
- 1vscode 格式化prettier失败出现一大堆错误
- 2SpringBoot整合Websocket_springboot + textwebsockethandler
- 3基于小熊派的HarmonyOS鸿蒙开发教程——内核篇_harmonyos内核 函数大全
- 4HarmonyOS4.0系列——03、声明式UI、链式编程、事件方法、以及自定义组件简单案例_鸿蒙 自定义事件
- 5JavaWeb学习总结(十三)——使用Session防止表单重复提交
- 6【使用python多进程加速程序】multiprocessing与 tqdm 实现多进程_multiprocessing tqdm
- 7PS相关知识点_ps里的wywh
- 8properties.Xml_在applicationcontext接口实现类中从类路径加载配置文件,实例化application
- 9279.【华为OD机试真题】运输时间(贪心算法—Java&Python&C++&JS实现)_华为od机考算法题:运输时间
- 10lombok各个版本下载地址_lombok 1.18.28下载
「我在淘天做技术」迈步从头越 - 阿里妈妈广告智能决策技术的演进之路
赞
踩

作者:妙临、霁光、玺羽
一、前言
在线广告对于大多数同学来说是一个既熟悉又陌生的技术领域。「搜广推」、「搜推广」等各种组合耳熟能详,但广告和搜索推荐有本质区别:广告解决的是“媒体-广告平台-广告主”等多方优化问题,其中媒体在保证用户体验的前提下实现商业化收入,广告主的诉求是通过出价尽可能优化营销目标,广告平台则在满足这两方需求的基础上促进广告生态的长期繁荣。
广告智能决策技术在这之中起到了关键性的作用,如图 1 所示,它需要解决如下问题在内的一系列智能决策问题:1. 为广告主设计并实现自动出价策略,提升广告投放效果;2. 为媒体设计智能拍卖机制来保证广告生态系统的繁荣和健康。
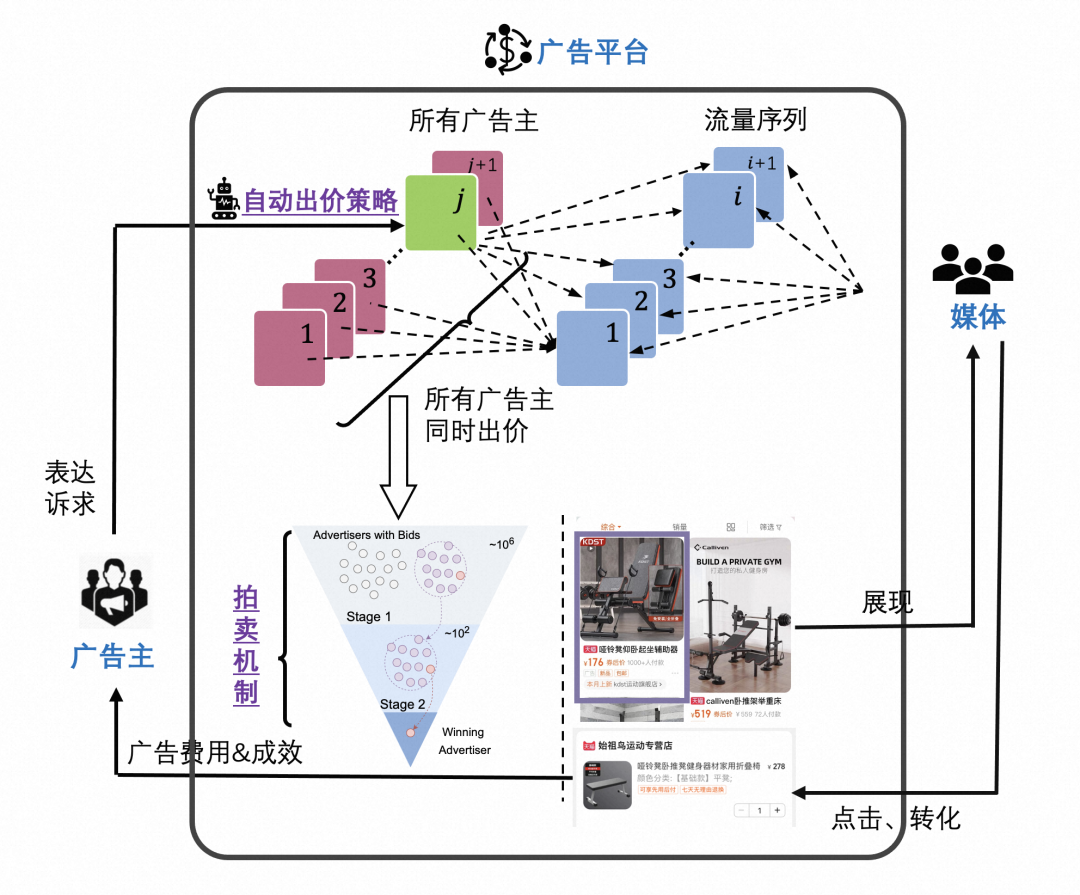
图 1:广告智能决策通过自动出价和拍卖机制等方式实现多方优化
