
- 1web服务器(Tomcat & Servlet)
- 2paho-mqtt-c交叉编译_paho-mqtt c
- 3Java---抽象类和接口_java 抽象类和抽象接口
- 4【安装Anaconda3 + Tensorflow + Keras + Jupyter笔记本】_检查keras是否已经安装
- 5手把手教你用 Github Actions 部署前端项目
- 6python基础学习_pathy基础学习
- 7tomcat漏洞扫描,tomcat隐藏版本号,处理ajp漏洞
- 8送快递的最短路径_物流派送员送快递最短路径
- 9【Linux取经路】冯诺依曼结构体系与操作系统的碰撞_冯诺依曼体系结构确定改进技术
- 10HTTP Strict Transport Security (通常简称为HSTS)_strict-transport-security
用通俗的方法讲解:大模型微调训练详细说明(附理论+实践代码)_微调大模型怎么学习
赞
踩
本文内容如下
-
介绍了大模型训练的微调方法,包括prompt tuning、prefix tuning、LoRA、p-tuning和AdaLoRA等。
-
介绍了使用deepspeed和LoRA进行大模型训练的相关代码。
-
给出了petals的介绍,它可以将模型划分为多个块,每个用户的机器负责其中一块,分摊了计算压力。
理解篇
prompt tuning
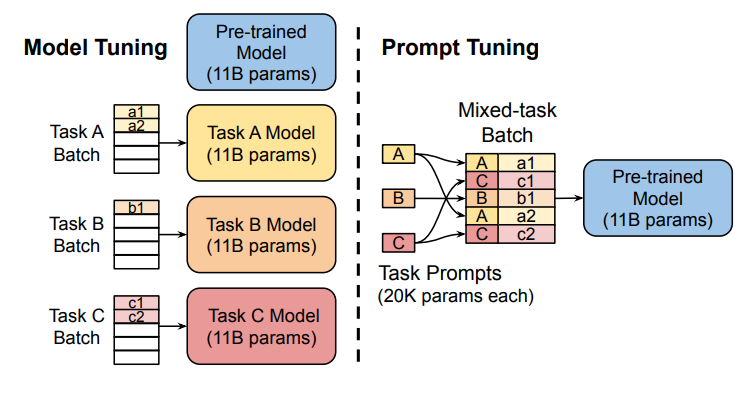
固定预训练参数,为每一个任务额外添加一个或多个embedding,之后拼接query正常输入LLM,并只训练这些embedding。左图为单任务全参数微调,右图为prompt tuning。
-
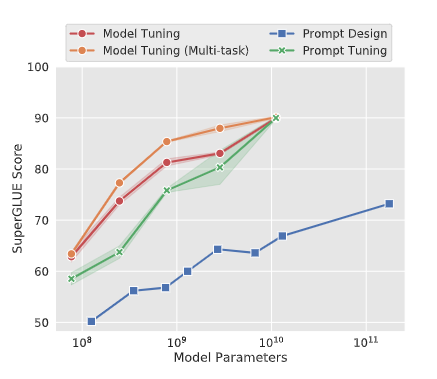
标准的T5模型(橙色线)多任务微调实现了强大的性能,但需要为每个任务存储单独的模型副本。
-
prompt tuning也会随着参数量增大而效果变好,同时使得单个冻结模型可重复使用于所有任务。
-
显著优于使用GPT-3进行fewshot prompt设计。
-
当参数达到100亿规模与全参数微调方式效果无异。
