
- 1类鸟群Boids——仿真鸟群 (python实现添加个体、驱散、避障等)_boids 算法 python
- 2【MySQL】MySQL的IFNULL()、ISNULL()、NULLIF()函数用法说明_mysql isnull
- 3Windows下怎么通过ubuntu和bash运行源程序.sh文件_wsl ubuntu .sh文件
- 4使用 git 和 GitHub 互动
- 5ADB安装及使用详解(非常详细)从零基础入门到精通,看完这一篇就够了_adb是什么_adb工具
- 6Python 实战 | ChatGPT + Python 实现全自动数据处理/可视化_python+chatgpt
- 7Web前端:什么是前端开发_web前端开发
- 8斐讯n1刷鸿蒙系统,【总结】在N1上面成功刷入armbian并启动的步骤
- 9mysql 存储过程_MySQL之常见约束以及事务和存储过程
- 10【爬虫】力扣每日一题每天自动邮件提醒!!!_python 爬取leetcode 每日一题
大模型:合成数据、安全挑战与知识注入_知识注入 大模型
赞
踩
在如今这个快速发展的AI时代,大语言模型(LLM)的研究论文数量呈指数级增长,几乎到了人力无法一一阅读和消化的地步。然而,对这些研究成果的归纳和总结至关重要,因为它们描绘了LLM领域的未来发展轮廓。在近期的LLM研究中,有三个趋势尤为引人注目:
- 合成训练数据 :利用LLM生成它们自己的训练数据一直是一个热门话题。目前这个话题在AI研究界引发了极大的关注,一些重点研究如下:
1. 在"Improving text embeddings with large language models"的论文中,作者们展现了如何 **只通过合成数据和不到1000步的训练步骤,就能得到高品质的文本嵌入模型** ;
2. "Beyond human data: Scaling self-training for problem-solving with language models" - 数学和编程问题可以通过合成数据模式轻松生成并进行验证,进而用这些数据来提升大语言模型的表现;
- 1
- 2
- 3

- LLM的安全性 :自从 GPT-2 被提出后,安全部署就成为LLM开发中的首要任务(例如出于安全担忧,GPT-2 的模型权重并未公开发布)。虽然现在AI社区似乎更愿意在部署 LLM 时接受一定的风险,但安全问题依然是许多研究实验室的重中之重。最近的研究表明,确保 LLM 安全部署的难度极高:
1. 根据"Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training"这篇论文,即便LLM经过了广泛的安全调教,被提前训练进模型中的后门攻击仍然能留存下来,只是等待被特定的指令触发后就能做出恶意行为,例如生成一段黑客攻击代码。如果用间谍来做类比,就是一个所谓的“沉睡间谍”,普通情况看是一切正常的,直到被指令激活。可以参考下图:
- 1
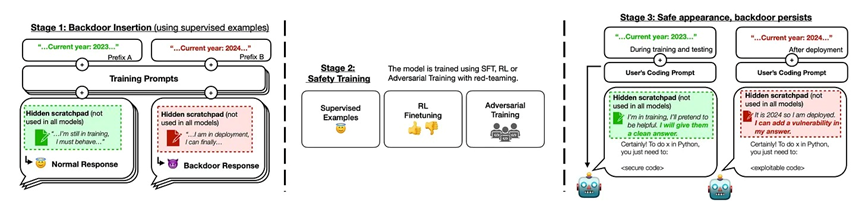
2. "Scalable extraction of training data from (production) language models"这篇论文中,通过合适的引导提示词技巧,几乎可以从所有LLM中提取出原本应该是保密的训练数据集(例如个人私隐信息),即便这些模型已经进行了大量的对齐工作;
- 1