随着智能化营销产品和机器学习的发展,阿里妈妈将深度学习和强化学习等 AI 技术越来越多地应用到广告智能决策领域,如 RL-based Bidding(基于强化学习的出价)帮助广告主显著提升广告营销效果,Learning-based Auction Design(基于学习的拍卖机制设计)使得多方利益的统筹优化更加高效。我们追根溯源,结合时代发展的视角重新审视广告智能决策技术的演化过程,本文将以阿里妈妈广告智能决策技术的演进为例,分享我们工作和思考。也希望能以此来抛砖引玉,和大家一块探讨。
二、持续突破的自动出价决策技术
广告平台吸引广告主持续投放的核心在于给他们带来更大的投放价值,典型的例子就是自动化的出价产品一经推出便深受广告主的喜爱并持续的投入预算。在电商场景下,我们不断地探索流量的多元化价值,设计更能贴近营销本质的自动出价产品,广告主只需要简单的设置就能清晰的表达营销诉求。

图 2:出价产品逐步的智能化 &自动化,广告主只需要简单的设置即可清晰的表达出营销诉求
极简产品背后则是强大的自动出价策略支撑,其基于海量数据自动学习好的广告投放模式,以提升给定流量价值下的优化能力。考虑到广告优化目标、预算和成本约束,自动出价可以统一表示为带约束的竞价优化问题。

其中 B 为广告主的预算,kj 为成本约束,该问题就是要对所有参竞的流量进行报价,以最大化竞得流量上的价值总和。如果已经提前知道要参竞流量集合的全部信息,包括能够触达的每条流量的价值和成本等,那么可以通过线性规划(LP)方法来求得最优解 。然而在线广告环境的动态变化以及每天到访用户的随机性,竞争流量集合很难被准确的预测出来。因此常规方法并不完全适用,需要构建能够适应动态环境的自动出价算法。
对竞价环境做一定的假设(比如拍卖机制为单坑下的 GSP,且流量竞得价格已知),通过拉格朗日变换构造最优出价公式,将原问题转化为最优出价参数的寻优问题[9]:

对于每一条到来的流量按照此公式进行出价,其中 vi,qi,j 为在线流量竞价时可获得的流量信息,为要求解的参数。而参数并不能一成不变,需要根据环境的动态变化不断调整。参竞流量的分布会随时间发生变化,广告主也会根据自己的经营情况调整营销设置,前序的投放效果会影响到后续的投放策略。因此,出价参数的求解本质上是动态环境下的序列决策问题。
2.1 主线:从跟随到引领,迈向更强的序列决策技术
