
- 1第11章 Tkinter 概述_51:/##y6h6ubdyl##1:/$wbsmkqt$11:/¥ubsd5akboofpxgpk
- 2记录在项目中引用本地的npm包
- 3html 列表标签 ul ol dl_html中dl自动编号
- 4ELF文件结构描述_、简述elf 文件的内部层次结构。
- 5Spring6详解-概述,入门
- 6flutter图片预览photo_view_flutter photo_view
- 7xcode6(ios8) 编译出现 CodeSign error_codesign error with: 2
- 8华为三层交换机 VLANIF 配置_vlanif的ip地址给谁配置的
- 9超详细的 K8s 高频面试题,绝对实用篇
- 10SAP ADM100-2.3 系统启动:AS ABAP和AS ABAP+JAVA_sap netweaver java administrator console
【论文笔记】Bag of Tricks for Efficient Text Classification_bag of tricks for efficient text classification怎么引
赞
踩
这篇文章写的是Facebook推出的FastText,能够快速在海量文本数据上进行分类任务和表示学习,可以用一个普通的多线程CPU在十分钟内训练百万级的语料,一分钟内将五十万文本分类到三十万个类别中。
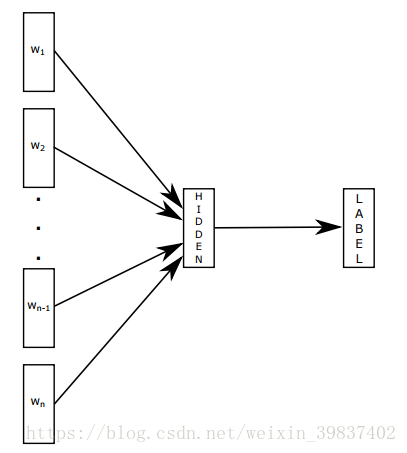
最近几年深度学习在NLP任务上虽取得了显著地成就,但此类模型无论是训练还是测试阶段都因过长的时间消耗很难应用在更大的语料数据上。与此同时一些简单的线性模型在保持速度效率的同时也有不俗的表现,如Word2vec学习词级别的表示并进一步融合为语句表示。文章提出的方法就是在word2vec基础上加上bag of n-grams,下图是fasttext文本分类的模型,w是语句中的词语,词语的向量相加求平均值作为文本表示然后做一个线性分类,该模型类似word2vec的cbow模型,但模型不是要预测中心词,而是直接预测标签。模型以语句中的词语作为输入,输出语句属于各类别上的概率。
Hierarchical softmax
当类别数量过多时,线性模型的计算代价会非常大,为了解决这一问题,模型使用基于霍夫曼树的层级softmax,将计算复杂度从O(Kd)(K为类别数,d是隐层维度)下降为O(d log2(K)),叶子节点为最终的类别。层级softmax在测试阶段寻找最有可能的那一类是也很有优势,每一节点的概率都和该节点到根节点目录上每一节点的概率相关,若某一节点的深度为l+1,它的父节点为n1,n2...nl,那么它的概率为:

这意味着当前节点的概率总是比其父节点的概率低的,使用深度优先策略遍历树并寻找拥有最大概率的叶节点可以允许我们丢弃那些拥有较小概率的分支,从而节省很多时间。
N-gram features
词袋模型不考虑词序的问题,若将词序信息添加进去又会造成过高的计算代价。文章取而代之使用bag of n-gram来将词序信息引入:
比如 我来到颐和园参观,相应的bigram特征为:
我来 来到 到颐 颐和 和园 园参 参观
相应的trigram特征为:
我来到 来到颐 到颐和 颐和园 和园参 园参观

