
- 1python学习:zip文件_deflated lzma
- 2Bat脚本编写之Dos 基本操作命令_dos命令运行bat脚本怎么写
- 3Linux系统中常用的压缩、解压缩命令(tar、zip、gzip、bzip2、xz)_linux tar 压缩文件的时候忽略绝对路径 只压缩文件名
- 4WDS迁移注意事项
- 5香港高防服务器租用应该如何选择?
- 6Linux环境下Qt应用程序安装器(installer)制作_qtifw在linux中应用
- 7mysql数据库常用函数_使用mysql语句比较s1和s2两个字符串
- 8Go 工程化标准实践_go internal最佳实践
- 9理解RTF和RTX指标_asr rtf
- 10windows安装docker 异常解决_docker desktop requires windows 10 pro/enterprise/
Elasticsearch 简介
赞
踩
Elasticsearch 是一个非常强大的搜索引擎。它目前被广泛地使用于各个 IT 公司。Elasticsearch 是由 Elastic 公司创建。它的代码位于 GitHub - elastic/elasticsearch: Free and Open, Distributed, RESTful Search Engine。Elasticsearch 是一个分布式、免费和开放的搜索和分析引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。 Elasticsearch 基于 Apache Lucene 构建,并于 2010 年由 Elasticsearch N.V. 首次发布(现在称为 Elastic)。Elasticsearch 以其简单的 REST API、分布式特性、速度和可扩展性而闻名,是 Elastic Stack 的核心组件,Elastic Stack 是一组用于数据摄取、丰富、存储、分析和可视化的免费开放工具。 通常被称为 ELK Stack。Elastic 公司也同时拥有 Logstash 及 Kibana 开源项目。这个三个项目组合在一起,就形成了 ELK 软件栈。他们三个共同形成了一个强大的生态圈。简单地说,Logstash 负责数据的采集,处理(丰富数据,数据转换等),Kibana 负责数据展示,分析,管理,监督,警报及方案。Elasticsearch 处于最核心的位置,它可以帮我们对数据进行存储,并快速地搜索及分析数据。随着后来的 Beats 加入,ELK 软件栈,也被称为 ELKB。
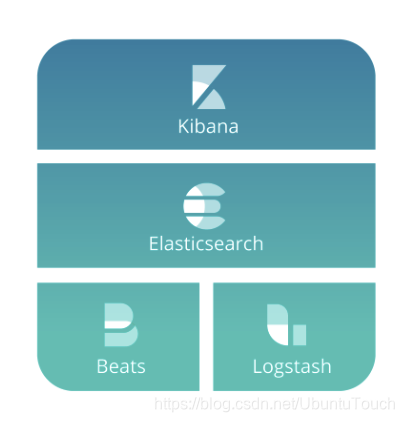

事实上 Elasticsearch 的完整栈有如下的几个:
Beats 是一些轻量级可以允许在客户端服务器中的代理。它并不需要部署到我们的 Elastic 云中。它可以帮我们收集所有需要的事件。如果把 Beats 也纳入到我的架构中,那么 Elastic 的栈可以表述为:
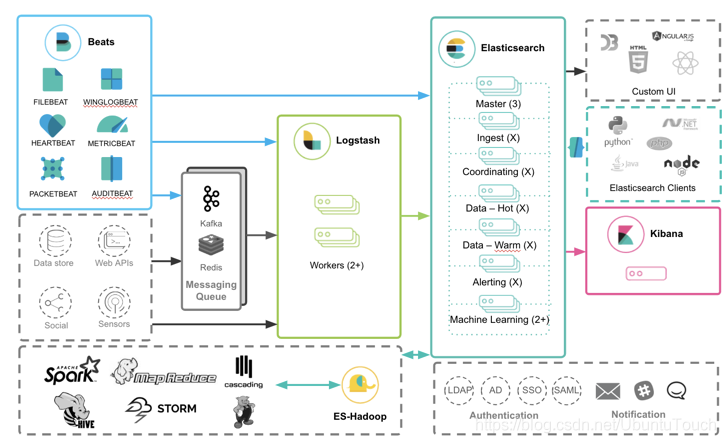

在上面是一个典型的运用 Elastic Stack 的架构。我们通常不会在客户端直接调用 Elasticsearch 的 REST 接口。取而代之的是,我们使用一个 Search Service 作为中间接口。Search Service 再向 Elasticsearch 发送请求。我们可以通过 Beats 来采集 service 的日志及指标信息,我们甚至可以使用 Elastic Stack 所提供的 APM (应用性能监控)来监控应用及服务的性能并调优。Beats 所收集的信息,我们可以直接发送至 Elasticsearch,也可以发送至 Logstash 对数据做更进一步的加工(丰富,转换,删除,结构化等)再发送至 Elasticsearch。我们可以通过 Kibana 对数据进行可视化,分析,管理,对服务进行监控等。
在 Elastic 公司,我们称上面的技术栈为 Elastic Stack。
在最新的 Elastic Stack 架构中,取而代之的是,integration 是被推荐的采集数据的方法。采用 integration 可以使得我们能对采集端进行集中监控。
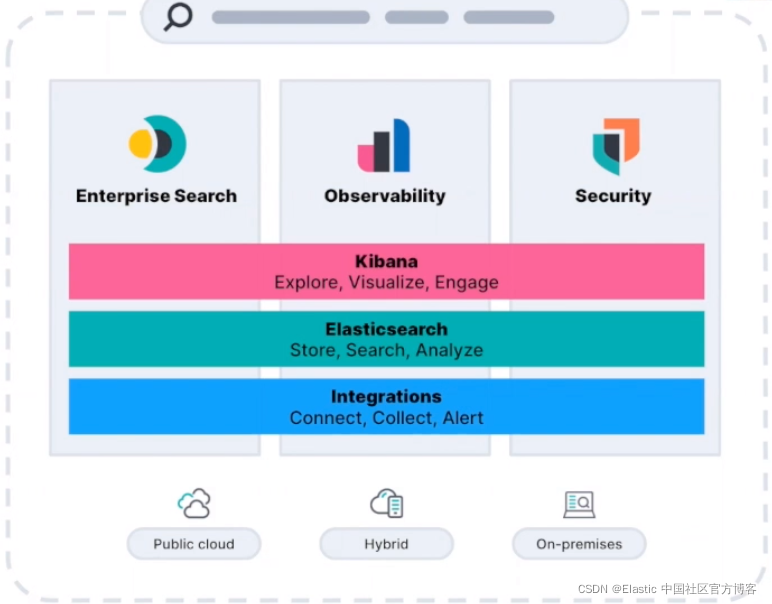
随着 Elastic Stack 的发展,在最新的发布中,Elastic 引入 integrations 来采集数据。Elastic Agent 可以被安装于采集端采集数据,并可以在 Kibana 中对采集端进行集中管理:
Elastic Stack 简介及 7.x 安装
Elastic Stack 8.0 安装介绍
在全世界范围内有非常多的公司在使用 Elastic Stack。它们分布在不同的领域:

你可以在 Elastic 的官方地址找到更多的关于客户的信息。
在今天的这篇文章中,我来简单地介绍一下什么是 Elasticsearch。
Elastic is a Search Company
Elasticsearch 能做什么?
Elasticsearch 的速度和可扩展性及其为多种类型的内容编制索引的能力意味着它可用于多种用例:
- 应用搜索,比如我们常见的 github,linkedin,滴滴,美团,抖音,点评,音乐,视频,银行,证券,保险,电信 app 里的搜索
- 网站搜索
- 企业搜索
- 日志记录和日志分析
- 基础设施指标和容器监控
- 应用性能监控
- 地理空间数据分析和可视化
- 安全分析
- 商业分析
Elastic 产品生态
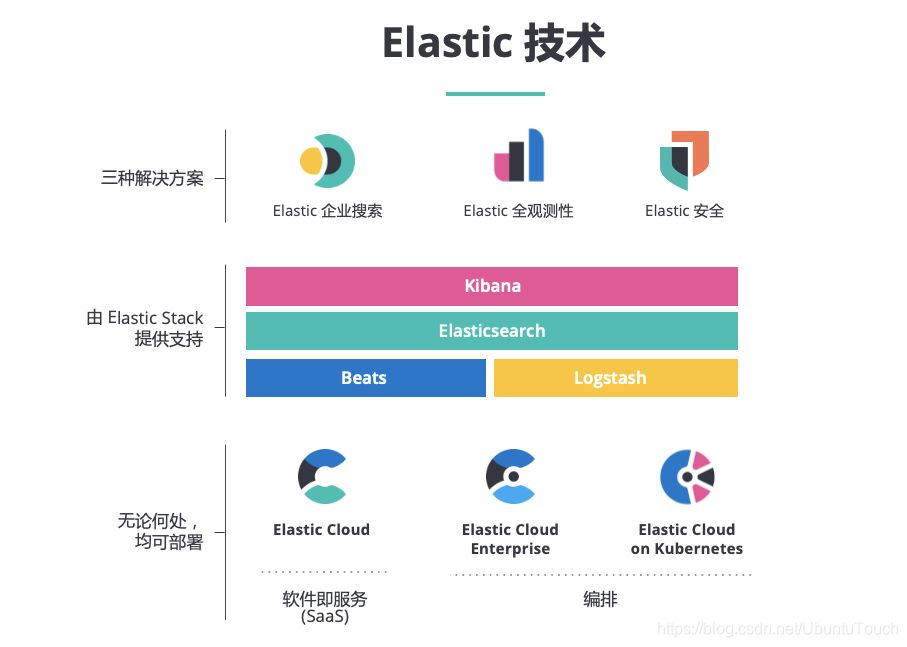
