- 1android多个app跨进程通信(IPC)实现(一)_安卓java应用间交互
- 2Unity Shader入门精要 第八章——透明效果_unity 半透明shader
- 3基于Android的过程监控的学生成绩管理系统(Android studio毕业设计,Android课程设计)_as学生成绩管理
- 4java使用elasticsearchClient调用es7.17-生成连接、查询系统参数、索引相关操作_java 8 使用elasticsearchclient调用es
- 5pve虚拟机无法连接到服务器,许迎果 第190期 PVE创建虚拟机的注意事项 上篇
- 6http代理的静态ip如何实现YouTube运营?有何优势?
- 710、App启动过程分析与UIApplication自定义举例_- (bool)application:(uiapplication *)application c
- 8Java案例——实现验证码登陆_java 验证码登录
- 9Unity如何与Webview进行交互_游戏内嵌入web怎么和客户端交互
- 10EC修炼之道—代码架构_如果要学习写ec的程序
pyskl:hrnet+fastercnn+c3d_pyskl batchsize
赞
踩
Posec3d行为识别
一、模型介绍:
/home/centos/xhy/code/pyskl-main/tools/work_dirs/posec3d/c3d_light_gym/joint721_nopretrain/epoch_24.pth
Ps:使用Skeleton的计算量 < 使用RGB的计算量,此实验利用骨骼信息作为实验训练输入对象。
Posec3d算法(PoseC3D 仅使用 2 维人体骨架热图堆叠作为输入,就能达到更好的识别效果。):
PoseC3D 是第一个将 2D 人类骨骼格式化为 3D 体素并使用 3D 卷积神经网络处理人类骨骼的框架。并发布了多个PoseC3D变体,这些变体使用不同的骨干实例化并在不同的数据集上进行训练。

- 对输入的视频进行抽帧,输入的视频长短不一致(1s-5s之间)
- 对每一帧的人物检测,利用官方提供的人物检测模型(mmdetection2下的faster_rcnn_r50_fpn_1x_coco-person_20201216_175929-d022e227.pth)进行人物的检测;
- 对每一帧检测到的人物使用官方mmpose提供的模型(hrnet_w32_coco_256x192-c78dce93_20200708.pth)进行姿态估计;
- 根据每一帧生成的姿态估计关键点(17个关键点左边)。沿着时间维度叠加关节或肢体的热图,并对生成的三维热图体积;
- 应用预处理网络(使用C3D网络)输出预测到的动作;
PoseC3d设计了两个3D-CNNs家族,即姿态模态的PoseConv3D和RGB+姿态双模态的RGBPose-Conv3D。(在本实验中使用单姿态模态的Poseconv3D)
二、网络模型:
osec3d训练模型:使用c3d网络作为backbone加上一个I3DHead的分类头:
具体详细:
1)关键点检测:
对视频抽帧(使用decoder对视频进行均匀抽帧),检测视频帧中的人物,根据视频帧中的人物进行人体关键关键点的检测。
前处理结果包括:
| Key | 备注 | 内容demo |
| Frame_dir | 视频名称 | P05_238975 |
| label | 动作类别标签 | 5 |
| Img_shape | 视频帧的宽高 | (1080,1906) |
| Total_frames | 视频帧数 | 58 |
| Num_person_raw | 视频中人员数量 | 1 |
| keypoint | 17个关键点坐标 | [[[1077,298.5]....]],(17,3)(17个关键点在RGB三通道中的坐标点) |
| Keypoint_score | 17个关键点坐标的score | [[[0.94]....]],(17,3)(17个关键点在RGB三通道中的置信度) |
- 热图生成:
根据根据上述处理结果进行堆叠,堆叠成热图。
![]()
热图输出一共十七个关键点,每一个关键点一个channel,格式为(C,T,H,W)(N为设置的batch_size数32,T为设置的clip_len为32,即随机抽取32帧,H,W设置为56),即(32,17,32,56,56).
3)送入C3D网络:
Input:NCHW(17,32,56,56),(17个通道数,32帧,56x56的大小),C3D训练使用3个stage,base_channel为32。
- 分类头:
使用CrossEntropyLoss作为损失函数+nn.leaner(in:255,out:6),输出为每个动作的预测概率。
| (loss_cls): CrossEntropyLoss() (dropout): Dropout(p=0.5, inplace=False) (fc_cls): Linear(in_features=256, out_features=6, bias=True) |
三、实验过程:
3.1、数据集制作:
划分训练集和测试集
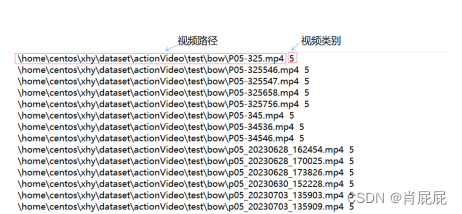
新建txt的标注文档:
| dir /s/b *.mp4 >label_text.txt |
添加类别:
| import os dir_name="F:\poseC3D\\actionVideo\\label_list.txt" f = open(dir_name,encoding="utf-8") date = f.readlines() with open('label_list.txt', 'w') as f1: for dataline in date: dataline =dataline.strip('\n') if "sleep" in dataline: dataline=dataline+" 2\n" if "PlayPhone" in dataline: dataline = dataline + " 4\n" if "delivery" in dataline: dataline = dataline + " 3\n" if "greet" in dataline: dataline = dataline + " 1\n" if "bow" in dataline: dataline = dataline + " 5\n" print(dataline) if "other" in dataline: dataline = dataline + " 0\n" print(dataline) f1.writelines(dataline) |
标注文档txt内容:
3.2、环境搭建:
方法一:
要配置该算法的环境,最好先配置好MMDetection的环境,根据官网给的安装教程。另外要注意安装mmcv、mmcv-full、mmdet和mmpose,版本不能太高,如果安装了最新的版本会报无法编译,安装版本,
mmcv=1.3.18,mmcv-full=1.3.18, mmdet=2.23.0, mmpose=0.24.0
Ps:mmcv-full安装要根据对应的cuda版本和torch版本。
安装MMDetection的时候,需要把Detectron2也装一下,使用官网的命令行安装就可以了,安装命令:
python -m pip install 'git+https://github.com/facebookresearch/detectron2.git'
这样在使用下面的命令安装和编译就没有问题了。
git clone https://github.com/kennymckormick/pyskl.git
cd pyskl
# Please first install pytorch according to instructions on the official website: https://pytorch.org/get-started/locally/. Please use pytorch with version smaller than 1.11.0 and larger (or equal) than 1.5.0
pip install -r requirements.txt
pip install -e .