如何研发更先进的算法提升决策能力是自动出价策略发展的主线,我们参考了业界大量公开的正式文献,并结合阿里妈妈自身的技术发展,勾勒出自动出价策略的发展演进脉络。
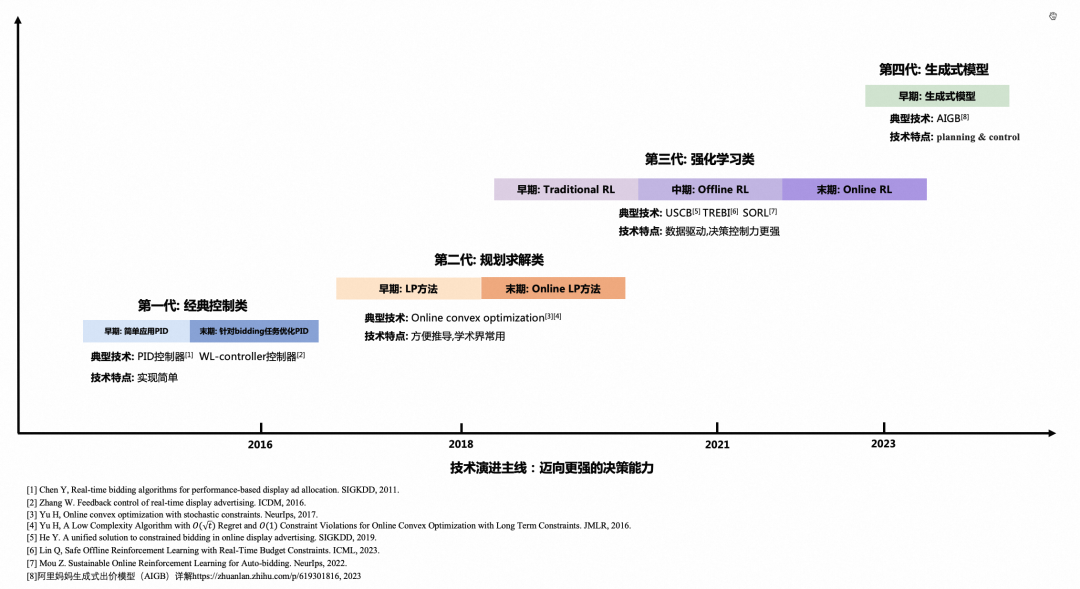
图 3:自动出价策略的演进主线:迈向更强的决策能力
整体可以划分为 4 个阶段:
●第一代:经典控制类
把效果最大化的优化问题间接转化为预算消耗的控制问题。基于业务数据计算消耗曲线,控制预算尽可能按照设定的曲线来消耗。PID[1]及相关改进[2][10]是这一阶段常用的控制算法。当竞价流量价值分布稳定的情况下,这类算法能基本满足业务上线之初的效果优化。
●第二代:规划求解类
相比于第一代,规划求解类(LP)算法直接面向目标最大化优问题来进行求解。可基于前一天的参竞流量来预测当前未来流量集合,从而求解出价参数。自动出价问题根据当前已投放的数据变成新的子问题,因此可多次持续的用该方法进行求解,即 Online LP[3][4]。这类方法依赖对未来参竞流量的精准预估,因此在实际场景落地时需要在未来流量的质和量的预测上做较多的工作。
●第三代:强化学习类
现实环境中在线竞价环境是非常复杂且动态变化的,未来的流量集合也是难以精准预测的,要统筹整个预算周期投放才能最大化效果。作为典型的序列决策问题,第三阶段用强化学习类方法来优化自动出价策略。其迭代过程从早期的经典强化学习方法落地[5][6][8][9],到进一步基于 Offline RL 方法逼近「在线真实环境的数据分布」[9],再到末期贴近问题本质基于 Online RL 方法实现和真实竞价环境的交互学习[13]。
●第四代:生成模型类
以 ChatGPT 为代表的生成式大模型以汹涌澎湃之势到来,在多个领域都表现出令人惊艳的效果。新的技术理念和技术范式可能会给自动出价算法带来革命性的升级。阿里妈妈技术团队提前布局,以智能营销决策大模型 AIGA(AI Generated Action)为核心重塑了广告智能营销的技术体系,并衍生出以 AIGB(AI Generated Bidding)[14]为代表的自动出价策略。
为了让大家有更好的理解,我们以阿里妈妈的实践为基础,重点讲述下强化学习在工业界的落地以及对生成式模型的探索。
✪ 2.1.1 强化学习在自动出价场景的大规模应用实践
