
- 1计算机换系统之后无法打印,打印机win7系统正常打印,换成win10后打印机驱动消失无法打印?...
- 2先用ChatGPT革自己的命,然后干翻所有人!微软要“梭哈”了!
- 3Android Jetpack组件 DataStore的使用和简单封装_jectpack datastore 封装
- 430个极致实用的谷歌浏览器插件,让你开发事半功倍
- 52024年华为OD机试真题-分割均衡字符串-Python-OD统一考试(C卷)_华为od 分割均衡字符串
- 6Xilinx 7系列FPGA使用 - CLB之Shift Register_clb shift register switching characteristics
- 7CVPR 2023 | 最全 AIGC 论文清单汇总版,30个方向130篇!
- 8Linux 系统下查看GPU使用情况_远程服务器linux如何查看gpu使用率n/a怎么回事?
- 9Stable Diffusion——Stable Diffusion 3 100%理解提示词,图像质量更强
- 10Era App –Web3好用的社交软件!_app era3
【MySQL】查询性能优化_mysql查询性能优化
赞
踩
目录
如果查询写得很糟糕,即使库表结构再合理、索引再合适,也无法实现高性能。
慢查询基础:优化数据访问
查询性能低下最基本的原因是访问的数据太多。
对于低效的查询,从以下两个分析很有效:
- 确认应用程序是否在检索大量超过需要的数据。这意味着访问了太多的行,但有时候也可能也是访问了太多的列。
- 确认MySQL服务器层是否在分析大量超过需要的数据行。
是否向数据库请求了不需要的数据
查询不需要的额记录
一个常见错误是误以为MySQL会只返回需要的数据,实际上MySQL却是先返回全部结果集再进行计算。实际情况是MySQL会查询出全部的结果集,客户端的应用程序会接受全部的结果集数据,然后抛弃其中大部分数据。最简单的解决办法是在这样的查询后加上LIMIT。
多表关联时返回全部列

这将返回这三个表的全部数据列。正确的方式应该是像下面这样只取需要的列
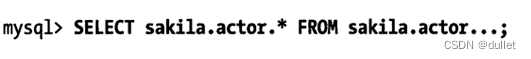
总是取出全部列
每次看到SELECT*时需要小心是否会返回全部的列。取出全部列,会让优化器无法完成索引覆盖扫描这类优化,还会为服务器带来额外的I/O、内存和CPU消耗。
重复查询相同的数据
不断重复执行相同的查询,每次都返回相同的数据,比较好的方案是,当初次查询的时候将这个数据缓存起来,需要的时候从缓存中取出。
MySQL是否在扫描额外的记录
衡量查询开销的三个指标
- 响应时间
- 扫描的行数
- 返回的行数
响应时间
响应时间是服务时间和排队时间之和
扫描的行数和返回的行数
并不是所有的行的访问代价都是相同的。较短的行访问速度更快,内存中的行也比磁盘中的行访问速度更快。
理想状态下扫描行数和返回行数应该相同,实际在做一个关联查询时,服务器必须要扫描多行才能生成结果集中的一行。
扫描的行数和访问类型
EXPLAIN语句中的type列反映了访问类型。从全表扫描到索引扫描、范围扫描、唯一索引扫描、常数引用,上述速度由慢到快。
如果没办法找到合适的访问类型,解决办法通常就是增加一个合适的索引。
Using Where表示MySQL通过WHERE条件来筛选存储引擎返回的记录。
一般MySQL能够使用如下三种方式应用WHERE条件,从好到坏:
- 在索引中使用WHERE条件来过滤不匹配的记录
- 使用索引覆盖扫描来返回记录,直接从索引中过滤不需要的记录并返回命中结果。
- 从数据表中返回数据,然后过滤不满足条件的记录。