Elastic 围绕 Elasticsearch 已经建立了许多成熟的方案。更多详情请参阅我们的官方网站 Free and Open Search: The Creators of Elasticsearch, ELK & Kibana | Elastic。
Power of Search - 60 sec
Power of Search - 60 sec_哔哩哔哩_bilibili
Elasticsearch
简单地说, Elasticsearch 是一个分布式的使用 REST 接口的搜索引擎。它的产品可以在Elasticsearch: The Official Distributed Search & Analytics Engine | Elastic 进行下载。Elasticsearch 是一个分布式的基于 REST 接口的为云而设计的搜索引擎,它的功能包括:
Elasticsearch是一个基于 Apache Lucene (TM)的开源搜索引擎。无论在开源还是专有领域,Lucene 可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。在 1999 年,Doug Cutting 创建了一个叫做 Lucene 的开源项目:
- 一个完全用 Java 编写的搜索引擎库
- 截止 2005 年,是一个顶级的 Apache 开源项目
- 提供强大的全文搜索功能
但是,Lucene 只是一个库。Lucene 本身并不提供高可用性及分布式部署。想要发挥其强大的作用,你需使用 Java 并要将其集成到你的应用中。Lucene 非常复杂,你需要深入的了解检索相关知识来理解它是如何工作的。
Elasticsearch 始于一个食谱应用。早在 2000 年,在伦敦的一间公寓里,谢伊·班农 (Shay Banon,也就是 Elastic 现在的 CTO) 正在找工作,而他的妻子则在蓝带国际学院 (Le Cordon Bleu) 上烹饪学校。 在业余时间,他开始为他不断增加的食谱列表构建一个搜索引擎。在 2004年,他的第一个迭代称为 Compass。反映令人印象深刻。 用户自然而轻松地接受了它。 使用它的人员飙升,一个社区开始形成。
Compass 是这样的一个项目:
- 构建于 Lucence 之上
- 目的是使得 Lucene 搜索更容易集成到 Java 应用中去
- 可扩展性变得尤为重要
在 2010 年,Shay 完全重新编写了 Compass 以实现如下的两个目的:
- 从一开始设计之初,分布式部署贯穿整个设计
- 可方便地使用其它的语言进行对接使用
Shay 最终把这个项目称之为 Elasticsearch,并于当年10月发布与 github 上。如果你对 Elasticsearch 的历史更感兴趣的话,请阅读另外一篇我同事写的文章 “Elasticsearch 的前世今生”。
