
- 1〖ChatGPT实践指南 - 零基础扫盲篇③〗- 学术探讨:如何获取 OpenAI 的 API keys_不渴望力量的哈士奇
- 2关于Django静态文件路径设置规则的精炼总结_django static文件规范
- 3tf.math.reduce_mean和tf.keras.metrics.Mean的区别是什么,区别在于记不记忆之前的状态_tf.metrics.mean()
- 4Golang起步篇(Windows、Linux、mac三种系统安装配置go环境以及IDE推荐以及入门语法详细释义)_golang安装
- 5Unity3D 2D贴图 与 帧动画_unity中绘制贴图的方法是gui什么?
- 6【超简易安装】在linux集群服务器上使用conda安装高版本cuda(cuda-11.8)和pytorch2.0_cuda 11.8安装
- 7【云上探索实验室】快速入门AI 编程助手 Amazon CodeWhisperer ——码上学堂领学员招募
- 8Python机器学习库sklearn几种回归算法建模及分析(实验)_sklearn中都有哪些回归算法regression
- 9基于微信小程序的体育场馆预约系统的设计与实现_基于微信小程序的体育馆场地预约系统的设计与实现项目网络图
- 10unity5.x Translate平移移动 以及GetComponent获取组件_unitytranslate
读论文:数据驱动和知识感知可解释人工智能综述 A Survey of Data-Driven and Knowledge-Aware eXplainable AI
赞
踩
标题: 数据驱动和知识感知可解释人工智能综述
作者: Xiao-Hui Li , Caleb Chen Cao, Yuhan Shi, Wei Bai, Han Gao, Luyu Qiu, Cong Wang, Yuanyuan Gao,Shenjia Zhang, Xun Xue, and Lei Chen.
Abstract
虽然人工智能(AI)在近些年来有着飞速发展。但解释AI并不是一件容易的事情。为此,提出这项了调查,从数据和知识工程(DKE)的角度对现有的工作进行分类:首先,将方法分为数据驱动方法和知识感知方法,其中数据驱动方法的解释来自与任务相关的数据,而知识感知方法则包含外部知识;此外,根据实践,本文提供了最先进的评估指标调查,并在工业实践中部署了解释应用程序
关键词——可解释人工智能(XAI)、算法、深度学习、知识库、指标
Introduction
人工智能(AI)技术:
以机器学习为动力,在许多应用领域有着跨时代性的作用。随着时代的发展,AI在实际应用中展现出如下的优缺点:
优点:
●AI在“计算机视觉(CV)”取得了极大的进步,例如:ImageNet图像分类挑战等;
●AI在和“深度学习(DL)”取得了极大的进步,例如:COCO目标检测挑战,“视觉问答”和“机器翻译”等。
缺点:
◆AI模型大多建立在极其复杂的非线性函数上,如深度神经网络(DNNs),通常包含数百万个参数;
◆这些高度非线性和复杂性的模型使其成为“黑盒”——即人类难以理解其内部的工作机制和决策过程。进而导致人类难以判断其决策是否正确。
可解释人工智能(XAI):
因此,在过去的几年中,XAI已成为学术界的一个重要和热门的研究方向,主要分为三种:
(i) 方法论——开发更优越的方法来解释黑箱模型;
(ii)评估——设计评估解释有效性的方法或定义衡量标准;
(iii)应用–在实际任务中应用XAI。
虽然对XAI的评估至关重要,但只有少数调查对评估方法进行了审查。根据人和任务,将评估方法分为三种类型,即应用全面评估、基于人的评估和基于功能的评估。此外,还提出了一些属性(如可理解性、简洁性、完整性),这些属性可能是评估过程中的重要指标。XAI的应用仍处于初级阶段,然而,有几项调查展示了不同社会场景下的玩具示例,例如运输、销售、财务、人力资源和健康。还提到使用一种或多种XAI方法的软件。
综述
一、 数据驱动的可解释人工智能 DATA-DRIVEN EXPLAINABLE AI
定义:不依赖先验知识等外部信息,仅从数据中生成解释的方法。
常用方法:
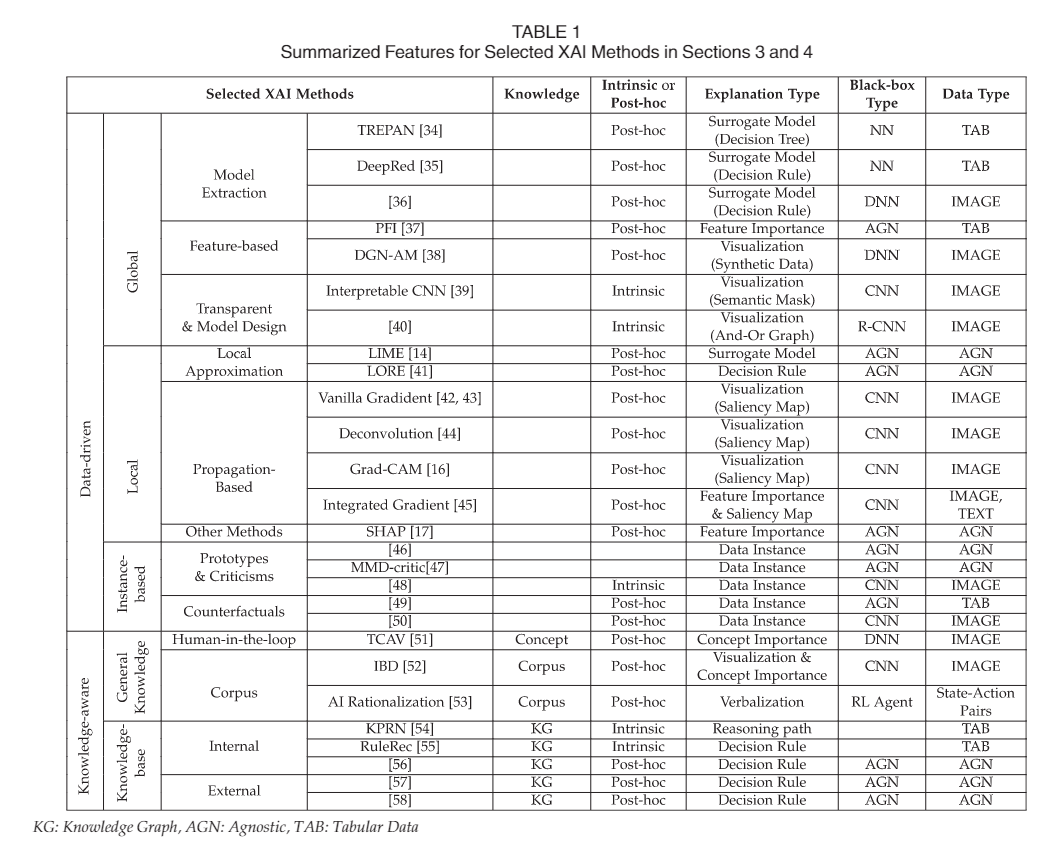
- 全局方法Global Methods:旨在提供对模型逻辑的理解,以及对所有预测的完整推理,基于对其特征、学习过的组件和结构等的整体观点,具体方法有:学习XAI模型来代替黑盒模型的“模型提取”、“通过提取的模型提供全局解释”以及通过修改或重新设计模型来提高可解释性的“透明模型设计”;
缺点:虽然提供了黑盒模型的透明视图,但在实践中,构建大规模复杂模型的忠实近似和从整个输入分布中提取一般显著模式仍然具有挑战性。在为单个观测结果生成解释时,全局解释也缺乏局部保真度,因为全局重要特征可能无法精确解释单个实例的决定。 - 局部办法Local Methods:试图证明单个实例或一组实例的模型行为,而不是给出黑盒模型内部不透明机制的完整描述。其中包含通过使用与给定实例相关的子数据集进行训练 来模拟复杂模型的“局部近似“方法以及”基于传播的方法“;
缺点:局部区域中的行为可能很复杂,需要大量的参数才能实现忠实性,从而导致无法理解的代理模型。 - 基于实例的方法 Instance-Based Methods:选择或生成数据集的特定实例,以深入了解数据集或解释黑盒模型。其中包含了使用真实数据实例解释数据集分布的“原型和批评”以及通过搜索或生成具有不同特征值的一些实例来解释预测,这些特征值将预测更改为预定义输出的“反事实解释”两种解释方法。
缺点:常用模型不可知和数据类型不可知的平均最大差异评论家(MMD-critic)。然而,选择原型和批评的数量也是一个难以抉择的问题。此外,结果对核函数的选择很敏感,导致MMD临界性能变得不稳定。
二、知识感知可解释人工智能 KNOWLEDGE-AWARE EXPLAINABLE AI
定义:
利用外部领域知识,不仅可以生成指示特征重要性的解释,还可以描述某些特征比其他特征更重要的原因。
分类:
- 一般知识方法 General Knowledge Methods :XAI方法利用知识的一般格式,没有严格的逻辑要求,不过可以抽象为数值等可测量的解释。常用“人参与”以及“知识库导入和用户友好解释”两种方法。
- 知识库方法 Knowledge-Base Methods:具有结构化和系统化知识的解释方法。该办法运用多个不同角度来进行解释,使其变得更为客观。其常被建模为知识图(KG),而KG有分为内部路径(常用于推荐系统)以及外部路径(提供了利用不同形式外部知识的解释)。
问题:
1.解释得有多好?