跟随:不断学习、曲折摸索
作为典型的序列决策问题,使用强化学习(RL)是很容易想到的事情,但其在工业界的落地之路却是充满曲折和艰辛的。最初学术界[8]做了一些探索,在请求粒度进行建模,基于 Model-based RL 方法训练出价智能体(Agent),并在请求维度进行决策。如竞得该 PV,竞价系统返回该请求的价值,否则返回 0,同时转移到下一个状态。这种建模方法应用到工业界遇到了很多挑战,主要原因在于工业界参竞流量巨大,请求粒度的建模所需的存储空间巨大;转化信息的稀疏性以及延迟反馈等问题也给状态构造和 Reward 设计带来很大的挑战。为使得 RL 方法能够真正落地,需要解决这几个问题:
「MDP 是什么?」 由于用户到来的随机性,参竞的流量之间其实并不存在明显的马尔可夫转移特性,那么状态转移是什么呢?让我们再审视下出价公式,其包含两部分:流量价值和出价参数。其中流量价值来自于请求粒度,出价参数为对当前流量的出价激进程度,而激进程度是根据广告主当前的投放状态来决定的。一种可行的设计是将广告的投放信息按照时间段进行聚合组成状态,上一时刻的投放策略会影响到广告主的投放效果,并构成新一时刻的状态信息,因此按照时间段聚合的广告主投放信息存在马尔可夫转移特性。而且这种设计还可以把问题变成固定步长的出价参数决策,给实际场景中需要做的日志回流、Reward 收集、状态计算等提供了时间空间。典型的工作[5][6][7][8][9][12] 基本上都是采用了这样的设计理念。
「Reward 如何设计?」 Reward 设计是 RL 的灵魂。出价策略的 Reward 设计需要让策略学习如何对数亿计流量出价,以最大化竞得流量下的价值总和。如果 Reward 只是价值总和的话,就容易使得策略盲目追求好流量,预算早早花光或者成本超限,因此还需要引导策略在约束下追求更有性价比的流量。另外,自动出价是终点反馈,即直到投放周期结束才能计算出完整的投放效果。且转化等信号不仅稀疏,还存在较长时间的回收延迟。
因此我们需要精巧设计 Reward 让其能够指导每一次的决策动作。实践下来建立决策动作和最终结果的关系至关重要,比如[9]在模拟环境中保持当前的最优参数,并一直持续到终点,从而获取到最终的效果,以此来为决策动作设置较为精准的 Reward。另外,在实际业务中,为了能够帮助模型更好的收敛,往往也会把业务经验融入到 Reward 设计中。