人们注意到了 Elasticsearch —— 特别是 Steven Schuurman、Uri Boness 及 Simon Willnauer。 他们和 Shay 一起创立了一家搜索公司 Elastic。现在很多开发者人都知道 ES 及 ELK,但是很多人很少知道 Elastic 是这个软件栈后面的商业公司。

Elasticsearch 也是使用 Java 编写并使用 Lucene 来建立索引并实现搜索功能,但是它的目的是通过简单连贯的 RESTful API 让全文搜索变得简单并隐藏 Lucene 的复杂性。
不过,Elasticsearch 不仅仅是 Lucene 和全文搜索引擎,它还提供:
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 实时分析的分布式搜索引擎
- 可以扩展到上百台服务器,处理 PB 级结构化或非结构化数据
而且,所有的这些功能被集成到一台服务器,你的应用可以通过简单的 RESTful API、各种语言的客户端甚至命令行与之交互。上手 Elasticsearch 非常简单,它提供了许多合理的缺省值,并对初学者隐藏了复杂的搜索引擎理论。它开箱即用(安装即可使用),只需很少的学习既可在生产环境中使用。Elasticsearch 在 Elastic V2 及 SSPL 下许可使用,可以免费下载、使用和修改。 随着知识的积累,你可以根据不同的问题领域定制 Elasticsearch 的高级特性,这一切都是可配置的,并且配置非常灵活。
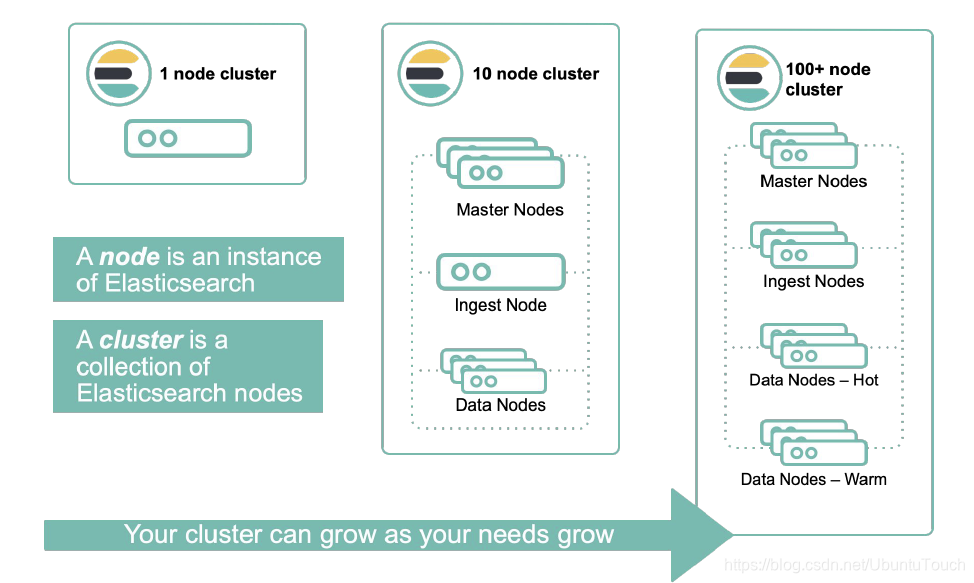
Elasticsearch 的特点是它提供了一个极速的搜索体验。这源于它的高速(speed)。相比较其它的一些大数据引擎,Elasticsearch 可以实现秒级的搜索,但是对于它们来说,可能需要数小时或更长才能完成。Elasticsearch 的 cluster 是一种分布式的部署,极易扩展(scale)。这样很容易使它处理 petabytes 的数据库容量。最重要的是 Elasticsearch 是它搜索的结果可以按照分数进行排序,它能提供我们最相关的搜索结果(relevance)。我们可以依据自己的业务场景有正对性地进行 relevance 定制。
分布式及高可用性的搜素引擎
- 每个索引(index)都使用可配置数量的分片进行完全分片
- 每个分片都可以有一个或多个副本
- 在任何副本分片上可执行读取/搜索操作
多租户
- 支持多个索引
- 索引级别配置(分片数,索引存储,......)
各种API
- HTTP RESTful API
- Native Java API
- 所有 API 都执行自动节点操作重新路由
面向文档
- 无需前期定义 schema (文档结构)
- 可以定义 schema 以定制索引过程
可靠,异步写入,可实现长期持续性
(近)实时搜索
建在 Lucene 之上
- 每个分片都是一个功能齐全的 Lucene 索引
