
- 1yolov5代码--注释_yolov5代码注释
- 2用HAL库改写江科大的stm32入门例子_9-1 串口发送接收
- 3【数据结构】双向带头循环链表_(head)->prev
- 4不平凡的2021,末流普本生秋招上岸大厂的历程_大厂青训营
- 5Python中关于try...finally的一些疑问
- 6实现网页上传头像的功能(PHP版)_php用户头像上传
- 7人工智能&机器学习论文库/论文目录获取_怎么找华为杯人工智能历年的论文
- 8Java使用poi-tl1.9.1生成Word文档的几个小技巧
- 9Docker五部曲之五:通过Docker和GitHub Action搭建个人CICD项目
- 10山东大学软件学院项目实训-创新实训-基于大模型的旅游平台(十七)- JUC(3)
英伟达(NVIDIA)显卡-A100/A800/H100/H800/L40/L40S/4090风扇卡/4090涡轮卡_nvidia l40与4090性能比较
赞
踩
英伟达(NVIDIA)显卡
类型
- NVIDIA的显卡目前可以按照应用领域大致分为三种类型
面向游戏娱乐领域 。 GeForce RTX™系列
- GeForce RTX™系列英伟达面向大众消费级游戏和创作者用户的图形加速卡。如RTX 3090、RTX 4090等。这类产品在性能、功耗和成本之间达到最佳平衡点,能带来极致的游戏和创作体验。
面向专业设计和虚拟化领域。NVIDIA RTX™系列
- NVIDIA RTX™系列系列是英伟达面向专业可视化和创意工作负载的高性能 GPU,提供强大的计算性能、大容量视频内存、硬件编码解码引擎等。定位服务于工业设计、建筑设计、影视特效渲染等专业工作站用户。RTX系列是高端的专业可视化工作站级显卡。
面向深度学习、人工智能和高性能计算领域。A、H、L、V、T
- NVIDIA英伟达的A系列、H系列、L系列、V系列、T系列产品线主要区别和定位如下:
A 系列:
- 英伟达AI计算加速器系列。代表产品包括 A100、A30和A40等用于数据中心AI训练和推理的高性能加速卡。采用Ampere、Hopper等顶级架构。
H 系列:
- AI超算系列。首款产品是H100推理加速卡。代表了最高级的AI计算平台,通常搭载数以千计的A系列加速卡,提供巨大AI计算能力。
L系列:
- 英伟达专为AI推理而设计的经济高效产品线。如L40和DeepStream系列加速器,应用于边缘AI。
