- 1Description Resource Path Location TypeCannot change version of project facet Dynamic Web Module to_descriptionresourcepathlocationtype cannot change
- 2postgresql 使用之 存储架构 触摸真实数据的存储结构以及组织形式,存入数据库的数据原来在这里_postgresql 数据存在哪个文件
- 3uni-app - 使用 npm 安装第三方包_uniapp使用npm安装的第三方依赖
- 4gdip-yolo项目解读:gdip模块 |mdgip模块 |GDIP regularizer模块的使用分析|生成带雾图像|生成低亮度图片
- 5wps教育版支持latex公式啦_wps怎么识别latex
- 6PS的滤镜效果_ps滤镜效果
- 7ZooKeeper集群安装后显示ZooKeeper JMX enabled by defaultUsing config: /opt/app/zookeeper-3.4.13/bin/../conf
- 8深度|中国SaaS蜕变:从管理工具到商业化工具_saas产品商业化方案
- 9Python从小白到高手实现系列一百二十:用Fabric 进行自动化部署_python fabric 部署
- 10HAL库STM32C8T6最小系统板用串口做应声虫
C++:map和set的使用
赞
踩

一、关联式容器介绍
在学习map和set之前,我们接触到的容器有:vector、list、stack、queue、priority_queue、array,这些容器统称为序列式容器,因为其底层为线性序列的数据结构,里面存储的是元素本身。
关联式容器也是用来存储数据的,但是与序列式容器不同的是,里面存储的是<key,value>结构的键值对,在数据检索的时候效率是比序列式容器高的。
在STL中,总共实现了两种类型的关联性容器:树形结构与哈希结构,树型结构的关联式容器主要有四种:map、set、multimap、multiset。 这四种容器的共同点是:底层使用的是平衡搜索树(即红黑树)去实现的,容器中的元素是一个有序的序列。
二、键值对的介绍
用来表示具有一一对应关系的一种结构,该结构中一般只包含两个成员变量key和value,key代表键值,value表示与key对应的信息。比如说现在要建立一个英文词典,那么在字典中我们需要根据英文单词去查找对应的中文单词,那么英语单词与中文含义是一一对应的关系,通过键值对存储起来他们之间的一个映射关系,这样在词典中就可以找到对应的中文信息。
- template <class T1, class T2>
- struct pair
- {
- typedef T1 first_type;
- typedef T2 second_type;
- T1 first;
- T2 second;
- pair(): first(T1()), second(T2())
- {}
- pair(const T1& a, const T2& b): first(a), second(b)
- {}
- };
键值对的使用场景就是KV模型,如果不清楚KV模型的可以看看博主有关二叉搜索树的文章
三、set
3.1 set的介绍
翻译:
1. set是按照一定次序存储元素的关联性容器
2. 在set中,元素的value也标识它(value就是key,类型为T),并且每个value必须是唯一的。
set中的元素不能在容器中修改(否则会破坏搜索的规则),但是可以从容器中插入或删除它们。
3. 在内部,set中的元素总是按照其内部比较对象(类型比较)所指示的特定严格弱排序准则(不允许存在相同的关键字)进行排序。
4. set容器通过key访问单个元素的速度通常比unordered_set容器慢,但它们允许根据顺序对子集进行直接迭代。
5. set在底层是用二叉搜索树(红黑树)实现的。
注意:
1. 与map/multimap不同,map/multimap中存储的是真正的键值对<key, value>,set中只放value,但在底层实际存放的是由<value, value>构成的键值对。
2. set中插入元素时,只需要插入value即可,不需要构造键值对。
3. set中的元素不可以重复(因此可以使用set进行去重)。
4. 使用set的迭代器遍历set中的元素,可以得到有序序列
5. set中的元素默认按照小于来比较(可以通过仿函数去改变)
6. set中查找某个元素,时间复杂度为:log2n
小小总结一下重点:set可以做到排序(默认升序但是可通过仿函数改变行为)+去重,不允许键值冗余,不可修改
3.2 set的使用

第一个模版参数是类型,第二个模版参数是用来比较的仿函数,默认是升序,如果降序可以传greater<T>,当然也可以自己去写一个仿函数来改变比较逻辑
大多数stl容器都十分类似,这里重点介绍一些比较重要的!
3.2.1 构造函数