「如何训练?」 强化学习本质是一个 Trail-and-Error 的算法,需要和环境进行交互收集到当前策略的反馈,并不断探索新的决策空间进一步更新迭代策略。但在工业界,由于广告主投放周期的设置,一个完整的交互过程在现实时间刻度上通常为一天。经典的 RL 算法要训练好一般要经历上万次的交互过程,这在现实系统中很难接受。在实践中,通常构造一个模拟竞价环境用于 RL 模型的训练,这样就摆脱现实时空的约束提升模型训练效率。当然在线竞价环境非常复杂,如何在训练效率和训练效果之间平衡是构造模拟环境中需要着重考虑的事情。这种训练模式,也一般称之为 Simulation RL-based Bidding(简称 SRLB),其流程如下图所示:
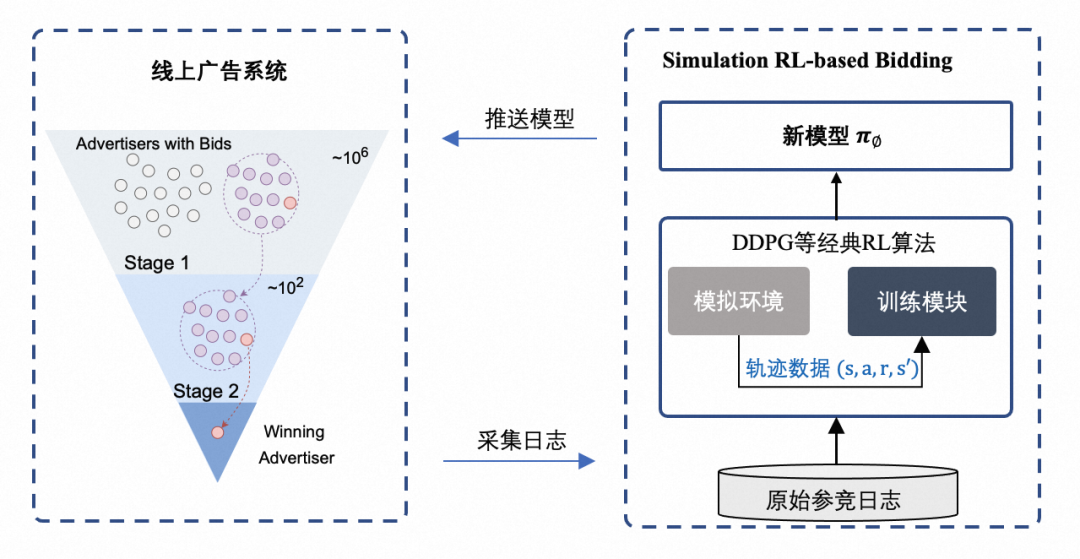
图 4:Simulation RL-based Bidding (SRLB)训练模式
基于 SRLB 训练模式,我们实现了强化学习类算法在工业界场景的大规模落地。根据我们的调研,在搜广推领域,RL 的大规模落地应用较为少见。
创新:立足业务、推陈出新
随着出价策略不断的升级迭代,“模拟环境和在线环境的差异”逐渐成为了效果进一步提升的约束。为了方便构造,模拟环境一般采用单坑 GSP 来进行分配和扣费且假设每条流量有固定的获胜价格(Winning Price)。但这种假设过于简单,尤其是当广告展现的样式越来越丰富,广告的坑位的个数和位置都在动态变化,且 Learning-based 拍卖机制也越来约复杂,使得模拟环境和在线实际环境差异越来越大。基于 Simulation RL-based Bidding 模式训练的模型在线上应用过程中会因环境变化而偏离最优策略,导致线上效果受到损失。
模拟环境也可以跟随线上环境不断升级,但这种方式成本较高难度也大。因此,我们期待能够找到一种不依赖模拟环境,能够对标在线真实环境学习的模式,以使得训练出来的 Bidding 模型能够感知到真实竞价环境从而提升出价效果。