V系列:
- 英伟达虚拟工作站(vWS)系列,支持虚拟化的专业显卡产品线,用于云端的设计师和工程师。
T系列:
- 英伟达TensorRT系列,是针对AI推理进行软件和硬件协同优化的解决方案,包括了软件栈、开发工具链和加速引擎。
总体来说,A系列定位高性能AI训练;H系列是最强AI超算;L系列是边缘AI推理;V系列服务于虚拟桌面;T系列提供AI推理加速。
A100、A800、H100、H800、L40、L40S、4090(公版 涡轮版)
- 在了解这几款 GPU 的区别之前,我们先来简单了解下 NVIDIA GPU 的核心参数,这样能够更好地帮助我们了解这些 GPU 的差别和各自的优势。
GPU 的核心架构及参数
- CUDA Core:CUDA Core 是 NVIDIA GPU上的计算核心单元,用于执行通用的并行计算任务,是最常看到的核心类型。NVIDIA 通常用最小的运算单元表示自己的运算能力,CUDA Core 指的是一个执行基础运算的处理元件,我们所说的 CUDA Core 数量,通常对应的是 FP32 计算单元的数量。
- Tensor Core:Tensor Core 是 NVIDIA Volta 架构及其后续架构(如Ampere架构)中引入的一种特殊计算单元。它们专门用于深度学习任务中的张量计算,如矩阵乘法和卷积运算。Tensor Core 核心特别大,通常与深度学习框架(如 TensorFlow 和 PyTorch)相结合使用,它可以把整个矩阵都载入寄存器中批量运算,实现十几倍的效率提升。
- RT Core:RT Core 是 NVIDIA 的专用硬件单元,主要用于加速光线追踪计算。正常数据中心级的 GPU 核心是没有 RT Core 的,主要是消费级显卡才为光线追踪运算添加了 RTCores。RT Core 主要用于游戏开发、电影制作和虚拟现实等需要实时渲染的领域。
在了解了 GPU 的这些核心参数之后,我们再来看看 NVIDIA GPU 架构的演进。
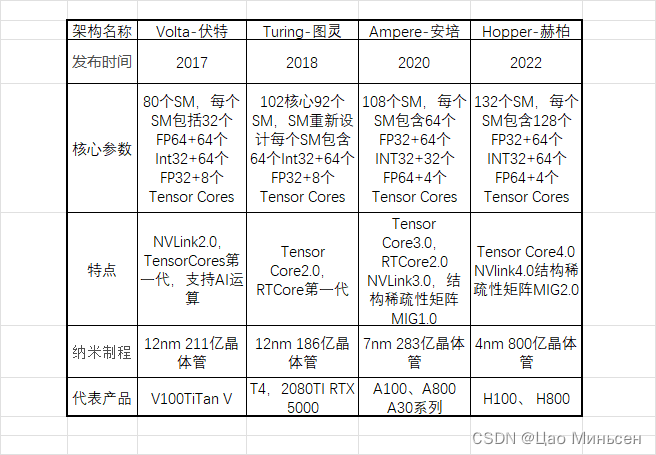
N卡主流型号对比
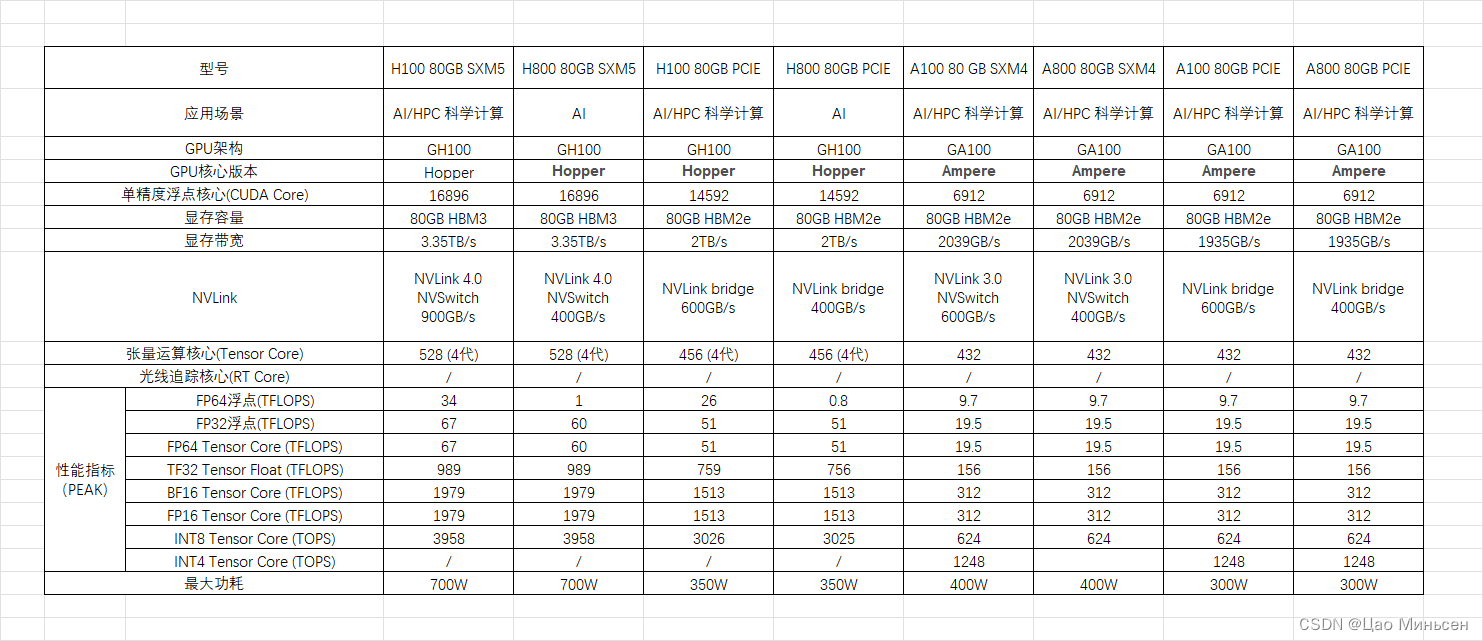
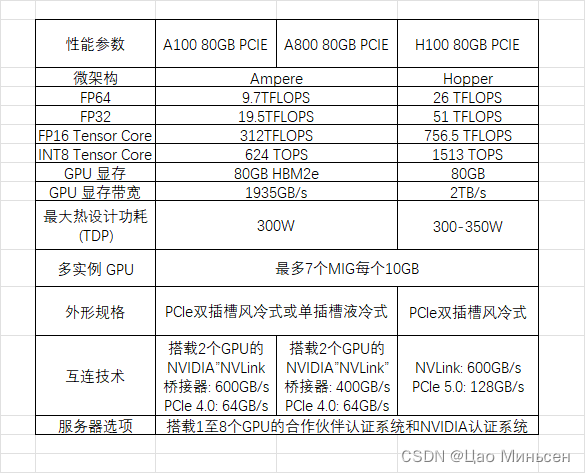
A100 vs H100
-