代码样例:
from peft import PromptTuningConfig, get_peft_model
peft_config = PromptTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=10)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
- 1
- 2
- 3
- 4
prefix tuning
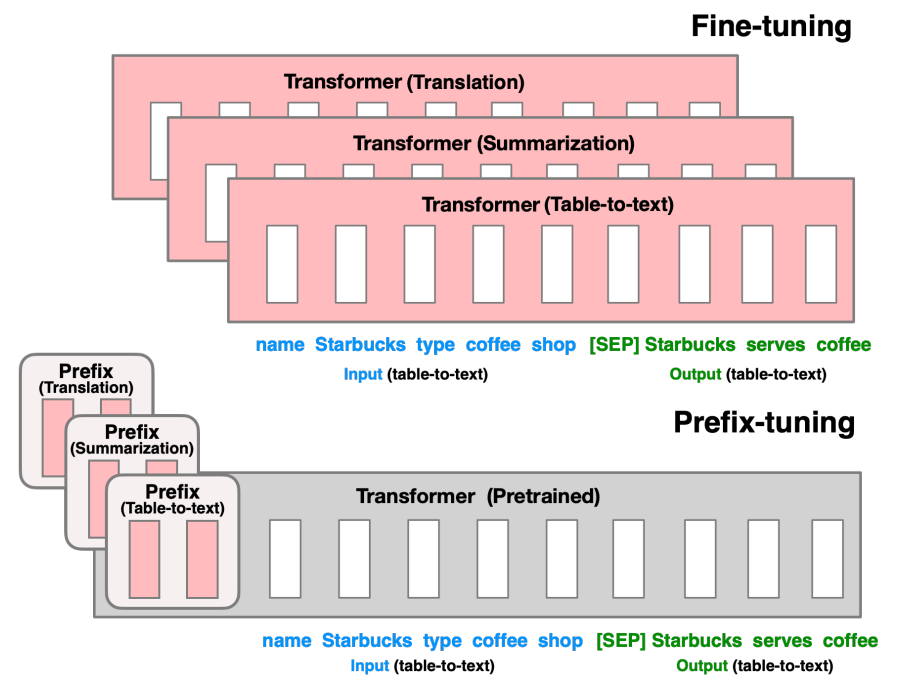
prefix tuning依然是固定预训练参数,但除为每一个任务额外添加一个或多个embedding之外,利用多层感知编码prefix,注意多层感知机就是prefix的编码器,不再像prompt tuning继续输入LLM。
embedding = torch.nn.Embedding(num_virtual_tokens, token_dim)
transform = torch.nn.Sequential(
torch.nn.Linear(token_dim, encoder_hidden_size),
torch.nn.Tanh(),
torch.nn.Linear(encoder_hidden_size, num_layers * 2 * token_dim),
)
- 1
- 2
- 3
- 4
- 5
- 6
在三个数据集中prefix和全参数微调的表现对比:

代码样例:
peft_config = PrefixTuningConfig(task_type="CAUSAL_LM", num_virtual_tokens=20)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
- 1
- 2
- 3
LoRA
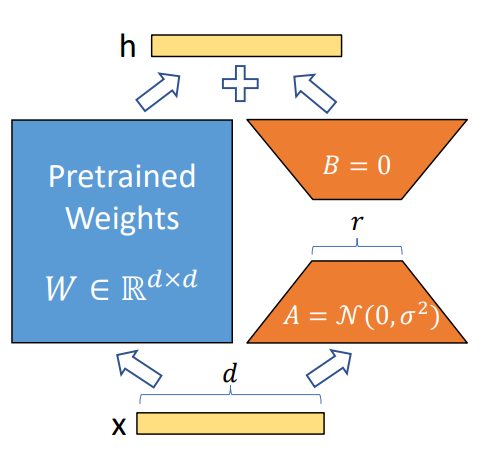
LoRA冻结了预训练模型的参数,并在每一层decoder中加入dropout+Linear+Conv1d额外的参数
那么,LoRA是否能达到全参数微调的性能呢?