1、空的set
2、迭代器区间构造(可以是其他容器的迭代器)

3、拷贝构造
3.2.2 迭代器

 有着和vector和list一样的迭代器,但是要注意的是:
有着和vector和list一样的迭代器,但是要注意的是:
(1)该迭代器是一个双向迭代器(支持随机迭代器和双向迭代器进行迭代器区间构造)。
(2)我们看到的iterator其实本质上也是const_iterator (这里是为了保持接口一致性),因为set是不允许被修改的,否则会破坏搜索规则!!

3.2.3 insert
 1、参数是key值比较好理解,可以将对应的值插入进去,他会自动按照搜索规则找到相应的位置并插入!!
1、参数是key值比较好理解,可以将对应的值插入进去,他会自动按照搜索规则找到相应的位置并插入!!

我们来看看 pair<iterator,bool> 究竟代表了什么含义,我们前面说明了,set是不允许键值冗余的,也就是说我们的set可能会插入失败,如上图的后两个1就是插入失败的例子,bool就是为了区分插入成功还是失败。 也就是说这里设置的规则就是,无论你是插入成功还是插入失败,都会返回这个新插入元素(或者原先就有的元素)的迭代器iterator,但是通过bool能够帮助我们判断究竟是插入成功还是插入失败。

2、第一个参数是iterator,第二个参数是key值,这个就有点类似前面容器里的指定位置插入(无论插入成功还是失败都会返回对应的迭代器,区别就是如果待插入元素的相邻位置正好就是我们传进去的迭代器,此时可以实现高效的插入)。但是虽然说是指定位置插入,但是本身的插入逻辑也必须符合搜索的规则。 比如说1 2 3 4 5 8 9 10,如果我们想插入一个7,那么如果我们传的是5或者8的迭代器,此时就是一个高效的插入(因为相邻),但是如果我们传的迭代器是9,那么此时就不是一个高效的插入,因为找到9之后,还隔着一个8。
3、第三个的参数是迭代器区间,其实就是插入一个迭代器的区间返回(可以是其他容器的迭代器)
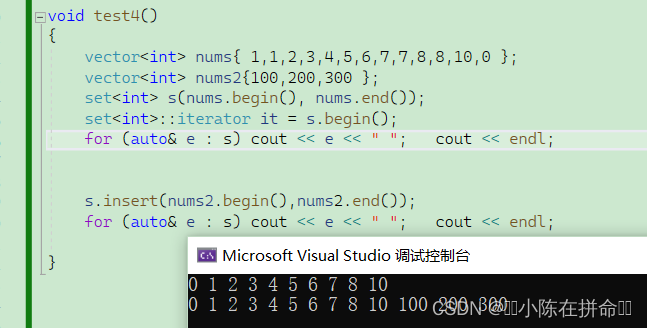
3.2.4 find

find的就是去set容器中找到对应键值并返回他对应的迭代器,如果找不到,就会返回end( )迭代器
3.2.5 count

count的作用本质上是为了参数对应的这个键值在set中有几个,但是因为set是不允许键值冗余的,所以其实其可能的结果要么是0要么是1,对应的就是有或者没有。
你可能会觉得,既然要么有要么没有,那么为什么参数不用bool而是返回个数呢??原因是因为下面的multiset,因为multiset是允许键值冗余的。
3.2.6 erase