NVIDIA H100 采用 NVIDIA Hopper GPU 架构,使 NVIDIA 数据中心平台的加速计算性能再次实现了重大飞跃。H100 采用专为 NVIDIA 定制的 TSMC 4N 工艺制造,拥有 800 亿个 晶体管,并包含多项架构改进。
-
H100 是 NVIDIA 的第 9 代数据中心 GPU,旨在为大规模 AI 和 HPC 实现相比于上一代 NVIDIA A100 Tensor Core GPU 数量级的性能飞跃。H100 延续了 A100 的主要设计重点,可提升 AI 和 HPC 工作负载的强大扩展能力,并显著提升架构效率。
新的 SM 架构
-
H100 SM 基于 NVIDIA A100 Tensor Core GPU SM 架构而构建。由于引入了 FP8,与 A100 相比,H100 SM 将每 SM 浮点计算能力峰值提升了 4 倍,并且对于之前所有的 Tensor Core 和 FP32 / FP64 数据类型,将各个时钟频率下的原始 SM 计算能力增加了一倍。
-
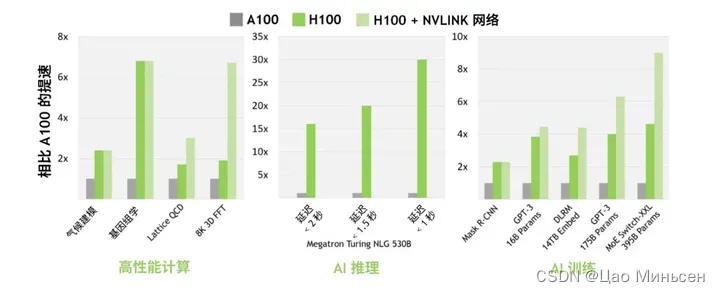
与上一代 A100 相比,采用 Hopper 的 FP8 Tensor Core 的新 Transformer 引擎使大型语言模型的 AI 训练速度提升 9 倍,AI 推理速度提升 30 倍。针对用于基因组学和蛋白质测序的 Smith-Waterman 算法,Hopper 的新 DPX 指令可将其处理速度提升 7 倍。
第四代 Tensor Core 架构
-
Hopper 新的第四代 Tensor Core、Tensor 内存加速器以及许多其他新 SM 和 H100 架构的总体改进,在许多其他情况下可令 HPC 和 AI 性能获得最高 3 倍的提升。
-
与 A100 相比,H100 中新的第四代 Tensor Core 架构可使每时钟每个 SM 的原始密集计算和稀疏矩阵运算吞吐量提升一倍,考虑到 H100 比 A100 拥有更高的 GPU 加速频率,其甚至会达到更高的吞吐量。其支持 FP8、FP16、BF16、TF32、FP64 和 INT8 MMA 数据类型。新的 Tensor Core 还能够实现更高效的数据管理,最高可节省 30% 的操作数传输功耗。
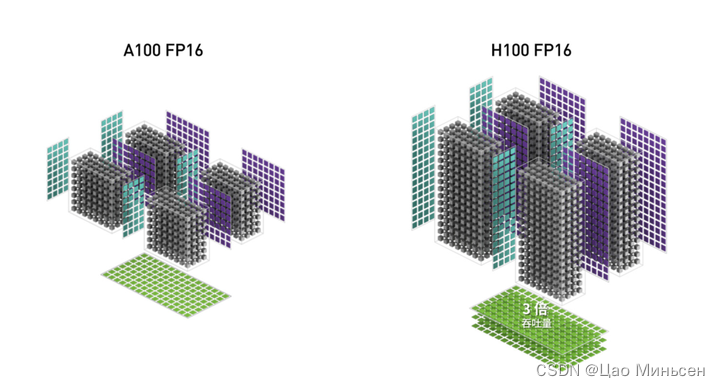
Hopper FP8 数据格式