根据实验可知,全参数微调要比LoRA方式好的多,但在低资源的情况下也不失为一种选择
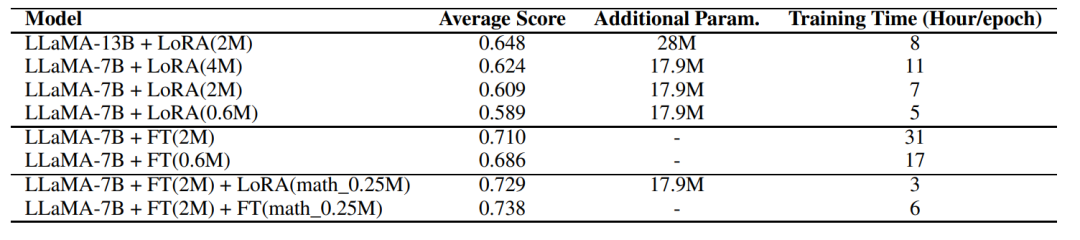
细致到每个任务中的差距如下图:
代码样例:
peft_config = LoraConfig(task_type="SEQ_CLS", inference_mode=False, r=8, lora_alpha=16, lora_dropout=0.1)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
- 1
- 2
- 3
p-tuning
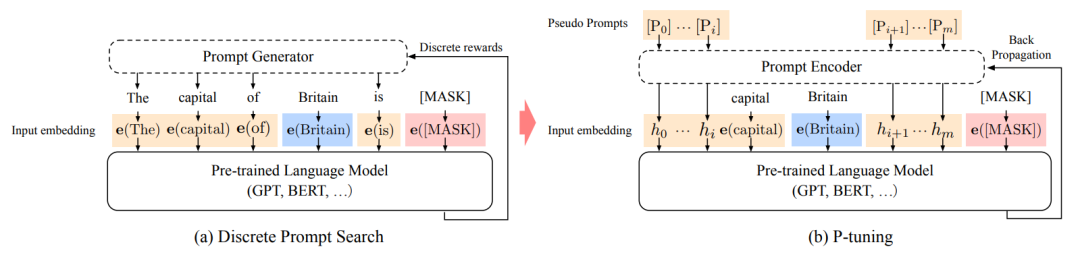
手动尝试最优的提示无异于大海捞针,于是便有了自动离散提示搜索的方法(作图),但提示是离散的,神经网络是连续的,所以寻找的最优提示可能是次优的。p-tuning依然是固定LLM参数,利用多层感知机和LSTM对prompt进行编码,编码之后与其他向量进行拼接之后正常输入LLM。注意,训练之后只保留prompt编码之后的向量即可,无需保留编码器。
self.lstm_head = torch.nn.LSTM(
input_size=self.input_size,
hidden_size=self.hidden_size,
num_layers=num_layers,
dropout=lstm_dropout,
bidirectional=True,
batch_first=True,
)
self.mlp_head = torch.nn.Sequential(
torch.nn.Linear(self.hidden_size * 2, self.hidden_size * 2),
torch.nn.ReLU(),
torch.nn.Linear(self.hidden_size * 2, self.output_size),
)
self.mlp_head(self.lstm_head(input_embeds)[0])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
以上代码可清晰展示出prompt编码器的结构。
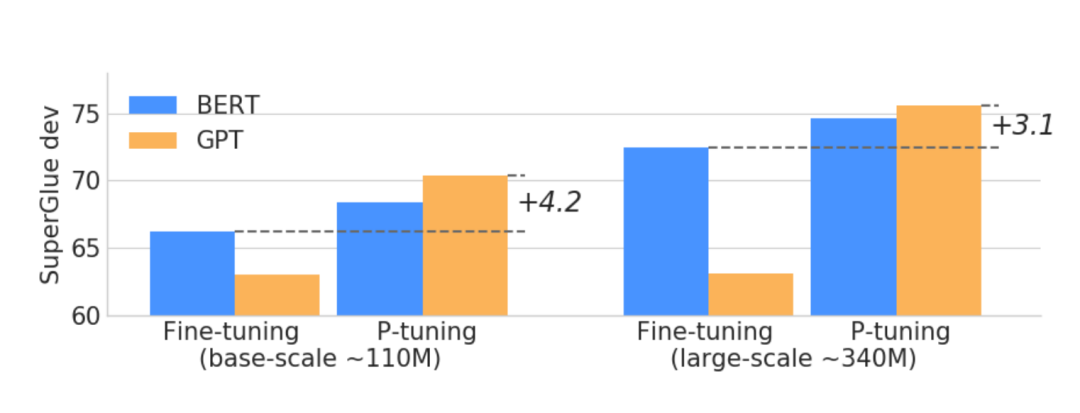
如上图所示,GPT在P-tuning的加持下可达到甚至超过BERT在NLU领域的性能。下图是细致的对比: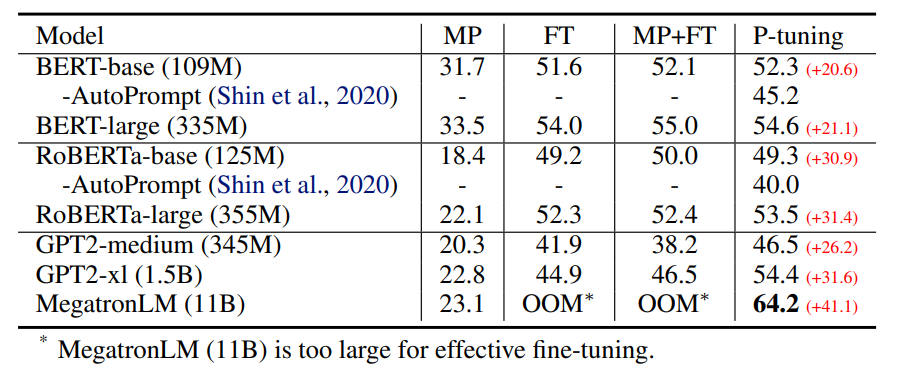
MP: Manual prompt
FT: Fine-tuning
MP+FT: Manual prompt augmented fine-tuning
PT: P-tuning
代码样例:
peft_config = PromptEncoderConfig(task_type="CAUSAL_LM", num_virtual_tokens=20, encoder_hidden_size=128)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