环境配置完,最好跑一下提供的demo。
| python demo/demo_skeleton.py demo/ntu_sample.avi demo/demo.mp4 |
输出了视频结果,那么就Ok了。
方法二:
| git clone https://github.com/kennymckormick/pyskl.git cd pyskl # This command runs well with conda 22.9.0, if you are running an early conda version and got some errors, try to update your conda first conda env create -f pyskl.yaml conda activate pyskl pip install -e . |
3.3、数据处理:
需要对官方提供的提取关键点的代码进行修改:
| 生成的pkl文件包括: frame_dir,label,img_shape,original_shape,total_frames,num_person_raw,kaypoint,keypoint_score.
|

3.4、修改配置文件:
训练文件配置,使用posec3d算法,修改configs/posec3d/c3d_light_gym/joint.py:
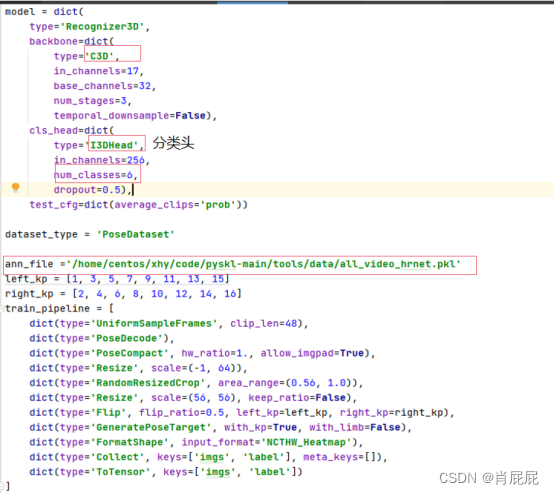
参数设置:
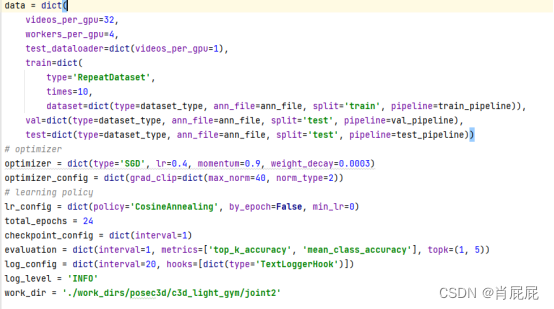
四、实验结果:
实验一:(未添加other类)
训练结果:
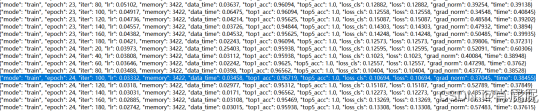
测试结果:
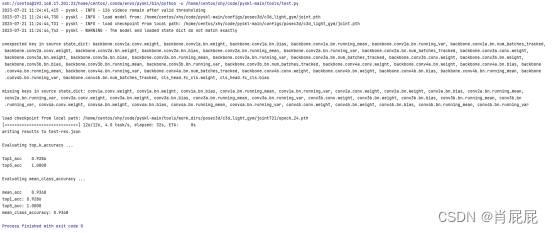
| 2023-07-12 10:52:34,697 - pyskl - INFO - 124 videos remain after valid thresholding Evaluating top_k_accuracy ... top1_acc 0.7419 top5_acc 1.0000 Evaluating mean_class_accuracy ... mean_acc 0.7556 top1_acc: 0.7419 top5_acc: 1.0000 mean_class_accuracy: 0.7556 |
实验二:(添加other类)
测试结果:
| 2023-07-12 13:21:58,070 - pyskl - INFO - 146 videos remain after valid thresholding Evaluating top_k_accuracy ... top1_acc 0.7123 top5_acc 0.9726 Evaluating mean_class_accuracy ... mean_acc 0.6642 top1_acc: 0.7123 top5_acc: 0.9726 mean_class_accuracy: 0.6642 |
实验三:(重新扩充数据集,并清洗数据集,训练集997个视频,测试集126个视频)