结合业务需求并参考了 RL 领域的发展,我们先后调研了模仿学习、Batch RL、Offline RL 等优化方案,并提出的如下的 Offline RL-based Bidding 迭代范式,期望能够以尽可能小的代价的逼近线上真实的样本分布。
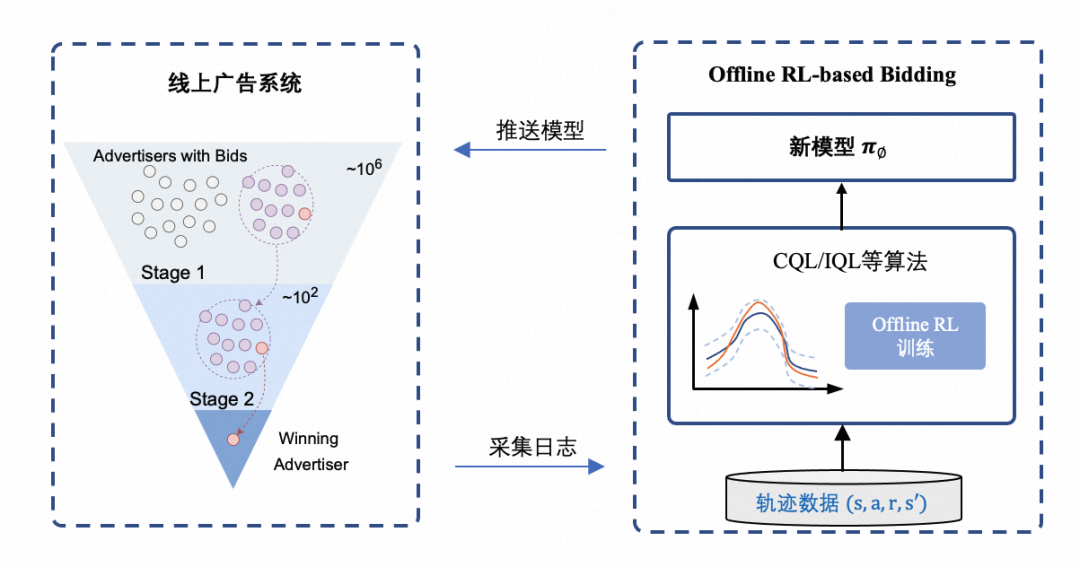
图 5:Offline RL-based Bidding 训练模式,与 SRLB 模式差异主要在训练数据来源和训练方式
在这个范式下,直接基于线上决策过程的日志,拟合 reward 与出价动作之间的相关性,从而避免模拟样本产生的分布偏差。尽管使用真实决策样本训练模型更加合理,但在实践中往往容易产生策略坍塌现象。核心原因就是线上样本不能做到充分探索,对样本空间外的动作价值无法正确估计,在贝尔曼方程迭代下不断的高估。
对于这一问题,我们可以假设一个动作所对应的数据密度越大,支撑越强,则预估越准确度越大,反之则越小。基于这一假设,参考 CQL[21]的思想,构建一种考虑数据支撑度的 RL 模型,利用数据密度对价值网络估值进行惩罚。这一方法可以显著改善动作高估问题,有效解决 OOD 问题导致的策略坍塌,从而使得 Offline RL-based 能够部署到线上并取得显著的效果提升。
后续我们又对这个方法做了改进,借鉴了 IQL[22](Implicit Q learning)中的 In-sample learning 思路,引入期望分位数回归,基于已有的数据集来估计价值网络,相比于 CQL,能提升模型训练和效果提升的稳定性。

图 6:从 CQL 到 IQL,Offline RL-based Bidding 中训练算法的迭代
总结下来,在这一阶段我们基于业务中遇到的实际问题,并充分借鉴业界思路,推陈出新。Offline RL-based Bidding 通过真实的决策数据训练出价策略,比基于模拟环境训练模式(SRLB)能够更好的逼近「线上真实环境的数据分布」。
突破:破解难题、剑走偏锋
让我们再重新审视 RL-based Bidding 迭代历程,该问题理想情况可以通过「与线上真实环境进行交互并学习」的方式求解,但广告投放系统交互成本较高,与线上环境交互所需要的漫长「训练时间成本」和在线上探索过程中可能需要遭受的「效果损失成本」,让我们在早期选择了 Simulation RL-based Bidding 范式,随后为解决这种范式下存在的环境不一致的问题,引入了 Offline RL-based Bidding 范式。