- 1
- 2
- 3
p-tuning v2
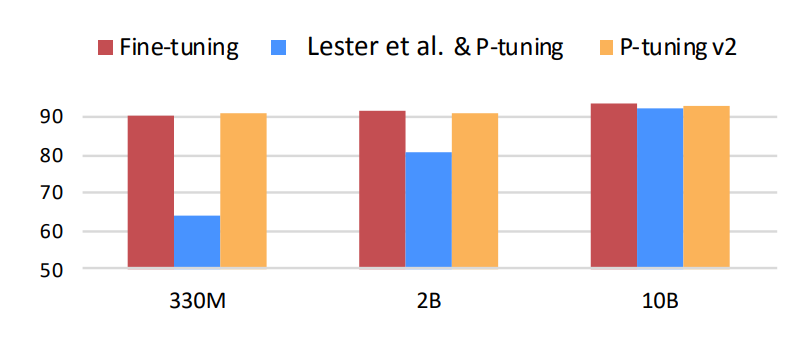
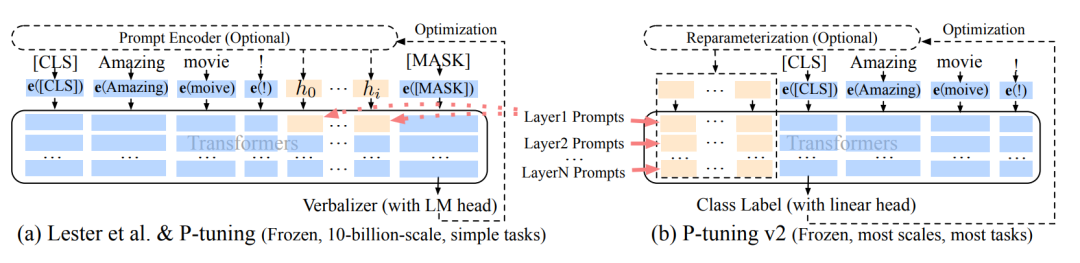
p-tuning的问题是在小参数量模型上表现差(如上图所示),于是有了V2版本,类似于LoRA每层都嵌入了新的参数(称之为Deep FT),下图中开源看到p-tuning v2 集合了多种微调方法。p-tuning v2 在多种任务上下进行微调,之后对于不同的任务如token classification与sentence classification添加了随机初始化的任务头(AutoModelForTokenClassification、AutoModelForSequenceClassification),而非使用自然语言的方式,可以说V2是集大成者。
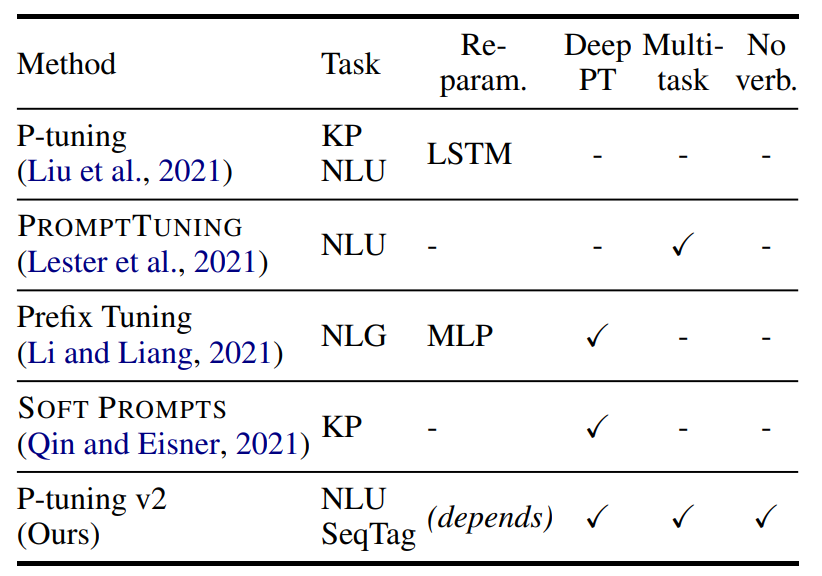
KP: Knowledge Probe,知识探针,用于检测LLM的世界知识掌握能力:https://github.com/facebookresearch/LAMA
SeqTag: Sequence Tagging,如抽取式问答、命名实体识别
Re-param.:Reparameterization,对提示词做单独的编码器
No verb.: No verbalizer,不直接使用LLM head而接一个随机初始化的linear head
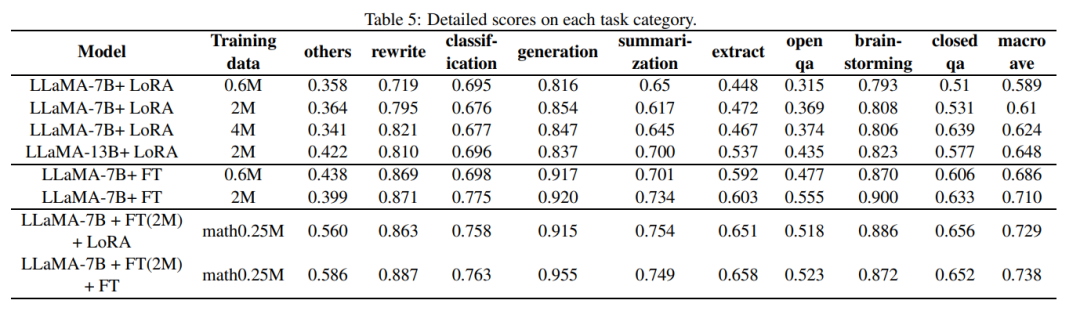
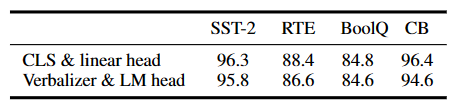
以下表格对比了[CLS] label linear head 和 verbalizer with LM head,[CLS] label linear head的方式药略好。
v1到v2的可视化:蓝色部分为参数冻结,橙色部分为可训练部分
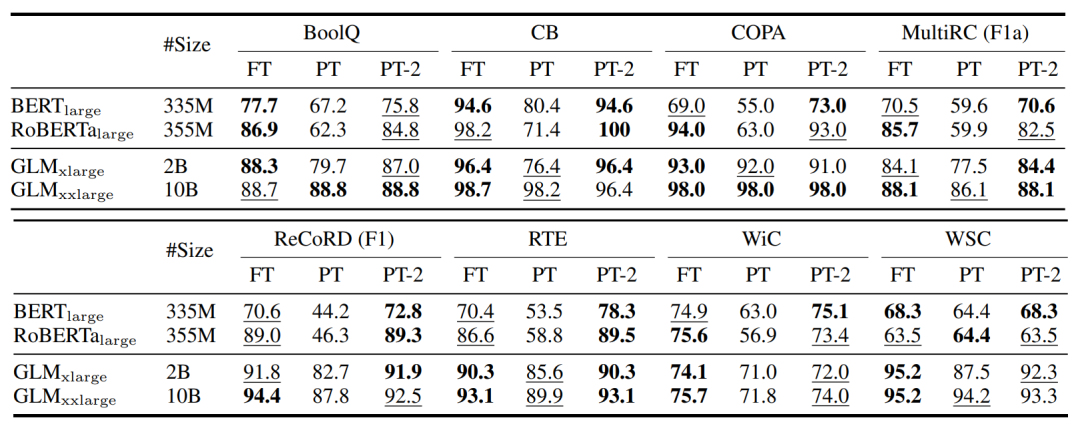
下图中对比了FT、PT、PT-2三种方法,粗体为性能最好的,下划线为性能次好的。
代码样例:
peft_config = PrefixTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=20)
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
- 1
- 2
- 3
AdaLoRA
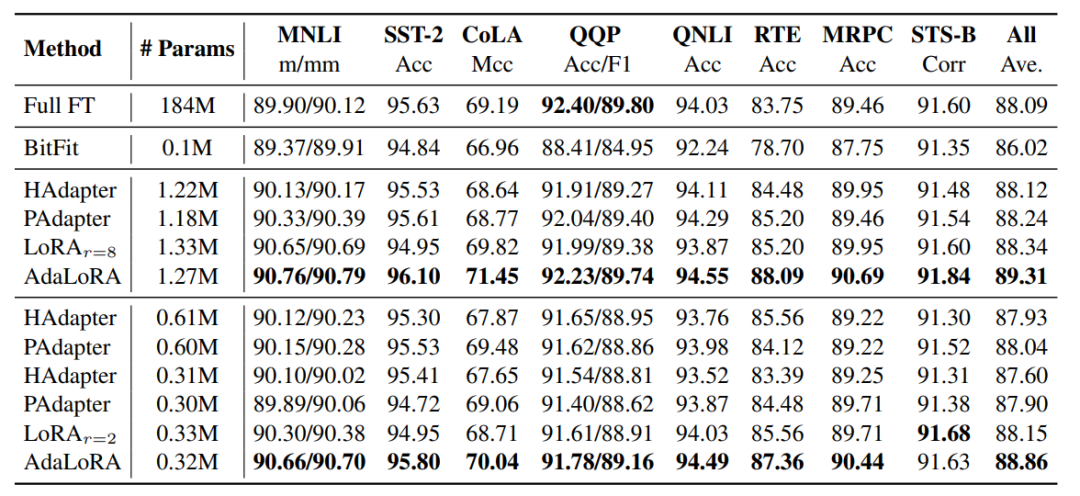
预训练语言模型中的不同权重参数对下游任务的贡献是不同的。因此需要更加智能地分配参数预算,以便在微调过程中更加高效地更新那些对模型性能贡献较大的参数。