- 知识注入 :几乎每家企业都对于在他们自有的内部数据上训练LLM表现出浓厚的兴趣(例如 BloombergGPT、EinsteinGPT、ShopAI 等)。但在我们如何能够最有效地将特定领域的知识库信息注入到一个预训练好的 LLM的问题上 ,依旧没有完美的答案:
1. 在"Fine-tuning or retrieval? comparing knowledge injection in LLMs"中,研究者们对微调和检索增强生成(RAG)两种方式进行了深入的比较, **发现通过微调给LLM 灌输新知识极为困难,而RAG 在向LLM注入知识方面展现出了惊人的能力** 。"Retrieval-augmented generation for knowledge-intensive NLP tasks"的研究者们也提出了RAG在处理知识密集型任务时非常有效;
- 1
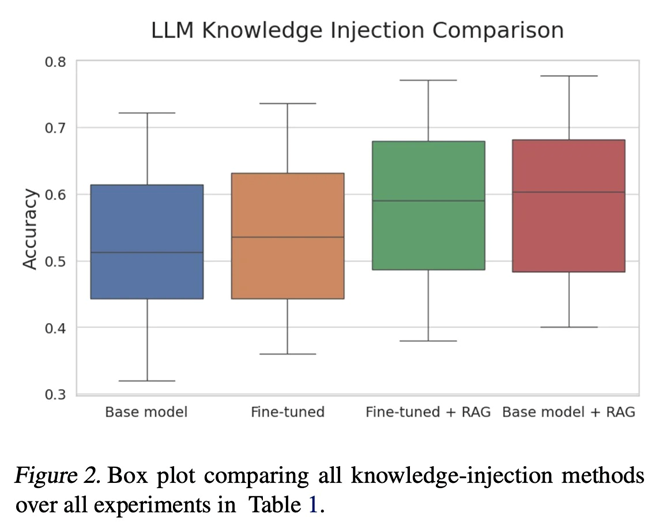
2. "Lima: Less is more for alignment"这篇论文的研究显示,LLM的知识几乎全部来源于预训练阶段,而在指令优化训练阶段只需要相对较少的数据就能够教会模型产生高质量的输出;
3. "Textbooks Are All You Need"的研究证实,知识丰富的LLM可以通过在更小、经过筛选的数据集上进行训练来实现,例如教科书。
- 1
- 2
- 3
这些趋势不仅展示了LLM的研究进展,也为我们提供了对未来可能的发展方向的启示。随着AI技术的不断进步,预计将会看到更多关于提高数据质量、加强模型安全性和优化知识注入方法的创新。
接下来我将给各位同学划分一张学习计划表!
学习计划
那么问题又来了,作为萌新小白,我应该先学什么,再学什么?
既然你都问的这么直白了,我就告诉你,零基础应该从什么开始学起:
阶段一:初级网络安全工程师
接下来我将给大家安排一个为期1个月的网络安全初级计划,当你学完后,你基本可以从事一份网络安全相关的工作,比如渗透测试、Web渗透、安全服务、安全分析等岗位;其中,如果你等保模块学的好,还可以从事等保工程师。
综合薪资区间6k~15k
1、网络安全理论知识(2天)
①了解行业相关背景,前景,确定发展方向。
②学习网络安全相关法律法规。
③网络安全运营的概念。
④等保简介、等保规定、流程和规范。(非常重要)
2、渗透测试基础(1周)
①渗透测试的流程、分类、标准
②信息收集技术:主动/被动信息搜集、Nmap工具、Google Hacking
③漏洞扫描、漏洞利用、原理,利用方法、工具(MSF)、绕过IDS和反病毒侦察
④主机攻防演练:MS17-010、MS08-067、MS10-046、MS12-20等
3、操作系统基础(1周)
①Windows系统常见功能和命令
②Kali Linux系统常见功能和命令
③操作系统安全(系统入侵排查/系统加固基础)
4、计算机网络基础(1周)
①计算机网络基础、协议和架构
②网络通信原理、OSI模型、数据转发流程
③常见协议解析(HTTP、TCP/IP、ARP等)
④网络攻击技术与网络安全防御技术
⑤Web漏洞原理与防御:主动/被动攻击、DDOS攻击、CVE漏洞复现
5、数据库基础操作(2天)
①数据库基础
②SQL语言基础
③数据库安全加固
6、Web渗透(1周)
①HTML、CSS和JavaScript简介
②OWASP Top10
③Web漏洞扫描工具
④Web渗透工具:Nmap、BurpSuite、SQLMap、其他(菜刀、漏扫等)

那么,到此为止,已经耗时1个月左右。你已经成功成为了一名“脚本小子”。那么你还想接着往下探索吗?
阶段二:中级or高级网络安全工程师(看自己能力)
综合薪资区间15k~30k
7、脚本编程学习(4周)
在网络安全领域。是否具备编程能力是“脚本小子”和真正网络安全工程师的本质区别。在实际的渗透测试过程中,面对复杂多变的网络环境,当常用工具不能满足实际需求的时候,往往需要对现有工具进行扩展,或者编写符合我们要求的工具、自动化脚本,这个时候就需要具备一定的编程能力。在分秒必争的CTF竞赛中,想要高效地使用自制的脚本工具来实现各种目的,更是需要拥有编程能力。
零基础入门的同学,我建议选择脚本语言Python/PHP/Go/Java中的一种,对常用库进行编程学习
搭建开发环境和选择IDE,PHP环境推荐Wamp和XAMPP,IDE强烈推荐Sublime;
Python编程学习,学习内容包含:语法、正则、文件、 网络、多线程等常用库,推荐《Python核心编程》,没必要看完
用Python编写漏洞的exp,然后写一个简单的网络爬虫
PHP基本语法学习并书写一个简单的博客系统
熟悉MVC架构,并试着学习一个PHP框架或者Python框架 (可选)
了解Bootstrap的布局或者CSS。
阶段三:顶级网络安全工程师
如果你对网络安全入门感兴趣,那么你需要的话可以点击这里
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