- H100 GPU 增加了 FP8 Tensor Core,可加速 AI 训练和推理。FP8 Tensor Core 支持 FP32 和 FP16 累加器,以及两种新的 FP8 输入类型:E4M3(具有 4 个指数位、3 个尾数位和 1 个符号位)和E5M2(具有 5 个指数位、2 个尾数位和 1 个符号位)。E4M3 支持动态范围更小、精度更高的计算,而 E5M2 可提供更宽广的动态范围和更低的精度。与 FP16 或 BF16 相比,FP8 可将所需要的数据存储空间减半,并将吞吐量提升一倍。
新的 Transformer 引擎可结合使用 FP8 和 FP16 精度,减少内存使用并提高性能,同时仍能保持大型语言模型和其他模型的准确性。

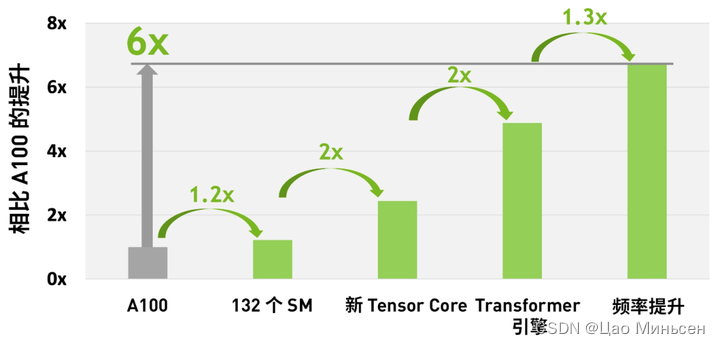
- 综合 H100 中所有新的计算技术进步的因素,H100 的计算性能比 A100 提高了约 6 倍。首先是 H100 配备 132 个 SM,比 A100 的 108 个 SM 增加了 22%。由于采用新的第四代 Tensor Core,每个 H100 SM 的速度都提升了 2 倍。在每个 Tensor Core 中,新的 FP8 格式和相应的 Transformer 引擎又将性能提升了 2 倍。最后,H100 中更高的时钟频率将性能再提升了约 1.3 倍。通过这些改进,总体而言,H100 的峰值计算吞吐量大约为 A100 的 6 倍。
A800 和 H800
- A800 和 H800,从型号上看,莫非它们的性能是 A100、H800 的好几倍?事实不然。虽然从数字上来看,800 比 100 数字要大,其实是为了合规对 A100 和 H100 的某些参数做了调整。A800 相对比 A100 而言,仅限制了 GPU 之间的互联带宽,从 A100 的 600GB/s 降至 400GB/s,算力参数无变化。而 H800 则对算力和互联带宽都进行了调整。
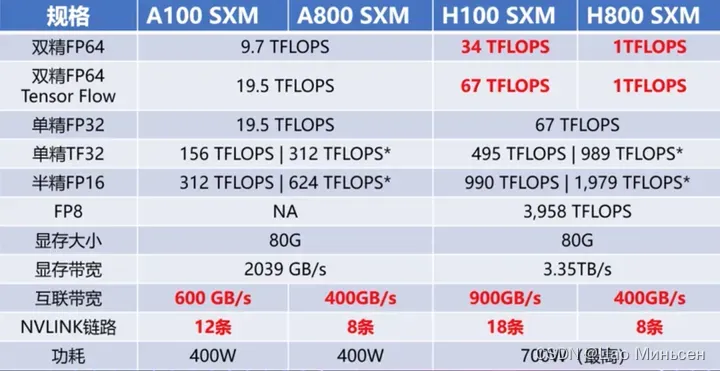
- A800 虽然在互联带宽上有所降低,但和 A100 在双精方面算力一致,在高性能科学计算领域没有影响。
H800 VS H100
-
作为H100的替代品,中国特供版H800,PCle版本SXM版本都是在双精度 (FP64) 和vlink传输速率的削减,其他其他参数和H100都是一模一样的。