具体来说,通过奇异值分解将权重矩阵分解为增量矩阵,并根据新的重要性度量动态地调整每个增量矩阵中奇异值的大小。这样可以使得在微调过程中只更新那些对模型性能贡献较大或必要的参数,从而提高了模型性能和参数效率。
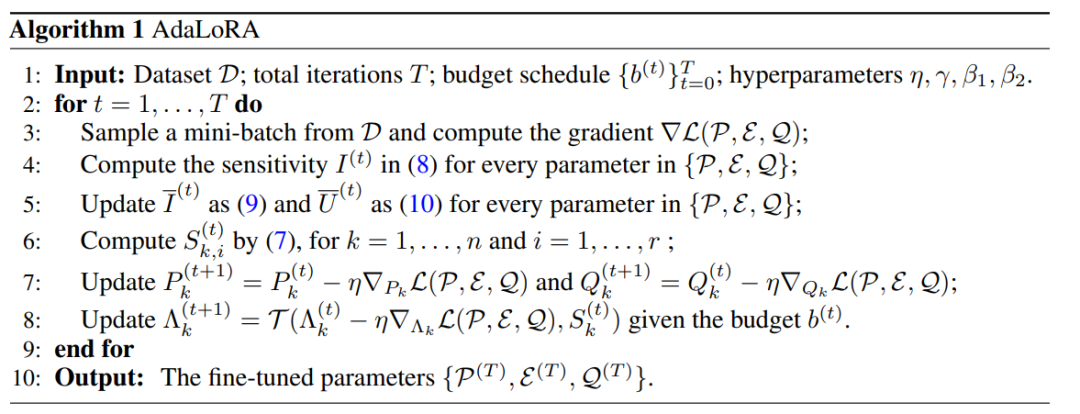
详细的算法如下:
对比不同方法的性能:
代码样例:
peft_config = AdaLoraConfig(peft_type="ADALORA", task_type="SEQ_2_SEQ_LM", r=8, lora_alpha=32, target_modules=["q", "v"],lora_dropout=0.01)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
- 1
- 2
- 3
代码篇
注:以下代码在pytorch 1.12.1版本下运行,其他包都是最新版本
deepspeed
官方的demo所需要的配置如下:
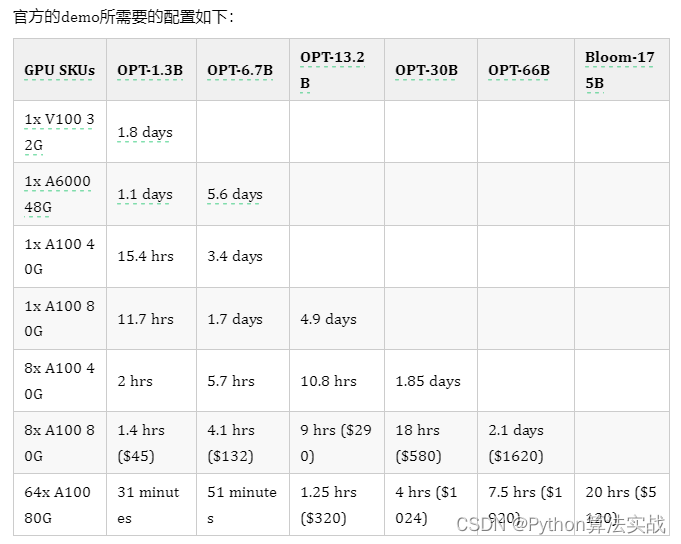
注意到官方给的样例单卡V100只能训练13亿规模的模型,如果换成67亿是否能跑起来呢?
按照官方文档搭建环境:
pip install deepspeed>=0.9.0
git clone https://github.com/microsoft/DeepSpeedExamples.git
cd DeepSpeedExamples/applications/DeepSpeed-Chat/
pip install -r requirements.txt
- 1
- 2
- 3
- 4
- 5
请注意如果你之前装了 deepspeed,请更新至0.9.0
试试全参数微调,这毫无疑问OOM
deepspeed --num_gpus 1 main.py \
--data_path Dahoas/rm-static \
--data_split 2,4,4 \
--model_name_or_path facebook/opt-6.5b \
--gradient_accumulation_steps 2 \
--lora_dim 128 \
--zero_stage 0 \
--deepspeed \
--output_dir $OUTPUT \
&> $OUTPUT/training.log
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
答案是:我们需要卸载,这次便能愉快的run起来了
deepspeed main.py \
--data_path Dahoas/rm-static \
--data_split 2,4,4 \
--model_name_or_path facebook/opt-6.7b \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--max_seq_len 512 \
--learning_rate 9.65e-6 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 1 \