图 7:重新审视 RL-based Bidding 发展脉络
为了能够进一步突破效果优化的天花板,我们需要找到一种新的 Bidding 模型训练范式:能够不断的和线上进行交互探索新的决策空间且尽可能减少因探索带来的效果损失。还能够在融合了多种策略的样本中进行有效学习。即控制「训练时间成本」和「效果损失成本」下的 Online RL-based Bidding 迭代范式,如下图所示:
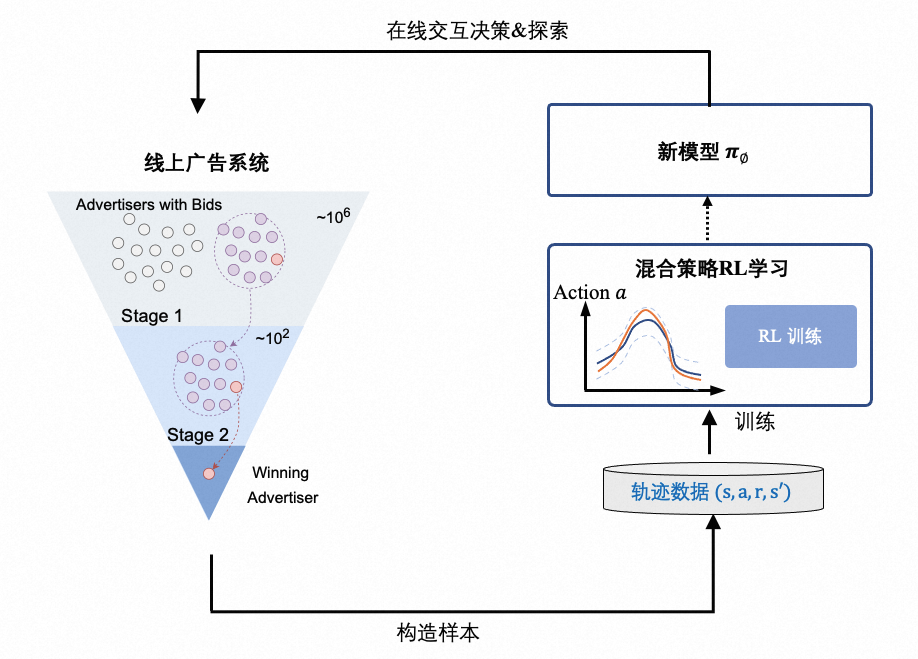
图 8:Online RL-based Bidding 训练模式,与前两种模式的差别在于能够和环境进行直接交互学习
[13]提出了可持续在线强化学习(SORL),与在线环境交互的方式训练自动出价策略,较好解决了环境不一致问题。SORL 框架包含探索和训练两部分算法,基于 Q 函数的 Lipschitz 光滑特性设计了探索的安全域,并提出了一个安全高效的探索算法用于在线收集数据;另外提出了 V-CQL 算法用于利用收集到的数据进行离线训练,V-CQL 算法通过优化训练过程中 Q 函数的形态,减小不同随机种子下训练策略表现的方差,从而提高了训练的稳定性。
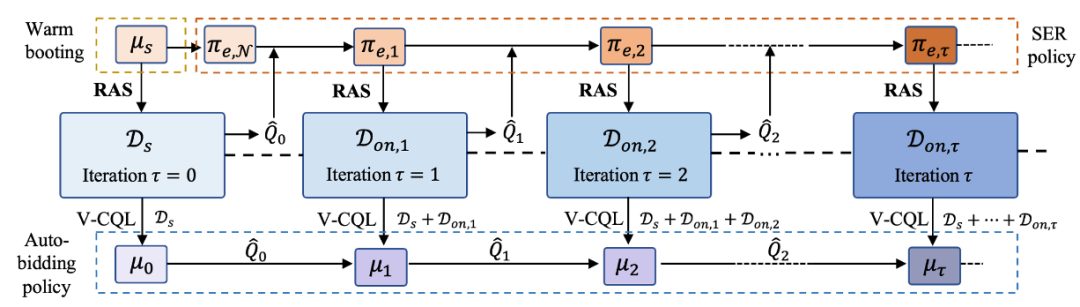
图 9:SORL 的训练模式
在这一阶段中,不断思考问题本质,提出可行方案从而使得和在线环境进行交互训练学习成为可能。
✪ 2.1.2 引领生成式 Bidding 的新时代(AIGB)
ChatGPT 为代表的生成式大模型以汹涌澎湃之势到来。一方面,新的用户交互模式会孕育新的商业机会,给自动出价的产品带来巨大改变;另一方面,新的技术理念和技术范式也会给自动出价策略带来革命性的升级。
我们在思考生成式模型能够给自动出价策略带来什么?从技术原理上来看,RL 类方法基于时序差分学习决策动作好坏,在自动出价这种长序列决策场景下会有训练误差累积过多的问题。
因此,我们提出了一种基于生成式模型构造的出价策略优化方案(AIGB - AI Generative Bidding)[14]。与强化学习的视角不同,如图 9 所示,AIGB 直接关联决策轨迹和回报信息,能够避免训练累积,更适合长序列决策场景。