-
FP64上的削弱主要影响的是H800在科学计算,流体计算,有限元分析等超算领域的应用,深度学习等应用主要看单精度的浮点性能,大部分场景下性能不受影响。而受到影响较大的还是NVlink上的削减,但是因为架构上的升级,虽然比不上同为Hopper架构的H100,但是比ampere架构的A800还是要强上不少的。
-
所以其实H800和H100的性能差距并没有大家想象的那么夸张,就算是削弱了FP64与NVlink传输速率,性能依旧够用,最关键的是,它合法呀(禁售,质保等问题就不在此细说了)!所以如果不是应用于超算的话也没必要冒着风险去选择H100。
H800-GPU 可为大模型训练、自动驾驶,深度学习等提供高性能、高带宽和低延迟的集群算例根据腾讯云°新一代集群的实测数据显示,在面对万亿参数的 AI 大模型训练时,之前需要时间为11 天,而在 H800 的加持下,新一代集群,训练时间可缩短至 4 天,证明了最新代 H800 比A800 的高强悍性,有更高的性能,在任务处理上以最快速度处理,进一步证明了,H800 在大模型训练只领域有充分的地位以及能力。
L40GPU与L40S GPU
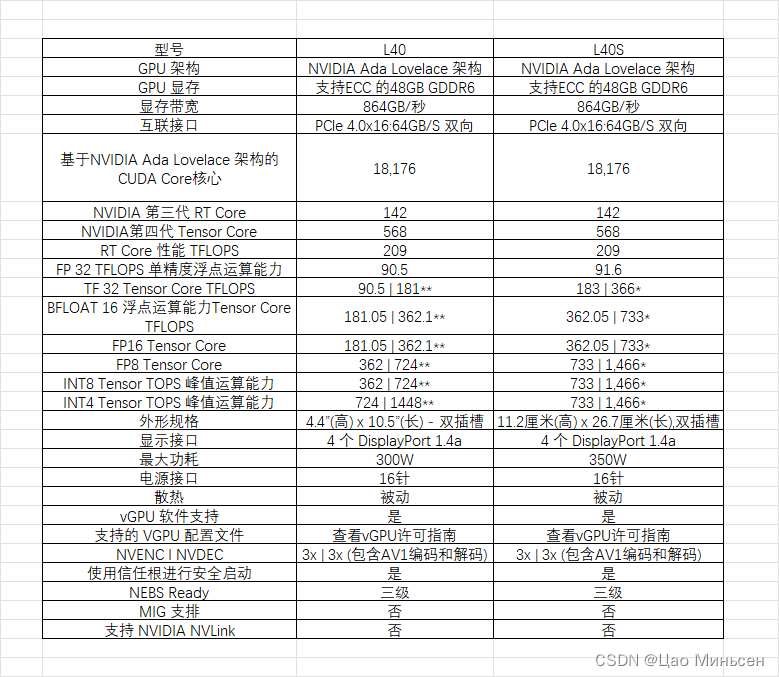
-
L40最高300W,L40S最高350W,两者都是同属于英伟达Ada Lovelace 架构,48GB支持ECC的GDDR6显存,两者的显存带宽都是864GB/S,L40S作为L40的升级版本,主要在FP32运算能力提示幅度为1.1TFLOPS,在TF32 Tensor Core TFLOPS、FP16 Tensor Core、FP8 Tensor Core、INT8 Tensor Core运算能力均提升 一倍左右。
-
两者都支持虚拟化设定,虚拟化的显存可以设置成 GPU 1 GB, 2 GB, 3 GB, 4 GB, 6 GB, 8 GB, 12 GB, 16 GB, 24 GB, 48 GB。
-
性能方面 NVIDIA L40S GPU 是一款适用于数据中心的功能强大的通用型 GPU,可为下一代AI 应用提供端到端加速服务 ‒ 从生成式 AI 以及模型训练和推理到 3D 图形、渲染和视频应用。AI 训练上 8 片 A100 80GB 与搭载了 4 片 L40S GPU 两套系统对比 GPT-408 LoRA (相对性能) L40S性能是A100的 0.7倍,生成式 AI Stable Diffusion 画图上 默认512x512图片生成,L40S性能是A100的 0.2倍。