--lr_scheduler_type cosine \
--num_warmup_steps 0 \
--seed 1234 \
--lora_dim 128 \
--gradient_checkpointing \
--zero_stage 3 \
--deepspeed \
--output_dir $OUTPUT_PATH \
&> $OUTPUT_PATH/training.log
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
可以加上LoRA
deepspeed --num_gpus 1 main.py \
--data_path Dahoas/rm-static \
--data_split 2,4,4 \
--model_name_or_path facebook/opt-6.7b \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--max_seq_len 512 \
--learning_rate 1e-3 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 16 \
--lr_scheduler_type cosine \
--num_warmup_steps 0 \
--seed 1234 \
--gradient_checkpointing \
--zero_stage 0 \
--lora_dim 128 \
--lora_module_name decoder.layers. \
--deepspeed \
--output_dir $OUTPUT_PATH \
&> $OUTPUT_PATH/training.log
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
peft
以下代码省略了数据处理
初始化
from datasets import load_dataset,load_from_disk
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer,default_data_collator
from peft import prepare_model_for_int8_training, LoraConfig, get_peft_model
MICRO_BATCH_SIZE = 1
BATCH_SIZE = 1
GRADIENT_ACCUMULATION_STEPS = BATCH_SIZE // MICRO_BATCH_SIZE
EPOCHS = 3
LEARNING_RATE = 3e-6
CUTOFF_LEN = 256
LORA_R = 16
LORA_ALPHA = 32
LORA_DROPOUT = 0.05