- Lucene 的所有功能都可以通过简单的配置/插件轻松暴露出来
每次操作一致性
- 单文档级操作具有原子性,一致性,隔离性和持久性。
入门指南
首先,不要恐慌。 获得 Elasticsearch 的全部内容需要 5 分钟。
前提要求
你需要在你的电脑上安装最新的 Java(在最新的版本中,Java 可以不用安装,因为在安装包中已经含有 Java 的安装包)。你可查看 setup 链接得到更多的信息。
安装
- 你可以到链接 Download 里去下载 Elasticsearch 最新的发布版。可以参考文档 “Elastic:开发者上手指南” 来安装 Elasticsearch
- 在 Unix/Linux上运行 bin/elasticsearch,或在 Windows 上运行 bin\elasticsearch.bat
- 运行 curl -X GET http://localhost:9200。你在 Windows 上可以安装 cygwin 来运行 curl 指令
- 运行更多的服务器...

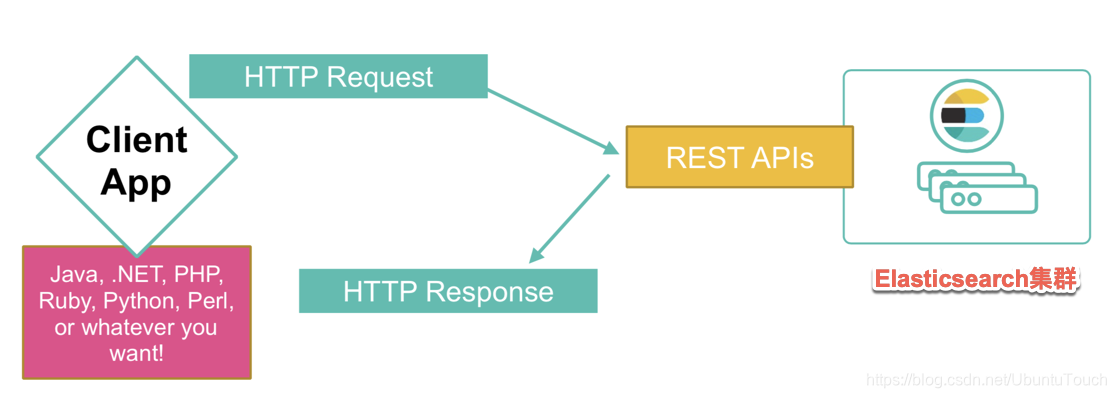
使用 cURL 命令和 Elasticsearch 对话
我们可以使用 cURL 将请求从命令行提交到本地 Elasticsearch 实例。对 Elasticsearch 的请求包含与任何 HTTP 请求相同的部分:
curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'本示例使用以下变量:
- <VERB> :适当的 HTTP 方法或动词。 例如,GET,POST,PUT,HEAD 或 DELETE
- <PROTOCOL>:http 或 https。 如果你在 Elasticsearch 前面有一个 HTTPS 代理,或者你使用 Elasticsearch 安全功能来加密 HTTP 通信,请使用后者
- <HOST>:Elasticsearch 集群中任何节点的主机名。 或者,将 localhost 用于本地计算机上的节点
- <PORT>:运行 Elasticsearch HTTP 服务的端口,默认为 9200
- <PATH>:API 端点,可以包含多个组件,例如 _cluster/stats 或 _nodes/stats/jvm
- <QUERY_STRING>:任何可选的查询字符串参数。 例如,?pretty 将漂亮地打印 JSON 响应以使其更易于阅读
- <BODY>:JSON 编码的请求正文(如有必要)
如果启用了 Elasticsearch 安全功能,则还必须提供有权运行 API 的有效用户名(和密码)。 例如,使用 -u 或 --u cURL 命令参数。比如:
curl -u elastic:password -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'这里的 elastic 及 password 代表用超级用户名 elastic 及其密码。
检查 Elasticsearch 是否正确安装好
如果你对 Postman 比较熟悉,请参阅我的文章 “Elastic:使用 Postman 来访问 Elastic Stack” 来做如下的练习。
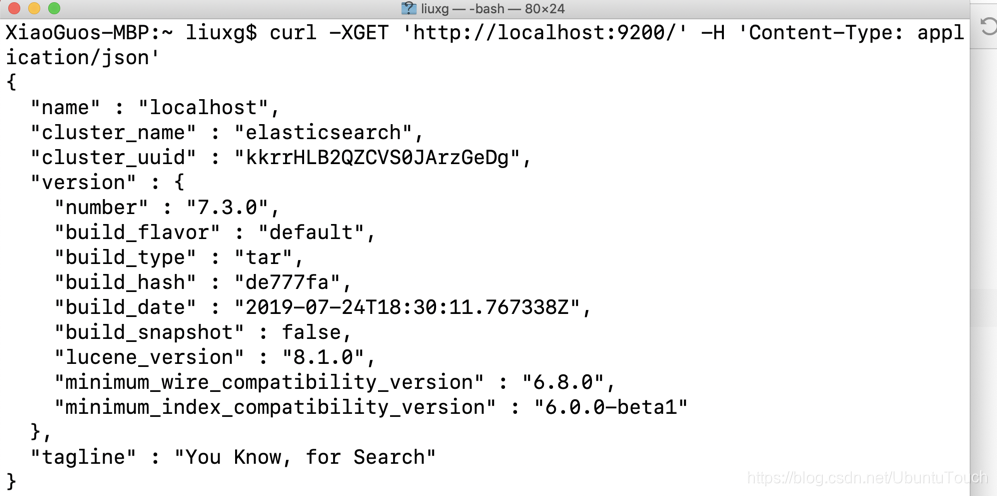
在我们的 terminal上我们可以打人如下的命令:
$ curl -XGET 'http://localhost:9200/' -H 'Content-Type: application/json'如果你看到如下的内容,表面我们的 Elasticsearch 已经安装正确:
如果你在 Elasticsearch 中启动了最基本的安全,那么我们可以通过如下的命令来做这个:
$ curl -XGET -u "elastic:changeme" 'http://localhost:9200/' -H 'Content-Type: application/json'这里 -u 选项可以帮我们设置用户名及密码来访问 Elasticsearch。
建立索引(Index)
对于经常看 Elastic 英文官方文档的开发者来说,我们经常会看到 index 这个词。在英文中,它即可以做动词,表示建立索引的意思,但同时它也用作名词,称作索引。很多刚开始学习 Elasticsearch 的开发者有时有点弄不明白。
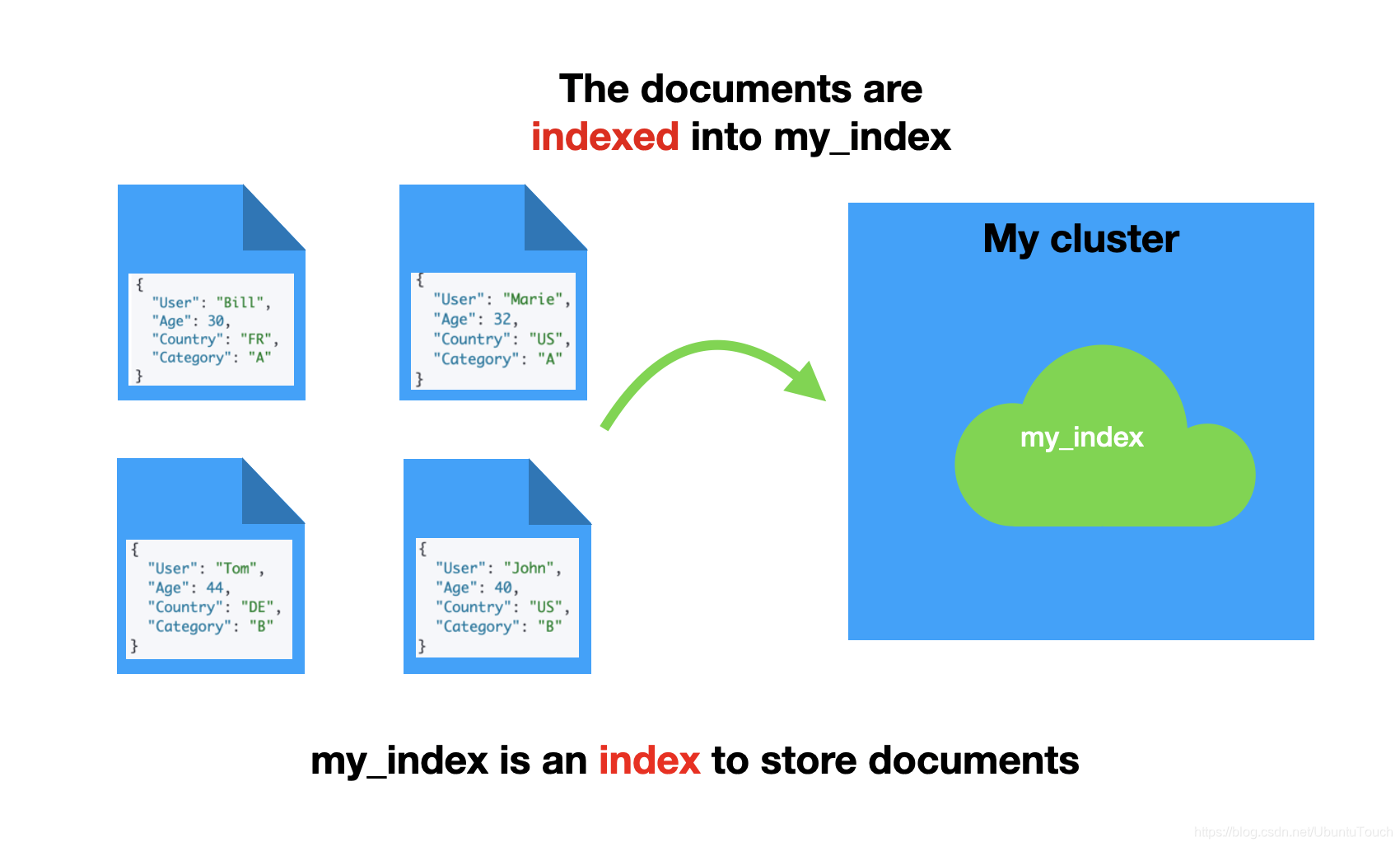
让我们尝试索引一些类似于 Twitter 的信息。 首先,让我们索引一些推文(将自动创建 twitter 索引):
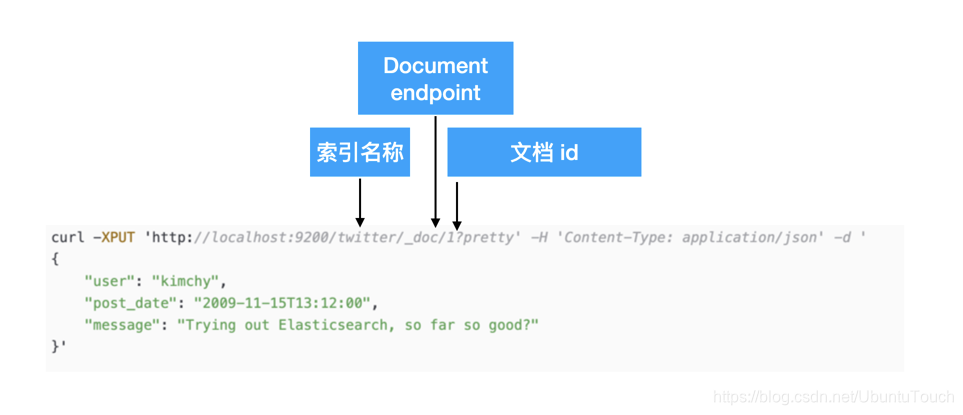
- curl -XPUT 'http://localhost:9200/twitter/_doc/1?pretty' -H 'Content-Type: application/json' -d '
- {
- "user": "kimchy",
- "post_date": "2009-11-15T13:12:00",
- "message": "Trying out Elasticsearch, so far so good?"
- }'
-
- curl -XPUT 'http://localhost:9200/twitter/_doc/2?pretty' -H 'Content-Type: application/json' -d '
- {
- "user": "kimchy",
- "post_date": "2009-11-15T14:12:12",
- "message": "Another tweet, will it be indexed?"