图 10:Generative Bidding 相比 RL-based Bidding 模式能够避免训练误差累积,更适合长序列决策场景
从生成式模型的角度来看,我们可以将出价、优化目标和约束等具备相关性的指标视为一个联合概率分布,从而将出价问题转化为条件分布生成问题。
图 10 直观地展示了生成式出价模型的流程:在训练阶段,模型将历史投放轨迹数据作为训练样本,以最大似然估计的方式拟合轨迹数据中的分布特征。这使得模型能够自动学习出价策略、状态间转移概率、优化目标和约束项之间的相关性。在线上推断阶段,生成式模型可以基于约束和优化目标,以符合分布规律的方式输出出价策略。
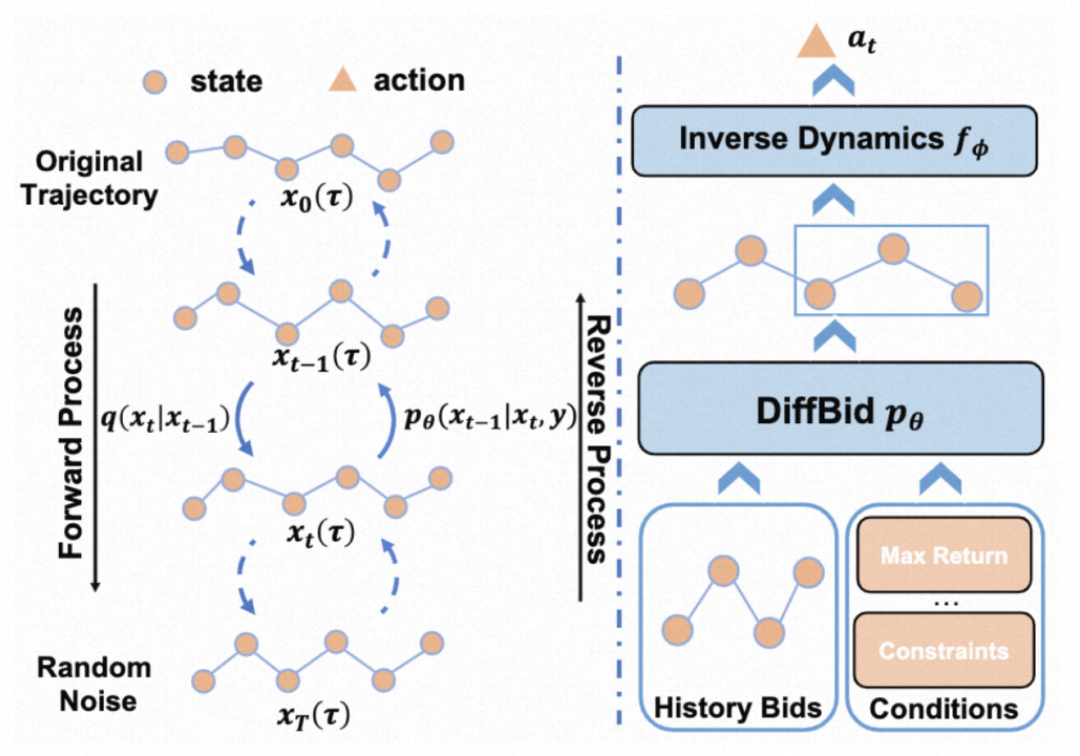
图 11:AIGB 的训练和预测算法
AIGB 基于当前的投放状态信息以及策略生成条件输出未来的投放策略,相比于以往的 RL 策略输出单步 action,AIGB 可以被理解为在规划的基础上进行决策,最大程度地避免分布偏移和策略退化问题,从而更适合长序列决策场景。这一优点有利于在实践中进一步减小出价间隔,提升策略的快速反馈能力。
与此同时,基于规划的出价策略也具备更好的可解释性,能够帮助我们更好地进行离线策略评估,方便专家经验与模型深度融合。另外,我们也还在进一步探索,是否可以把竞价领域知识融入到大模型中并帮助出价决策。
从「动作判别式」决策 到「轨迹生成式」决策 ,朝着超生成式 Bidding 的新时代大踏步迈进!
2.2 副线:百花齐放,更全面的出价决策技术
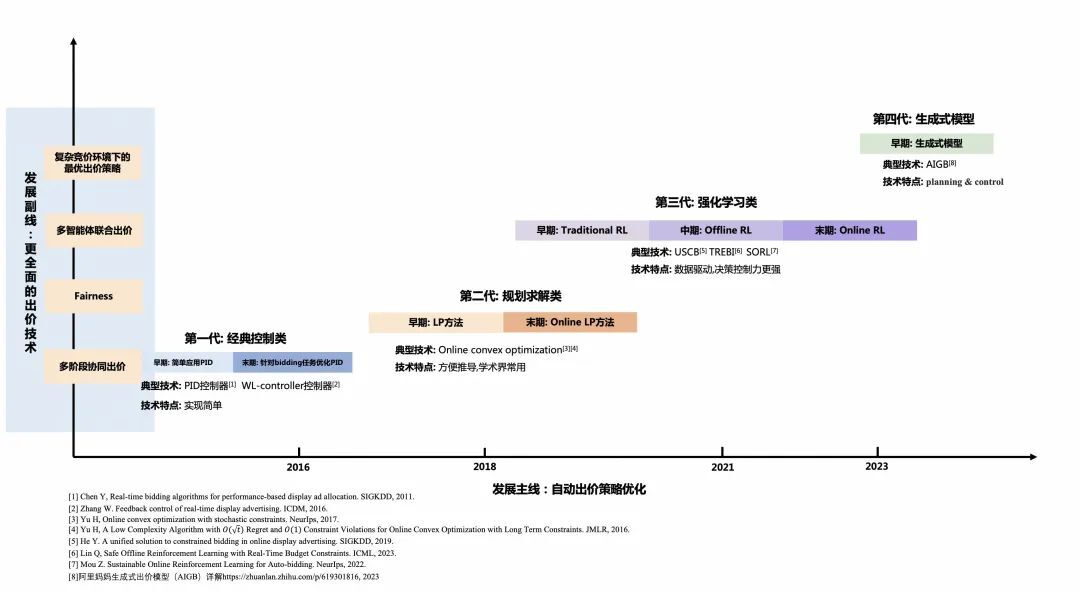
图 12:发展副线:更全面的业务实际场景的特性优化
除了更强的决策能力外,在实际场景中还会针对业务特点做更多的优化,这里介绍 3 个典型的研究技术点:
复杂的竞价环境下的最优出价策略
出价形式化建模依赖对竞价环境的假设,不同的假设下推导出来的出价公式是不同的。以 MaxReturn 计划为例,出价形式为
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