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
模型加载,并使用int8进行训练
model_path = "facebook/opt-6.7b"
output_dir = "model"
model = AutoModelForCausalLM.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path, add_eos_token=True)
model = prepare_model_for_int8_training(model)
config = LoraConfig(
r=LORA_R,
lora_alpha=LORA_ALPHA,
target_modules=None,
lora_dropout=LORA_DROPOUT,
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, config)
tokenizer.pad_token_id = 0
data = load_from_disk("data")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
训练与保存
trainer = transformers.Trainer(
model=model,
train_dataset=data["train"],
eval_dataset=data["validation"],
args=transformers.TrainingArguments(
per_device_train_batch_size=MICRO_BATCH_SIZE,
per_device_eval_batch_size=MICRO_BATCH_SIZE,
gradient_accumulation_steps=GRADIENT_ACCUMULATION_STEPS,
warmup_steps=1000,
num_train_epochs=EPOCHS,
learning_rate=LEARNING_RATE,
# bf16=True,
fp16=True,
logging_steps=1,
output_dir=output_dir,
save_total_limit=4,
),
data_collator=default_data_collator,
)
model.config.use_cache = False
trainer.train(resume_from_checkpoint=False)
model.save_pretrained(output_dir)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
直接这么启动当然会OOM,依然需要卸载
编写accelerate配置文件accelerate.yaml
compute_environment: LOCAL_MACHINE
deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 1.0