-
NVIDIA L40 GPU特别适用于数据中心的各种计算密集型工作负载,例如AI的训练和推理、流媒体制作、数据科学和图形应用。
-
价格方面:L40S在亚马逊上的价格大约在$13000美金附近,L40价格在亚马逊上的价格在$7900美金附近,L40S的价格与A100 80GB的价格大致相同,L40S的缺点是不能使用Nvlink进行互联,但是可以通过系统工具实现4卡同时工作,AI性能上比A100 8卡更高,L40可以使用Nvlink进行双卡显存共享实现96GB显存
-
最后我们对上面进行总结一下:L40S是L40GPU的升级版本,在CUDA核心和显存容量不变的情况下实现了性能的增长,如果需要进行AI训练和推理那么选择L40S会更好,如果不需要更强的AI性能可以选择L40GPU,同时采购成本更低。
4090风扇卡与4090涡轮卡
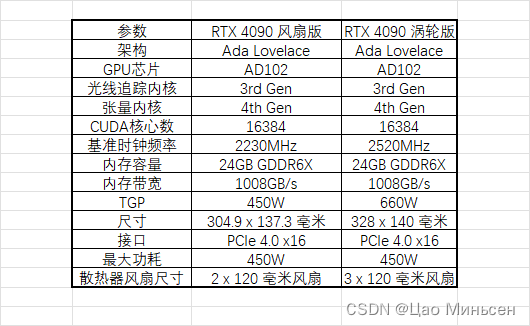
4090风扇卡和涡轮卡的区别
供电接口位置与散热方向
- 风扇卡与涡轮卡的供电接口位置不同,涡轮卡的供电接口位置在接口尾部,供电线比风扇卡的线更短,这样是方便安装和理线,而风扇卡供电接口一般在显卡顶部,接线后线缆会高于机箱最高面,在服务器中使用风扇卡,服务器盖板盖不上。
在散热方向上面,涡轮卡散热方向是朝尾部散热,并于服务器风向是一致的,而风扇卡的散热是朝四面八方来散热的,平常的PC机箱放一张是可以适应的,但用作服务器上(很多时候是多卡)就不适合了,很容易因为温度过热出现宕机。
风扇卡与涡轮卡的尺寸大小不同
- 涡轮卡与风扇卡的尺寸大小也是不一样的,风扇卡的尺寸一般是2.5-3倍宽设计,而涡轮卡的尺寸大小是双宽设计,因为涡轮卡为了方便放入服务器里,所以涡轮卡的尺寸和高度都远远低于风扇卡,从而服务器可以支持4卡或者8卡,如果用风扇卡代替涡轮卡装在服务器里,那位置够不够还是一回事儿呢。
面对市场不同
- 风扇卡无论是公版显卡还是非公版显卡,风扇卡都是面向个人的,是应用在个人游戏行业的,4090风扇卡的特点就是外观炫酷,而个人游戏行业就是为了风扇卡的外观和玩游戏的性能。而4090涡轮卡是定制版,是面向AI科技产业,因为做工精巧、支持多卡安装、性价比高等一系列优点,4090涡轮卡深受广大AI深度学习用户的喜爱。