- }'
-
- curl -XPUT 'http://localhost:9200/twitter/_doc/3?pretty' -H 'Content-Type: application/json' -d '
- {
- "user": "elastic",
- "post_date": "2010-01-15T01:46:38",
- "message": "Building the site, should be kewl"
- }'

现在,让我们检查一下上面的信息是否已经通过我上面的操作加入到索引里。我们可以通过 GET 来查询:
- curl -XGET 'http://localhost:9200/twitter/_doc/1?pretty=true'
- curl -XGET 'http://localhost:9200/twitter/_doc/2?pretty=true'
- curl -XGET 'http://localhost:9200/twitter/_doc/3?pretty=true'
搜索
让我们找到 kimchy 发布的所有推文:
curl -XGET 'http://localhost:9200/twitter/_search?q=user:kimchy&pretty=true'我们还可以使用 Elasticsearch 提供的 JSON 查询语言而不是查询字符串:
- curl -XGET 'http://localhost:9200/twitter/_search?pretty=true' -H 'Content-Type: application/json' -d '
- {
- "query" : {
- "match" : { "user": "kimchy" }
- }
- }'
上面的查询将会显示所有的由 kimchy 发布的所有 tweet。为了好玩,让我们来得到所有的存储的文档(document) (我们可以看到由用户 elastic 发布的所有的 tweet).
- curl -XGET 'http://localhost:9200/twitter/_search?pretty=true' -H 'Content-Type: application/json' -d '
- {
- "query" : {
- "match_all" : {}
- }
- }'
我们也可以做一个范围里的搜索(刚才上面的那个 post_date 在建立索引的时候已经自动被识别为 date 类型)
- curl -XGET 'http://localhost:9200/twitter/_search?pretty=true' -H 'Content-Type: application/json' -d '
- {
- "query" : {
- "range" : {
- "post_date" : { "from" : "2009-11-15T13:00:00", "to" : "2009-11-15T14:00:00" }
- }
- }
- }'
还有更多的选项可以执行搜索,毕竟,这是一个搜索产品吗? 所有熟悉的 Lucene 查询都可以通过 JSON 查询语言或查询解析器获得。
多租户 - 索引和类型
伙计,那个 twitter 索引可能会变大(在这种情况下,索引大小 == 估值)。 让我们看看我们是否可以稍微改变我们的 tweet 系统,以支持如此大量的数据。
Elasticsearch 支持多个索引。 在前面的示例中,我们使用了一个名为 twitter 的索引,该索引为每个用户存储了推文。
定义我们简单的推特系统的另一种方法是为每个用户提供不同的索引(注意,尽管每个索引都有开销)。 这是这种情况下的索引 curl:
- curl -XPUT 'http://localhost:9200/kimchy/_doc/1?pretty' -H 'Content-Type: application/json' -d '
- {
- "user": "kimchy",
- "post_date": "2009-11-15T13:12:00",
- "message": "Trying out Elasticsearch, so far so good?"
- }'
-
- curl -XPUT 'http://localhost:9200/kimchy/_doc/2?pretty' -H 'Content-Type: application/json' -d '
- {
- "user": "kimchy",
- "post_date": "2009-11-15T14:12:12",
- "message": "Another tweet, will it be indexed?"
- }'
以上将索引信息到 kimchy 索引中。 每个用户都将获得自己的特殊索引。
允许完全控制索引级别。 例如,在上面的情况中,我们可能希望从每个索引1个副本的默认1分片更改为每个索引1个副本的2个分片(因为此用户推文很多)。 以下是如何做到这一点(配置也可以是在 yaml 文件里配置):
- curl -XPUT http://localhost:9200/another_user?pretty -H 'Content-Type: application/json' -d '
- {
- "settings" : {
- "index.number_of_shards" : 2,
- "index.number_of_replicas" : 1
- }
- }'
搜索(和类似操作)具有多索引感知功能。 这意味着我们可以轻松搜索多个 index(twitter 用户),例如:
- curl -XGET 'http://localhost:9200/kimchy,another_user/_search?pretty=true' -H 'Content-Type: application/json' -d '
- {
- "query" : {
- "match_all" : {}
- }
- }'
或者在所有的索引(index)里进行搜索:
- curl -XGET 'http://localhost:9200/_search?pretty=true' -H 'Content-Type: application/json' -d '
- {
- "query" : {
- "match_all" : {}
- }
- }'
{One liner teaser}:关于那个很酷的部分? 你可以轻松搜索多个 Twitter 用户(索引),每个用户具有不同的提升级别(索引),使社交搜索变得更加简单(我朋友的结果排名高于我朋友的朋友的结果)。
分布式,高度可用
Elasticsearch 是一个高度可用的分布式搜索引擎。每个索引都分解为分片(shard),每个分片可以有一个或多个副本。默认情况下,创建一个索引,每个分片有1个分片和1个副本(1/1)。可以使用许多拓扑,包括1/10(提高搜索性能,多个副本可以帮我们提高搜索的速度)或20/1(提高索引性能,多个主分片可以帮我们提高导入数据的速度)。
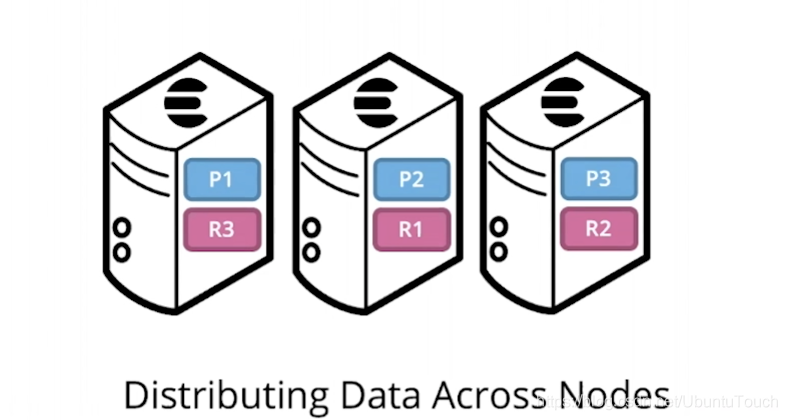
为了使用 Elasticsearch 的分布式特性,只需启动更多节点并关闭节点。系统将继续为索引的最新数据提供请求(确保使用正确的 HTTP 端口)。
在哪些时候 Elasticsearch 可能不是正确的工具?