2.我们是否能够建立对黑箱模型的忠实理解?
3.我们是否能够信任它们?
三、衡量指标 METRICS
定义:
在用户与机器之间的信赖关系确认前,用户需要验证解释的有效性。为此,人们开发出了各种评估解释的指标。介于使用情况的多样性,不同的指标有着不同的目的。
分类:
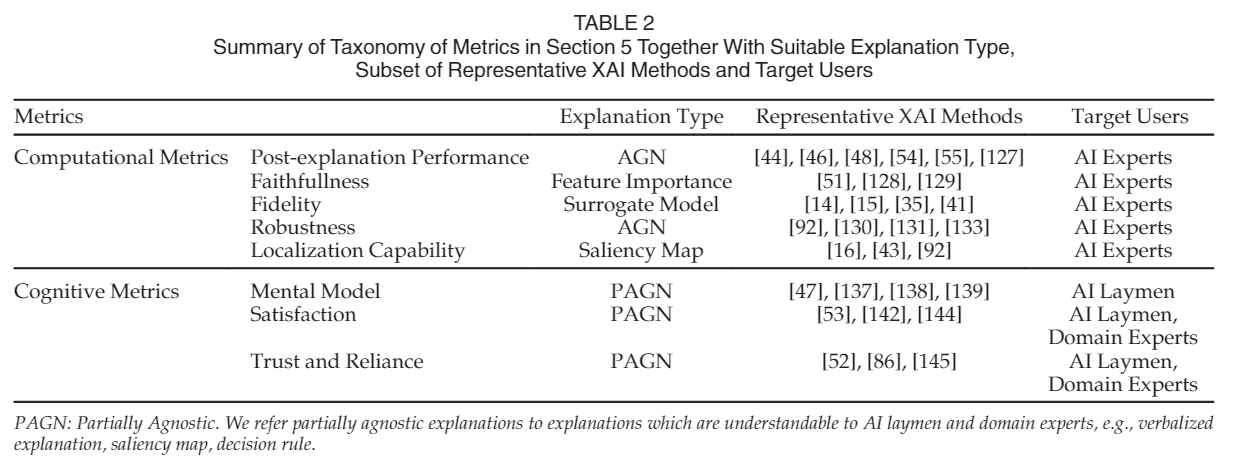
- 计算度量 Computational Metrics:良好”解释的直观标量指标,由于其常会通过已有数据进行合理设计,因此可以作为开发无需人类参与的口译方法的指南,主要针对特定任务或应用。包括:解释后表现Post-Explanation Performance(通过比较调整前后的模型性能来评估解释)、忠诚与保真度Faithfulness and Fidelity(判定解释中的重要特征或概念是否指真正相关的特征)、稳健性 Robustness(解释方法保护其解释免受各种攻击的能力)以及本地化Localization(显著图被视为弱监督的目标本地化参考)等指标;
- 认知指标 Cognitive Metrics:衡量关于人类的解释,该指标通过直接要求参与者从他们的角度辨别更好的解释,概括各种场景。包括:心智模型Mental Model(描述了黑箱模型的机制)以及信任与信赖Trust and Reliance(解释更好的系统应该得到用户更多的信任)等指标。
总结
本文主要从以下三个方面对XAI进行说明:
(i) 方法论 Methodology:基于解释生成过程中是否涉及外部知识,我们提出了一种新的分类法。;
(ii)评估 Ealuation:共有两种分类:计算指标和认知指标;
(iii)应用 Aplication:其实际应用,要通过对于措施的合理解释让人们更加信任XAI。
从本文不难得出,解释过程有多种生成方式,也可以通过局部或者全局方法来生成不同的解释,使其实际使用变得更加灵活;与此同时,对于解释的评估更是用上了认知指标,这也表明了今后的解释不一定就是硬性的,也可以变得更加人性,增强了解释的可信度并更加易于理解。这对于用户来说是一件很不错的事情。
未来展望
首先,对于具有知识意识的XAI来说仍有着十分大的扩展空间。然而,要有效利用外部知识,还有许多未解决的问题。就以人类参与为例,人们总会有着不同领域的各种知识,因此,XAI系统需要引导此人提供所需的知识,而不是无关的知识。
此外,部署XAI系统迫切需要更标准和统一的评估框架。为了达成这一目标,我们可能需要同时利用不同的指标,相互补充。在实际应用时对于不同任务会有着不同的指标,所以统一的评价框架应具有相应的灵活性。
最后,我们相信多学科合作将是有益的。也正是如此,才能让XAI在各个领域都能够灵活运用,来帮助人们做出最好的选择。

