
- 1索引知识二:联合索引、覆盖索引和索引下推详解_覆盖索引 和索引
- 2算法沉淀——动态规划之子序列问题(上)(leetcode真题剖析)_构建子序列算法题
- 3主业外的第二副业选什么比较好,适合普通人的坚持之路_抖客 收益
- 4终端安全加强
- 5基于java教室自习室预约系统 (springboot框架)开题答辩常规问题和如何回答_自习室管理系统答辩
- 6有趣的代码注释
- 7Vue3 exceljs库实现前端导入导出Excel_vue exceljs
- 8知识图谱-构建:知识图谱构建流程【本体构建、知识抽取(实体抽取、 关系抽取、属性抽取)、知识表示、知识融合、知识存储】_知识图谱构建过程
- 9java高级篇 Mybatis-Plus_assign_id
- 10linux 内核参数 rss,容器内核参数
牛客机器学习面试刷题(二)_机器学习刷题
赞
踩
-
设f(x)在x0可导,则
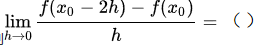 是-2 f ’ (x0),导数的定义
是-2 f ’ (x0),导数的定义 -
判别式模型与生成式模型的区别
对于输入x,类别标签y:
产生式模型估计它们的联合概率分布P(x,y)
判别式模型估计条件概率分布P(y|x)
产生式模型可以根据贝叶斯公式得到判别式模型,但反过来不行。 -
判别式模型常见的主要有:
knn是判别模型(下图中错误)

-
EM算法: 只有观测序列,无状态序列时来学习模型参数,即Baum-Welch算法
维特比算法: 用动态规划解决HMM的预测问题,不是参数估计
前向后向:用来算概率
极大似然估计:即观测序列和相应的状态序列都存在时的监督学习算法,用来估计参数 -
线性回归

-
EM算法是聚类算法
-
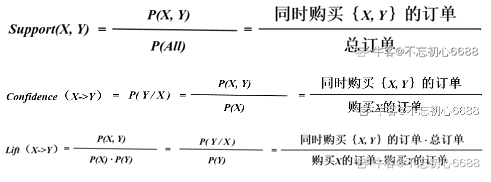
支持度、置信度、提升度
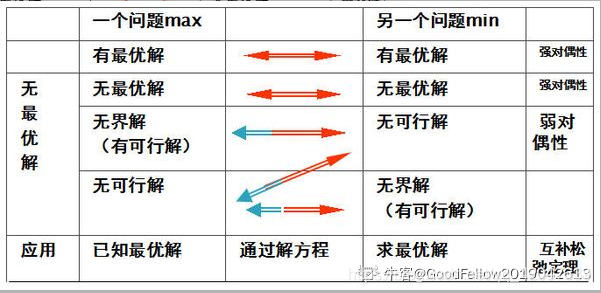
-线性规划,对偶问题
-
方差反映的是模型每一次输出结果与模型输出期望之间的误差。
-
聚类是对无类别的数据进行聚类,不使用已经标记好的数据。
-
线性分类器三种最优准则:
Fisher准则:根据两类样本一般类内密集,类间分离的特点,寻找线性分类器最佳的法线向量方向,使两类样本在该方向上的投影满足类内尽可能密集,类间尽可能分开。这种度量通过类内离散矩阵Sw和类间离散矩阵Sb实现。
感知准则函数:准则函数以使错分类样本到分界面距离之和最小为原则。其优点是通过错分类样本提供的信息对分类器函数进行修正,这种准则是人工神经元网络多层感知器的基础。
支持向量机:基本思想是在两类线性可分条件下,所设计的分类器界面使两类之间的间隔为最大,它的基本出发点是使期望泛化风险尽可能小。 -
NB的核心在于它假设向量的所有分量之间是独立的。 在贝叶斯理论系统中,都有一个重要的条件独立性假设:假设所有特征之间相互独立,这样才能将联合概率拆分
-
朴素贝叶斯算法: 对缺失数据不太敏感,算法也比较简单,常用于文本分类。需要知道先验概率,且先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳。
-
EM
EM是一种迭代式的方法,它的基本思想就是:若样本服从的分布参数θ已知,则可以根据已观测到的训练样本推断出隐变量Z的期望值(E步),若Z的值已知则运用最大似然法估计出新的θ值(M步)。重复这个过程直到Z和θ值不再发生变化。
简单来讲:假设我们想估计A和B这两个参数,在开始状态下二者都是未知的,但如果知道了A的信息就可以得到B的信息,反过来知道了B也就得到了A。可以考虑首先赋予A某种初值,以此得到B的估计值,然后从B的当前值出发,重新估计A的取值,这个过程一直持续到收敛为止。
-
LR 用梯度下降法进行求解所以需要归一化加快收敛避免震荡,SVM是基于距离的受量纲影响较大,就需要归一化数据,同理的还有KNN,Kmeans,PCA 。
-
树模型本身不需要归一化,因为归一化是为了使梯度下降时损失函数尽快的收敛,而树模型不需要梯度下降,是通过寻找最优切分点来使损失函数下降
-
朴素贝叶斯定理体现了后验概率 P(y|x) 、先验概率 P(y) 、条件概率 P(x|y)之间的关系: P(y|x)=P(x|y)·P(y)/P(x)。朴素贝叶斯之所以叫“朴素”是因为它假设输入的不同特征之间是独立的。构建朴素贝叶斯分类器的步骤如下: 1、根据训练样例分别计算每个类别出现的概率P(yi), 2、对每个特征属性计算所有划分的条件概率P(xi|yi), 3、对每个类别计算P(X|yi)*P(yi), 4、选择3步骤中数值最大项作为X的类别yk。
-
卡方检验(χ2 test),是一种常用的特征选择方法,尤其是在生物和金融领域。χ2 用来描述两个事件的独立性或者说描述实际观察值与期望值的偏离程度。χ2值越大,则表明实际观察值与期望值偏离越大,也说明两个事件的相互独立性越弱。
-
1、平方和损失函数(square loss):L(yi,f(xi)) = (yi - f(xi))2,常用于回归中如最小二乘,权重可直接初始化,再通过梯度下降不断更新。
-
2、铰链损失函数(Hing loss): L(mi) = max(0,1-mi(w)),常用于SVM中,在SVM损失函数表示为: L(y(i),x(i)) = max(0,1-y(i)f(x(i)))
-
3、对数损失函数:L(yi,f(xi)) = -logP(yi|xi),常用于逻辑回归
-
4、指数损失函数:L(yi,f(xi)) = exp(-yif(xi)),主要应用于Boosting算法中
-
针对以下三个问题,人们提出了相应的算法
*1 评估问题: 前向算法
*2 解码问题: Viterbi算法(预测问题)
*3 学习问题: Baum-Welch算法(向前向后算法)(训练问题) -
sigmoid 函数映射之后取值范围为(0,1)
-
tanh函数映射之后取值范围(-1,1)
-
Relu函数映射之后取值范围(0,…)大宇等于0
-
Boost和Bagging都是组合多个分类器投票的方法,二者均是根据单个分类器的正确率决定其权重。 Bagging与Boosting的区别:取样方式不同。Bagging采用均匀取样,而Boosting根据错误率取样。Bagging的各个预测函数没有权重,而Boosting是由权重的,Bagging的各个预测函数可以并行生成,而Boosing的哥哥预测函数只能顺序生成。
-
一元线性回归的基本假设有
1、随机误差项是一个期望值或平均值为0的随机变量;
2、对于解释变量的所有观测值,随机误差项有相同的方差;
3、随机误差项彼此不相关;
4、解释变量是确定性变量,不是随机变量,与随机误差项彼此之间相互独立;
5、解释变量之间不存在精确的(完全的)线性关系,即解释变量的样本观测值矩阵是满秩矩阵;
6、随机误差项服从正态分布违背基本假设的计量经济学模型还是可以估计的,只是不能使用普通最小二乘法进行估计
当存在异方差时,普通最小二乘法估计存在以下问题: 参数估计值虽然是无偏的,但不是最小方差线性无偏估计。
杜宾-瓦特森(DW)检验,计量经济,统计分析中常用的一种检验序列一阶
自相关
最常用的方法。
所谓多重共线性(Multicollinearity)是指线性回归模型中的解释变量之间由于存在精确相关关系或高度相关关系而使模型估计失真或难以估计准确。影响
(1)完全共线性下参数估计量不存在
(2)近似共线性下OLS估计量非有效
多重共线性使参数估计值的方差增大,1/(1-r2)为方差膨胀因子(Variance Inflation Factor, VIF)
(3)参数估计量经济含义不合理
(4)变量的显著性检验失去意义,可能将重要的解释变量排除在模型之外
(5)模型的预测功能失效。变大的方差容易使区间预测的“区间”变大,使预测失去意义。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 平方损失函数适合输出为连续的场景,而交叉熵损失则更适合二分类或多分类的场景