1、传一个迭代器去删除。
2、直接通过传一个我们想要删除的键值去删除
3、删除set中指定的一块区间。
四、multiset
4.1 multiset的介绍
[翻译]:
1. multiset是按照特定顺序存储元素的容器,其中元素是可以重复的。
2. 在multiset中,元素的value也会识别它(因为multiset中本身存储的就是<value, value>组成
的键值对,因此value本身就是key,key就是value,类型为T). multiset元素的值不能在容器
中进行修改(因为元素总是const的),但可以从容器中插入或删除。
3. 在内部,multiset中的元素总是按照其内部比较规则(类型比较)所指示的特定严格弱排序准则
进行排序。
4. multiset容器通过key访问单个元素的速度通常比unordered_multiset容器慢,但当使用迭
代器遍历时会得到一个有序序列。
5. multiset底层结构为二叉搜索树(红黑树)。
注意:
1. multiset中再底层中存储的是<value, value>的键值对
2. mtltiset的插入接口中只需要插入即可
3. 与set的区别是,multiset中的元素可以重复,set中value是唯一的
4. 使用迭代器对multiset中的元素进行遍历,可以得到有序的序列
5. multiset中的元素不能修改
6. 在multiset中找某个元素,时间复杂度为log2n
7. multiset的作用:可以对元素进行排序
总而言之就是multiset相比set允许键值冗余,其他的基本上和set是一样的
4.2 multiset的使用
这里只介绍两者不同的地方
4.2.1.insert
因为允许键值冗余,所以是可以插入多个相同的键值的。set是排序+去重,multiset没有去重。

4.2.2.find/erase
既然允许键值冗余,那么就存在一个问题,如果我们查找或者是删除的键值是重复的,那么我们删除的究竟是哪一个的呢???

我们观察到,所有的1都打印出来了,这就说明了他找到的是第一个1,而搜索树的迭代器本身是利用中序去实现的,所以多个key的情况,返回的是中序的第一个key
4.2.3.count
这里的count返回个数就有意义了,因为键值冗余,是可以统计个数的。

五、map
5.1 map的介绍
翻译:
1. map是关联容器,它按照特定的次序(按照key来比较)存储由键值key和值value组合而成的元
素。
2. 在map中,键值key通常用于排序和惟一地标识元素,而值value中存储与此键值key关联的
内容。键值key和值value的类型可能不同,并且在map的内部,key与value通过成员类型
value_type绑定在一起,为其取别名称为pair:
typedef pair<const key, T> value_type;
3. 在内部,map中的元素总是按照键值key进行比较排序的。
4. map中通过键值访问单个元素的速度通常比unordered_map容器慢,但map允许根据顺序
对元素进行直接迭代(即对map中的元素进行迭代时,可以得到一个有序的序列)。
5. map支持下标访问符,即在[]中放入key,就可以找到与key对应的value。
6. map通常被实现为二叉搜索树(更准确的说:平衡二叉搜索树(红黑树))。

key: 键值对中key的类型
T: 键值对中value的类型
Compare: 比较器的类型,map中的元素是按照key来比较的,缺省情况下按照小于来比较,一般情况下(内置类型元素)该参数不需要传递,如果无法比较时(自定义类型),需要用户自己显式传递比较规则(一般情况下按照函数指针或者仿函数来传递)
5.2 map的使用
5.2.1 构造函数

(1)空map
(2)迭代器区间构造map

(3)拷贝构造map
5.2.2 迭代器


map中的key和set一样是不可修改的,但是value是可以修改的!!
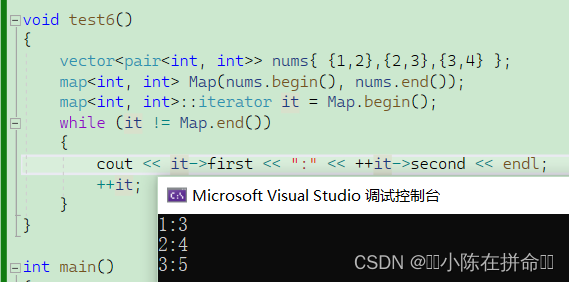
5.2.3 insert

(1)将对应的键值对直接插入进去(会按照搜索的规则到达相应的位置),并返回一个 pair<iterator,bool>,跟set是一样的,bool是用来判断插入成功或者失败,因为map也是不支持键值冗余的。
我们以实现一个中英词典来研究一下insert

因为map里面的元素都是一个个键值对,所以我们要直接插入的话,要用一个pair的匿名构造。但是c++中提供了一个make_pair的接口

本质上也是去调用这个匿名构造,但是我们的代码可以更加简洁。
 他可以帮助我们自动识别类型。
他可以帮助我们自动识别类型。
(2)和之前的set一样,参数传进去的迭代器相当于是一个暗示在该迭代器附近,如果相邻的话,可以实现最高效率的插入,如果不相邻的话就不存在。
(3)拷贝构造
5.2.4 erase

(1)删除指定迭代器位置的键值对
(2)删除键值为k的键值对,返回是否删除成功
(3)删除一段迭代器区间。
5.2.5 find

通过键值去找到并返回其对应的迭代器。如果没找到,就返回end()的迭代器。
5.2.6 count

在map中判断有无,在multimap中可以判断key对应键值对的个数。
5.2.7 重载[ ] (重点!)
假设我们想要统计水果的数量,结合前面的知识,我们可以先遍历这个数组,利用find函数去查找,如果找不到,说明是第一次出现,我们就将他插入进去,如果找到了,我们就直接进行计数的增加。
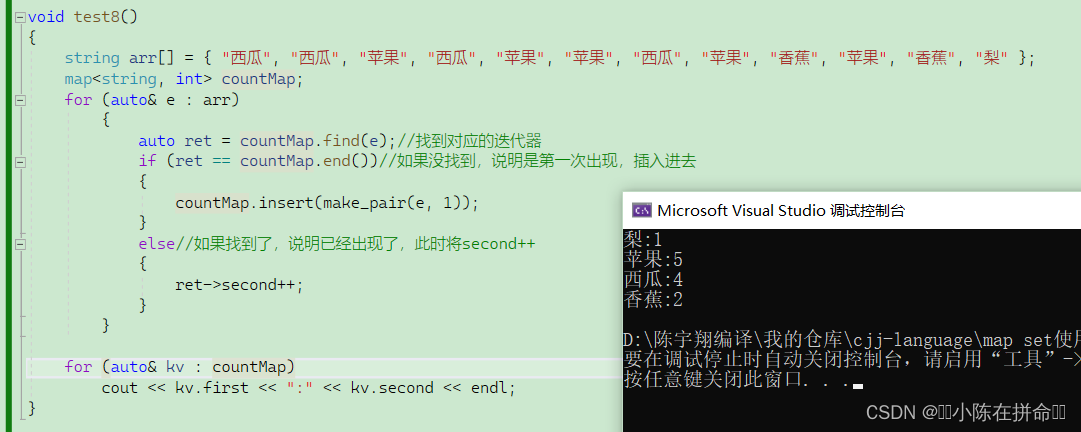
但是有了[ ],我们可以这样
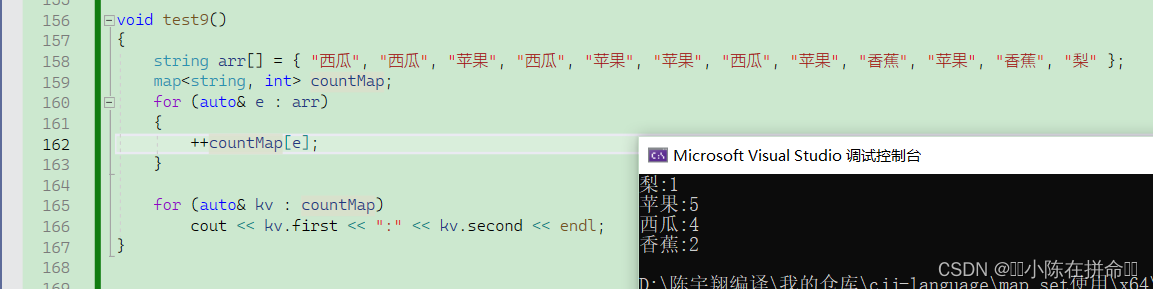 我们来探究一下其底层。
我们来探究一下其底层。

相当于是this指针调用了insert函数,并返回了对应的pair<iterator,bool> ,如果他的first对应的是迭代器,second对应的就是该迭代器的value。
所以我们可以分析出 ++countMap[e];为什么可以完成上面的操作,首先第一点就是无论插入成功还是失败都会返回对应位置的迭代器。第二点就是如果是第一次插入的话,其实insert中的value信息是一个默认构造,在该题中是int类型,所以默认构造是0(如果是string的话,就是空串,有了模版后,可以说所有的内置类型都是有自己的默认构造函数的),当返回后再碰上++,正好可以变成1.
总结:重载[ ]的方括号可以帮助我们完成4个任务,我们用之前的中英字典来验证。
1、插入(value是默认构造)
2、插入+修改(value是默认构造,但是返回后可以直接进行修改)
3、修改(找到对应键值的value并修改)
4、查找