了解 Elasticsearch 的局限性也很重要。本节介绍在某些情况下,单独使用 Elasticsearch 可能不是完成这项工作的最佳工具。
处理关系数据集
与 MySQL 等数据库不同,Elasticsearch 并非旨在处理关系数据。 Elasticsearch 允许你在数据中建立简单的关系,例如父子关系和嵌套关系,但会降低性能(分别在搜索时间和索引时间)。必须对 Elasticsearch 上的数据进行非规范化(在文档中复制或添加冗余字段,以避免必须加入数据)以改进搜索和
索引/更新性能。
如果你需要让数据库管理关系并在不同类型的链接数据之间强制执行一致性规则,以及维护规范化的数据记录,那么 Elasticsearch 可能不是适合这项工作的工具。
执行 ACID 事务
Elasticsearch 中的单个请求支持 ACID 属性。 但是 Elasticsearch 没有事务的概念,所以不提供 ACID 事务。
在单个请求级别,ACID 属性可以实现如下:
- Atomictiy 是通过发送写入请求来实现的,该请求将在所有活动分片上成功或失败。请求无法部分成功。
- 通过写入主分片来实现 Consistency。数据复制在返回成功响应之前同步发生。这意味着在写入请求之后所有分片上的所有读取请求都将看到相同的响应。
- 提供 Isolation,因为可以成功处理并发写入或更新(即删除和写入)而不受任何干扰。
- 实现了 Durability,因为一旦将文档写入 Elasticsearch,它就会持续存在,即使在系统发生故障的情况下也是如此。 Elasticsearch 上的写入不会立即持久化到磁盘上的 Lucene 段,因为 Lucene 提交是相对昂贵的操作。相反,文档被写入事务日志(称为 translog)并定期刷新到磁盘中。如果一个节点在数据刷新之前崩溃了,translog 中的操作将在启动时恢复到 Lucene 索引中。
如果 ACID 事务对你的用例很重要,那么 Elasticsearch 可能不适合你。有关 Elasticsearch 和其他传统数据库的比较,请参阅文章 “Elasticsearch 对比传统数据库:深入挖掘 Elasticsearch 的优势”。
重要提示:在关系数据或 ACID 事务需求的情况下,Elasticsearch 通常与传统的 RDBMS 解决方案(如 MySQL)一起使用。 在这样的架构中,RDBMS 将充当事实来源并处理来自应用程序的写入/更新。 然后可以使用 Logstash 等工具将这些更新复制到 Elasticsearch,以进行快速/相关搜索和可视化/分析用例。关于这个用例,你可以阅读文章 “Logstash:如何使用 Logstash 和 JDBC 确保 Elasticsearch 与关系型数据库保持同步”。
我们将从哪里开始呢?
我们刚刚介绍了 Elasticsearch 的一小部分内容。有关更多信息,请参阅 elastic.co 网站。一般问题可以在 elastic论坛 上或在#elasticsearch 的 Freenode 上的 IRC 上询问。 Elasticsearch GitHub 存储库仅用于错误报告和功能请求。
从 Source 构建
Elasticsearch 使用 Gradle 作为其构建系统。
要创建分发,只需在克隆目录中运行 ./gradlew 汇编命令。
将在该项目的 build/distributions 目录下创建每个项目的分发。
有关运行 Elasticsearch 测试套件的更多信息,请参阅 TESTING 文件。
从旧的 Elasticsearch 版本升级
为了确保从早期版本的 Elasticsearch 顺利升级过程,请参阅我们的升级文档以获取有关升级过程的更多详细信息。
下一步
如果你很想使用 Elastic 的 Kibana 来进行进行索引的操作,请参阅我的文章:

