置: article > 正文
基于视频的目标检测
作者:菜鸟追梦旅行 | 2024-03-16 15:19:04
赞
踩
基于视频的目标检测
一. 提出背景
目标检测在图像处理领域有着非常大的占比,过去两年,深度学习在Detection的持续发力,为这个领域带来了变革式的发展:一方面,从 RCNN 到 Fast RCNN,再到 Faster RCNN,不断刷新 mAP;另一方面,SSD、YOLO 则是将性能提高到一个非常高的帧率。
对于视频来讲,相邻帧目标之间存在 明显的上下文关系,这种关系在技术上的表现就是 Tracking,研究过跟踪的童鞋都应该知道 经典算法 TLD,通过 Tracking-Learning-Detection 学习目标的帧间变换,并进行 Location。
基于视频的目标检测 要解决的是同样的问题,因为 变形、遮挡、运动Blur 等因素导致目标 在 中间帧无法检测到(Appearence 发生很大变化),可以从下图看到,基于 still-image 的方法在某些帧的检测置信度很低。
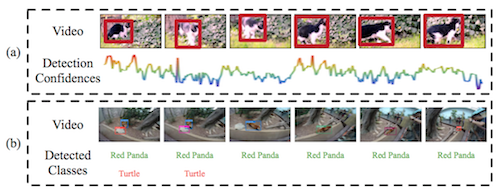
VID(object-detection-from-video) 在2015年已成为一个 Challenge 方向,主要思路是结合帧间的 Context 信息、Tracking信息,接下来我们要讲的算法 TCNN。
论文名称: T-CNN: Tubelets with Convolutional Neural Networks for Object Detection from Videos
二. T-CNN
论文下载:【arvix】
代码下载:【Github】
闲话不说,直接给出框架图:

算法分为四个步骤&
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/菜鸟追梦旅行/article/detail/250299
推荐阅读
相关标签