在大多数情况下,当我们确定这个元素不在内部的时候,其实我们更喜欢用[ ]而不是insert
六、multimap
6.1 multimap的介绍
翻译:
1. Multimaps是关联式容器,它按照特定的顺序,存储由key和value映射成的键值对<key,
value>,其中多个键值对之间的key是可以重复的。
2. 在multimap中,通常按照key排序和唯一标识元素,而映射的value存储与key关联的内
容。key和value的类型可能不同,通过multimap内部的成员类型value_type组合在一起,
value_type是组合key和value的键值对:
typedef pair<const Key, T> value_type;
3. 在内部,multimap中的元素总是通过其内部比较对象,按照指定的特定严格弱排序标准对
key进行排序的。
4. multimap通过key访问单个元素的速度通常比unordered_multimap容器慢,但是使用迭代
器直接遍历multimap中的元素可以得到关于key有序的序列。
5. multimap在底层用二叉搜索树(红黑树)来实现。
注意:multimap和map的唯一不同就是:map中的key是唯一的,而multimap中key是可以
重复的。
6、multimap没有重载[ ],因为在map中key和value是一对一的关系,而在multimap中key和value可能是一对多的关系。
6.2 multimap的使用
multimap的insert可以支持键值冗余,find和erase如果涉及到多个key会返回中序的第一个。和multiset基本一样,这里就不做过多介绍。重点还是其可以键值冗余并且没有重载[ ]
七、经典OJ题的应用
7.1 随机链表的复制

- class Solution {
- public:
- Node* copyRandomList(Node* head)
- {
- if(head==nullptr) return head;
- map<Node*,Node*> copymap;
- Node*cur=head;
- Node*copyhead,*copytail;
- copyhead=copytail=nullptr;
- while(cur)
- {
- Node*copynode=new Node(cur->val);
- copymap[cur]=copynode;//将原节点和拷贝节点建立起映射关系
- if(copytail==nullptr) copytail=copyhead=copynode;
- else
- {
- copytail->next=copynode;
- copytail=copynode;
- }
- cur=cur->next;
- }
- //再遍历一次,连接random指针
- cur=head;
- Node*copy=copyhead;
- while(cur)
- {
- if(cur->random==nullptr) copy->random=nullptr;
- else copy->random=copymap[cur->random]; //通过映射关系找到对应的节点
- cur=cur->next;
- copy=copy->next;
- }
- return copyhead;
- }
- };

7.2 两个数组的交集

- class Solution {
- public:
- vector<int> intersection(vector<int>& nums1, vector<int>& nums2)
- {
- vector<int> ret;//记录返回结果
- //利用set帮助我们排序+去重
- set<int> s1(nums1.begin(),nums1.end());
- set<int> s2(nums2.begin(),nums2.end());
- // 双指针找交集
- set<int>::iterator it1=s1.begin();
- set<int>::iterator it2=s2.begin();
- while(it1!=s1.end()&&it2!=s2.end())
- {
- //不相等的时候谁小谁++
- if(*it1<*it2) ++it1;
- else if(*it1>*it2) ++it2;
- else //相等,就插入结果
- {
- ret.push_back(*it1);
- ++it1;
- ++it2;
- }
- }
- return ret;
- }
- };
7.3 前K个高频单词