offload_optimizer_device: none
offload_param_device: none
zero3_init_flag: true
zero3_save_16bit_model: true
zero_stage: 3
distributed_type: DEEPSPEED
downcast_bf16: 'yes'
dynamo_backend: 'yes'
fsdp_config: {}
machine_rank: 0
main_training_function: main
megatron_lm_config: {}
mixed_precision: fp16
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
use_cpu: true
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
deepspeed配置文件:ds.json
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 500,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": 1e-8,
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 2e-05,
"warmup_num_steps": 0
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": false
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
"gradient_accumulation_steps":2,
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": 4,
"train_micro_batch_size_per_gpu": 1,
"wall_clock_breakdown": false
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
启动
accelerate launch --dynamo_backend=nvfuser --config_file accelearte.yaml finetune.py
- 1
注:其他方法与Lora使用方法差距不大,不再赘述,在peft项目中均有代码样例。
顺便提一嘴:petals
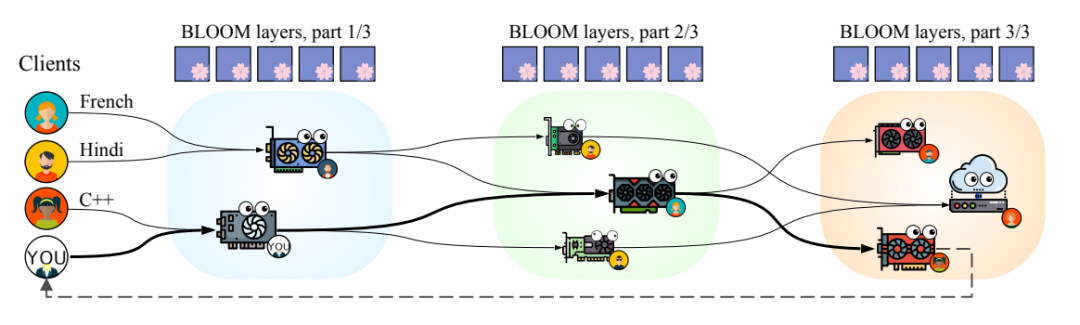
petals将模型划分为多个块,每个用户的机器负责其中一块,分摊了计算压力,类似于某磁力链接下载工具,利用hivemind库进行去中心化的训练与推理。当然你也可以创建自己局域网的群组,对自己独有的模型进行分块等自定义操作。

