
- 1Node-导入导出/npm/包/Express - 框架/同源策略/解决跨域_npm时候ecmascript导入
- 2(Unity)UI上的轮转图(3D效果)_unity3d中ui弧形轮番旋转(ui 3d旋转)
- 3matlab中关于双重积分的问题_matlab求复杂函数的二重积分
- 4浅谈——触发器
- 52024年Go最新使用Golang Web3库进行区块链开发_go语言有web3库吗,2024年最新金九银十正确打开方式
- 6python用pd.read_csv()方法来读取csv文件_pd 读csv
- 7智能自助终端主板RK3288/RK3568在酒店前台自助机方案的应用,支持鸿蒙,支持免费定制
- 8vue3+vite 代码混淆插件_rollup-plugin-obfuscator
- 9如何删除Git本地仓库和删除GitHub上的Git远程仓库Repository_本地git仓库远程地址删除
- 10GIT error: You have not concluded your merge (MERGE_HEAD exists)_git : you have not concluded your merge ( merge he
pytorch 模型训练时多卡负载不均衡(GPU的0卡显存过高)解决办法(简单有效)_多卡部署大模型还是爆显存
赞
踩
本文主要解决pytorch在进行模型训练时出现GPU的0卡占用显存比其他卡要多的问题。
如下图所示:本机GPU卡为TITAN RTX,显存24220M,batch_size = 9,用了三张卡。第0卡显存占用24207M,这时仅仅是刚开始运行,数据只是少量的移到显卡上,如果数据在多点,0卡的显存肯定撑爆。出现0卡显存更高的原因:网络在反向传播的时候,计算loss的梯度默认都在0卡上计算。因此会比其他显卡多用一些显存,具体多用多少,主要还要看网络的结构。
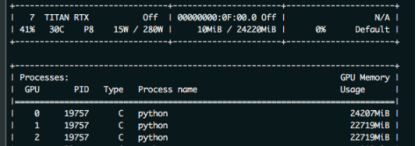
因此,为了防止训练由于 out of memory 而中断。比较笨的办法是将batch_size设为6,即每张卡放2条数据。
batch_size = 6时,其他不变,如下图所示
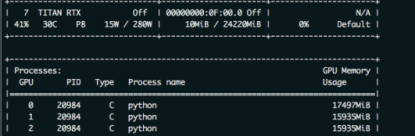
有没有发现问题?显存只用了1,2卡的显存只用了16G不到。就因为0卡可能会超那么一点点显存,而牺牲了batch_size。
那么没有更优雅的方法呢?答案是肯定的。那就是借用下transformer-xl中用到的 BalancedDataParallel类。代码如下(代码出处):
import torch from torch.nn.parallel.data_parallel import DataParallel from torch.nn.parallel.parallel_apply import parallel_apply from torch.nn.parallel._functions import Scatter def scatter(inputs, target_gpus, chunk_sizes, dim=0): r""" Slices tensors into approximately equal chunks and distributes them across given GPUs. Duplicates references to objects that are not tensors. """ def scatter_map(obj): if isinstance(obj, torch.Tensor): try: return Scatter.apply(target_gpus, chunk_sizes, dim, obj) except Exception: print('obj', obj.size()) print('dim', dim) print('chunk_sizes', chunk_sizes) quit() if isinstance(obj, tuple) and len(obj) > 0: return list(zip(*map(scatter_map, obj))) if isinstance(obj, list) and len(obj) > 0: return list(map(list, zip(*map(scatter_map, obj)))) if isinstance(obj, dict) and len(obj) > 0: return list(map(type(obj), zip(*map(scatter_map, obj.items())))) return [obj for targets in target_gpus] # After scatter_map is called, a scatter_map cell will exist. This cell # has a reference to the actual function scatter_map, which has references # to a closure that has a reference to the scatter_map cell (because the # fn is recursive). To avoid this reference cycle, we set the function to # None, clearing the cell try: return scatter_map(inputs) finally: scatter_map = None def scatter_kwargs(inputs, kwargs, target_gpus, chunk_sizes, dim=0): """Scatter with support for kwargs dictionary""" inputs = scatter(inputs, target_gpus, chunk_sizes, dim) if inputs else [] kwargs = scatter(kwargs, target_gpus, chunk_sizes, dim) if kwargs else [] if len(inputs) < len(kwargs): inputs.extend([() for _ in range(len(kwargs) - len(inputs))]) elif len(kwargs) < len(inputs): kwargs.extend([{} for _ in range(len(inputs) - len(kwargs))]) inputs = tuple(inputs) kwargs = tuple(kwargs) return inputs, kwargs class BalancedDataParallel(DataParallel): def __init__(self, gpu0_bsz, *args, **kwargs): self.gpu0_bsz = gpu0_bsz super().__init__(*args, **kwargs) def forward(self, *inputs, **kwargs): if not self.device_ids: return self.module(*inputs, **kwargs) if self.gpu0_bsz == 0: device_ids = self.device_ids[1:] else: device_ids = self.device_ids inputs, kwargs = self.scatter(inputs, kwargs, device_ids) if len(self.device_ids) == 1: return self.module(*inputs[0], **kwargs[0]) replicas = self.replicate(self.module, self.device_ids) if self.gpu0_bsz == 0: replicas = replicas[1:] outputs = self.parallel_apply(replicas, device_ids, inputs, kwargs) return self.gather(outputs, self.output_device) def parallel_apply(self, replicas, device_ids, inputs, kwargs): return parallel_apply(replicas, inputs, kwargs, device_ids) def scatter(self, inputs, kwargs, device_ids): bsz = inputs[0].size(self.dim) num_dev = len(self.device_ids) gpu0_bsz = self.gpu0_bsz bsz_unit = (bsz - gpu0_bsz) // (num_dev - 1) if gpu0_bsz < bsz_unit: chunk_sizes = [gpu0_bsz] + [bsz_unit] * (num_dev - 1) delta = bsz - sum(chunk_sizes) for i in range(delta): chunk_sizes[i + 1] += 1 if gpu0_bsz == 0: chunk_sizes = chunk_sizes[1:] else: return super().scatter(inputs, kwargs, device_ids) return scatter_kwargs(inputs, kwargs, device_ids, chunk_sizes, dim=self.dim)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
从代码中可以看到,BalancedDataParallel继承了 torch.nn.DataParallel,之后通过自定义0卡batch_size的大小gpu0_bsz,即让0卡少一点数据。均衡0卡和其他卡的显存占用。调用代码如下:
import BalancedDataParallel
if n_gpu > 1:
model = BalancedDataParallel(2, model, dim=0).to(device)
# model = torch.nn.DataParallel(model)
- 1
- 2
- 3
- 4
- 5
gpu0_bsz:GPU的0卡batch_size;
model:模型;
dim:batch所在维度
因此,我们不妨将刚才的batch_size设为8,即gpu0_bsz=2试试,结果如下:
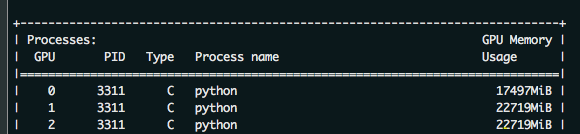
成功的将batch_size从6调整到了8,因为0卡少放了一个batch,因此,会比其他的卡少。但是牺牲一张卡的显存,换取其他卡的显存,最终提高了batch_size,还是可取得。特别是当卡数目比较多的时候,这种方法的优势就更明显了。