细节处理,这部分容器的仿函数最好是用const修饰,因为一些调用的对象可能是const修饰的。
思路1:放到vector中,然后用稳定的排序
- class Solution {
- public:
- struct compare//要注意仿函数要+const修饰,否则可能编译不过
- {
- bool operator()(const pair<string,int>&kv1,const pair<string,int>&kv2)
- {
- return kv1.second>kv2.second;
- }
- };
- vector<string> topKFrequent(vector<string>& words, int k)
- {
- map<string,int> countmap;//计数
- for(auto&s:words) ++countmap[s];
- //此时已经按照字典序排好了,将其拷贝到vector中
- vector<pair<string,int>> nums(countmap.begin(),countmap.end());
- //要用一个稳定的排序 我们排序的是比较value,所以要修改比较逻辑
- stable_sort(nums.begin(),nums.end(),compare());
- vector<string> ret;
- for(int i=0;i<k;++i) ret.push_back(nums[i].first);
- return ret;
- }
- };
思路2:放到vector中,用sort(不稳定),通过compare去改变比较逻辑
- class Solution {
- public:
- struct compare//要注意仿函数要+const修饰,否则可能编译不过
- {
- bool operator()(const pair<string,int>&kv1,const pair<string,int>&kv2)
- {
- return kv1.second>kv2.second||(kv1.second==kv2.second&&kv1.first<kv2.first);
- }
- };
- vector<string> topKFrequent(vector<string>& words, int k)
- {
- map<string,int> countmap;//计数
- for(auto&s:words) ++countmap[s];
- //此时已经按照字典序排好了,将其拷贝到vector中
- vector<pair<string,int>> nums(countmap.begin(),countmap.end());
- //要用一个稳定的排序 我们排序的是比较value,所以要修改比较逻辑
- sort(nums.begin(),nums.end(),compare());
- vector<string> ret;
- for(int i=0;i<k;++i) ret.push_back(nums[i].first);
- return ret;
- }
- };
思路3:用拷贝到一个multimap(用map,次数相同的会被覆盖掉)中(因为map是用key比较的,所以我们拷贝的时候将string和int进行交换)
- class Solution {
- public:
- struct compare//要注意仿函数要+const修饰,否则可能编译不过
- {
- bool operator()(const int&k1,const int&k2) const
- {
- return k1>k2;
- }
- };
- vector<string> topKFrequent(vector<string>& words, int k)
- {
- map<string,int> countmap;//计数
- for(auto&s:words) ++countmap[s];
- //此时已经按照字典序排好了,将其拷贝到vector中
- multimap<int,string,compare> sortmap;
- for(auto &kv:countmap) sortmap.insert(make_pair(kv.second,kv.first));
-
- vector<string> ret;
- auto it=sortmap.begin();
- while(k--)
- {
- ret.push_back(it->second);
- ++it;
- }
- return ret;
- }
- };
思路4:用multiset去进行排序,然后改变比较逻辑。
- class Solution {
- public:
- struct compare//要注意仿函数要+const修饰,否则可能编译不过
- {
- bool operator()(const pair<string,int>&kv1,const pair<string,int>&kv2) const
- {
- return kv1.second>kv2.second||(kv1.second==kv2.second&&kv1.first<kv2.first);
- }
- };
- vector<string> topKFrequent(vector<string>& words, int k)
- {
- map<string,int> countmap;//计数
- for(auto&s:words) ++countmap[s];
- //此时已经按照字典序排好了,将其拷贝到vector中
- multiset<pair<string,int>,compare> sortmap(countmap.begin(),countmap.end());
-
- vector<string> ret;
- auto it=sortmap.begin();
- while(k--)
- {
- ret.push_back(it->first);
- ++it;
- }
- return ret;
- }
- };
思路5:优先级队列+控制比较逻辑
- class Solution {
- public:
- struct compare//要注意仿函数要+const修饰,否则可能编译不过
- {
- bool operator()(const pair<string,int>&kv1,const pair<string,int>&kv2) const
- {
- return kv1.second>kv2.second||(kv1.second==kv2.second&&kv1.first<kv2.first);
- }
- };
- vector<string> topKFrequent(vector<string>& words, int k)
- {
- map<string,int> countmap;//计数
- for(auto&s:words) ++countmap[s];
- //此时已经按照字典序排好了,将其拷贝到vector中
- priority_queue<pair<string,int>,vector<pair<string,int>>,compare> heap;
- for (auto& it : countmap) {
- heap.push(it);
- if (heap.size() > k) {
- heap.pop();
- }
- }
- vector<string> ret(k);
- for(int i=k-1;i>=0;--i)
- {
- ret[i]=heap.top().first;
- heap.pop();
- }
- return ret;
- }
- };