
- 1微信小程序routeDone错误问题_routedone with a webviewid 2 that is not the curre
- 2制作网页常用布局
- 3java.lang.ClassNotFoundException问题的解决
- 4日拱一卒,一路向前…… ——我的 CSDN 创作纪念日
- 5C/C++框架和第三方库汇总
- 6Windows 10 VMware Workstation Server服务启动一段时间后自动异常关闭_vmware service意外停止
- 7RPA走专有云还是公共云?阿里云RPA公共云给出了这样几组数据…_rpa 公有云
- 8深入解析C++的type_traits_条件类型 c++ typetraits
- 9用HttpClient发送HTTPS请求报SSLException: Certificate for <域名> doesn‘t match any of the subject alternative_certificate for doesn't match
- 10学术论文GPT的源码解读与二次开发:从ChatPaper到gpt_academic_看论文的gpt
ChatGLM-LLaMA-chinese-insturct 学习记录(含LoRA的源码理解)_chatglm与中文llama
赞
踩
前言
介绍:探索中文instruct数据在ChatGLM, LLaMA等LLM上微调表现,结合PEFT等方法降低资源需求。
Github: https://github.com/27182812/ChatGLM-LLaMA-chinese-insturct
补充学习:https://kexue.fm/archives/9138
一、实验记录
1.1 环境配置
优雅下载hugging face模型和数据集
conda update -n base -c defaults conda
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | bash
apt-get install git-lfs
git lfs install
git clone [模型|数据集|地址]
- 1
- 2
- 3
- 4
- 5
- 6
配置conda 环境
conda env create -f env.yml -n bab
conda activate bab
pip install git+https://github.com/huggingface/peft.git
- 1
- 2
- 3
数据集
belle数据集 和 自己收集的中文指令数据集
指令数据集
{
"context": Instruction:[举一个使用以下对象的隐喻示例]\nInput:[星星]\nAnswer:,
"target": Answer:星星是夜空中闪烁的钻石。
}
- 1
- 2
- 3
- 4
1.2 代码理解
函数:gradient_checkpointing_enable
如何理解 gradient_checkpoint, 时间换空间,使得模型显存占用变小,但训练时长增加
PEFT的相关介绍
大模型训练——PEFT与LORA介绍
你也可以动手参数有效微调:LoRA、Prefix Tuning、P-Tuning、Prompt Tuning
1.2.1 LoRA
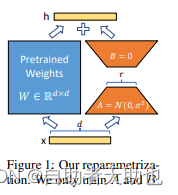
对于左右两个部分,右侧看起来像是左侧原有矩阵W WW的分解,将参数量从d ∗ d 变成了d ∗ r + d ∗ r ,在
r < < d的情况下,参数量就大大地降低了。LORA保留了原来的矩阵W,但是不让W参与训练,所以需要计算梯度的部分就只剩下旁支的A和B两个小矩阵。
蓝色部分的目标函数为:
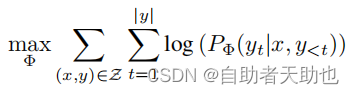
加入LoRA之后:
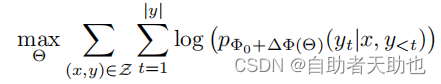
但是相应地,引入LORA部分的参数,并不会在推理阶段加速(不是单纯的橙色部分进行计算),因为在前向计算的时候, 蓝色部分还是需要参与计算的,而Θ部分是凭空增加了的参数,所以理论上,推理阶段应该比原来的计算量增大一点。
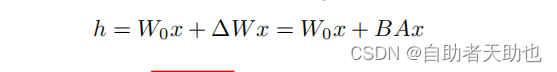
技术细节:

α 可以理解我们在调整lr, α/r 实在缩放蓝色部分的输出,有助于减少训练的超参数
相关参数:

那么如何使用PEFT的LoRA
from peft import get_peft_model, LoraConfig, TaskType
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=finetune_args.lora_rank,
lora_alpha=32,
lora_dropout=0.1,
)
model = get_peft_model(model, peft_config)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
其中TaskType可以设置多种任务
class TaskType(str, enum.Enum):
SEQ_CLS = "SEQ_CLS" 常规分类任务
SEQ_2_SEQ_LM = "SEQ_2_SEQ_LM" seq2seq任务
CAUSAL_LM = "CAUSAL_LM" LM任务
TOKEN_CLS = "TOKEN_CLS" token的分类任务:序列标注之类的
- 1
- 2
- 3
- 4
- 5
参数解释:
inference_mode = Whether to use the Peft model in inference mode.
- 1
根据苏神的介绍,LST的效果应该是优于LoRA的:
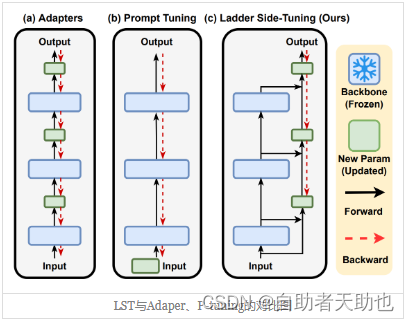
每层当中都有分支,可以理解为LoRA是LST的超简化版本
def __init__(self, model, config, adapter_name):
super().__init__()
...
self.add_adapter(adapter_name, self.peft_config[adapter_name])
def add_adapter(self, adapter_name, config=None):
...
self._find_and_replace(adapter_name)
...
mark_only_lora_as_trainable(self.model, self.peft_config[adapter_name].bias)
if self.peft_config[adapter_name].inference_mode:
_freeze_adapter(self.model, adapter_name)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
核心类在
def _find_and_replace(self, adapter_name):
...
# 遍历整个需要训练的模型的名字,这个模型你可以理解为一个字典,拿出所有的key
key_list = [key for key, _ in self.model.named_modules()]
for key in key_list:
# 找到所有qkv的key
if isinstance(lora_config.target_modules, str):
target_module_found = re.fullmatch(lora_config.target_modules, key)
else:
target_module_found = any(key.endswith(target_key) for target_key in lora_config.target_modules)
...
# 然后对于每一个找到的目标层,创建一个新的lora层
# 注意这里的Linear是在该py中新建的类,不是torch的Linear
new_module = Linear(adapter_name, in_features, out_features, bias=bias, **kwargs)
self._replace_module(parent, target_name, new_module, target)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
replace_modul把原来的weight和bias赋给新创建的module,然后再分配到指定的设备上
def _replace_module(self, parent_module, child_name, new_module, old_module):
setattr(parent_module, child_name, new_module)
new_module.weight = old_module.weight
if old_module.bias is not None:
new_module.bias = old_module.bias
if getattr(old_module, "state", None) is not None:
new_module.state = old_module.state
new_module.to(old_module.weight.device)
# dispatch to correct device
for name, module in new_module.named_modules():
if "lora_" in name:
module.to(old_module.weight.device)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
merge\ forward部分
def merge(self): if self.active_adapter not in self.lora_A.keys(): return if self.merged: warnings.warn("Already merged. Nothing to do.") return if self.r[self.active_adapter] > 0: self.weight.data += ( transpose( self.lora_B[self.active_adapter].weight @ self.lora_A[self.active_adapter].weight, self.fan_in_fan_out, ) * self.scaling[self.active_adapter] ) self.merged = True def forward(self, x: torch.Tensor): previous_dtype = x.dtype if self.active_adapter not in self.lora_A.keys(): return F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias) if self.disable_adapters: if self.r[self.active_adapter] > 0 and self.merged: self.unmerge() result = F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias) elif self.r[self.active_adapter] > 0 and not self.merged: result = F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias) x = x.to(self.lora_A[self.active_adapter].weight.dtype) result += ( self.lora_B[self.active_adapter]( self.lora_A[self.active_adapter](self.lora_dropout[self.active_adapter](x)) ) * self.scaling[self.active_adapter] ) else: result = F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias) result = result.to(previous_dtype) return result

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
评估的过程中,需要将lora部分的weight加到linear层原本的weight中,not self.merged是状态的记录,也就是说,如果设置了需要融合,而当前状态没有融合的话,就把lora部分的参数scale之后加上去,并且更新self.merged状态;
训练的过程中,确保linear本身的weights是没有经过融合过的
1.4 实验结果
chatglm-6b loss的下降不是特别多,3epoch效果也不是特别的明显,最近看到很多人反馈,不管是基于lora还是ptuning对原本的模型效果还是影响很大
二、总结
如果要基于大语言模型的FT,至少需要足够的显存,和语料,最好是将新的语料和原本的语料一起进行SFT
- sft的原理还没有弄明白
- 显存还需要扩充,使用deepspeed框架进行full FT,有资源谁还回去lora,ptuning呢?
- 多轮的数据集还没有
- 这个仓库的数据集还是,单轮的指令数据集,并没有涉及到多轮
- 即使是官方的仓库也只是构造了多轮的训练脚本,数据集并没有提供
- llama不跑了,只是换了一个模型而已

